By Daniel Ecer and Giuliano Maciocci
Introduction
When we first embarked on the ScienceBeam project just over two years ago, we had one clear goal in mind: to liberate knowledge locked inside academic papers published in the print-era PDF format, and make it available to new, web-native tools and services that could improve the experience of publishing, discovering and consuming science. With the rapidly increasing popularity of preprints, those goals are even more valid today.
In order to make better use of the knowledge locked inside academic research PDFs, we need to extract information in a semantically structured way, that is to say in a way that lets us understand and record what it is that we are extracting. This goal is not an easy one to achieve, as the PDF format, with its primary focus on presentation, does not do much to help represent the semantic structure of a paper. PDF has no concept of an “Abstract” or a “Methods section”, much less which strings of text signify an author’s name, their affiliation, a reference.
Authors pay for this by having to fill lengthy submission forms with information they already included in their submitted Word or PDF manuscript, because no submission system is smart enough to accurately extract that information on its own. Production staff working at journals pay for it in time and effort ensuring those forms match the contents of the paper. Scientific data miners and software developers pay for it by spending resources on data extraction that could be much better spent on data analysis. And a whole industry has developed around the painstaking manual conversion of Word and PDF submissions into more web-friendly formats that power the online academic publishing industry.
These are challenging problems, but we’re making great progress. Here we share an update on ScienceBeam’s latest results, launch a working prototype you can try out today, and talk about how you can contribute to the project to help move it forward.
Working with open source
We have evaluated a number of existing open-source tools that are able to extract semantic information from scientific manuscript PDFs. We also consulted with a number of other publishers and initiatives with an interest in this space, such as the Public Knowledge Project. As a result, we decided to focus our open-source technology development path on using and improving GROBID, a machine learning library for extracting, parsing and re-structuring raw documents such as PDF into structured XML.
An important consideration in that decision was GROBID’s active development and community, as well as a close affinity between its project scope and our goals for ScienceBeam. Out of the box, GROBID’s extraction accuracy for author-submitted manuscripts was not where we wanted it to be, so improving its semantic extraction accuracy for author submitted papers in the life sciences domain is where we felt we could provide our strongest contribution.
If you want to learn more about GROBID, you might be interested in our Innovator Story with its creator, Patrice.
The bioRxiv dataset
While most authors will submit to a scientific publication in Word or PDF format, by the end of the typical publication process a JATS XML file will be created that semantically describes the published article.
That eventual XML file will only be an approximation of the author-submitted manuscript, since its contents may have undergone further changes following peer review (if applicable) and production workflows. As that same XML file then gets used to power the web view of the article once published, it will also usually get converted back into a polished, styled and branded PDF and made available for download on the publisher’s website.
If we are ever to use ScienceBeam to improve the experience of getting a paper published, we need to be able to work right from the first interaction with the author. That means ScienceBeam needs to be optimised to parse original author-submitted PDF manuscripts, and not more polished PDF versions created later in the publishing process. One of our challenges was, therefore, to find and prepare the right training data for our machine learning system:a large corpus of manuscripts with matching PDFs and XML versions so we could train our machine learning solutions to tell how one becomes the other.
Enter bioRxiv, a prominent preprint server for the life sciences. When bioRxiv made their content including XML publicly available (NB: This is why open science is amazing), it provided us with an ideal, high-quality training and evaluation data set for author-submitted papers. The bioRxiv data contains the PDF and the corresponding JATS XML file, with additional resources, such as images, often included.
We have prepared and shared a CC-BY 4.0 subset of the bioRxiv data for training and evaluation purposes.
Re-training GROBID using bioRxiv
GROBID uses a hierarchy of models. These range from top-level segmentation such as identifying the front matter, body text and references, to more granular segmentation such as separating author names into first, middle and last names. Many accuracy improvements in semantic extraction can be achieved by retraining the corresponding GROBID model.
The general GROBID training workflow would normally include generating training data for each GROBID model from the PDF files, which would then have to be manually annotated or corrected by a human. Instead, we decided to use the JATS XML provided by bioRxiv to auto-annotate the training data (an approach we already outlined in our previous post). This approach allowed us to generate more training data from bioRxiv or another dataset with similar XML, without additional time-consuming model-specific human annotations. As a result of having more training data, using GROBID’s Deep Learning models (via DeLFT) became a more practical option. For the bioRxiv evaluation dataset, we can in fact show a significant improvement of the extraction accuracy.
You can find out more about how we generated the GROBID training data. We are also sharing the Docker Image of GROBID with our re-trained models.
Evaluation and results so far
The following evaluation chart illustrates how our version of GROBID with re-trained models compares to the latest release version 0.6.1 of GROBID (at the time of evaluation).
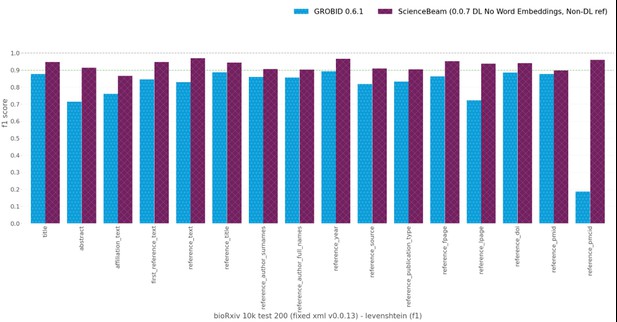
Evaluation results of GROBID 0.6.1 with default models vs ScienceBeam GROBID 0.0.7 trained on the bioRxiv 10k training dataset.
The evaluation results show a significant improvement on the bioRxiv test dataset for selected fields – we invite you to find out more about the evaluation process and results.
Outputs
The ScienceBeam project has multiple outputs that you may be interested in using.
Docker Image, optimized for bioRxiv like manuscripts:
- The Docker Image will be useful if you just want to convert documents that are preprints, or similar in overall format to the papers found on bioRxiv. You can try some of your own papers out using our ScienceBeam Demo website.
- The bioRxiv dataset can either be used for benchmarking or training purposes for your own machine algorithms (licensed under CC BY 4.0)
Training data generation method:
- We gave an overview of the training data generation which allowed us to utilise the bioRxiv dataset without further manual annotation. This approach could be of interest if you have your own dataset with which you would like to re-train GROBID or similar machine learning models.
Next Steps
Our focus so far has been on extracting the kind of article metadata that authors are normally forced to enter via time-consuming submission forms, and which can also be used to quickly list or identify a paper’s authorship, provenance and subject. These are fields like author names, affiliations and abstracts, which have immediate applications to the improvement of software tools for the submission, organisation and presentation of academic papers. Bibliographies in particular are important components of a manuscript, but they are often time-consuming to re-enter and hugely variable in format. For the most part, as can be seen in the figure above, we are delighted to have achieved in excess of 90% accuracy in extracting this information.
Now we will be able to focus on the full-text elements of a manuscript, including key sections (e.g. “methods”) and figures. That will potentially open up new use cases, for example by making preprints immediately more accessible upon submission, without waiting for the somewhat manual process of re-working them into more web-friendly formats.
Conclusion
We provided an overview of the progress we made on the ScienceBeam project and the output to date. We envision that the day a paper in a Word or PDF format can be seamlessly and automatically converted to semantically structured formats, we will unlock a multitude of new use cases - from greatly reduced form-filling when submitting to a publication, to instant access to online collaborative editing tools with no loss of key metadata. We hope that by sharing our progress so far, we might interest the community in bringing that day forward.
If you have found this post or any of the datasets and tools we have shared useful, or if you have a suggestion for which specific aspects of semantic extraction we should focus on, or would like to contribute to the project, please do share your feedback with us at innovation [at] elifesciences [dot] org. We look forward to hearing from you.
Related Resources
Previous Labs Posts:
- Innovator Story: Unlocking knowledge from PDFs
- Libero Reviewer: The making of a user-friendly submission and peer-review platform
- Texture - an open science manuscript editor
#
Do you have an idea or innovation to share? Send a short outline for a Labs blogpost to innovation [at] elifesciences [dot] org.
For the latest in innovation, eLife Labs and new open-source tools, sign up for our technology and innovation newsletter. You can also follow @eLifeInnovation on Twitter.



