Meta-Research: Large-scale language analysis of peer review reports
- Department of Research in Biomedicine and Health, University of Split School of Medicine, Croatia
- Department d'Informàtica, University of Valencia, Spain
- Department of Social and Political Sciences, University of Milan, Italy
Abstract
Peer review is often criticized for being flawed, subjective and biased, but research into peer review has been hindered by a lack of access to peer review reports. Here we report the results of a study in which text-analysis software was used to determine the linguistic characteristics of 472,449 peer review reports. A range of characteristics (including analytical tone, authenticity, clout, three measures of sentiment, and morality) were studied as a function of reviewer recommendation, area of research, type of peer review and reviewer gender. We found that reviewer recommendation had the biggest impact on the linguistic characteristics of reports, and that area of research, type of peer review and reviewer gender had little or no impact. The lack of influence of research area, type of review or reviewer gender on the linguistic characteristics is a sign of the robustness of peer review.
Introduction
Most journals rely on peer review to ensure that the papers they publish are of a certain quality, but there are concerns that peer review suffers from a number of shortcomings (Grimaldo et al., 2018; Fyfe et al., 2020). These include gender bias, and other less obvious forms of bias, such as more favourable reviews for articles with positive findings, articles by authors from prestigious institutions, or articles by authors from the same country as the reviewer (Haffar et al., 2019; Lee et al., 2013; Resnik and Elmore, 2016).
Analysing the linguistic characteristics of written texts, speeches, and audio-visual materials is well established in the humanities and psychology (Pennebaker, 2017). A recent example of this is the use of machine learning by Garg et al. to track gender and ethnic stereotypes in the United States over the past 100 years (Garg et al., 2018). Similar techniques have been used to analyse scientific articles, with an early study showing that scientific writing is a complex process that is sensitive to formal and informal standards, context-specific canons and subjective factors (Hartley et al., 2003). Later studies found that fraudulent scientific papers seem to be less readable than non-fraudulent papers (Markowitz and Hancock, 2016), and that papers in economics written by women are better written than equivalent papers by men (and that this gap increases during the peer review process; Hengel, 2018). There is clearly scope for these techniques to be used to study other aspects of the research and publishing process.
To date most research on the linguistic characteristics of peer review has focused on comparisons between different types of peer review, and it has been shown that open peer review (in which peer review reports and/or the names of reviewers are made public) leads to longer reports and a more positive emotional tone compared to confidential peer review (Bravo et al., 2019; Bornmann et al., 2012). Similar techniques have been used to explore possible gender bias in the peer review of grant applications, but a consensus has not been reached yet (Marsh et al., 2011; Magua et al., 2017). To date, however, these techniques have not been applied to the peer review process at a large scale, largely because most journals strictly limit access to peer review reports.
Here we report the results of a linguistic analysis of 472,449 peer review reports from the PEERE database (Squazzoni et al., 2017). The reports came from 61 journals published by Elsevier in four broad areas of research: health and medical sciences (22 journals); life sciences (5); physical sciences (30); social sciences and economics (4). For each review we had data on the following: i) the recommendation made by the reviewer (accept [n = 26,387, 5.6%]; minor revisions required [134,858, 28.5%]; major revisions required [161,696, 34.2%]; reject [n = 149,508, 31.7%]); ii) the broad area of research; iii) the type of peer review used by the journal (single-blind [n = 411,727, 87.1%] or double-blind [n = 60,722, 12.9%]); and the gender of the reviewer (75.9% were male; 24.1% were female).
Results
We used various linguistic tools to examine the peer review reports in our sample (see Methods for more details). Linguistic Inquiry and Word Count (LIWC) text-analysis software was used to perform word counts and to return scores of between 0% and 100% for ‘analytical tone’, ‘clout’ and ‘authenticity’ (Pennebaker et al., 2015). Three different approaches were used to perform sentiment analysis: i) LIWC returns a score between 0% and 100% for ‘emotional tone’ (with more positive emotions leading to higher scores); ii) the SentimentR package returns a majority of scores between –1 (negative sentiment) and +1 (positive sentiment), with an extremely low number of results outside that range (0.03% in our sample); iii) the Stanford CoreNLP returns a score between 0 (negative sentiment) to +4 (positive sentiment). We also used LIWC to analyse the reports in terms of five foundations of morality (Graham et al., 2009).
Length of report
For all combinations of area of research, type of peer review and reviewer gender, reports recommending accept were shortest, followed by reports recommending minor revisions, reject, and major revisions (Figure 1). Reports written by reviewers for social sciences and economics journals were significantly longer than those written by reviewers for medical journals; men also tended to write longer reports than women; however, the type of peer review (i.e., single- vs. double-blind) did not have any influence on the length of reports (see Table 2 in Supplementary file 1).
Figure 1
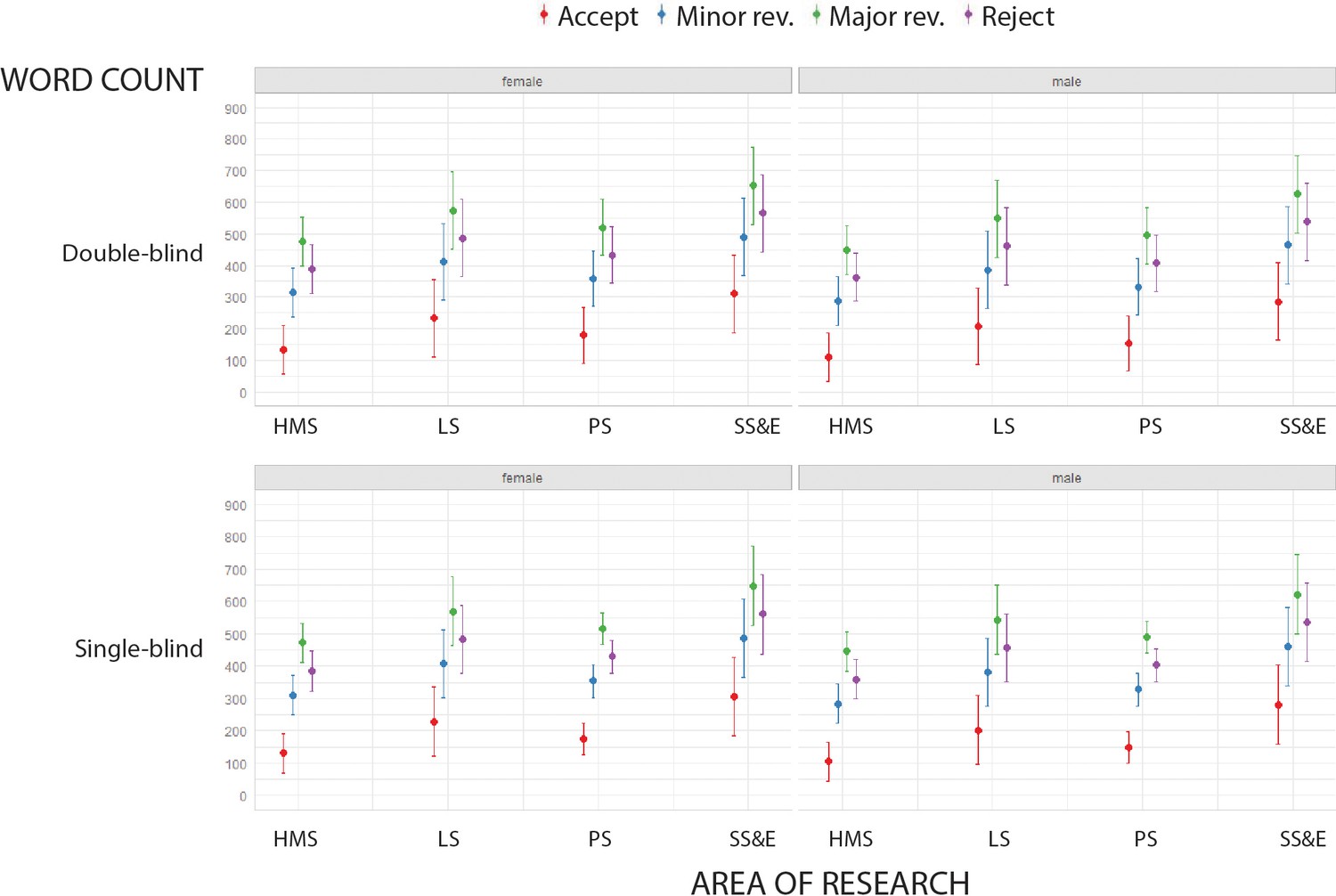
Words counts in peer review reports.
Word count (mean and 95% confidence interval; LIWC analysis) of peer review reports in four broad areas of research for double-blind review (top) and single-blind review (bottom), and for female reviewers (left) and male reviewers (right). Reports recommending accept (red) were consistently the shortest, and reports recommending major revisions (green) were consistently the longest. See Supplementary file 1 for summary data and mixed model linear regression coefficients and residuals. HMS: health and medical sciences; LS: life sciences; PS: physical sciences; SS&E: social sciences and economics.
Analytical tone, clout and authenticity
LIWC returned high scores (typically between 85.0 and 91.0) for analytical tone, and low scores (typically between 18.0 and 25.0) for authenticity, for the peer review reports in our sample (Figure 2A,C; Figure 2—figure supplement 1A,C). High authenticity of a text is defined as the use of more personal words (I-words), present tense words, and relativity words, and fewer non-personal words and modal words (Pennebaker et al., 2015). Low authenticity and high analytical tone are characteristic of texts describing medical research (Karačić et al., 2019; Glonti et al., 2017). There was some variation with reviewer recommendation in the scores returned for clout, with accept having the highest scores for clout, followed by minor revisions, major revisions and reject (Figure 2B; Figure 2—figure supplement 1B).
Figure 2 with 1 supplement see all
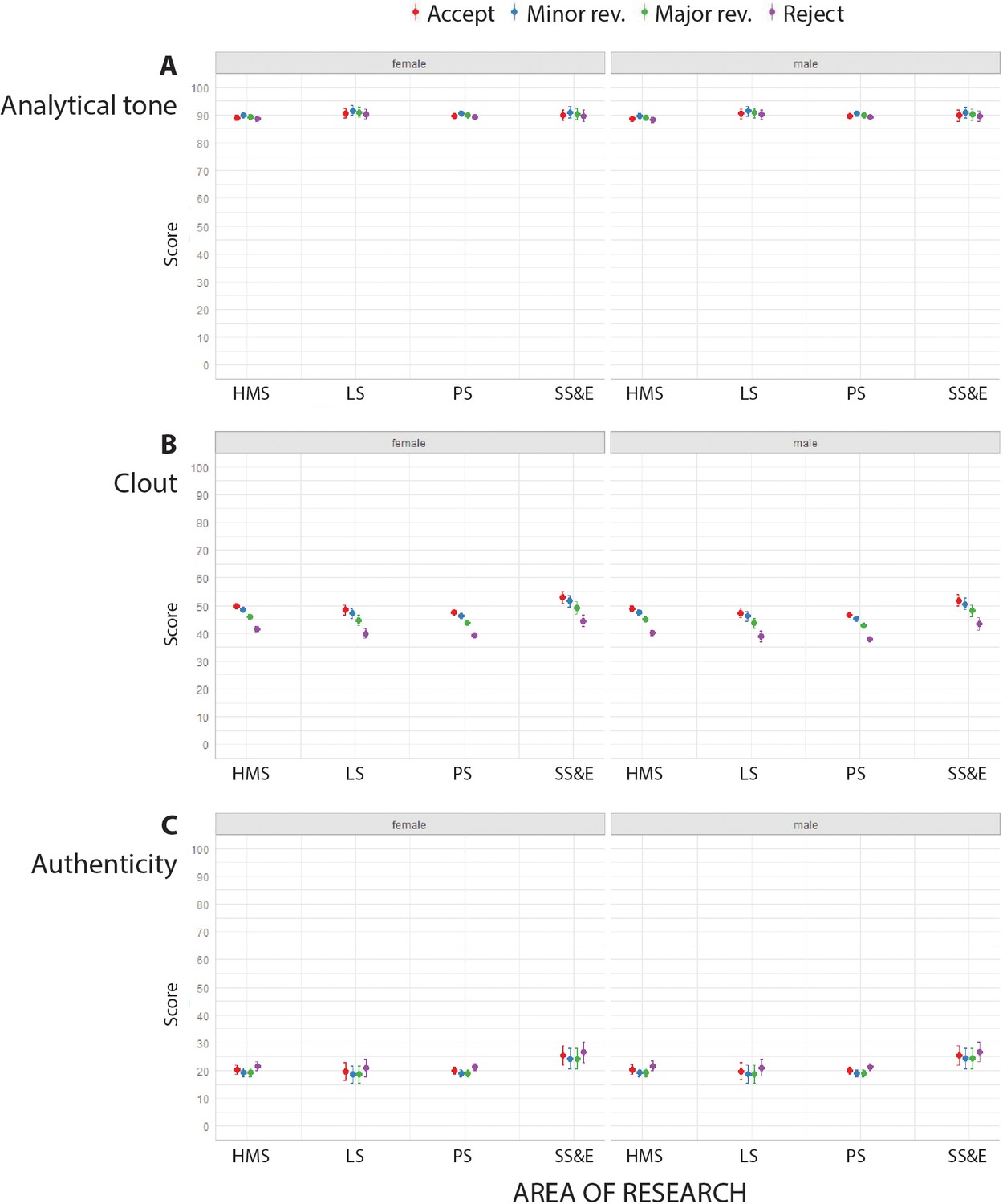
Analytical tone, clout and authenticity and in peer review reports for single-blind review.
Scores returned by LIWC (mean percentages and 95% confidence interval) for analytical tone (A), clout (B) and authenticity (C) for peer review reports in four broad areas of research for female reviewers (left) and male reviewers (right) using single-blind review. Reports recommending accept (red) consistently had the most clout, and reports recommending reject (purple) consistently had the least clout. See Supplementary files 2–4 for summary data, mixed model linear regression coefficients and residuals, and examples of reports with high and low scores for analytical tone, clout and authenticity. HMS: health and medical sciences; LS: life sciences; PS: physical sciences; SS&E: social sciences and economics.
When reviewers recommended major revisions, the text of the report was more analytical. The analytical tone was higher when reviewers were women and for single-blind peer review, but we did not find any effect of the area of research (see Table 4 in Supplementary file 2).
Clout levels varied with area of research, with the highest levels in social sciences and economics journals (see Table 7 in Supplementary file 3). When reviewers recommended rejection, the text showed low levels of clout, as it did when reviewers were men and when the journal useded single-blind peer review (see Table 7 in Supplementary file 3).
The text of reports in social sciences and economics journals had the highest levels of authenticity. Authenticity was prevalent also when reviewers recommended rejection. There was no significant variation in terms of authenticity per reviewer gender or type of peer review (see Table 10 in Supplementary file 4).
Sentiment analysis
The three approaches were used to perform sentiment analysis on our sample – LIWC, SentimentR and the Stanford CoreNLP – produced similar results. Reports recommending accept had the highest scores, indicating higher sentiment, followed by reports recommending minor revisions, major revisions and reject (Figure 3; Figure 3—figure supplement 1). Furthermore, reports for social sciences and economics journals had the highest levels of sentiment, as did reviews written by women. We did not find any association between sentiment and the type of peer review (see Table 13 in Supplementary file 5, Table 16 in Supplementary file 6 and Table 19 in Supplementary file 7).
Figure 3 with 1 supplement see all

Sentiment analysis of peer review reports for single-blind review.
Scores for sentiment analysis returned by LIWC (A; mean percentage and 95% confidence interval, CI), SentimentR (B; mean score and 95% CI), and Stanford CoreNLP (C; mean score and 95% CI) for peer review reports in four broad areas of research for female reviewers (left) and male reviewers (right) using single-blind review. See Supplementary files 5–7 for summary data, mixed model linear regression coefficients and residuals, and examples of reports with high and low scores for sentiment according to LIWC, SentimentR and Stanford CoreNLP analysis.
Moral foundations
LIWC was also used to explore the morality of the reports in our sample (Graham et al., 2009). The differences between peer review recommendations were statistically significant. Reports recommending acceptance had the highest scores for general morality, followed by reports recommending minor revisions, major revisions and reject (Figure 4). Regarding the research area, we found a lowest proportion of words related to morality in the social sciences and economics, when reviewers were men, and when single-blind peer review was used (Figure 4).
Figure 4 with 5 supplements see all
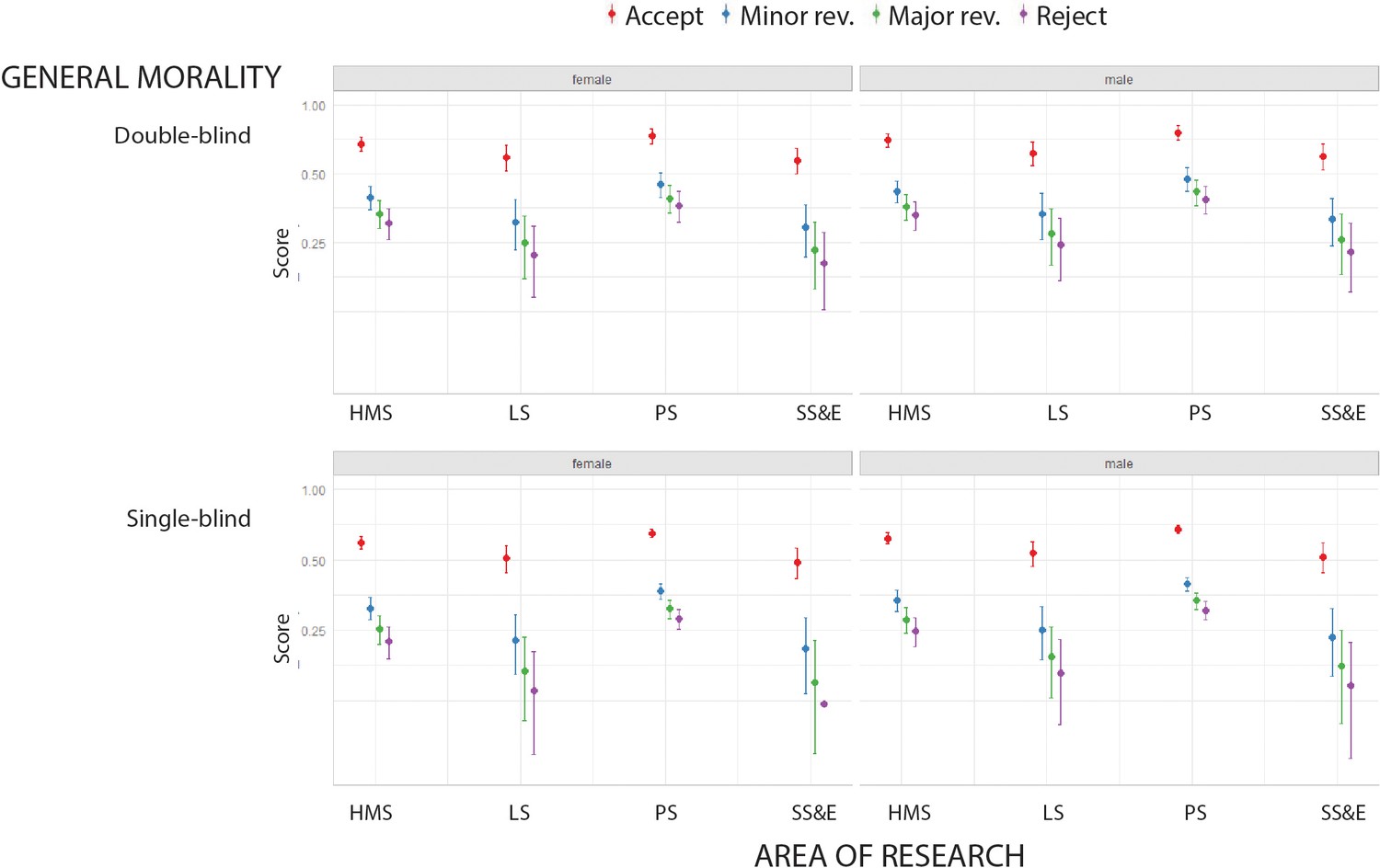
Moral foundations in peer review reports.
Scores returned by LIWC (mean percentage on a log scale) for general morality in peer review reports in four broad areas of research for double-blind review (top) and single-blind review (bottom), and for female reviewers (left) and male reviewers (right). Reports recommending accept (red) consistently had the highest scores. See Supplementary file 8 for lists of the ten most frequent words found in peer review reports for general morality and the five moral foundation variables. HMS: health and medical sciences; LS: life sciences; PS: physical sciences; SS&E: social sciences and economics.
We also explored five foundations of morality – care/harm, fairness/cheating, loyalty/betrayal, authority/subversion, and sanctity/degradation – but no clear patterns emerged (Figure 4—figure supplements 1–5). See the Methods section for more details, and Supplementary file 8 for lists of the ten most common phrases from the LIWC Moral Foundation dictionary. In general, the prevalence of these words was minimal, with average scores lower than 1%. Moreover, these words tended to be part of common phrases and thus did not speak to the moral content of the reviews. This suggests that a combination of qualitative and quantitative methods, including machine learning tools, will be required to explore the moral aspects of peer review.
Conclusion
Our study suggests that the reviewer recommendation has the biggest influence on the linguistic characteristics (and length) of peer review reports, which is consistent with previous, case-based research (Casnici et al., 2017). It is probable that whenever reviewers recommend revision, they write a longer report in order to justify their requests and/or to suggest changes to improve the manuscript (which they do not have to do when they recommend to accept or reject). In our study, in the case of the two more negative recommendations (reject and major revisions), the reports were shorter, and language was less emotional and more analytical. We found that the type of peer review – single-blind or double-blind – had no significant influence on the reports, contrary to previous reports on smaller samples (Bravo et al., 2019; van Rooyen et al., 1999). Likewise, area of research had no significant influence on the reports in the sample, and neither did reviewer gender, which is consistent with a previous smaller study (Bravo et al., 2019). The lack of influence exerted by the area of research, the type of peer review or the reviewer gender on the linguistic characteristics of the reports is a sign of the robustness of peer review.
The results of our study should be considered in the light of certain limitations. Most of the journals were in the health and medical sciences and the physical sciences, and most used single-blind peer review. However, the size, depth and uniqueness of our dataset helped us provide a more comprehensive analysis of peer review reports than previous studies, which were often limited to small samples and incomplete data (van den Besselaar et al., 2018; Sizo et al., 2019; Falk Delgado et al., 2019). Future research would also benefit from baseline data against which results could be compared, although our results match the preliminary results from a study at a single biomedical journal (Glonti et al., 2017), and from knowing more about the referees (such as their status or expertise). Finally, we did not examine the actual content of the manuscripts under review, so we could not determine how reliable reviewers were in their assessments. Combining language analyses of peer review reports with estimates of peer review reliability for the same manuscripts (via inter-reviewer ratings) could provide new insights into the peer review process.
Methods
The PEERE dataset
PEERE is a collaboration between publishers and researchers (Squazzoni et al., 2020), and the PEERE dataset contains 583,365 peer review reports from 61 journal published by Elsevier, with data on reviewer recommendation, area of research (health and medical sciences; life sciences; physical sciences; social sciences and economics), type of peer review (single blind or double blind), and reviewer gender for each report. Most of the reports (N = 481,961) are for original research papers, with the rest (N = 101,404) being for opinion pieces, editorials and letters to the editor. The database was first filtered to exclude reviews that included reference to manuscript revisions, resulting in 583,365 reports. We eliminated 110,636 due to the impossibility to determine reviewer gender, and 260 because we did not have data on the recommendation. Our analysis was performed on a total number of 472,449 peer review reports.
Gender determination
To determine reviewer gender, we followed a standard disambiguation algorithm that has already been validated on a dataset of scientists extracted from the Web of Science database covering a similar publication time window (Santamaría and Mihaljević, 2018). Gender was assigned following a multi-stage gender inference procedure consisting of three steps. First, we performed a preliminary gender determination using, when available, gender salutation (i.e., Mr, Mrs, Ms...). Secondly, we queried the Python package gender-guesser about the extracted first names and country of origin, if any. Gender-guesser has demonstrated to achieve the lowest misclassification rate and introduce the smallest gender bias (Paltridge, 2017). Lastly, we queried the best performer gender inference service, Gender API (https://gender-api.com/), and used the returned gender whenever we found a minimum of 62 samples with, at least, 57% accuracy, which follows the optimal values found in benchmark 2 of the previous research (Santamaría and Mihaljević, 2018). This threshold for the obtained confidence parameters was suitable to ensure that the rate of misclassified names did not exceed 5% (Santamaría and Mihaljević, 2018). This allowed us to determine the gender of 81.1% of reviewers, among which 75.9% were male and 24.1% female. With regards to the three possible gender sources, 6.3% of genders came from scientist salutation, 77.2% from gender-guesser, and 16.5% from the Gender API. The remaining 18.9% of reviewers were assigned an unknown gender. This level of gender determination is consistent with the non-classification rate for names of scientists in previous research (Santamaría and Mihaljević, 2018).
Analytical tone, authenticity and clout
We used a version of the Linguistic Inquiry and Word Count (LIWC) text-analysis software with standardized scores (http://liwc.wpengine.com/) to analyze the peer review reports in our sample. LIWC measures the percentage of words related to three psychological features (so scores range from 0 to 100): ‘analytical tone’; ‘clout’; and "authenticity. A high score for analytical tone indicates a report with a logical and hierarchical style of writing. Clout reveals personal sensitivity towards social status, confidence or leadership: a low score for clout is associated with insecurities and a less confident and more tentative tone (Kacewicz et al., 2014). A high score for authenticity indicates a report written in a style that is honest and humble, whereas a low score indicates a style that is deceptive and superficial (Pennebaker et al., 2015). The words people use also reflect how authentic or personal they sound. People who are authentic tend to use more I-words (e.g. I, me, mine), present-tense verbs, and relativity words (e.g. near, new) and fewer she-he words (e.g. his, her) and discrepancies (e.g. should, could) (Pennebaker et al., 2015).
Sentiment analysis
We used three different methodological approaches to assess sentiment. (i) LIWC measures ‘emotional tone’, which indicates writing dominated by either positive or negative emotions by counting number of words from a pre-specified dictionary. (ii) The SentimentR package (Rinker, 2019) classifies the proportion of words related to sentiment in the text, similarly to the ‘emotional tone’ scores in LIWC but using a different vocabulary. The SentimentR score is the valence of words related with the specific sentiment, majority of scores (99.97%) ranging from −1 (negative sentiment) +1 (positive sentiment). (iii) Stanford CoreNLP is a deep language analysis program that uses machine learning to determine the emotional valence of the text (Socher et al., 2013), and score ranges from 0 (negative sentiment) to +4 (positive sentiment). Examples of characteristic text variables from the peer review reports analysed with these approaches are given in Supplementary files 5–7.
Moral foundations
We used LIWC and Moral Foundations Theory (https://moralfoundations.org/other-materials/) to analyse the reports in our sample according to five moral foundations: care/harm (also known as care-virtue/care-vice); fairness/cheating (or fairness-virtue/fairness-vice); loyalty/betrayal (or loyalty-virtue/loyalty-vice); authority/subversion (authority virtue/authority-vice); and sanctity/degradation (or sanctity-virtue/sanctity-vice).
Statistical methods
Data were analysed using the R programming language, version 3.6.3. (R Development Core Team, 2017). To test the interaction effects and compare different peer review characteristics, we conducted a mixed model linear analysis on each variable (analytical tone, authenticity, clout; the measures of sentiment; and the measures of morality) with reviewer recommendation, area of research, type of peer review (single- or double-blind) and reviewer gender as fixed factors (predictors) and the journal, word count and article type as the random factor. This was to control across-journal interactions, number of words and article type.
Data availability
The journal dataset required a data sharing agreement to be established between authors and publishers. A protocol on data sharing entitled 'TD1306 COST Action New frontiers of peer review (PEERE) PEERE policy on data sharing on peer review' was signed by all partners involved in this research on 1 March 2017, as part of a collaborative project funded by the EU Commission. The protocol established rules and practices for data sharing from a sample of scholarly journals, which included a specific data management policy, including data minimization, retention and storage, privacy impact assessment, anonymization, and dissemination. The protocol required that data access and use were restricted to the authors of this manuscript and data aggregation and report were done in such a way to avoid any identification of publishers, journals or individual records involved. The protocol was written to protect the interests of any stakeholder involved, including publishers, journal editors and academic scholars, who could be potentially acted by data sharing, use and release. The full version of the protocol is available on the peere.org website. To request additional information on the dataset and for any claim or objection, please contact the PEERE data controller at info@peere.org.
References
-
Attitudes of referees in a multidisciplinary journal: An empirical analysisJournal of the Association for Information Science and Technology 68:1763–1771.https://doi.org/10.1002/asi.23665
-
Managing the growth of peer review at the Royal Society journals, 1865-1965Science, Technology & Human Values 45:405–429.https://doi.org/10.1177/0162243919862868
-
WebsiteLinguistic features in peer reviewer reports: how peer reviewers communicate their recommendationsProceedings of the International Congress on Peer Review and Scientific Publication. Accessed April 20, 2020.
-
Liberals and conservatives rely on different sets of moral foundationsJournal of Personality and Social Psychology 96:1029–1046.https://doi.org/10.1037/a0015141
-
Peer review bias: a critical reviewMayo Clinic Proceedings 94:670–676.https://doi.org/10.1016/j.mayocp.2018.09.004
-
Pronoun use reflects standings in social hierarchiesJournal of Language and Social Psychology 33:125–143.https://doi.org/10.1177/0261927X13502654
-
Bias in peer reviewJournal of the American Society for Information Science and Technology 64:2–17.https://doi.org/10.1002/asi.22784
-
Linguistic obfuscation in fraudulent scienceJournal of Language and Social Psychology 35:435–445.https://doi.org/10.1177/0261927X15614605
-
BookThe Discourse of Peer Review: Reviewing Submissions to Academic JournalsLondon: Palgrave Macmillan.https://doi.org/10.1057/978-1-137-48736-0
-
Mind mapping: Using everyday language to explore social & psychological processesProcedia Computer Science 118:100–107.https://doi.org/10.1016/j.procs.2017.11.150
-
SoftwareR: a language and environment for statistical computing, version 3.6.3R Foundation for Statistical Computing, Vienna, Austria.
-
Ensuring the quality, fairness, and integrity of journal peer review: a possible role of editorsScience and Engineering Ethics 22:169–188.https://doi.org/10.1007/s11948-015-9625-5
-
Comparison and benchmark of name-to-gender inference servicesPeerJ Computer Science 4:e156.https://doi.org/10.7717/peerj-cs.156
-
An overview of assessing the quality of peer review reports of scientific articlesInternational Journal of Information Management 46:286–293.https://doi.org/10.1016/j.ijinfomgt.2018.07.002
-
ConferenceRecursive deep models for semantic compositionality over a sentiment treebankProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. pp. 1631–1642.
Decision letter
-
Peter RodgersSenior and Reviewing Editor; eLife, United Kingdom
-
Erin HengelReviewer
In the interests of transparency, eLife publishes the most substantive revision requests and the accompanying author responses.
Thank you for submitting your article "Meta research: Large-scale language analysis of peer review reports reveals lack of moral bias" to eLife for consideration as a Feature Article. Your article has been reviewed by three peer reviewers, and the evaluation has been overseen by the eLife Features Editor. One of the reviewers was Erin Hengel; the other two reviewers have opted to remain anonymous.
The reviewers have discussed the reviews with one another and the Reviewing Editor has drafted this decision to help you prepare a revised submission.
Summary:
The paper presents an explorative study of the linguistic content of a very large set (roughly 500,000) of peer review reports. To our knowledge, this is the first paper addressing such a large data set on peer review and the potential biases often experienced by scholars of all fields. This is highly valuable to academic research as a whole. However, we do not believe the evidence warrants the authors' conclusion that peer review lacks moral bias (see below), and we suggest that the authors revise their paper to focus exclusively on the LIWC indicators (and conduct further research into moral bias, informed by the comments from referee #2 at the end of this email, with a view to writing a second manuscript for future submission). There are also a number of other issues that need to be addressed in a revised manuscript.
Essential revisions:
1. Reducing the emphasis on moral bias in the present manuscript will involve deleting the last 10 rows of table 1 (and similarly for tables 2, 3 and 4), and making changes to the text. The title also needs to be changed, but Figure 1 does not need to be changed.
2. The authors should analyze the data they have for word length, analytical thinking, clout, authenticity, emotional tone and morality in general in greater detail through regression analyses and/or multilevel models.
Here is what referee #1 said on this topic: I am concerned that the explorative approach misses a lot of underlying information. By comparing means of groups, the in-group variance is overlooked. Some of the observed effects might be large enough to hold some sort of universal "truth", but for other cases, substantial effects might still exist within groups. My suggestion would be to rethink the design into one that allows for multidimensionality. One approach could be regression analysis, which would require a more strict type of test-design though. Another approach could be to build reviewer-profiles based on their characteristics. E.g. reviews with a high degree of clout and negative emotion, and low analytical thinking could be one type. Where is this type found? What characterizes it? Additionally, this would allow the authors to include information about the reviewer, e.g. are they always negative? This might also solve the baseline problem, as this would be a classification issue rather than a measurement issue.
Here is what referee #3 said on this topic: All the analyses are descriptive ANOVAs and the like (bivariate). Given the supposed quality of the data, I'd recommend they explore multilevel models. Then they can fix out differences by fields, journals, etc so we get a more clear sense of what's going on.
3. Please include a fuller description of your dataset and describe how representative/biased the sampling is by field and type of journal.
4. Please provide more information on what the LIWC measures and how it is calculated? It would be especially helpful if you showed several LIWC scores together with sample texts (preferably from your own database) to illustrate how well it analyses text. This can be shown in an appendix. If you can't show text from your own database due to privacy concerns, feel free to show passages from this report. (Alternatively, you could take a few reports from, say, the BMJ which makes referee reports publicly available for published papers.)
5. What are baseline effects? What kind of changes should we expect? E.g. when arguing that the language is cold and analytical, what is this comparable to? I would expect most scientific writing to be mostly in this category, and it should not be a surprise - I hope. It would be very useful for the reader to have some type of comparison.
6. Does the analysis allow for the fact that different subject areas will have different LIWC scores? The largest sample of reports comes from the physical sciences, which use single-blind review the most. Reports from this field are also shorter, slightly more analytic and display less Clout and Authenticity. I think your results are picking up this selection bias instead of representing actual differences between the two review processes.
Please discuss.
7. Please add a section on the limitations of your study. For example, there is no discussion of sample bias and representation really.
Also, LIWC is full of issues and problems (NLP has come a ways since LIWC arrived on the scene): do you use the standardized version of LIWC constructs with high cronbach alphas, or the raw versions with poor cronbach alphas?
Does the analysis distinguish between original research content and other forms of content (eg, editorials, opinion pieces, book reviews etc)?
https://doi.org/10.7554/eLife.53249.sa1Author response
[We repeat the reviewers’ points here in italic, and include our replies point by point in Roman.]
Essential revisions:
1. Reducing the emphasis on moral bias in the present manuscript will involve deleting the last 10 rows of table 1 (and similarly for tables 2, 3 and 4), and making changes to the text. The title also needs to be changed, but Figure 1 does not need to be changed.
Thank you for your comment. We revised the tables according to the reviewers’ recommendations and created new tables where we present multilevel description of the review reports based on the interaction effects of the reviewer recommendation, journal discipline, journal peer review type and reviewer gender. We created the tables for the five LIWC variables (word count, analytical tone, clout tone, authenticity and emotional tone), and two new additional measures (SentimentR- an R package that has its own dictionaries for the emotional tone of the text, and Stanford CoreNLP-a deep language analysis software, which served as the concurrent validity assessment of the tone variables from the LIWC package). All multilevel relations are now presented in new figures, which are the results of the mixed methods linear regression where we controlled the random effect of the journal, word count (except for LIWC word count) and article type. In light of the new results, and coherently with referee recommendations, we introduced a change in the title and replaced the Figure 1. We now have seven new graphs describing linguistic characteristics of the reviews between groups in the main text and eleven graphs presenting the moral variables in the Supplementary file.
2. The authors should analyze the data they have for word length, analytical thinking, clout, authenticity, emotional tone and morality in general in greater detail through regression analyses and/or multilevel models.
Thank you for your comment. As mentioned above, we performed a new analysis, where we used the mixed methods approach with reviewer recommendation, journal discipline, journal peer review type and reviewer gender as predictors (fixed factors) and different journals, word count and article type as the random factor, which would enable us to control the variations between journals (there were 61 journals in total from which some were more represented than others, and the majority of the articles were original research articles). We found significant interaction of the reviewer recommendation, journal’s field of research, the type of peer review and reviewer’s gender in each variable assessment, but we understand that this significance could be due to the large sample size. So, we presented figures with the within-group relations on standardized scales where we presented the differences between groups.
Here is what referee #1 said on this topic: I am concerned that the explorative approach misses a lot of underlying information. By comparing means of groups, the in-group variance is overlooked. Some of the observed effects might be large enough to hold some sort of universal "truth", but for other cases, substantial effects might still exist within groups. My suggestion would be to rethink the design into one that allows for multidimensionality. One approach could be regression analysis, which would require a stricter type of test-design though. Another approach could be to build reviewer-profiles based on their characteristics. E.g. reviews with a high degree of clout and negative emotion, and low analytical thinking could be one type. Where is this type found? What characterizes it? Additionally, this would allow the authors to include information about the reviewer, e.g. are they always negative? This might also solve the baseline problem, as this would be a classification issue rather than a measurement issue.
Thank you for the comment. Excellent point. We re-performed the analysis accordingly. The mixed methods approach revealed that the majority of effects of the differences in the writing style of the reviews can be attributed to reviewer recommendations, much less to the journal’s field of research, the type of peer review type and reviewer’s gender. We tried to provide an overview of the general writing style in peer reviews by presenting relevant variables in the same graphs so that a reader can have an overview about what peer review characteristics predict different language styles.
Here is what referee #3 said on this topic: All the analyses are descriptive ANOVAs and the like (bivariate). Given the supposed quality of the data, I'd recommend they explore multilevel models. Then they can fix out differences by fields, journals, etc so we get a clearer sense of what's going on.
As explained above, we performed mixed methods approach where these effects were analysed jointly. The current analysis provides an overview of the interaction effects in peer review characteristics and sizes of the differences between them.
3. Please include a fuller description of your dataset and describe how representative/biased the sampling is by field and type of journal.
Thank you, we added this both to the methods and the limitations in the Discussion section.
4. Please provide more information on what the LIWC measures and how it is calculated? It would be especially helpful if you showed several LIWC scores together with sample texts (preferably from your own database) to illustrate how well it analyses text. This can be shown in an appendix. If you can't show text from your own database due to privacy concerns, feel free to show passages from this report. (Alternatively, you could take a few reports from, say, the BMJ which makes referee reports publicly available for published papers.)
LIWC has a dictionary with words associated with different tone, and it counts number of words for each tone type in a certain text. The LIWC output is the percentage of words from a tone category in the text. We now provided the calculation of the different tone variables in the Supplementary file, both for high and low levels of tone. The examples are anonymized.
5. What are baseline effects? What kind of changes should we expect? E.g. when arguing that the language is cold and analytical, what is this comparable to? I would expect most scientific writing to be mostly in this category, and it should not be a surprise - I hope. It would be very useful for the reader to have some type of comparison.
Another good point. The results in our study were similar to an unpublished study that focused on the analysis of the peer review linguistic characteristics, but on a much smaller sample and in only in a single journal (https://peerreviewcongress.org/prc17-0234). However, with the new methodological approach we looked at the relationship of the linguistic characteristics and different aspects of peer review process and found important differences. The analytical tone was indeed predominant in all types of peer review reports, but we found differences in other linguistic characteristics. The new results are presented in the revised manuscript.
6. Does the analysis allow for the fact that different subject areas will have different LIWC scores? The largest sample of reports comes from the physical sciences, which use single-blind review the most. Reports from this field are also shorter, slightly more analytic and display less Clout and Authenticity. I think your results are picking up this selection bias instead of representing actual differences between the two review processes.
Thank you for your comment. The dataset characteristics are now described in the limitations in the Discussion section and we are aware that there is a higher prevalence of journals from Physical sciences, double blind reviews and those which asked for revisions. However, the new analyses now include the interaction of peer review characteristics and so we introduced a better control for this selection bias.
7. Please add a section on the limitations of your study. For example, there is no discussion of sample bias and representation really.
As mentioned previously, we added a limitation section to the revised manuscript.
Also, LIWC is full of issues and problems (NLP has come a ways since LIWC arrived on the scene): do you use the standardized version of LIWC constructs with high cronbach alphas, or the raw versions with poor cronbach alphas?
The LIWC version we used is the standardized version with high Cronbach alphas. This has now been clarified in the Methods section of the revised manuscript. We also analysed the data using Stanford CoreNLP deep learning tool in order to increase internal validity of our approach.
Does the analysis distinguish between original research content and other forms of content (eg, editorials, opinion pieces, book reviews etc)?
There were no book reviews in the dataset. However, we did make the distinction between the original articles and other formats (There was the total of 388,737 original articles and 83,972 of other types or articles of those included in the mixed model analyses), which is now described in the Methods. We used this as the random factor in the mixed model linear regression.
https://doi.org/10.7554/eLife.53249.sa2Article and author information
Author details
Daniel Garcia-Costa

Francisco Grimaldo
Flaminio Squazzoni
Funding
Ministerio de Ciencia e Innovación (RTI2018-095820-B-I00)
- Daniel Garcia-Costa
- Francisco Grimaldo
Spanish Agencia Estatal de Investigación (RTI2018-095820-B-I00)
- Daniel Garcia-Costa
- Francisco Grimaldo
European Regional Development Fund (RTI2018-095820-B-I00)
- Daniel Garcia-Costa
- Francisco Grimaldo
Croatian Science Foundation (IP-2019-04-4882)
- Ana Marušić
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Dr Bahar Mehmani from Elsevier for helping us with data collection.
Publication history
- Received:
- Accepted:
- Accepted Manuscript published:
- Version of Record published:
Copyright
© 2020, Buljan et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 3,112
- views
-
- 314
- downloads
-
- 24
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Meta-Research: Large-scale language analysis of peer review reports
eLife 9:e53249.
https://doi.org/10.7554/eLife.53249





{kind=link}
{kind=link}
{kind=link}
{kind=link}