Aligned and oblique dynamics in recurrent neural networks
- Faculty of Electrical Engineering and Computer Science, Technical University of Berlin, Germany
- Science of Intelligence, Research Cluster of Excellence, Germany
- Champalimaud Foundation, Portugal
- Laboratoire de Neurosciences Cognitives et Computationnelles, INSERM U960, Ecole Normale Superieure-PSL Research University, France
- Rappaport Faculty of Medicine and Network Biology Research Laboratories, Technion - Israel Institute of Technology, Israel
eLife Assessment
This work provides an important and novel framework for interpreting the interactions between recurrent dynamics across stages of neural processing. The authors report that two different kinds of dynamics exist in recurrent networks differing in the extent to which they align with the output weights. The authors also present convincing evidence that both types of dynamics exist in the brain.
https://doi.org/10.7554/eLife.93060.3.sa0Significance of the findings:
Important: Findings that have theoretical or practical implications beyond a single subfield
- Landmark
- Fundamental
- Important
- Valuable
- Useful
Strength of evidence:
Convincing: Appropriate and validated methodology in line with current state-of-the-art
- Exceptional
- Compelling
- Convincing
- Solid
- Incomplete
- Inadequate
During the peer-review process the editor and reviewers write an eLife Assessment that summarises the significance of the findings reported in the article (on a scale ranging from landmark to useful) and the strength of the evidence (on a scale ranging from exceptional to inadequate). Learn more about eLife Assessments
Abstract
The relation between neural activity and behaviorally relevant variables is at the heart of neuroscience research. When strong, this relation is termed a neural representation. There is increasing evidence, however, for partial dissociations between activity in an area and relevant external variables. While many explanations have been proposed, a theoretical framework for the relationship between external and internal variables is lacking. Here, we utilize recurrent neural networks (RNNs) to explore the question of when and how neural dynamics and the network’s output are related from a geometrical point of view. We find that training RNNs can lead to two dynamical regimes: dynamics can either be aligned with the directions that generate output variables, or oblique to them. We show that the choice of readout weight magnitude before training can serve as a control knob between the regimes, similar to recent findings in feedforward networks. These regimes are functionally distinct. Oblique networks are more heterogeneous and suppress noise in their output directions. They are furthermore more robust to perturbations along the output directions. Crucially, the oblique regime is specific to recurrent (but not feedforward) networks, arising from dynamical stability considerations. Finally, we show that tendencies toward the aligned or the oblique regime can be dissociated in neural recordings. Altogether, our results open a new perspective for interpreting neural activity by relating network dynamics and their output.
Introduction
The relation between neural activity and behavioral variables is often expressed in terms of neural representations. Sensory input and motor output have been related to the tuning curves of single neurons (Hubel and Wiesel, 1962; O’Keefe and Dostrovsky, 1971; Hafting et al., 2005) and, since the advent of large-scale recordings, to population activity (Buonomano and Maass, 2009; Saxena and Cunningham, 2019; Vyas et al., 2020). Both input and output can be decoded from population activity (Churchland et al., 2012; Mante et al., 2013), even in real-time, closed-loop settings (Sadtler et al., 2014; Willett et al., 2021). However, neural activity is often not fully explained by observable behavioral variables. Some components of the unexplained neural activity have been interpreted as random trial-to-trial fluctuations (Galgali et al., 2023), potentially linked to unobserved behavior (Stringer et al., 2019b; Musall et al., 2019; Wang et al., 2023). Activity may further be due to other ongoing computations not immediately related to behavior, such as preparatory motor activity in a null space of the motor readout (Kaufman et al., 2014; Hennequin et al., 2014). Finally, neural activity may partially be due to other constraints, e.g., related to the underlying connectivity (Atallah and Scanziani, 2009; Okun and Lampl, 2008), the process of learning (Sadtler et al., 2014), or stability, i.e., the robustness of the neural dynamics to perturbations (Russo et al., 2020).
Here, we aim for a theoretical understanding of neural representations: Which factors might determine how strongly activity and behavioral output variables are related? To this end, we use trained recurrent neural networks (RNNs). In this setting, output variables are determined by the task at hand, and neural activity can be described by its projection onto the principal components (PCs). We show that these networks can operate between two extremes: an ‘aligned’ regime in which the output weights and the largest PCs are strongly correlated, and a second, ‘oblique’ regime, where the output weights and the largest PCs are poorly correlated.
What determines the regime in which a network operates? We show that quite general considerations lead to a link between the magnitude of output weights and the regime of the network. As a consequence, we can use output magnitude as a control knob for trained RNNs. Indeed, when we trained RNN models on different neuroscience tasks, large output weights led to oblique dynamics, and small output weights to aligned dynamics. Recent results in feedforward networks identified two regimes – rich and lazy – that can also arise from choices of output weights (Chizat et al., 2019; Jacot et al., 2018). In an extensive Methods section, we further analyze in detail how the oblique and aligned regimes arise during learning. There we show that the dynamical nature of RNNs, in particular demanding stable dynamics, leads to the replacement of unstable, lazy, solutions by oblique ones.
We then considered the functional consequences of the two regimes. Building on the concept of feedback loops driving the network dynamics (Sussillo and Abbott, 2009; Rivkind and Barak, 2017), we show that, in the aligned regime, the largest PCs and the output are qualitatively similar. In the oblique regime, in contrast, the two may be qualitatively different. This functional decoupling in oblique networks leads to a large freedom for neural dynamics. Different networks with oblique dynamics thus tend to employ different dynamics for the same tasks. Aligned dynamics, in contrast, are much more stereotypical. Furthermore, as a result of how neural dynamics and output are coupled, oblique and aligned networks react differently to perturbations of the neural activity along the output direction. In particular, oblique (but not aligned) networks develop an additional negative feedback loop that suppresses output noise. We finally show that neural recordings from different experiments can have different degrees of alignment, which indicates that our theoretical results may be useful in identifying different regimes for different experiments, tasks, or brain regions.
Altogether, our work opens a new perspective relating network dynamics and their output, yielding important insights for modeling brain dynamics as well as experimentally accessible questions about learning and dynamics in the brain.
Results
Aligned and oblique population dynamics
We consider an animal performing a task while both behavior and neural activity are recorded. For example, the task might be to produce a periodic motion, described by the output of Figure 1A. For simplicity, we assume that the behavioral output can be decoded linearly from the neural activity (Mante et al., 2013; Sadtler et al., 2014; Gallego et al., 2017; Russo et al., 2018; Willett et al., 2021). We can thus write
(1)
with readout weights . The activity of neuron is given by , and we refer to the vector as the state of the network.
Figure 1
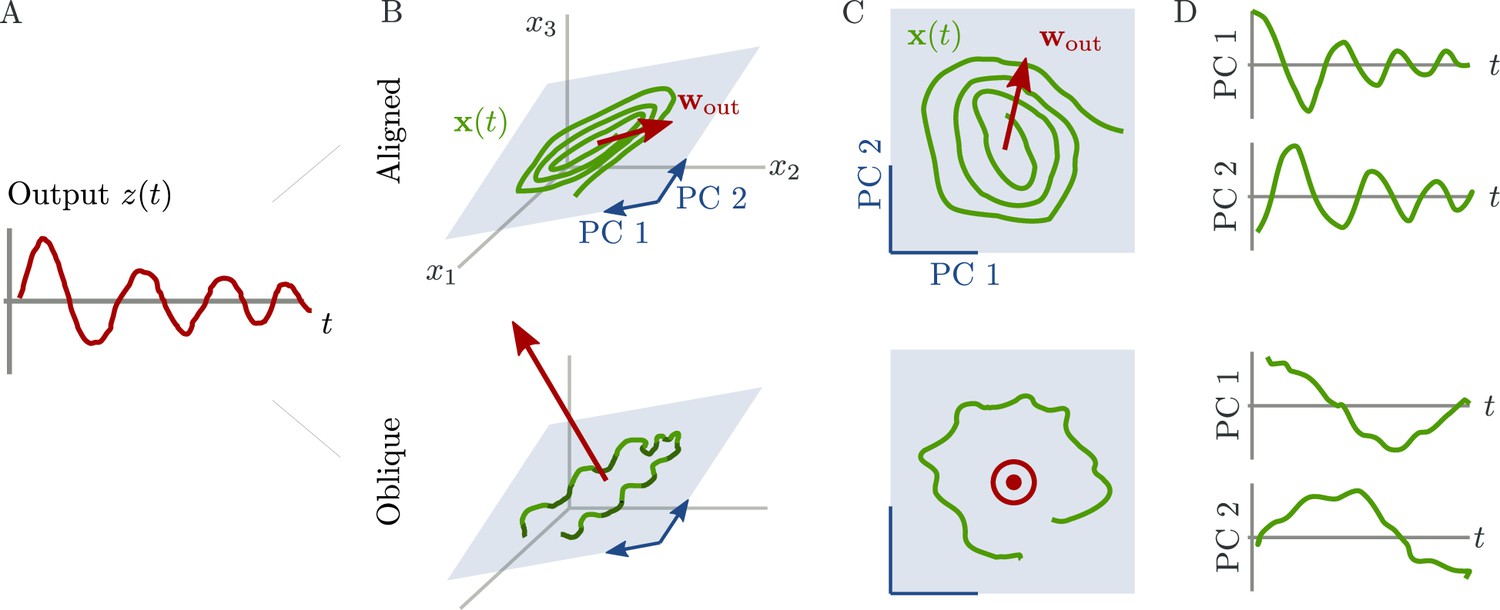
Schematic of aligned and oblique dynamics in recurrent neural networks.
(A) Output generated by both networks. (B) Neural activity of aligned (top) and oblique (bottom) dynamics, visualized in the space spanned by three neurons. Here, the activity (green) is three-dimensional, but most of the variance is concentrated along the two largest principal components (PCs) (blue). For aligned dynamics, the output weights (red) are small and lie in the subspace spanned by the largest PCs; they are hence correlated to the activity. For oblique dynamics, the output weights are large and lie outside of the subspace spanned by the largest PCs; they are hence poorly correlated to the activity. (C) Projection of activity onto the two largest PCs. For oblique dynamics, the output weights are orthogonal to the leading PCs. (D) Evolution of PC projections over time. For aligned dynamics, the projection on the PCs resembles the output , and reconstructing the output from the largest two components is possible. For the oblique dynamics, such reconstruction is not possible, because the projections oscillate much more slowly than the output.
Neural activity has to generate the output in some subspace of the state space, where each axis represents the activity of one neuron. In the simplest case (Figure 1B, top), the output is produced along the largest PCs of activity, as shown by the fact that projecting the neural activity onto the largest PCs returns the target oscillation (Figure 1D, top). We call such dynamics ‘aligned’ because of the alignment between the subspace spanned by the largest PCs and the output vector (red).
There is, however, another possibility. Neural activity may have many other components not directly related to the output and these other components may even dominate the overall activity. In this case (Figure 1B and D, bottom), the two largest PCs are not enough to read out the output, and smaller PCs are needed. We call such dynamics ‘oblique’ because the subspace spanned by the largest PCs and the output vector are poorly aligned.
We consider these two possibilities as distinct dynamical regimes, noting that intermediate situations are also possible. The actual regime of neural dynamics has important consequences for how one interprets neural recordings. For aligned dynamics, analyzing the dynamics within the largest PCs may lead to insights about the computations generating the output (Vyas et al., 2020). For oblique dynamics, such an analysis is hampered by the dissociation between the large PCs and the components generating the output (Russo et al., 2018).
Magnitude of output weights controls regime in trained RNNs
What determines which regime a neural network operates in? Given that behavior is the same, but representations differ, we study this question using trained RNNs. This framework constrains what networks do, but not how they do it (Sussillo, 2014; Barak, 2017). The specific property of representation we are interested in is the alignment, or correlation, between output weights and states:
(2)
where the vector norms and quantify the magnitude of each vector.
For aligned dynamics, the correlation is large, corresponding to the alignment between the leading PCs of the neural activity and the output weights (Figure 1B, top). In contrast, for oblique dynamics, this correlation is small (Figure 1B, bottom). Note that the concept of correlation can be generalized to accommodate multiple time points and multidimensional output (see section Generalized correlation).
Studying the same task means that the output is the same, so it is instructive to express it in terms of the correlation :
(3)
Recent work on feedforward networks showed that can have a large effect on the resulting representations (Jacot et al., 2018; Chizat et al., 2019). Equation 3 shows that is indeed linked to , but can also vary. In a detailed analysis in the Methods (sections Analysis of solutions under noiseless conditions to Oblique solutions arise for noisy, nonlinear systems), we show that for recurrent networks, stability considerations preclude from being small. This implies that if we choose a readout norm and then train the RNN on a given task, the correlation must compensate.
If we choose small output weights, we expect aligned dynamics, because a large correlation is necessary to generate sufficiently large output (Figure 1B, top). If instead we choose large output weights, we expect oblique dynamics, because only a small correlation keeps the output magnitude from growing too large.
We tested whether output weights can serve as a control knob to select dynamical regimes using an RNN model trained on an abstract version of the cycling task introduced in Russo et al., 2018. The networks were trained to generate a 2D signal that rotated in the plane spanned by two outputs and (Figure 2A). An input pulse at the beginning of each trial indicated the desired direction of rotation. We set up two models with either small or large output weights and trained the recurrent weights of each with gradient descent (section Details on RNN models and training).
Figure 2
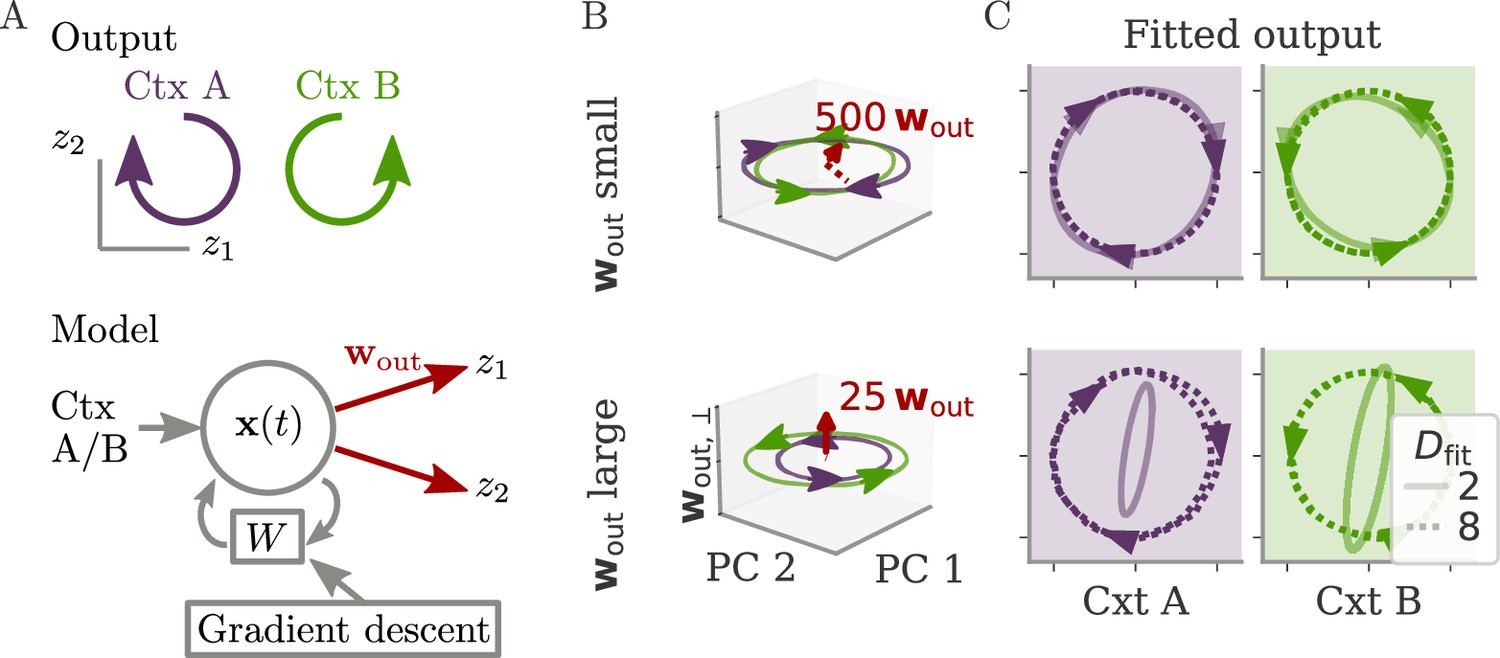
Aligned and oblique dynamics for a cycling task (Russo et al., 2018).
(A) A network with two outputs was trained to generate either clockwise or anticlockwise rotations, depending on the context (top). Our model recurrent neural network (RNN) (bottom) received a context input pulse, generated dynamics via recurrent weights , and yielded the output as linear projections of the states. We trained the recurrent weights with gradient descent. (B, C) Resulting internal dynamics for two networks with small (top) and large (bottom) output weights, corresponding to aligned and oblique dynamics, respectively. (B) Dynamics projected on the first two principal components (PCs) and the remaining direction of the first output vector (for ). The output weights are amplified to be visible. Arrowheads indicate the direction of the dynamics. Note that for the large output weights, the dynamics in the first two PCs co-rotated, despite the counter-rotating output. (C) Output reconstructed from the largest PCs, with dimension (full lines) or 8 (dotted). Two dimensions already yield a fit with for aligned dynamics (top), but almost no output for oblique (bottom, , no arrows shown). For the latter, a good fit with % is only reached with .
After both models learned the task, we projected the network activity into a three-dimensional (3D) space spanned by the two largest PCs of the dynamics . A third direction, , spanned the remaining part of the first output vector . The resulting plots, Figure 2B, corroborate our hypothesis: Small output weights led to aligned dynamics with a large correlation between the largest PCs and the output weights. In contrast, the large output weights of the second network were almost orthogonal, or oblique, to the two leading PCs. Further qualitative differences between the two solutions in terms of the direction of trajectories will be discussed below.
Another way to quantify these regimes is by the ability to reconstruct the output from the large PCs of neural activity, as quantified by the coefficient of determination . For the aligned network, the projection on the two largest PCs (Figure 2C, solid) already led to a good reconstruction. For the oblique networks, the two largest PCs were not sufficient. We needed the first eight dimensions (Figure 2C, dashed) to obtain a good reconstruction (). In contrast to the differences in these fits, the neural dynamics themselves were much more similar between the networks. Specifically, 90% of the variance was explained by four and five dimensions for the aligned and oblique networks, respectively.
Can we use the output weights to induce aligned or oblique dynamics in more general settings? We trained RNN models with small or large initial output weights on five different neuroscience tasks (section Task details). All weights (input, recurrent, and output) were trained using the Adam algorithm (section Details on RNN models and training). After training, we measured the three quantities of Equation 3: magnitudes of neural activity and output weights, and the correlation between the two. The results in Figure 3A show that across tasks, initialization with large output weights led to oblique dynamics (small correlation), and with small output weights to aligned dynamics (large correlation). While training could, in principle, change the initially small output weights to large ones (and vice versa), we noticed that this does not happen. Small output weights did increase with training, but the large gap in norms remained. This shows that setting the output weights at initialization can serve to determine their scale after learning under realistic settings. While explaining this observation is beyond the scope of this work, we note that (1) changing the internal weights suffices to solve the task, and (2) the extent to which the output weights change during learning depends on the algorithm and specific parameterization (Jacot et al., 2018; Geiger et al., 2020; Yang and Hu, 2020).
Figure 3
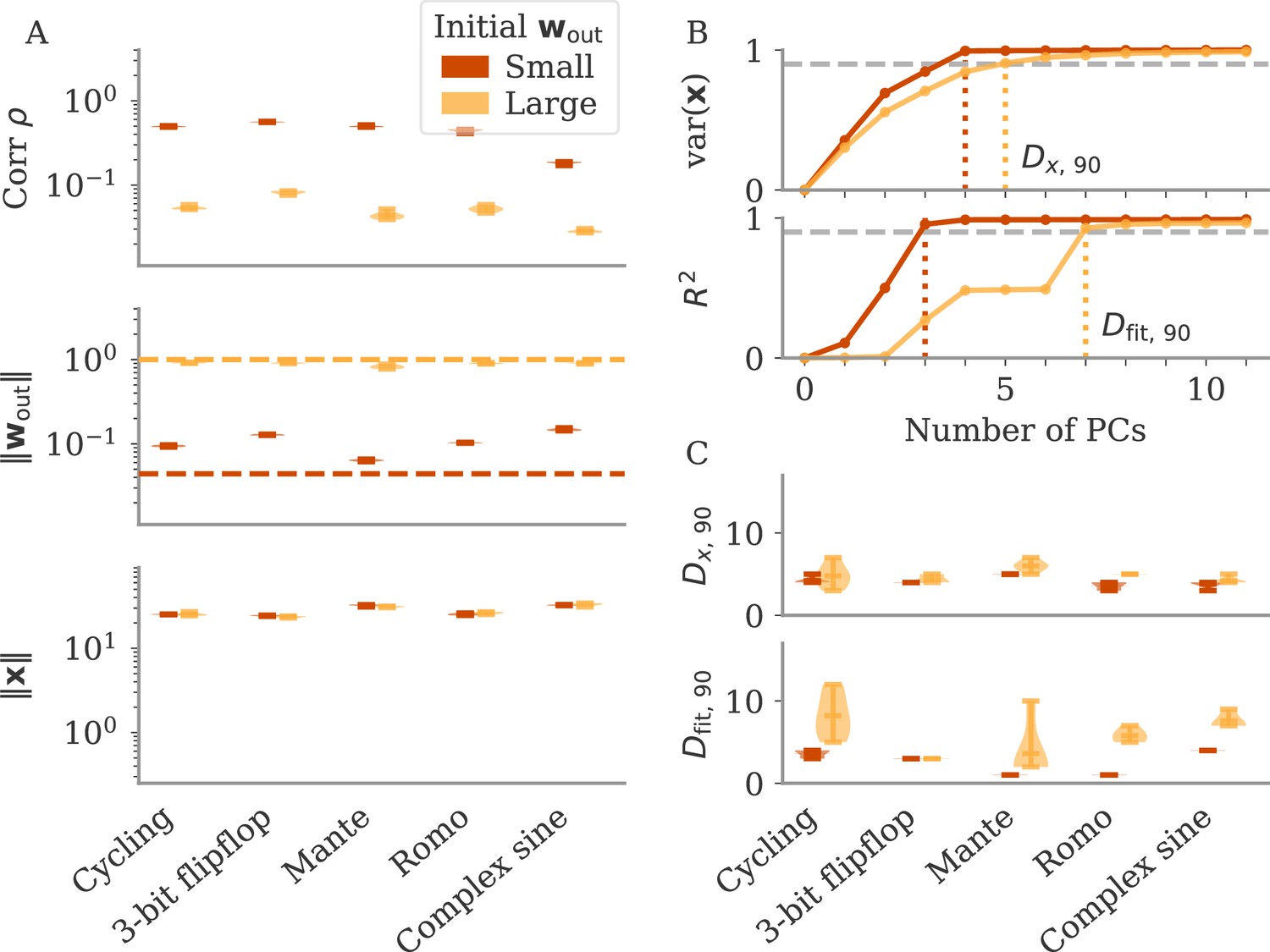
The magnitude of output weights determines regimes across multiple neuroscience tasks (Russo et al., 2018; Mante et al., 2013; Romo et al., 1999; Sussillo and Barak, 2013).
(A) Correlation and norms of output weights and neural activity. For each task, we initialized networks with small or large output weights (dark vs light orange). The initial norms are indicated by the dashed lines. Learning only weakly changes the norm of the output weights. Note that all y-axes are logarithmically scaled. (B) Variance of explained and of reconstructed output for projections of on increasing number of principal components (PCs). Results from one example network trained on the cycling task are shown for each condition. (C) Number of PCs necessary to reach 90% of the variance of or of the of the output reconstruction (top/bottom; dotted lines in B). In (A, C) violin plots show the distribution over five sample networks, with vertical bars indicating the mean and the extreme values (where visible).
In Figure 3B and C, we adopted the perspective of Figure 2C and quantified how well we can reconstruct the output from a projection of onto its largest PCs (section Regression). As expected, both the variance of explained and the quality of output reconstruction increased, for an increasing number of PCs (Figure 3B). How both quantities increased, however, differs between the two regimes. While the variance explained increased similarly in both cases, the quality of the reconstruction increased much more slowly for the model with large output weights. We quantified this phenomenon by comparing the dimensions at which either the variance of explained or reaches 90%, denoted by and , respectively.
In Figure 3C, we compare and across multiple networks and tasks. Generally, larger output weights led to larger numbers for both. However, for large output weights, the number of PCs necessary to obtain a good reconstruction increased much more drastically than the dimension of the data. Thus, the output was less well represented by the large PCs of the dynamics for networks with large output weights, in agreement with our notion of oblique dynamics.
Importantly, reaching the aligned and oblique regimes relies on ensuring robust and stable dynamics, which we achieve by adding noise to the dynamics during training. This yields a similar magnitude of neural activity across networks and tasks (Figure 3A). We show in Methods, section Analysis of solutions under noiseless conditions, that learning in simple, noise-free conditions with large output weights can lead to solutions not captured by either aligned or oblique dynamics; those solutions, however, are unstable. Furthermore, we observed that some of the qualitative differences between aligned and oblique dynamics are less pronounced if we initialized networks with small recurrent weights and initially decaying dynamics (Appendix 1—figure 2).
Neural dynamics decouple from the output for the oblique regime
What are the functional consequences of the two regimes? A hint might be seen in an intriguing qualitative difference between the aligned and oblique solutions for the cycling task in Figure 2. For the aligned network, the two trajectories for the two different contexts (green and purple) are counter-rotating (Figure 2B, top). This agrees with the output, which also counter-rotates as demanded by the task (Figure 2A). In contrast, the neural activity of the oblique network co-rotates in the leading two PCs (Figure 2B, bottom). This is despite the counter-rotating output, since this network also solves the task (not shown). The co-rotation also indicates why reconstructing the output from the leading two PCs is not possible (Figure 2C). Naturally, the dynamics also contain counter-rotating trajectories for producing the correct output, but these are only present in low-variance PCs. (Note also that for aligned networks, one can also observe co-rotation in low-variance PCs, see Appendix 1—figure 3.) Taken together, aligned and oblique dynamics differ in the coupling between leading neural dynamics and output. For aligned dynamics, the two are strongly coupled. For oblique dynamics, the two decouple qualitatively.
Such a decoupling for oblique, but not aligned, dynamics leads to a prediction regarding the universality of solutions (Maheswaranathan et al., 2019; Turner et al., 2021; Pagan et al., 2022). For aligned dynamics, the coupling implies that the internal dynamics are strongly constrained by the task. We thus expect different learners to converge to similar solutions, even if their initial connectivity is random and unstructured. In Figure 4A, we show the dynamics of three randomly initialized aligned networks trained on the cycling task, projected onto the three leading PCs. Apart from global rotations, the dynamics in the three networks are very similar.
Figure 4
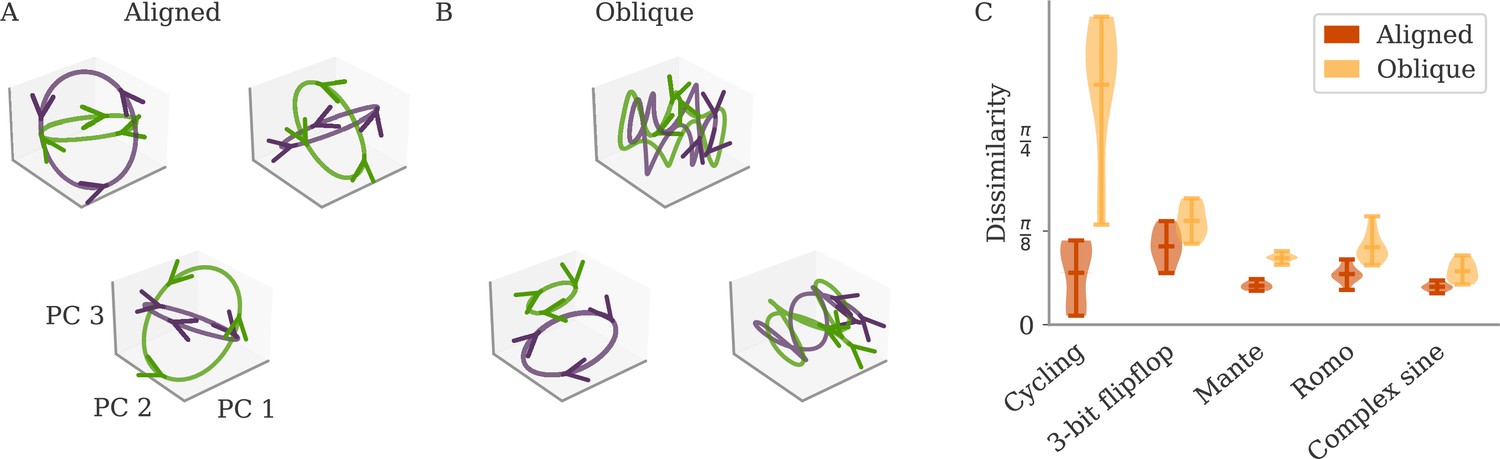
Variability between learners for the two regimes.
(A, B) Examples of networks trained on the cycling task with small (aligned) or large (oblique) output weights. The top left and central networks, respectively, are the same as those plotted in Figure 2. (C) Dissimilarity between solutions across different tasks. Aligned dynamics (red) were less dissimilar to each other than oblique ones (yellow). The violin plots show the distribution over all possible different pairs for five samples (mean and extrema as bars).
For oblique dynamics, the task-defined output exerts weaker constraints on the internal dynamics. Any variability experienced during learning can potentially build up, and eventually create qualitatively different solutions. Three examples of oblique networks solving the cycling tasks indeed show visibly different dynamics (Figure 4B). Further analysis shows that the models also differ in the frequency components in the leading dynamics (Appendix 1—figure 4).
The degree of variability between learners depends on the task. The observable differences in the PC projections were most striking for the cycling task. For the flip-flop task, for example, solutions were generally noisier in the oblique regime than in the aligned but did not have observable qualitative differences in either regime (Appendix 1—figure 5). We quantified the difference between models for the different neuroscience tasks considered before. To compare different neural dynamics, we used a dissimilarity measure invariant under rotation (section Dissimilarity measure) (Williams et al., 2021). The results are shown in Figure 4C. Two observations stand out: First, across tasks, the dissimilarity was higher for networks in the oblique regime than for those in the aligned. Second, both overall dissimilarity and the discrepancy between regimes differed strongly between tasks. The largest dissimilarity (for oblique dynamics) and the largest discrepancy between regimes was found for the cycling. The smallest discrepancy between regimes was found for the flip-flop task. Such a difference between tasks is consistent with the differences in the range of possible solutions for different tasks, as reported in Turner et al., 2021; Maheswaranathan et al., 2019.
What are the underlying mechanisms for the qualitative decoupling in oblique, but not aligned networks? For aligned dynamics, we saw that the small output weights demand large activity to generate the output. In other words, the activity along the largest PCs must be coupled to the output. For oblique dynamics, this constraint is not present, which opens the possibility for small components outside the largest PCs to generate the output. If this is the case, we have a decoupling, such as the observed co-rotation in the cycling task, and the possible variability between solutions. We discuss this point in more detail in the Methods, section Mechanisms behind decoupling of neural dynamics and output.
In the following two sections, we will explore how the decoupling between neural dynamics and output for oblique, but not aligned, dynamics influences the response to perturbations and the effects of noise during learning.
Differences in response to perturbations
Understanding how networks respond to external perturbations and internal noise requires some insight into how dynamics are generated. Dynamics of trained networks are mostly generated internally, through recurrent interactions. In robust networks, these internally generated dynamics are a prominent part of the largest PCs (among input-driven components; section Analysis of solutions under noiseless conditions and Oblique solutions arise for noisy, nonlinear systems). Internally generated dynamics are sustained by positive feedback loops, through which neurons excite each other. Those loops are low-dimensional, with activity along a few directions of the dynamics being amplified and fed back along the same directions. This results in dynamics being driven by effective feedback loops along the largest PCs (Figure 5A). As shown above, the largest PCs can either be aligned or not aligned, with the output weights. This leads to predictions about how aligned and oblique networks differentiate in their responses to perturbations along different directions.
Figure 5
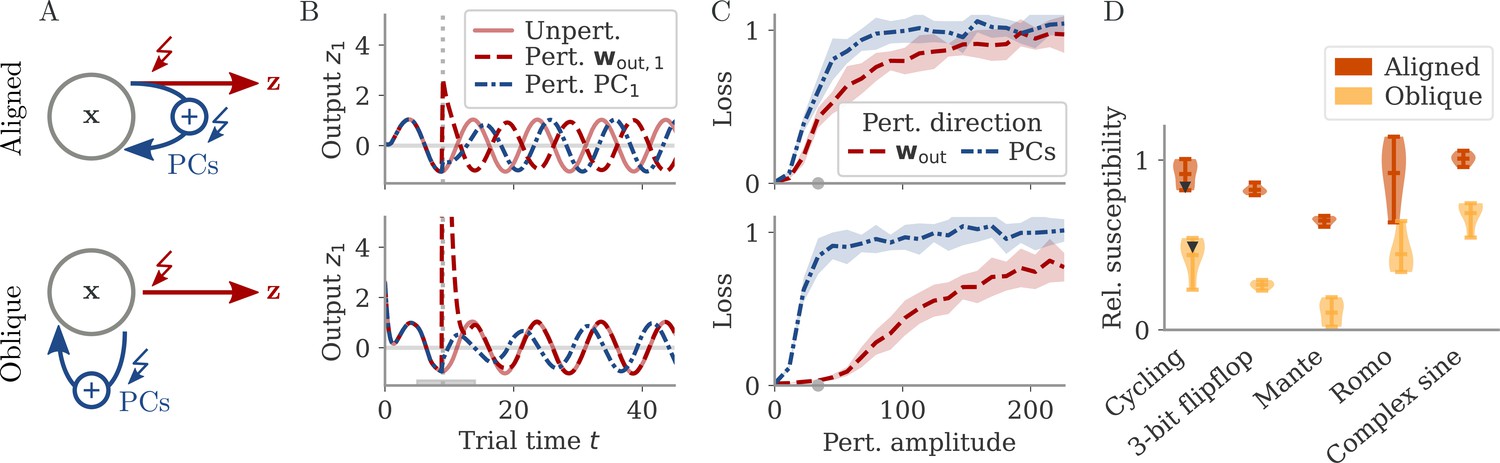
Perturbations differentially affect dynamics in the aligned and oblique regimes.
(A) Cartoon illustrating the relationship between perturbations along output weights or principal components (PCs) and the feedback loops driving autonomous dynamics. (B) Output after perturbation for aligned (top) and oblique (bottom) networks trained on the cycling task. The unperturbed network (light red line) yields a sine wave along the first output direction . At , a perturbation with amplitude is applied along the output weights (dashed red) or the first PC (dashed-dotted blue). The perturbations only differ in the directions applied. While the immediate response for the oblique network to a perturbation along the output weights is much larger, , the long-term dynamics yield the same output as the unperturbed network. See also Appendix 1—figure 6 for more details. (C) Loss for perturbations of different amplitudes for the two networks in (B). Lines and shades are means and standard deviations over different perturbation times and random directions spanned by the output weights (red) or the two largest PCs (blue). The loss is the mean squared error between output and target for . The gray dot indicates an example in (B). (D) Relative susceptibility of networks to perturbation directions for different tasks and dynamical regimes. We measured the area under the curve (AUC) of loss over perturbation amplitude for perturbations along the output weights of the two largest PCs. The relative susceptibility is the ratio between the two AUCs. The example in (C) is indicated by gray triangles.
Our intuition about feedback loops suggests that networks respond strongly to a perturbation that is aligned with the directions contributing to the feedback loop, but weakly to a perturbation that is orthogonal to them. In particular, if a perturbation is applied along the output weights, aligned and oblique dynamics should dissociate, with a strong disruption of dynamics for aligned, but not for oblique dynamics (Figure 5A).
To test this, we compare the response to perturbations along the output direction and the largest PCs. We apply perturbations to the neural activity at a single point in time: evolves undisturbed until time . At that point, it is shifted to . After the perturbation, we let the network evolve freely and compare this evolution to that of an unperturbed copy. Such a perturbation mimics a very short optogenetic perturbation applied to a selected neural population (O’Shea et al., 2022; Finkelstein et al., 2021). In Figure 5B, we show the output after such perturbations for an aligned (top) and an oblique network (bottom) trained on the cycling task. The time point and amplitude are the same for both directions and networks. For each network and type of perturbation, there is an immediate deflection and a long-term response. For both networks, perturbing along the PCs (blue) leads to a long-term phase shift. Only in the aligned network, however, perturbation along the output direction (red) leads to a visible long-term response. In the oblique network, the amplitude of the immediate response is larger, but the long-term response is smaller. Our results for the oblique network, but not for the aligned, agree with simulations of networks generating EMG data from the cycling experiments (Saxena et al., 2022).
To quantify the relative long-term susceptibility of networks to perturbations along output weights or PCs, we sampled from different times and different directions in the 2D subspaces spanned either by the two output vectors or by the two largest PCs. For each perturbation, we measured the loss of the perturbed networks on the original task (excluding the immediate deflection after the perturbation by starting to compute the loss at ). Figure 5C shows that the aligned network is almost equally susceptible to perturbations along the PCs and the output weights. In contrast, the oblique network is much more susceptible to perturbations along the PCs.
We repeated this analysis for oblique and aligned networks trained on the five different tasks. We computed the area under the curve (AUC) for both loss profiles in Figure 5C. We then defined the ‘relative susceptibility’ as the ratio , Figure 5D. For aligned networks (red), the relative susceptibility was close to 1 indicating similarly strong responses to both types of perturbations. For oblique networks (yellow), it was much smaller than 1, indicating that long-term responses to perturbations along the output direction were weaker than those to perturbations along the PCs.
Noise suppression for oblique dynamics
In the oblique regime, the output weights are large. To produce the correct output (and not a too large one), the large PCs of the dynamics are almost orthogonal to the output weights. The large output weights, however, pose a robustness problem: Small noise in the direction of the output weights is also amplified at the level of the readout. We show that learning leads to a slow process of sculpting noise statistics to avoid this effect (Figure 11). Specifically, a negative feedback loop is generated that suppresses fluctuations along the output direction (Figure 6A, Figure 10; Kadmon et al., 2020). Because the positive feedback loop that gives rise to the large PCs is mostly orthogonal to the output direction, it remains unaffected by this additional negative feedback loop. A detailed analysis of how learning is affected by noise shows that, for large output weights, the network first learns a solution that is not robust to noise. This solution is then transformed to increasingly stable and oblique dynamics over longer time scales (section Learning with noise for linear RNNs and Oblique solutions arise for noisy, nonlinear systems).
Figure 6
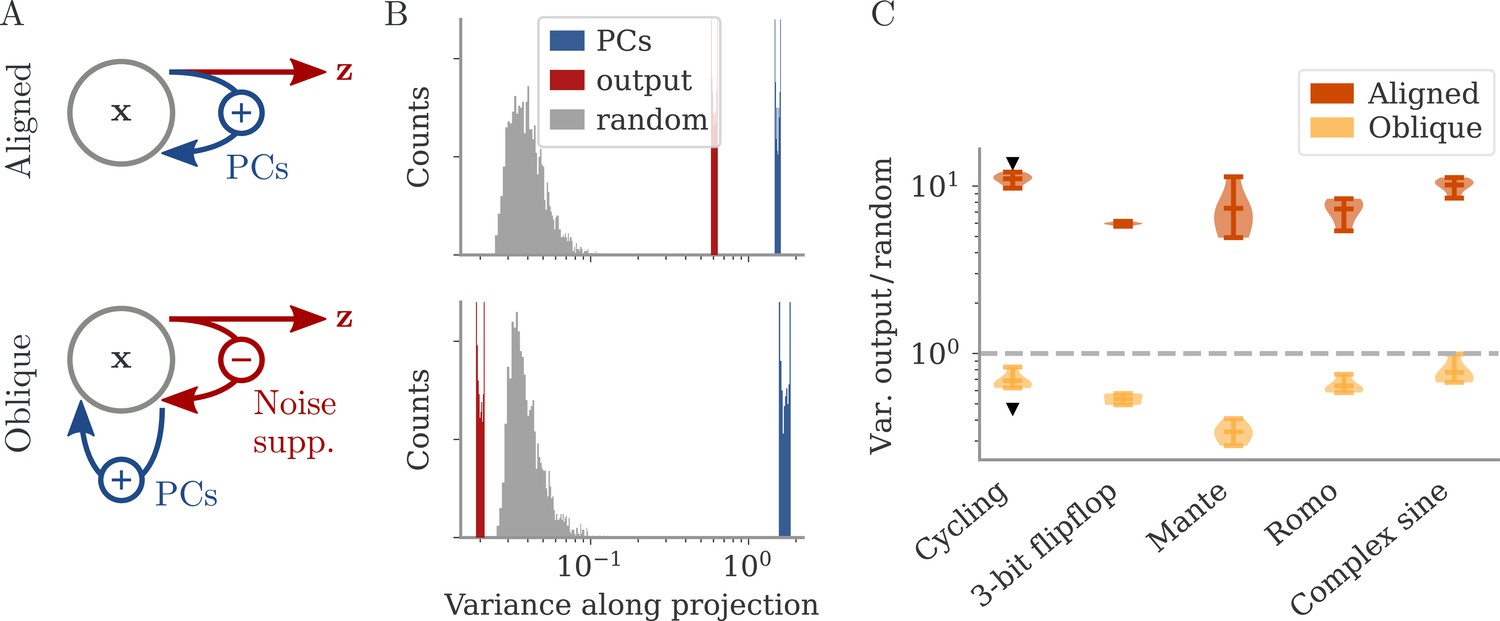
Noise suppression along the output direction in the oblique regime.
(A) A cartoon of the feedback loop structure for aligned (top) and oblique (bottom) dynamics. The latter develops a negative feedback loop which suppresses fluctuations along the output direction. (B) Comparing the distribution of variance of mean-subtracted activity along different directions for networks trained on the cycling task (see Appendix 1—figure 7): principal components (PCs) of trial-averaged activity (blue), readout (red), and random (gray) directions. For the PCs and output weights, we sampled 100 normalized combinations of either the first two PCs or the two output vectors. For the random directions, we drew 1000 random vectors in the full, -dimensional space. (C) Noise compression across tasks as measured by the ratio between variance along output and random directions. The dashed line indicates neither compression nor expansion. Black markers indicate the values for the two examples in (B, C). Note the log-scales in (B, C).
To illustrate the effect of the negative feedback loop, we consider the fluctuations around trial averages. We take a collection of states and then subtract the task-conditioned averages to compute . We then project onto three different direction categories: the largest PCs of the averaged data , the output directions, or randomly drawn directions.
How strongly the activity fluctuates along each direction is quantified by the variance of the projections (Figure 6B). For both aligned and oblique dynamics, the variance is much larger along the PCs than along random directions. This is not necessarily expected, because the PCA was performed on the averaged activity, without the fluctuations. Instead, it is a dynamical effect: the same positive feedback that generates the autonomous dynamics also amplifies the noise (section Oblique solutions arise for noisy, nonlinear systems).
The two network regimes, however, dissociate when considering the variance along the output direction. For aligned dynamics, there is no negative feedback loop, and is correlated with the PCs. The variance along the output direction is hence similar to that along the PCs, and larger than along random directions. For oblique dynamics, the negative feedback loop suppresses the fluctuations along the output direction, so that they become weaker than along random directions.
In Figure 6C, we quantify this dissociation across different tasks. We measured the ratio between variance along output and random directions. Aligned networks have a ratio much larger than one, indicating that the fluctuations along the output direction are increased due to the autonomous dynamics along the PCs. In contrast, oblique networks have a ratio smaller than 1 for all tasks, which indicates noise compression along the output.
Different degrees of alignment in experimental settings
For the cycling task, we observed that dynamics were qualitatively different for the two regimes, with trajectories either counter- or co-rotating (Figure 2B). Interestingly, the experimental results of Russo et al., 2018, matched the oblique, but not the aligned dynamics. The authors observed co-rotating dynamics in the leading PCs of motor cortex activity despite counter-rotating activity of simultaneously recorded muscle activity. Here, we test whether our theory can help to more clearly and quantitatively distinguish between the two regimes in experimental settings.
In typical experimental settings, we do not have direct access to output weights. We can, however, approximate these by fitting neural data to simultaneously recorded behavioral output, such as hand velocity in a motor control experiment (Figure 7A, top). Following the model above, where the output is a weighted average of the states, we reconstruct the output from the neural activity with linear regression. To quantify the dynamical regime, we then compute the correlation between the weights from fitting and the neural data. Additionally, we can also quantify the alignment by the ‘relative fitting dimension’ , where is the number of PCs necessary to recover the output and number to the number of PCs necessary to represent 90% of the variance of the neural data. We computed both the correlation and the relative fitting dimension for different publicly available data sets (Figure 7B). For details, see section Experimental data.
Figure 7
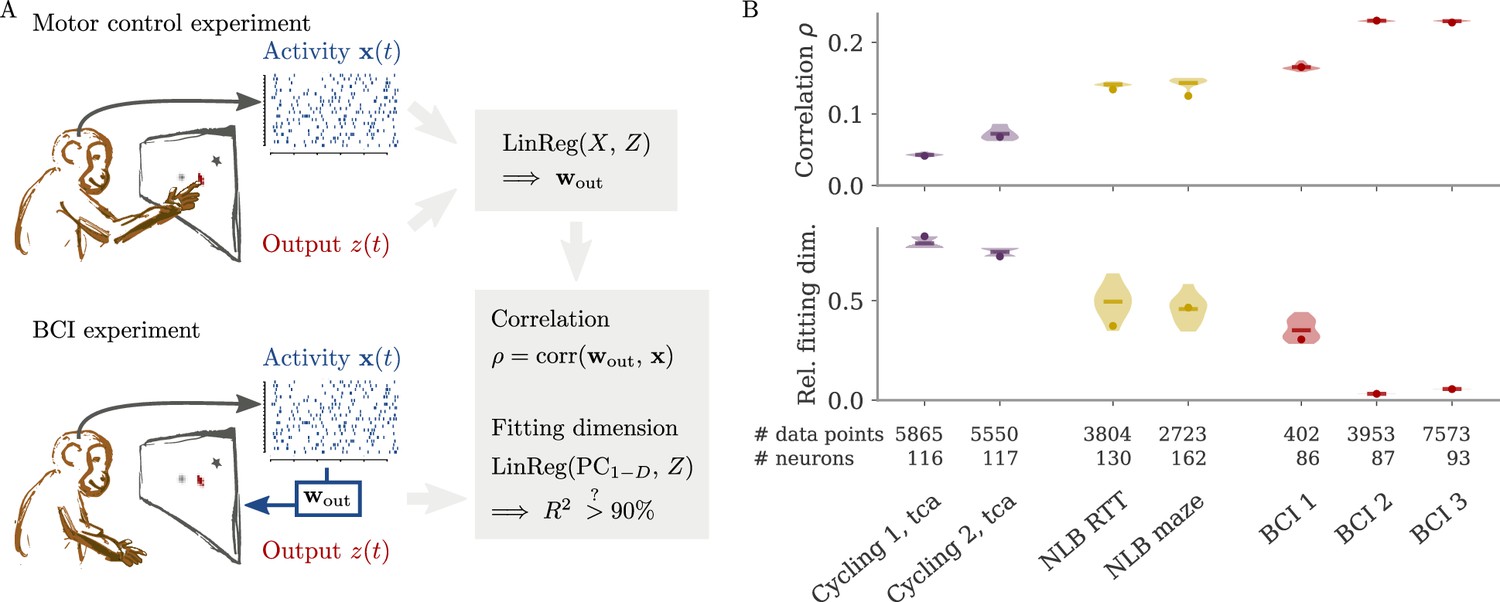
Quantifying aligned and oblique dynamics in experimental data (Russo et al., 2018; Pei et al., 2021; Golub et al., 2018; Hennig et al., 2018; Degenhart et al., 2020).
(A) Diagram of the two types of experimental data considered. Here, we always took the velocity as the output (hand, finger, or cursor). In motor control experiments (top), we first needed to obtain the output weights via linear regression. We then computed the correlation and the reconstruction dimension , i.e., the number of principal components (PCs) of necessary to obtain a coefficient of determination %. In brain-computer interface (BCI) experiments (bottom), the output (cursor velocity) is generated from neural activity via output weights defined by the experimenter. This allowed us to directly compute correlations and fitting dimensions. (B) Correlation (top) and relative fitting dimension (bottom) for several publicly available data sets. The cycling task data (purple) were trial-conditioned averages, the BCI experiments (red) and Neural Latents Benchmark (NLB) tasks (yellow) single-trial data. Results for the full data sets are shown as dots. Violin plots indicate results for 20 random subsets of 25% of the data points in each data set (bars indicate mean). See small text below x-axis for the number of time points and neurons.
We started with data sets from two monkeys performing the cycling task (Russo et al., 2018). The data contained motor cortex activity, hand movement, and EMG from the arms, all averaged over multiple trials of the same condition. In Figure 7B, we show results for reconstructing the hand velocity. The correlation was small, . To obtain a good reconstruction, we needed a substantial fraction of the dimension of the neural data: The relative fitting dimension was . Our results agree with previous studies, showing that the best decoding directions are only weakly correlated with the leading PCs of motor cortex activity (Schroeder et al., 2022).
We also analyzed data made available through the Neural Latents Benchmark (NLB) (Pei et al., 2021). In two different tasks, monkeys needed to perform movements along a screen. In a random target task, the monkeys had to point at a randomly generated target position on a screen, with a successive target point generated once the previous one was reached (Makin et al., 2018). In a maze task, the monkeys were trained to follow a trajectory through a maze with their hand (Churchland et al., 2010). In both cases, we reconstructed the finger or hand velocity from neural activity on single trials. The correlation was higher than in the cycling task, . The relative fitting dimension was lower than in the trial-averaged cycling data, albeit still on the same order: .
Finally, we considered brain-computer interface (BCI) experiments (Sadtler et al., 2014). In these experiments, monkeys were trained to control a cursor on a screen via activity read out from their motor cortex (Figure 7A, bottom). The output weights generating the cursor velocity were set by the experimenter (so we don’t need to fit). Importantly, the output weights were typically chosen to be spanned by the largest PCs (the ‘neural manifold’), suggesting aligned dynamics. For three example data sets (Golub et al., 2018; Hennig et al., 2018; Degenhart et al., 2020), we obtained higher correlation values, (Figure 7B). The relative fitting dimension was much smaller than for the non-BCI data sets, especially for the two largest data sets, where .
The higher correlation and much smaller relative fitting dimension suggest that, indeed, the neural dynamics arising in BCI experiments are more aligned, and those in non-BCI settings are more oblique. These trends also hold when decoding other behavioral outputs for the cycling task and the NLB tasks (position, acceleration, or EMG), even if the ability to decode and the numerical values for correlation and fitting dimension may fluctuate considerably (Appendix 1—figure 8). Thus, while we do not observe strongly different regimes as in the simulations, we do see an ordering between different data sets according to the alignment between outputs and neural dynamics. It would be interesting to test the differences between BCI and non-BCI data on larger data sets, and different experiments with different dimensions of neural data (Gao et al., 2017; Stringer et al., 2019a).
Discussion
We analyzed the relationship between neural dynamics and behavior, asking to which extent a network’s output is represented in its dynamics. We identified two different limiting regimes: aligned dynamics, in which the dominant activity in a network is related to its output, and oblique dynamics, where the output is only a small modulation on top of the dominating dynamics. We demonstrated that these two regimes have different functional implications. We also examined how they arise through learning, and how they relate to experimental findings.
Linking neural activity to external variables is one of the core challenges of neuroscience (Hubel and Wiesel, 1962). In most cases, however, such links are far from perfect. The activity of single neurons can be related in a nonlinear, mixed manner, to task variables (Rigotti et al., 2013). Even when considering populations of neurons, a large fraction of neural activity is not easily accounted for by external variables (Arieli et al., 1996). Various explanations have been proposed for this disconnect. In the visual cortex, activity has been shown to be related to ‘irrelevant’ external variables, such as body movements (Stringer et al., 2019b). Follow-up work showed that, in primates, some of these effects can be explained by the induced changes on retinal images (Talluri et al., 2022), but this study still explained only half of the neural variability. An alternative explanation hinges on the redundancy of the neural code, which allows ‘null spaces’ in which activity can visit without affecting behavior (Rokni et al., 2007; Kaufman et al., 2014; Kao et al., 2021). Through the oblique regime, our study offers a simple explanation for this phenomenon: in the presence of large output weights, resistance to noise or perturbations requires large, potentially task-unrelated neural dynamics. Conversely, generating task-related output in the presence of large, task-unrelated dynamics requires large readout weights.
We showed theoretically and in simulations that, when training RNNs, the magnitude of output weights is a central parameter that controls which regime is reached. This finding is vital for the use of RNNs as hypothesis generators (Sussillo, 2014; Barak, 2017; Vyas et al., 2020), where it is often implicitly assumed that training results in universal solutions (Maheswaranathan et al., 2019) (even though biases in the distribution of solutions have been discussed; Sussillo et al., 2015). Here, we show that a specific control knob allows one to move between qualitatively different solutions of the same task, thereby expanding the control over the hypothesis space (Turner et al., 2021; Pagan et al., 2022). Note in particular that the default initialization in standard learning frameworks has large output weights, which results in oblique dynamics (or unstable solutions if training without noise, see Methods, section Analysis of solutions under noiseless conditions).
The role of the magnitude of output weights is also discussed in machine learning settings, where different learning regimes have been found (Jacot et al., 2018; Chizat et al., 2019; Mei et al., 2018; Jacot et al., 2022). In particular, ‘lazy’ solutions were observed for large output weights in feedforward networks. We show in Methods, section Analysis of solutions under noiseless conditions, that these are unstable for recurrent networks and are replaced in a second phase of learning by oblique solutions. This second, slower, phase is reminiscent of implicit regularization in overparameterized networks (Ratzon et al., 2024; Blanc et al., 2020; Li et al., 2021; Yang et al., 2023). On a broader scale, which learning regime is relevant when modeling biological learning is an open question that has only just begun to be explored (Flesch et al., 2022; Liu et al., 2023).
The particular control knob we studied has an analog in the biological circuit – the synaptic weights. We can thus use experimental data to study whether the brain might rely on oblique or aligned dynamics. Existing experimental work has partially addressed this question. In particular, the work by Russo et al., 2018, has been a major inspiration for our study. Our results share some of the key findings from that paper – the importance of stability leading to ‘untangled’ dynamics (Susman et al., 2021) and a dissociation between hidden dynamics and output. In addition, we suggest a specific mechanism to reach oblique dynamics – training networks with large output weights. Furthermore, we characterize the aligned and oblique regimes along experimentally accessible axes.
We see three avenues for exploring our results experimentally. First, simultaneous measurements of neural dynamics and muscle activity could be used to quantify noise along the output direction. This would allow checking whether noise is compressed in this direction, and in particular, whether such compression occurs on a slow time scale after initial task acquisition. We suggest how to test this in Figure 6C. Second, we show how the dynamical regimes dissociate under perturbations along specific directions. Experiments along these lines have recently become possible (Russell et al., 2022; Finkelstein et al., 2021; Chettih and Harvey, 2019). Future work is left to combine our model with biological constraints that induce additional effects during perturbations, e.g., through non-normal synaptic connectivity (O’Shea et al., 2022; Kim et al., 2023; Bondanelli and Ostojic, 2020; Logiaco et al., 2021). Third, our work connects to the setting of BCI, where the experimenter chooses the output weights at the beginning of learning (Sadtler et al., 2014; Golub et al., 2018; Willett et al., 2021; Rajeswaran et al., 2024). Typically, the output weights are set to lie ‘within the manifold’ of the leading PCs so that we expect aligned dynamics (Sadtler et al., 2014). In experiments where the output weights were rotated out of the manifold (without changing the norm), learning took longer and led to a rotation of the manifold, i.e., at least a partial alignment (Oby et al., 2019). Our theory suggests directly comparing the degree of alignment between dynamics obtained from within- and out-of-manifold initializations. Furthermore, it would be interesting to systematically change the norm of the output weights (in particular for out-of-manifold initializations) to see whether larger output weights lead to more oblique solutions. If this is the case, we suggest testing whether such more oblique solutions meet our predictions, e.g., higher variability between individuals and noise suppression.
Overall, our results provide an explanation for the plethora of relationships between neural activity and external variables. It will be interesting to see whether future studies will find hallmarks of either regime for different experiments, tasks, or brain regions.
Methods
Details on RNN models and training
We consider rate-based RNNs with neurons. The states are governed by
(4)
where is a recurrent weight matrix and a nonlinearity applied element-wise. The network receives a low-dimensional input via input weights . It is also driven by white, isotropic noise with zero mean and covariance . The initial states are drawn from a centered normal distribution with variance at each trial. This serves as additional noise. The output is a low-dimensional, linear projection of the states: with .
The initial output weights are drawn from centered normal distributions with variance . ‘Small’ output weights refer to , and ‘large’ ones to . We have at initialization. Note that large initial output weights are the current default in standard learning environments (Paszke et al., 2017; Yang and Hu, 2020). The recurrent weights were initialized from centered normal distributions with variance . We chose so that dynamics were chaotic before learning (Sompolinsky et al., 1988).
To simulate the noisy RNN dynamics numerically, we used the Euler-Maruyama method (Kloeden and Platen, 1992) with a time step of . We used the Adam algorithm (Kingma and Ba, 2014) implemented in PyTorch (Paszke et al., 2017). Apart from the learning rate, we kept the parameters for Adam at the default (some filtering, no weight decay). We selected learning rates and the number of training steps such that learning was relatively smooth and converged sufficiently within the given number of trials. Learning rates were set to . Details for all simulation parameters can be found in Table 1.
Table 1
Task, simulation, and network parameters for Figures 3—6.
| Parameter | Symbol | Cycling | Flip-flop | Mante | Romo | Complex sine |
|---|---|---|---|---|---|---|
| # inputs | 2 | 3 | 4 | 1 | 1 | |
| # outputs | 2 | 3 | 1 | 1 | 1 | |
| Trial duration | 72 | 25 | 48 | 29 | 50 | |
| Fixation duration | 0 | 3 | 0 | |||
| Stimulus duration | 1 | 1 | 20 | 1 | 50 | |
| Stimulus delay | – | – | – | |||
| Decision delay | 1 | 2 | 5 | 4 | 0 | |
| Decision duration | 71 | 20 | 8 | 50 | ||
| Simulation time step | – 0.2 – | |||||
| Target time step | 1.0 | 1.0 | 1.0 | 1.0 | 0.2 | |
| Activation noise | 0.2 | 0.2 | 0.05 | 0.2 | 0.2 | |
| Initial state noise | – 1.0 – | |||||
| Network size | – 512 – | |||||
| # training epochs | 1000 | 4000 | 4000 | 6000 | 6000 | |
| Learning rate aligned | 0.02 | 0.005 | 0.002 | 0.005 | 0.005 | |
| Learning rate oblique | 0.02 | 0.01 | 0.02 | 0.01 | 0.005 | |
| Batch size | – 32 – | |||||
For the comparisons over different tasks (Figures 3—6), we trained five networks for each task. All weights () were adapted. For the example networks trained on the cycling task (Figures 2, 5, and 6), we used networks with neurons and only changed the recurrent weights . We also trained for longer (5000 training steps) and with a higher learning rate ().
Task details
The tasks the networks were trained on are taken from the neuroscience literature: a cycling task (Russo et al., 2018), a 3-bit flip-flop task, and a ‘complex sine’ task (with input-dependent frequencies) (Sussillo and Barak, 2013), a context-dependent decision-making task (‘Mante’) (Mante et al., 2013; Schuessler et al., 2020a), and a working memory task comparing the amplitudes of two pulse stimuli (‘Romo’) (Romo et al., 1999; Schuessler et al., 2020a). All tasks have similar structure (Schuessler et al., 2020b): A trial of length starts with a fixation period (length ). This is followed by an input for . For the cycling and flip-flop task, the inputs are pulses of amplitude 1; else see below. After a delay , the output of the network is required to reach an input-dependent value during a time period . During this decision period, we set target points every time steps. The loss was defined as the mean squared error between network output and target at these time points. Below, we provide further details for each task.
Cycling task
The network receives an initial pulse, whose direction ( or ) determines the sense of direction of the target. The target is given by a rotation in 2D, , with frequency and for the two directions (clockwise or anticlockwise).
Flip-flop task
The network repeatedly receives input pulses along one of three directions, followed by decision periods. In each decision period, the output coordinate corresponding to the last input should reach ±1 depending on the sign of the input. All other coordinates should remain at ±1 as defined by the last time they were triggered. To make sure that this is well defined, we trigger all inputs at time steps for with random signs.
Mante task
Input channels for this task are split into two groups of size : half of the channels for the signal and the other half for the context, indicating which of the signal channels is relevant. All signal channels deliver a constant mean plus additional white noise: . The mean is drawn uniformly from , and the noise amplitude is . For simulations, we draw a standard normal variable at time step , and set . Only a single contextual input is active at each trial, , with chosen uniformly from the number of context . The target during the decision period is the sign of the relevant input, .
Romo task
For the Romo task, the input consists of two input pulses separated by random delays . The amplitude of the inputs is drawn independently from with the condition of being at least 0.2 apart (else both are redrawn). During the decision period, the network needs to yield , depending on which of the two pulses was larger.
Complex sine
The target is , with frequency , and boundaries , and where . The input is a constant input of amplitude .
Generalized correlation
For Figure 3A, we used a generalized correlation measure which allows for multiple output dimensions, multiple time points, and noisy data. Consider neural activity of neurons at time points stacked into the matrix . We assume the states to be centered in time, for . The corresponding -dimensional output is summarized in the matrix
(5)
with weights . We define the generalized correlation as
(6)
The norm is the Frobenius norm, . In particular, we have
(7)
The case of 1D output and a single time step discussed in the main text, Equation 3, is recovered up to the sign, which we discard. Note that in that case, the vectors and should be centered along coordinates to receive a valid correlation. Our numerical results did not change qualitatively when centering across coordinates only or both coordinates and time.
For trajectories with multiple conditions, we stack these instances in a matrix , with the number of conditions, and the number of time points per trajectory. For noisy trajectories, we first average over multiple instances per condition and time point to obtain a similar matrix .
Regression
In Figure 3B and C we computed the number of PCs necessary to either represent the dynamics or fit the output. We simulated the trained networks again on their corresponding tasks. We did not apply noise during these simulations, since keeping the same noise as during training would reduce the quality of the output for large output weights; trial averaging yielded similar results to the ones obtained without noise (not shown).
The simulations yielded neural states and outputs , where is the number of data points (batch size times number of time points ). We applied PCA to the states . The cumulative explained variance ratio obtained from PCA is plotted in Figure 3B. We then projected onto the first PCs and fitted these projections to the output with ridge regression (cross-validated, using scikit-learn’s RidgeCV Pedregosa et al., 2011).
Dissimilarity measure
For measuring the dissimilarity between learners in Figure 4, we apply a measure following Williams et al., 2021. We define the distance between two sets with data points as
(8)
where the hat corresponds to centering along the rows, and is an orthogonal matrix. The solution to this so-called orthogonal Procrustes’ problem is found via the singular value decomposition . The optimal transformation is , and the numerator in Equation 8 is then .
Note that this is more restricted than canonical correlation analysis (CCA), which is also commonly used (Gallego et al., 2018; Gallego et al., 2020). In particular, CCA involves whitening the matrices and before applying a rotation (Williams et al., 2021). This sets all singular values to 1. For originally low-D data, this mostly means amplifying the noise, unless the data was previously projected onto a small number of PCs. In the latter case, the procedure still removes the information about how much each PC contributes.
Experimental data
We detail the analyses of neural data in section Different degrees of alignment in experimental settings. We made use of publicly available data sets: data from the cycling task of Russo et al., 2018, two data sets available through the NLB (Pei et al., 2021), and data from monkeys trained on a center-out reaching task with a BCI (Golub et al., 2018; Hennig et al., 2018; Degenhart et al., 2020). For all data sets, we first obtain firing rates , where is the number of measured neurons, and the number of data points, (see Figure 7B for these numbers). We also collect the simultaneously measured behavior in the matrix . In Figure 7, we only analyzed cursor or hand velocity for behavior, so that the output dimension is . See Appendix 1—figure 8 for similar results for hand position and acceleration or the largest two PCs of the EMG data recorded for the cycling task.
For the cycling task, the firing rates were binned in 1 ms bins and convolved with a 25 ms Gaussian filter. The mean firing rate was 22 and 18 Hz for the two monkeys, respectively. For the NLB data, spikes came in 1 ms bins. We binned data to 45 ms bins and applied a Gaussian filter with 45 ms width. This increased the quality of the fit, as firing rates were much lower (mean of 5 Hz for both) than in the cycling data set. For the BCI experiments, firing rates came as spike counts in 45 ms bins. The mean firing rate was (45, 45, 55) Hz for the data of Golub et al., 2018; Hennig et al., 2018; Degenhart et al., 2020, respectively. In agreement with the original BCI experiments, we did not apply a filter to the neural data.
For fitting, we centered both firing rates and output across time (but not coordinates). We also added a delay of 100 ms between firing rates and output for the cycling and NLB data sets, which increased the quality of the fits. We then fitted the output to the firing rates with ridge regression, with regularization obtained from cross-validation. We treated the coefficients as output weights . The trial average data of the cycling tasks was very well fitted for both monkeys, . For the NLB tasks with single-trial data, the fits were not as good, . For two of the BCI data sets (Golub et al., 2018; Hennig et al., 2018), the output weights were also given, and we checked that the fit recovers these. For the third BCI data set (Degenhart et al., 2020), we did not have access to the output weights, and only access to the cursor velocity after Kalman filtering. Here, fitting yielded .
For the fitting dimension in Figure 7B, bottom, we used an adapted definition of : Because % is not reached for all data sets, we asked for the number of PCs necessary to obtain 90% of the value obtained for the full data set.
We also considered whether the correlation scales with the number of neurons . In our model, oblique and aligned dynamics can be defined in terms of such a scaling: aligned dynamics have highly correlated output weights and low-dimensional dynamics, so that , i.e., independent of the network size. For oblique dynamics, large output weights with norm lead to vanishing correlation, . This is indeed similar to the relation between two random vectors, for which the correlation is precisely (in the limit of large ). In Figure 8, we show the scaling of and with the number of subsampled neurons. For the cycling task and NLB data, the correlation scaled slightly weaker than . For the BCI data, the scaling was closer to which is in between the aligned and oblique regimes of the model. These insights, however, are limited due to the trial averaging for the cycling task and the limited number of time points for the NLB tasks (not enough to reach ). Applying these measures to larger data sets could yield more definitive insights.
Figure 8
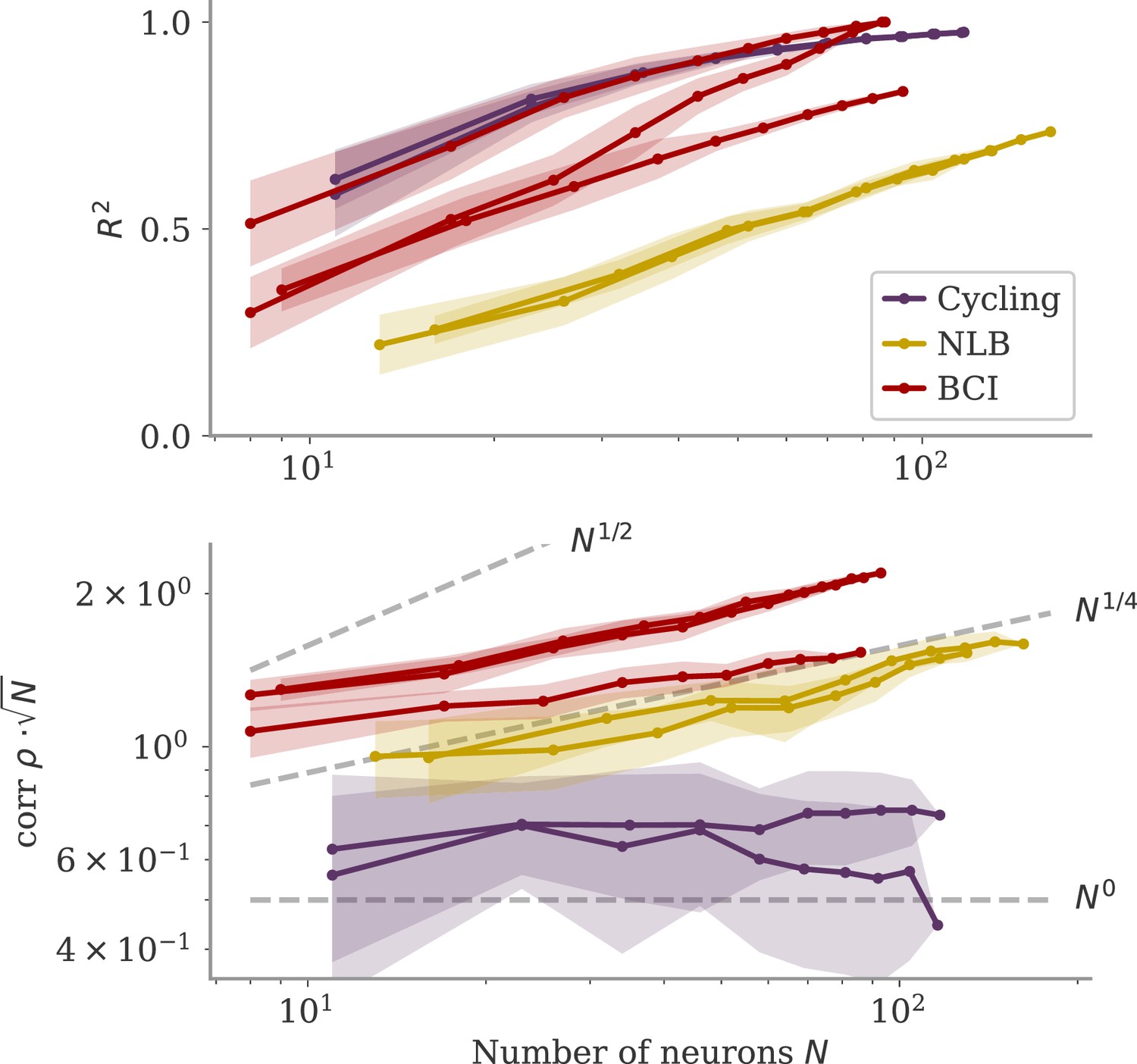
Correlation scaling with number of neurons.
Scaling of the correlation with the number of neurons in experimental data. We fitted the output weights to subsets of neurons and computed the quality of fit (top) and the correlation between the resulting output weight and firing rates (bottom). To compare with random vectors, the correlation is scaled by . Dashed lines are , for for comparison. The aligned regime corresponds to , and the oblique one to .
Analysis of solutions under noiseless conditions
In the sections below, we explore in detail under which conditions aligned and oblique solutions arise, and which other solutions arise if these conditions are not met.
We first consider small output weights and show that these lead to aligned solutions. Then, for large output weights, we show that without noise, two different, unstable solutions arise. Finally, we consider how adding noise affects learning dynamics. For a linear model, we can solve the dynamics of learning analytically and show how a negative feedback loop arises, that suppresses noise along the output direction. However, the linear model does not yield an oblique solution, so we also consider a nonlinear model for which we show in detail why oblique solutions arise.
We start by analyzing a simplified version of the network dynamics (Equation 4): autonomous dynamics without noise,
(9)
with fixed initial condition . We assume a 1D output and a target defined on a finite set of time points .
We illustrate the theory with an example of a simple sine wave task (Figure 9). We demand the network to autonomously produce a sine wave with fixed frequency . At the beginning of the task, the network receives an input pulse that sets the starting point of the trajectory. We set the noise on the initial state to zero. We define the target as 20 target points in the interval (two cycles; purple dots in Figure 9).
Figure 9
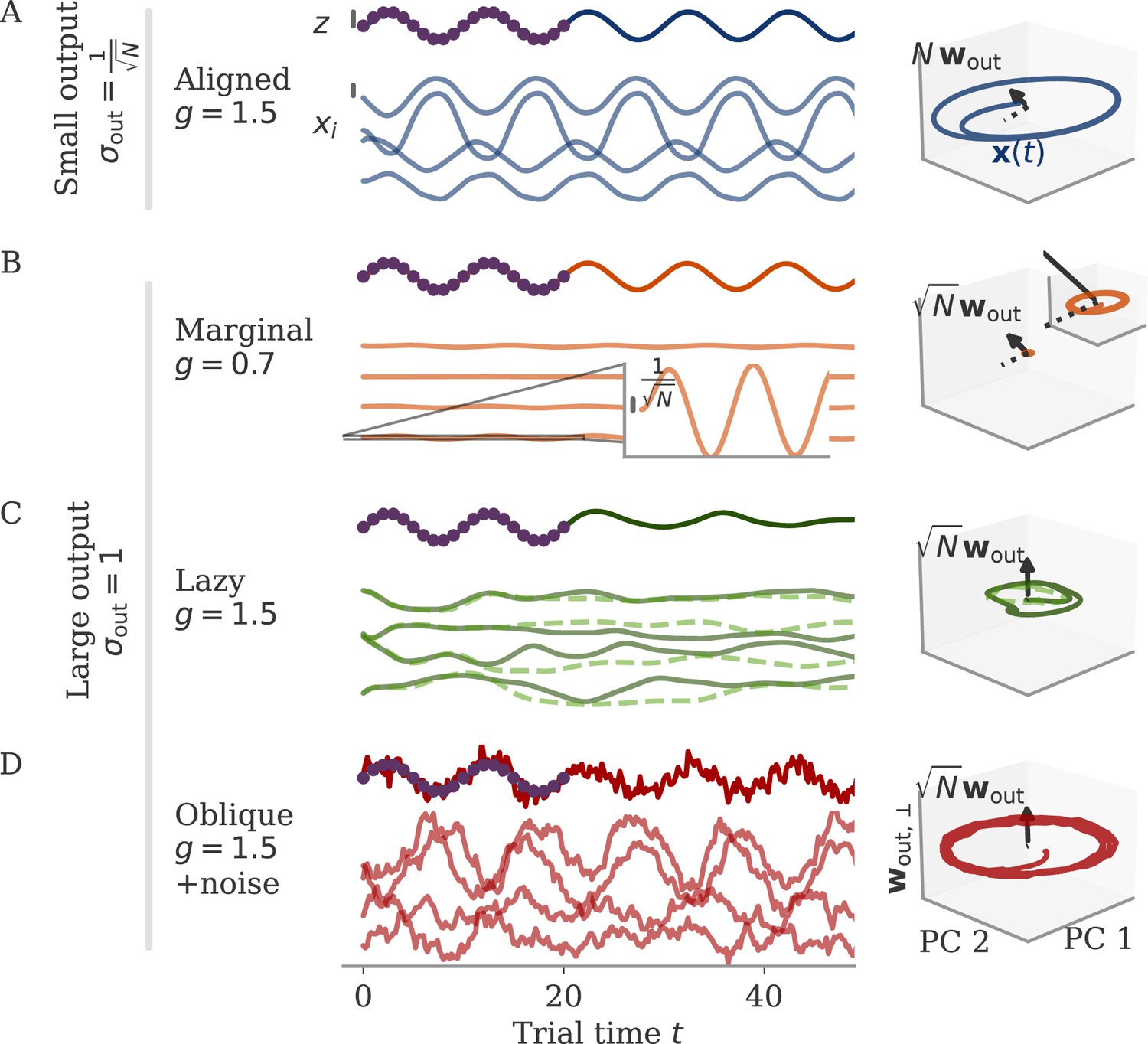
Different solutions for networks trained on a sine wave task.
All networks have neurons. Four regimes: (A) aligned for small output weights, (B) marginal for large output weights, small recurrent weights, (C) lazy for both large output and recurrent weights, (D) oblique for large output weights and noise added during training. Left: Output (dark), target (purple dots), and four states (light) of the network after training. Black bars indicate the scales for output and states (length = 1; same for all regimes). The output beyond the target interval can be considered as extrapolation. The network in the oblique regime, (D), receives white noise during training, and the evaluation is shown with the same noise. Without noise, this network still produces a sine wave (not shown). Right: Projection of states on the first two principal components (PCs) and the orthogonal component of the output vector. All axes have the same scale, which allows for comparison between the dynamics. Vectors show the (amplified) output weights, dotted lines the projection on the PCs (not visible for lazy and oblique). The insets for the marginal solution (B, left and right) show the dynamics magnified by .
Small weights lead to aligned solutions
For small output weights, , gradient-based learning in such a noise-less system has been analyzed by Schuessler et al., 2020b. Learning changes the dynamics qualitatively through low-rank weight changes . These weight changes are spanned by existing directions such as the output weights. The resulting dynamics are thus aligned to the output weights. This means that the correlation between the two is large, independent of the network size, . The target of the task is also independent of , so that after learning we have . Given the small output weights, we can thus infer the size of the states:
(10)
so that , or equivalently single neuron activations . This scaling corresponds to the aligned regime.
For the sine wave task, training with small output weights converges to an intuitive solution (Figure 9A). Neural activity evolves on a limit cycle, and the output is a sine wave that extrapolates beyond the training interval. Plotting activity and output weights along the largest two PCs and the remaining direction confirms substantial correlation, , as expected. The solution was robust to adding noise after training (not shown). Changes in the initial dynamics or the presence of noise during training did not lead to qualitatively different solutions (Appendix 1—figure 10). A further look at the eigenvalue spectrum of the trained recurrent weights revealed a pair of complex conjugate outliers corresponding to the limit cycle (Mastrogiuseppe and Ostojic, 2018; Schuessler et al., 2020a), and a bulk of remaining eigenvalues concentrated on a disk with radius , Appendix 1—figure 9.
Large weights, no noise: linearization of dynamics
We now consider learning with large output weights, , for noise-less dynamics, Equation 9. We start with the assumption that the activity changes for each neuron are small, , or . Here, , where is the activity before learning. To perform a task, learning needs to induce output changes to reach the target . Note that a possible order-one initial output must also be compensated. Together with the output weight scale, we arrive at
(11)
where . This shows that our assumption of small state changes is consistent – it allows for a solution – and that such small changes need to be strongly correlated to the output weights. Note that we make the distinction between the changes and the final activity , because the latter may be dominated by . In the main text, we only consider the correlation between and , because (as we show below) solutions with small are not robust, and the final will be dominated by .
For now, however, we ignore robustness and continue with the assumption of small . Given this assumption, we linearize the dynamics around the initial trajectory :
(12)
with diagonal matrix and the weights changes that induce . Note that we haven’t yet constrained the weight changes so we cannot discard the terms of the kind . The next steps depend on the initial trajectories .
Initially decaying dynamics lead to a marginal regime
We first consider networks with decaying dynamics before learning. This is obtained by drawing the initial recurrent weights independently from , with (Sompolinsky et al., 1988). With such dynamics, vanishes exponentially in time. In Equation 12, we disregard the term and have , so that
(13)
To have self-sustained dynamics, the matrix must have a leading eigenvalue with real part above the stability line: .
The distance must be small, else the states would become large. To understand how needs to scale with , we turn to a simple model studied before (Mastrogiuseppe and Ostojic, 2018; Schuessler et al., 2020a): an autonomously generated fixed point and rank-one connectivity . The vector has entries . A fixed point of the dynamics (Equation 9) fulfills . Projecting on and applying partial integration in the limit , we obtain
(14)
where , with standard normal measure . Here, is the scale of the states, or . The fixed point is situated along the vector . To have the smallest possible fixed point generate some output, we set the output weights to . Then, we have correlation and . In other words, a small fixed point with . We expand in Equation 14 around zero. For even , we have and
(15)
Sigmoidal functions have , e.g., for . Hence , with . Remarkably, the perturbation leading to states with only needs to have a distance away from the stability line.
The insights from this simplified setting extend to the example of the sine wave task (Figure 9B). The model with large output weights, , and no noise yields a limit cycle. The output extrapolates in time, but the states are very small, scaling as (analysis over different not shown). Such a solution is only marginally stable – adding a white noise with after training destroyed the rotation (not shown). The eigenvalues were again split into two outliers and a bulk (Appendix 1—figure 9). However, the two outliers now had a real part , i.e., they were very close to the stability line of the fixed point at zero. To better illustrate the marginal solution, we also set the initial state to small values, . For , there would be an initial decay much larger than the limit cycle.
Initially chaotic dynamics lead to a lazy regime
In contrast to the situation before, initially chaotic dynamics (for ) imply order-one initial states, for all trial times . The driving term in Equation 12 can thus not be ignored and we expect it to be on the same scale as :
(16)
The smallest possible weight changes will be those for which yields a maximal response, but other vectors do not yield a strong response. This is captured by the operator norm, . We can then write , and hence . The operator norm also bounds the eigenvalues and hence the effect of the matrix on the dynamics of the system. For large , this implies that the changes are too small to change the dynamics qualitatively, and the latter remain chaotic. Note that because the network dynamics are chaotic, the term in Equation 12 diverges, so that our discussion is only valid for short times. Numerically, we find small weight changes and chaotic solutions even for large target times (not shown).
For the sine wave task, the network with initially chaotic dynamics indeed converges to such a solution (Figure 9C). The output does not extrapolate beyond the training interval , and dynamics remain qualitatively similar to those before training. During the training interval, the dynamics also remain close to the initial trajectories (dashed line). Testing the response to small perturbations in indicated that the dynamics remain chaotic (not shown). No limit cycle was formed, and the spectrum of eigenvalues did not show outliers (Appendix 1—figure 9).
We called this regime ‘lazy’, following similar settings in feedforward networks (Jacot et al., 2018; Chizat et al., 2019). Note that there, the output is linearized around the weights at initialization (as opposed to the dynamics, Equation 9). This can be done in our case as well:
(17)
Demanding yields a linear equation for each time point . As we have parameters, this system is typically underconstrained. Gradient descent for this linear system leads to the minimal norm solution, which can also be found directly using the Moore-Penrose pseudo-inverse. Numerically, we found that the weights obtained by this linearization are very close to those found by gradient descent (GD) on the nonlinear system, , with Frobenius norm (section Linear approximation for lazy learning).
Marginal and lazy solutions disappear with noise during training
The deduction above hinges on the assumption that is small. This assumption does not hold if dynamics are noisy, Equation 4. For marginal dynamics, the noise would push solutions to different attractors or different positions along the limit cycle. For lazy dynamics, the chaotic dynamics would amplify any perturbations along the trajectory (if chaos persists under noise; Schuecker et al., 2018).
We will explore how learning is affected by noise in the sections below. Here, we only show that adding noise for our example task abolishes the marginal or lazy solutions and leads to oblique ones (Figure 9D). We added white noise with amplitude to the dynamics during learning. After training, the output was a noisy sine wave. States were order one, and the 3D projection showed dynamics along a limit cycle that was almost orthogonal to the output vector. The noise in the 2D subspace of the first two PCs was small, , and thus did not disrupt the dynamics (e.g. very little phase shift). The eigenvalue spectrum had two outliers whose real part was increased in comparison to those in the aligned regime (Appendix 1—figure 9). Note that for the chosen values and , the network actually was not chaotic at initialization (Schuecker et al., 2018). However, the choice of does not influence the solution in the oblique regime qualitatively, so both marginal and lazy solutions cease to exist g.
Learning with noise for linear RNNs
In the next two sections, we aim to understand how adding noise affects dynamics and training. We start with a simple setting of a linear RNN which allows us to track the learning dynamics analytically. Despite its simplicity, this setting already captures a range of observations: different time scales for learning the bias and variance part, and the rise of a negative feedback loop for noise suppression. Oblique dynamics, however, do not arise, showing that these need autonomously generated, nonlinear dynamics, covered in section Oblique solutions arise for noisy, nonlinear systems.
We consider a linear network driven by a constant input and additional white noise. The dynamics read
(18)
with noise as in Equation 4. We focus on a simplified task, which is to produce a constant nonzero output once the average dynamics converged, i.e., for large trial times. The output is , where the bar denotes average over the noise, and the delta fluctuations around the average. The average is given by . We train the network by changing only the recurrent weights via gradient descent. For small output weights, the fluctuations are too small to affect training: . Apart from a small correction, learning dynamics are then the same as for small output weights and no noise, a setting analyzed in Schuessler et al., 2020b. Here, we only consider the case of large output weights.
The loss separates into two parts, with and . Learning aims to minimize the sum. We first consider learning based on each part alone and then join both to describe the full learning dynamics.
Learning based on the bias part alone converges to a lazy solution (see section Details linear model: Bias only: lazy learning). For no initial weights, , we have to leading order
(19)
with
(20)
Thus, is rank one with norm . Furthermore, for a learning rate , it converges in time steps. We will see that this is very fast compared to learning the variance part.
Learning to reduce noise alone slowly produces a negative feedback loop
Next, we consider learning based on the variance part alone, i.e., to reduce fluctuations in the output while ignoring the mean. The network dynamics are linear, so that is an Ornstein-Uhlenbeck process. Its stationary variance is the solution to the Lyapunov equation
(21)
where . The variance part of the loss is then
(22)
One can state the gradient of this loss in terms of a second Lyapunov equation (Yan et al., 2016):
(23)
where Ω is the solution to
(24)
Generally, solving both Lyapunov equations analytically is not possible, and even results for random matrices are still sparse (e.g. for symmetric Wigner matrices Preciado and Rahimian, 2016). To gain intuition, we thus restrict ourselves to the case of no initial connectivity, which leads to the connectivity spanned by input and output weights only. We start with the simplest case of a rank-one matrix only spanned by the output weights, , and extend to rank two in the following section. The Lyapunov equations then become 1D, and we obtain
(25)
(26)
The gradient is therefore in the same subspace as , and we can evaluate the 1D dynamics
(27)
where is the number of update steps. We assume to be continuous, i.e., we assume a sufficiently small learning rate and approximate the discrete dynamics of gradient descent with gradient flow. With initial condition , the solution is
(28)
which is negative for . The loss then decays as
(29)
namely at order in learning time. We thus obtained that, during the variance phase of learning, connectivity develops a negative feedback look aligned with the output weights, which serves to suppress output noise. For very long learning times, , learning can in principle reduce the output fluctuations to . Note, however, that this implies a huge negative feedback loop, , which potentially leads to instability in a system with delays or discretized dynamics (Kadmon et al., 2020).
Optimizing mean and fluctuations occurs on different time scales
We now consider learning both the mean and the variance part. For zero initial recurrent weights, , the input and output vectors make up the only relevant directions in space. We thus express the recurrent weights as a rank-two matrix, , with orthonormal basis . The hats indicate normalized vectors. For large networks and large output weights, the first vector is already normalized, . The second vector is the input weights after Gram-Schmidt. Assuming that and are drawn independently, we have a small, random correlation , and can write
We computed the learning dynamics in terms of the coefficient matrix , using the same tools introduced above, and the insight that learning the mean is much faster than learning to reduce the variance. The details are relegated to section Details linear model: Bias and variance combined, here, we summarize the results. We obtained
(30)
Before discussing the temporal evolution of the two components, we analyze the structure of the matrix. The eigenvalue is a negative feedback loop along the eigenvector , and is a small feedforward component which maps the input to the output. Along the input direction , learning does not change the dynamics: The second eigenvalue, corresponding to this direction, is zero.
The dynamics unfold on two time scales. First, there is a very fast learning of the bias via the feedforward coefficient
(31)
During this phase, the eigenvalue remains at zero, so that overall weight changes remain small, . The average fixed point also does not change much, in comparison to the fixed point before learning, The loss evolves as
(32)
The variance part of the loss does not change during this phase.
In a second, slower learning phase, the eigenvalue evolves like above, Equation 28, the case where only the variance part is learned. The second coefficient compensates for the resulting change in the output. This compensation happens at a much faster time scale ( times faster than ), so we consider its steady state:
(33)
Because of this compensation, the bias part of the loss always remains at zero, and the full loss evolves as before, Equation 29. Meanwhile, the average fixed point does not change anymore; we have .
We compare our theoretical predictions against numerical simulations in Figure 10. For the task, we let the linear network dynamics converge from until , and demand the output to be at the target during the interval . Because the first learning phase converges times faster than the second one (with ), using a single learning rate is problematic. One can either observe the first phase only (for small ) or risk unstable learning during the first phase (for large ). We thus split learning into two parts with adapted learning rates. For the initial phase, we set a learning rate to , with (Figure 10, left column). For the second phase, we set (Figure 10, right column). Theory and simulation agree well for both phases. Small deviations can be observed for the second phase and long learning times: nonzero coefficients and and a corresponding increase in the norm . Testing with larger network sizes showed that these errors decreased as , which is consistent with our theory above (not shown).
Figure 10
Noise-induced learning for a linear network with input-driven fixed point.
Learning separates into fast learning of the bias part of the loss (left), and slow learning reducing the variance part (right). Learning rates are and , respectively, with and network size . Learning epochs in the first phase are counted from –1000, so that the second phase starts at 0. In the right column, the initial learning phase with learning time steps multiplied by is shown for comparison. In all plots, simulations (full lines) are compared with theory (dashed lines). (A) Loss . The two components are obtained by averaging over a batch with 32 examples at each learning step. The full loss is not plotted in the slow phase, because it is indistinguishable from . (B) Coefficients of the 2-by-2 coupling matrix . is the feedback loop along the output weights, a feedforward coupling from input to output. The theory predicts . (C) Norm of state changes during training. The theory predicts that it remains constant during the second phase and small compared to . Other parameters: target , , overlap between input and output vectors .
Our results show that learning in this linear system is a hybrid between oblique and aligned during the second phase. We have a large term that compresses the output noise, but a very small, ‘lazy’ correction in the feedforward component that corrects the output, and the states are only marginally changed. Although this system is a somewhat degenerate limiting case, we can still derive important insights. The two most striking features – the different time scales of the two learning processes, and the slow emergence of negative feedback, , along the output – are found robustly also for nonlinear networks and other tasks.
Oblique solutions arise for noisy, nonlinear systems
We now examine the origin of oblique solutions. The linear system did not yield oblique solutions, so we turn to a nonlinear model. We consider a 1D flip-flop task, where the network has to yield a constant, nonzero output depending on the sign of the last input pulse. We further simplify the analysis by only considering the steady state of a network, not how the input pulse mediates the transition. At the output, we thus only consider the average and the fluctuations . As for the linear network, the loss splits into a bias part and variance part . As before, we assume that learning only acts on a low-dimensional parameter matrix .
Because following the learning dynamics in nonlinear networks is difficult, we take a different approach. We develop a mean field theory to show how noise affects the dynamics of a nonlinear network with autonomous fixed points. This allows us to compute the loss components and in terms of . We then show that the minimum of the loss function corresponds to oblique solutions. This leads to a clear interpretation of the mechanisms pushing for oblique solutions. Finally, we show that the theory quantitatively predicts the outcome of learning with gradient descent.
Rank-two connectivity model with fixed point
We first introduce the connectivity model and compute the latent dynamics using mean field theory. We constrain the recurrent connectivity to a rank-two model of the form , where is a 2×2 coefficient matrix to be learned. The randomly drawn projection matrix has entries drawn independently from a standard normal distribution. This implies orthogonality to leading order, . We will discard the correction term, as it does not change our results apart from a constant bias. We further assume that the input and output vectors are spanned by , although not necessarily identified with the components of as in the previous section. Note also that for clarity we do not normalize as before. The assumption of Gaussian connectivity greatly simplifies the math, while its restrictions are irrelevant to the task considered here (Schuessler et al., 2020a; Beiran et al., 2021; Dubreuil et al., 2021).
To understand the dynamics Equation 4 analytically, we make use of the low-rank connectivity. Following previous work (Rivkind and Barak, 2017; Kadmon et al., 2020), we split the dynamics into two parts: a parallel part in the subspace spanned by , and an orthogonal part . This yields
(34)
(35)
Notice that the parallel part is partially driven by the orthogonal one, but not vice versa. The parallel part can be expressed in terms of the latent variable
(36)
The scaling here ensures that is order one if has order-one states. Because the readout is assumed to be spanned by , the output is fully determined by the parallel part. We can write
(37)
with projected output weights . Note that we assume large output weights, , so that is also normalized.
We split the latent state into its average over the noise and fluctuations, . Similarly, the output splits into The loss then has two components, , with
(38)
(39)
We want to understand situations with small loss. For the bias term, the average must be either small or oblique to the readout weights. For the variance term, the covariance of the fluctuations, , must be compressed along the output direction: Even though the covariance is , it still projects to the output at , as reflected by the factor in Equation 39. Figure 11 illustrates the situation in a cartoon from this high-level perspective.
Figure 11
Cartoon illustrating the split into bias and variance components of the loss, and noise suppression along the output direction.
The two-dimensional subspace spanned by illustrates the main directions under consideration: the principal components (PCs) of the average trajectories (here only a fixed point ), and the direction of output weights . Left: During learning, a fast process keeps the average output close to the target so that . Center: The variance component, , is determined by the projection of the fluctuations onto the output vector. Note that the noise in the low-D subspace is very small, , but the output is still affected due to the large output weights. Right: During training, the noise becomes non-isotropic. Along the average direction , the fluctuations are increased as a byproduct of the positive feedback . Meanwhile, a slow learning process suppresses the output variance via a negative feedback .
To understand the underlying mechanisms in detail, we next explore how the relevant variables and are determined by the coupling matrix . We do so by applying mean field theory, following previous works (Mastrogiuseppe and Ostojic, 2018; Schuessler et al., 2020a; Kadmon et al., 2020; Schuecker et al., 2018). Detailed derivations can be found in the section Details nonlinear autonomous system with noise. Here, we present the high-level results. The average dynamics converge to a fixed point determined by the equation for the latent variable,
(40)
The term is a constant offset for any given network that we ignore without loss of generality. The average slope is
(41)
with variance
(42)
(We have because the fluctuations are small.) The orthogonal variance is simply the variance of the noise, . The fixed point (Equation 40) implies that for a nonzero fixed point, the matrix must have an eigenvalue
(43)
This is very similar to the noiseless situation discussed briefly above, Equation 14. However, here the additional variance decreases the average slope due to saturation of the nonlinearity. This in turn increases the minimal eigenvalue for a nonzero fixed point, which can be found by setting , and hence :
(44)
In other words, the noise decreases the effective gain , and thus the connectivity eigenvalue needs to compensate. From the point of view of the spectrum, we are thus pushed away from the margin . These considerations, however, do not exclude the possibility that dynamics converge to an average fixed point that is small and correlated, which is at odds with oblique dynamics. To understand why learning leads to oblique dynamics, we need to move beyond the average and take into account the fluctuations .
Fluctuations of the latent variable
The fluctuations around a fixed point are driven by the noise, both directly and indirectly via the dynamics. The direct contribution is a white noise term of order because is isotropic and independent of . A detailed analysis (section Details nonlinear autonomous system with noise) shows that the indirect contribution is given by a colored noise term which originates from the finite size fluctuations in the variance of the orthogonal part. This second term is also , which implies that the fluctuations are small, . We can thus linearize their dynamics around the mean , which yields
(45)
where the order-one term contains both the white and the colored noise term. The Jacobian depends on and :
(46)
The averages are again evaluated at the joint variance . Apart from the increased variance, the stability analysis yields the same results as in the noise-free case (Schuessler et al., 2020a): The Jacobian has the eigenvalues and . The average over the third derivative is negative, so that . We assume that the second eigenvalue is smaller than the first, , so that . The fixed point under consideration is hence stable.
Next, we compute the covariance of the fluctuations at steady state, see section Details nonlinear autonomous system with noise. The outcome is
(47)
where is the normalized eigenvector of corresponding to eigenvalue . The 2×2 matrix is the covariance introduced by the white noise part alone and obeys the Lyapunov equation
(48)
The second term in Equation 47 stems from the colored noise component of .
The loss (Equation 39) is obtained by projecting the covariance on the output weights. Importantly, the factor in the covariance is compensated by the factor in the loss. Hence, even if the covariance shrinks with increasing network size, the output is still affected at order one. We next explore the implications of minimizing this loss.
Minimizing the loss by balancing saturation and negative feedback loop
To gain an understanding of how the output fluctuations responsible for can be reduced, we first consider the case of a symmetric coefficient matrix . Simulations of networks trained with gradient descent below show that this approximation is reasonable. For symmetric , the orthogonal eigenvectors with eigenvalues of the recurrent weights are also eigenvectors of , in that case corresponding to the eigenvalues . This allows to diagonalize the Lyapunov Equation 48 and yields the solution
(49)
For the loss (Equation 39), we further need the relation between the eigenvectors and the output weights. Because the fixed point is parallel to the eigenvector, we have . For the other eigenvector, orthogonality yields . Inserting this into Equations 39 and 47 yields an expression in terms of the Jacobian eigenvalues , the correlation , and the norm of the fixed point :
(50)
For more explicit insight, we choose the nonlinearity with . Similar to , this function is bounded between ±1 and has slope at the origin. For this function, we can explicitly compute the relevant Gaussian integrals. The minimal eigenvalue of to produce a fixed point, Equation 44, is then given by . For , the resulting fixed point has norm
(51)
as shown in Figure 12A. The larger eigenvalue of the Jacobian is . We next obtain the correlation between fixed point and output weights by assuming that the bias part of the loss (Equation 38) is kept at zero. This is reasonable because it requires only a small adaptation to the weights that leaves the variance part mostly untouched. The resulting correlation is
(52)
Figure 12
Mechanisms behind oblique solutions predicted by mean field theory.
(A–D) Mean field theory predictions as a function of positive feedback strength . The dotted lines indicate , the minimal eigenvalue necessary to generate fixed points. (A) Norm of fixed point . (B) Correlation so that . (C, D) Loss due to fluctuations for different or networks sizes . Dots indicate minima. (E–G) Latent states of simulated networks for randomly drawn projections . The symmetric matrix is fixed by setting as noted, , and demanding (for the mean field prediction). Dots are samples from the simulation interval . (H–J) Histogram for the corresponding output . Mean is indicated by full lines, the dashed lines indicate the target . Other parameters: , , .
so that increasing also decreases the correlation (Figure 12B). Finally, we obtain an expression for the variance part of the loss only in terms of the eigenvalues of :
(53)
We show over for different negative feedback loop sizes (Figure 12C) and different network sizes (Figure 12D). The first term diverges at the phase transition where the fixed point appears, . Learning will thus push the weights away from the phase transition toward larger . With such increasing , the fixed point norm increases, and the fixed point rotates away from the output, decreasing the correlation. This in term emphasizes the last term, scaled by . The last term is reduced with increasingly negative , corresponding to the negative feedback loop that suppresses noise.
Learning can in principle strengthen this feedback further and further, (apart from possible stability issues; Kadmon et al., 2020). However, as for the linear network, section Learning with noise for linear RNNs, this process takes time. We thus assume to be fixed and search for a minimum across . For , the last term in Equation 53 increases with increasing : the effective feedback loop in the full, nonlinear system is weakened by saturation. The loss thus has a minimum at some moderate .
To illustrate the mechanisms described above, we simulated networks at different and with . For each , we compute according to Equation 52. Setting , we then set the resulting symmetric . For each network sample, we then draw independent random projections . We started simulations at either one of the two nonzero fixed points. For just above , the noise pushes activity from one basin of attraction to the next (Figure 12C). The resulting output becomes centered around zero and independent of the initial condition for long simulation times (Figure 12F). For the optimal , the trajectories remain close to either one fixed point (Figure 12F). The output forms two overlapping distributions, each closely matching the target on average (Figure 12I). For larger , the fixed points become increasingly larger (Figure 12G). While this decreases the probability of leaving the basin of attraction even further, the variance along the output weights becomes larger (slightly wider histograms in Figure 12J). Note that the mean starts to deviate from the prediction. This is not covered by our theory and is potentially due to the linearization of the fluctuations.
All-in-all, this section revealed a potential path to oblique solutions, initiated by the large fluctuations close to a phase transition, and the interplay between the negative feedback loop and saturation. In the following section, we show that learning via gradient descent actually follows this path and that the parameters predicted by the minimum of quantitatively predict solutions from learning.
Oblique solutions from learning are predicted by the mean field theory
We trained neural networks on the fixed points task described above by applying gradient descent to the 2×2 matrix , initialized at . The gradients with respect to are equivalent to those with respect to restricted to the subspace spanned by , i.e., . Such a restriction is exact in the case of linear RNNs without random initial connectivity, and yields qualitative insights even for nonlinear networks with random initial connectivity (Schuessler et al., 2020b).
The output weights were set to , where is the first of the two projection vectors . We thus have large output weights with norm . Trajectories were initialized at . At the beginning of a trial with target output , the network receives one pulse along the input weights . The input direction is hence the second available direction for the rank-two connectivity. This is a sensible choice as networks without the restriction to rank-two weights would span the recurrent weights from existing directions, and a rank-two connectivity would hence also be spanned by and (Schuessler et al., 2020b).
The loss over learning time for one network is shown in Figure 13A. Learning consisted of two phases: a first phase in which the network did not possess a fixed point and hence did not match the target on average, . At some point, rapidly decreases, and dominates the overall loss. During the second phase, slowly decreases, with hovering around zero.
Figure 13
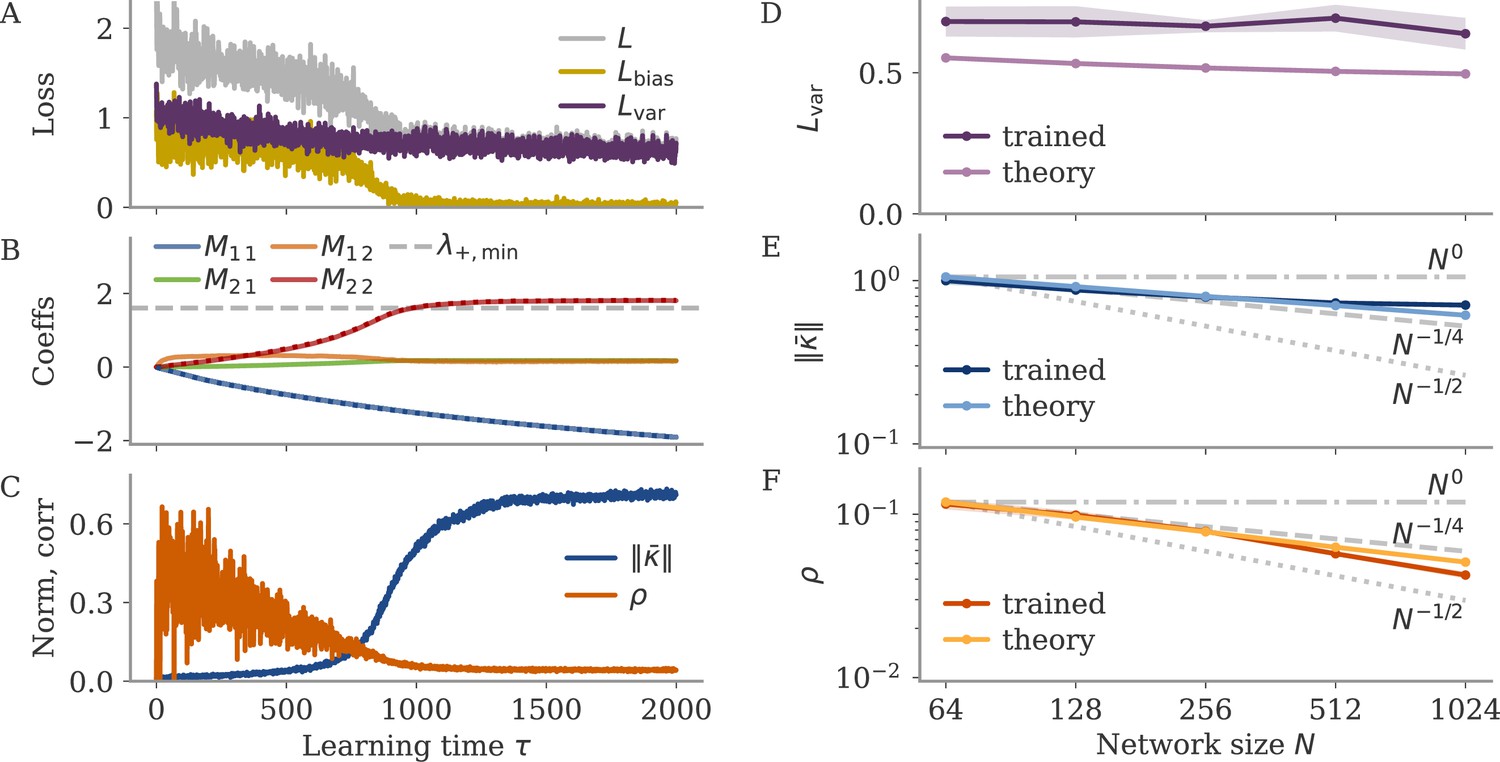
Mean field theory predicts learning with gradient descent.
(A–C) Learning dynamics with gradient descent for example network with neurons and with noise variance . (A) Loss with separate bias and variance components. (B) Matrix coefficients . The dotted lines almost identical to and indicate the eigenvalues and , respectively. The dashed line indicates . (C) Fixed point norm and correlation. (D–F) Final loss, fixed point norm, and correlation for networks of different sizes . Shown are mean (dots and lines) and standard deviation (shades) for five sample networks, and the prediction by the mean field theory. Gray lines indicate scaling as , with . Note the log-log axes for (E, F).
The coefficients of the matrix indicate the underlying learning dynamics (Figure 13B). The coefficient along the output weights, , is almost identical with . It continually grows in the negative direction, unaffected by the different phases. Its time course is very similar to the time course observed for the linear system (Figure 10B). In contrast, the coefficient along the input weights, , mirrors the two phases. It grows increasingly fast in the first phase and saturates during the second phase. Its value is very close to the larger eigenvalue, . The transition between the two phases of learning happens at the phase transition of the dynamical system when the fixed point emerges for . The off-diagonal entries show that is asymmetric during the first phase and becomes symmetric later on. The coefficient corresponds to the feedforward mode mapping the state decaying from after the pulse to the output weights .
Tracing the fixed point norm and the correlation over learning time shows what we expected (Figure 13C): The norm grows rapidly at the phase transition, which is accompanied by a decrease in the correlation. The example yields a fixed point with norm and correlation for a network with . The mere numbers already suggest that we call this an oblique solution, but the theory description above is based on how these numbers scale with network size . We trained networks with different but otherwise the same conditions. They reached the same loss (Figure 13A, not shown). The fixed point norm decreases weakly with , with , for some (Figure 13E). The correlation decreases faster, yet not quite with (Figure 13F).
We compared the outcome of learning to our mean field theory. Given that is approximately symmetric at the end of learning, we directly applied our results from the previous sections, again assuming . We fixated to match the value at the end of training and computed the that minimized , Equation 53. The results for the norm and correlation match those values obtained with gradient descent very closely.
Our high-level description of oblique and aligned dynamics did not involve scaling with network size (section Aligned and oblique population dynamics). However, the underlying assumption was that the activity of single neurons is not vanishing for large networks, i.e., . This would imply and . This is indeed what we observed for the more complex tasks when training networks of different sizes (not shown). We note that our results for the simple fixed point task deviate weakly from this (Figure 13E and F). This hints at other factors pushing solutions to . One such factor may be that the loss function is very flat for larger than the optimum (Figure 12C and D). If learning pushes trajectories beyond the optimum at some point, e.g., due to large updates or if the optimum shifts over learning , then the learning signal to reduce afterward may be too small to yield visible effects in finite learning time.
In summary, the last two sections capture the main mechanisms that drive solutions to the oblique regime in nonlinear, noise-driven networks. Although marginally small solutions seem possible for large output weights, such solutions are close to a phase transition, so the resulting system is very susceptible to noise. To accommodate robust solutions, the trajectories (here the fixed points) must increase in magnitude, while rotating away from the output weights. This further allows the implementation of a negative feedback loop that suppresses noise along the output direction. Its efficacy can be reduced by too much saturation, which in turn keeps solutions from growing ever larger. The resulting sweet spot is a network with oblique dynamics.
Mechanisms behind decoupling of neural dynamics and output
Here, we discuss in more detail the underlying mechanisms for the qualitative decoupling in oblique networks. We make a high-level argument that splits into two parts: first the possibility of decoupling in oblique, but not aligned, networks, and second a putative mechanism driving the decoupling.
For the first part, we observe that the output in oblique networks can be obtained from the leading components of the dynamics (along the PCs), but importantly also from the non-leading ones. To see this, we unpack the output in Equation 1 in a slightly different way than before, Equation 3. Namely, we split the activity vector into its component along the leading PCs, , and the remaining, trailing component, . By definition of the leading PCs as the directions of largest variance, the leading component is expected to be large, and the trailing one small. Inserting this decomposition into Equation 1 leads to
(54)
with separately defined correlations and .
For aligned networks, we recover the results from before: is small so that the output can only be generated by the leading part with large correlation . The trailing part is unconstrained but is also not contributing to either the output or the leading dynamics, and hence not of interest.
For oblique networks, is large so that the output can be generated by either of the two terms in Equation 54. The correlation has to be small because else the output would be too large. The other correlation, , can be large, because non-dominant component is small. Both terms are potentially of the same magnitude, which means both can potentially contribute to the output. If the dominant part alone generates the output, then neural dynamics and output are coupled and the solution is similar to an aligned one (Figure 14, right). If, however, the non-dominant part alone generates the output, and the correlation is so small that the dominant part does not contribute to the output, then the dominant part is not constrained by the task (Figure 14, center right). In that case, the dominant dynamics and the output can decouple qualitatively, and we may see the large variability between learners observed above.
Figure 14
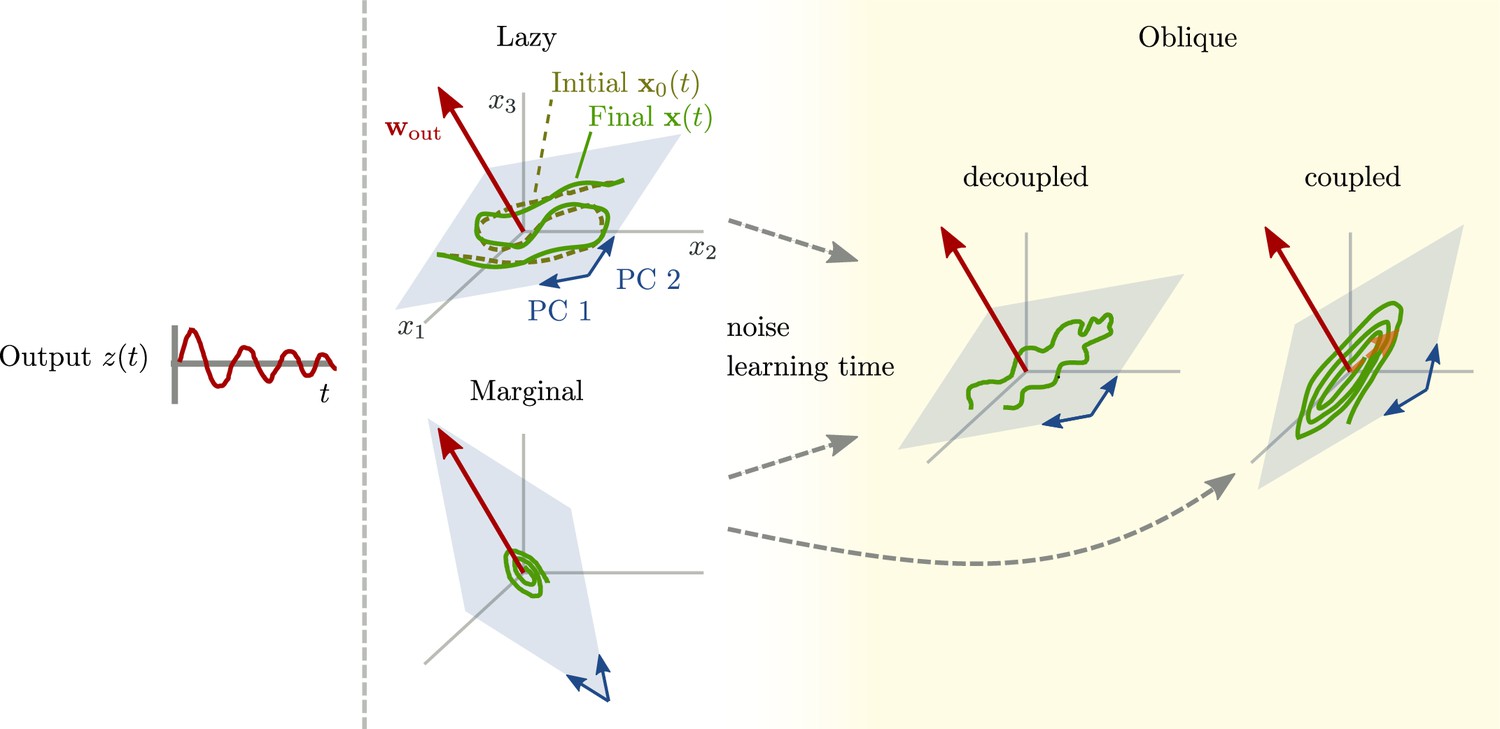
Path to oblique solutions for networks with large output weights.
Left: All networks produce the same output (Figure 1). Center: Unstable solutions that arise early in learning. For lazy solutions, initial chaotic activity is slightly adapted, without changing the dynamics qualitatively. For marginal solutions, vanishingly small initial activity is replaced with very small dynamics sufficient to generate the output. Right: With more learning time and noise added during the learning process, stable, oblique solutions arise. The neural dynamics along the largest principal components (PCs) can be either decoupled from the output (center right) or coupled (right). For decoupled dynamics, the components along the largest PCs (blue subspace) differ qualitatively from those generating the output (same as Figure 1B, bottom). The dynamics along the largest PCs inherit task-unrelated components from the initial dynamics or randomness during learning. Another possibility are oblique, but coupled dynamics (right). Such solutions don't inherit task-unrelated components of the dynamics at initialization. They are qualitatively similar to aligned solutions, and the output is generated by a small projection of the output weights onto the largest PCs (dashed orange arrow).
The existence of decoupled solutions for oblique dynamics leads to the second question: Why and when do such solutions arise? Understanding this requires more detailed insights into the learning process. Roughly speaking, learning in the oblique regime has two opposite goals: first, to generate the desired output as fast as possible, and hence to induce changes to activity that are as small as possible (section Analysis of solutions under noiseless conditions); and second, to generate solutions that are robust and stable, and hence to induce changes in activity that are large enough to not be disrupted by noise (section Oblique solutions arise for noisy, nonlinear systems). During the process of learning, small, unstable solutions appear first (Figure 14, center). These may be highly variable, depending strongly on random initialization or other randomness experienced during learning. Such solutions then slowly solidify into stable solutions, that may inherit the variability of the early solutions (Figure 14, right).
The process of how learning transforms small, unstable solutions to larger, robust ones is analyzed in section Learning with noise for linear RNNs and Oblique solutions arise for noisy, nonlinear systems. The details of how this process introduces variability between learners, however, are not discussed there and left for future work.
Appendix 1
Supplementary information
A.1. Linear approximation for lazy learning
We numerically investigated the linearization, Equation 17, of the output trajectory in weight changes , Equation 17. For this, we used the sine wave task and the same configuration as for the lazy network in Figure 9C. In Appendix 1—figure 1A, we plot the output of the full network after inserting the linear solution . The fit to the training points got more accurate with increasing network size. However, it did not reach zero error for the networks shown. In general, the error increased with increasing trial time. This indicates that the linear approximation was not valid. This is in line with the nature of the dynamical system: Trajectories become more nonlinear in with increasing time. The loss on the training set (Appendix 1—figure 1C) summarizes the observations seen before: The linear solution became more accurate with increasing network size.
Appendix 1—figure 1
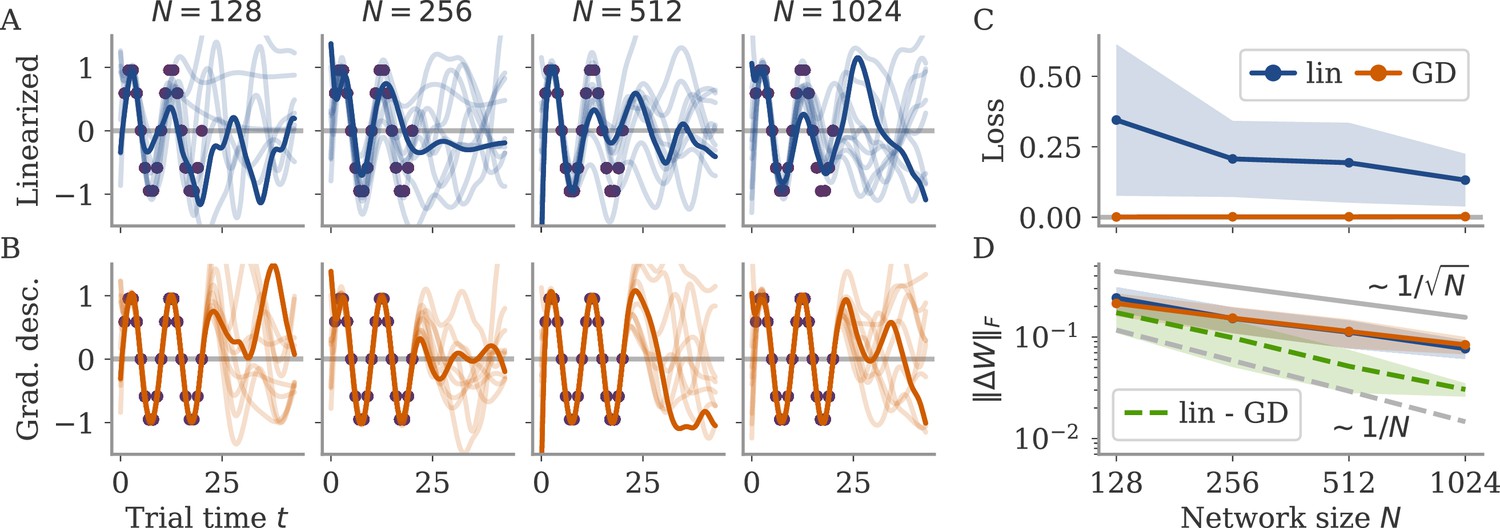
Solution to linearized network dynamics in the lazy regime.
(A) Network output for weight changes obtained from linearized dynamics for different network sizes. Each plot shows 10 different networks (one example in bold). Target points in purple. (B) Output for networks trained with gradient descent (GD) from the same initial conditions as those above. (C) Loss on the training set for the linear (lin) and GD solutions. (D) Frobenius norms of weight changes of the linear and GD solutions, as well as of the difference between the two. (dashed green). Gray and black dashed lines for comparison of scales.
How close was the linear solution to the one found by GD? To test this, we optimized the network with GD starting the same initial condition . The output of this network is shown in orange in Appendix 1—figure 1B. As seen before (Figure 9C) training points were met, but the dynamics after the last training points remained chaotic. We then quantified the norms of the two solutions and the difference between both. As shown in Appendix 1—figure 1D, both solutions had similar norm, which decays as . The difference decayed faster, as . This indicates that the linearized system can give a good insight into the solution found by training with GD, despite the inaccuracies of the linear approximation. In particular, the main features (scaling, unstable solutions, no extrapolation) are the same for the linear and the gradient descent solutions.
A.2 Details of linear model: bias only: lazy learning
We consider learning for the linear, input-driven model, Equation 4.
We start with the bias part, which is equivalent to the noise-free model (Schuessler et al., 2020b). Disregarding initial transients, the average output is , with . The gradient of the loss is then
(55)
We make the ansatz of small weight changes and hence linearize the output in weights (like in feedforward networks, Liu et al., 2020):
(56)
with the gradient of the output at initialization,
(57)
and . The dot-product signifies sum over all entries, for two matrices . Because the output is linear, the weight changes are spanned by the gradient, . Insertion into gradient descent dynamics yields
(58)
with
(59)
We used that for any vector independent of (which is the case for the input and output vectors) (Schuessler et al., 2020b). For initial condition , the solution to Equation 58 is
(60)
The corresponding output changes are . Because , the output converges to the target in learning steps. The resulting weights are
(61)
where the hats indicate normalized vectors. Consistent with linearization, the norm (both Frobenius and operator) of the changes is small: .
To connect with the following paragraph, we consider the case , so that . This is for reference, and Figure 10; see details below. We express the results in the orthonormalized bases introduced below:
(62)
with
(63)
The corresponding activity changes are with norm The output changes are so that the loss is
A.3 Details of linear model: bias and variance combined
We now combine results from the previous section, concerning the bias, with results from the Methods, concerning the variance, to derive the full learning dynamics of the linear model. For the case of no initial connectivity, , the gradients for both the bias and the variance component, Equations 23 and 55, are spanned by the output and input vector. By orthonormalizing, we define with . The weights are then constrained to . For ease of writing, we define the vectors and , where is the random, correlation between input and output vector. As before, the norms of input and output vectors are and .
The projection of the deterministic gradient is then
(64)
with deterministic output
(65)
and projection .
For the stochastic part, we need to solve the two Lyapunov Equations 21 and 24. They reduce to low-D versions after projection. For the first one, we have
(66)
and the projection solves the 2D Lyapunov equation
(67)
with . Similarly, the low-D version of the second Lyapunov Equation 24 is obtained by defining , with
(68)
The full learning dynamics for gradient flow are then given by
(69)
with and
(70)
For a small output scale, the deterministic part is order one, while the stochastic one is order (through ). Assuming , learning thus reaches an arbitrary small order-one loss after updates, with noise adding a stochastic loss, and noise-driven learning equally adding order deviations to the entries of . Hence, learning remains unaffected by the noise unless it is continued for steps.
For a large output scale, the deterministic part is fast but only leads to entries. In such a situation, the stochastic part can be expanded in orders of . To leading order, it yields dynamics along the first entry of .
In detail: For a large readout, , we expand to first order in :
(71)
The leading order of the output is
(72)
which implies that throughout learning. Under this assumption, we have
(73)
Furthermore, the deterministic gradient is
(74)
This component of learning converges on the order of learning steps due to the prefactor and the fact that enters at order one. The higher order terms therefore only lead to corrections.
The stochastic part of the gradient simplifies by assuming . The latter two are justified self-consistently because neither the deterministic nor the stochastic part contribute to and at order one if we start with . With this assumption, we have
(75)
Consistent with our assumption, we only have order-one growth for the entry . The resulting dynamics are
(76)
where is the number of learning steps. Further, because the deterministic part is so much faster, we can assume that the second entry, , is always constrained by the target. Namely, from Equation 73, we have
(77)
Lastly, the first-order corrections for the other entries all vanish due to vanishing initial conditions:
(78)
The loss due to the stochastic part is then
(79)
while the deterministic part is kept at .
During learning, the average states change only very little. To see this, we express the connectivity as with
(80)
and orthonormalized input weights
(81)
The output is then
(82)
The initial states are , so the changes are
(83)
where the scalar part is also the norm. Thus, , which is small, because the entries are . Paradoxically, the norm does not change with learning time. Essentially, once the lazy learning takes place at the beginning of learning, the norm does not change anymore (to leading order).
A.4 Details of nonlinear autonomous system with noise
This section contains detailed derivations for the average and fluctuations of the latent projection . The theoretical treatment of the network dynamics is very similar to that for a network with only a negative feedback loop for ‘balance’ by Kadmon et al., 2020. What is added here is a colored noise term that enters via the variance of the orthogonal dynamics. This is dependent on a nonzero fixed point (not present in Kadmon et al., 2020).
The dynamics of the latent variable are
(84)
That is, the low-D variable is driven autonomously by itself, but externally by the high-D orthogonal part . To resolve this into low-D dynamics only, we apply two averages: the trial-conditioned average, which is over the noise , and denoted by the bar, ; and the average over the statistics of , which arises naturally from the projection on (a population average). We start with the latter, writing
(85)
One can show that the error is small, and . For the average, we apply partial integration as in the noise-free case, Equation 14, and arrive at
(86)
where the average on the right-hand side is over the standard normal variable . In contrast to the noise-free case, the variance is now comprised of two terms,
(87)
and is the population average of . We included the time index here to emphasize that both variables still contain fluctuations around the trial-conditioned average.
We now split the term (Equation 85) into average and fluctuations around this. We self-consistently assume that all fluctuations, denoted with a , are small, which allows us to linearize around the respective averages. We have
(88)
We only keep terms up to order . The fluctuations of the error are and hence discarded. By linearization, we further have , with
(89)
The orthogonal part is an Ornstein-Uhlenbeck process with steady-state covariance
(90)
where the variance is inherited from the white noise, .
We take the average over the latent dynamics Equation 84. Apart from an initial transient, which we discard, this leaves us with a fixed point
(91)
We now discuss the fluctuations in Equation 88. There are two sources of fluctuations, and , so that we have
(92)
All derivatives are evaluated at the averages (we discard the bar in the following lines to keep notation at bay). We further compute
(93)
(94)
(95)
Inserting these terms into the dynamics (Equation 84), we arrive at
(96)
The white noise term has variance
(97)
For the fluctuations in the population average of the variance, we use Equation 90 to compute the covariance function between different time points,
(98)
For the third line, the average is taken over the independent standard normal variables . Putting all the pieces together, we have
(99)
with Jacobian
(100)
and noise term with zero average and covariance
(101)
with
(102)
We inserted the eigenvalue equation, . We note that the colored noise term did not appear in previous studies such as Kadmon et al., 2020, because there was no positive feedback and corresponding fixed point .
We now compute the variance of the fluctuations . The computation is simplified by the fact the is also eigenvector of , with eigenvalue
(103)
The eigenvector is also the direction in which the colored noise acts. Because of this, we can write
(104)
The first summand stems from the white noise term,
(105)
The integral can be computed to yield
(106)
For the steady-state variance, we take . The first term yields , which can be expressed as the solution of the Lyapunov equation
(107)
The integral converges to
(108)
Joining all the bits and pieces, we have the steady-state covariance
(109)
with normalized eigenvector
(110)
For the loss, we only need to consider the variance along the output vector. Namely, we have the output fluctuations
(111)
with projected output weights
(112)
Thus,
(113)
Appendix 1—figure 2
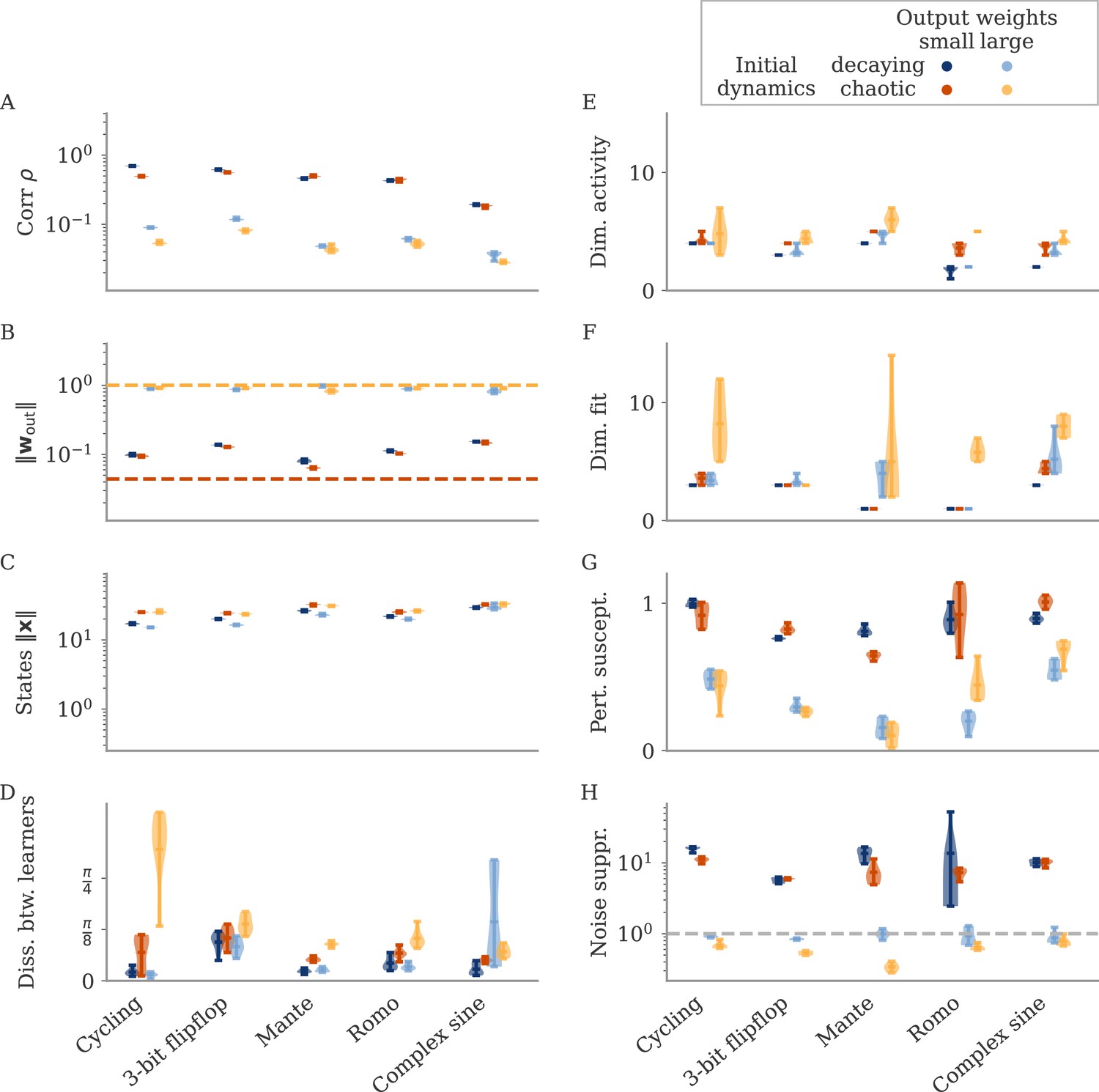
Summary of all measures for initially decaying or chaotic networks.
(A) Correlation, (B) norm of output weights, (C) norm of states, (D) dissimilarity between learners, (E) dimension of activity , (F) fit dimension , (G) susceptibility to perturbations, (H) noise suppression.
Appendix 1—figure 3

Projection of neural dynamics onto first four principal components (PCs) for the cycling task, Figure 2.
The x-axis for all plots is PC 1 of the respective dynamics (left: aligned, right: oblique). The y-axes are PCs 2–4. Axis labels indicate the relative variance explained by each PC. Arrows indicate direction. Note that there is co-rotation for the aligned network for PCs 1 and 3, as well as the counter-rotation for the oblique network for PCs 1 and 4.
Appendix 1—figure 4
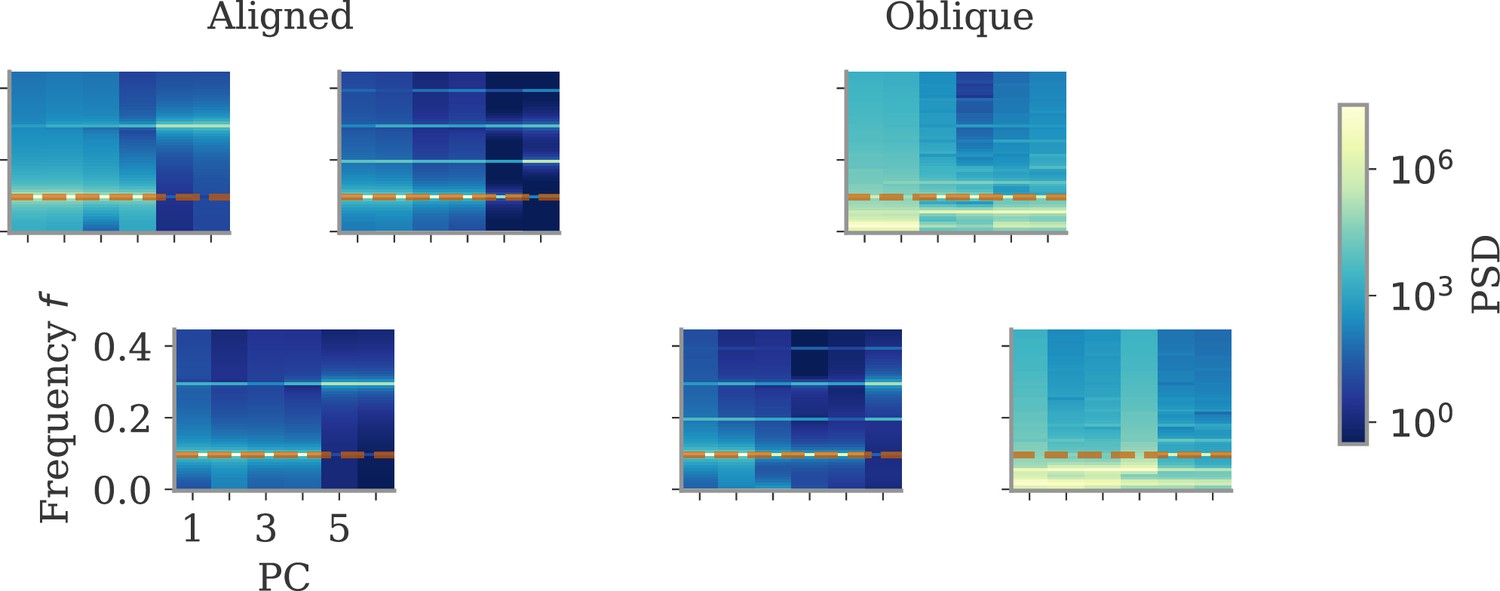
Power spectral densities for the six networks shown in Figure 4.
The dashed orange line indicates the output frequency. Note the high power for non-target frequencies in the first principal components (PCs) in some of the large output solutions.
Appendix 1—figure 5

Example of task variability for the flip-flop task.
The titles in each row indicate the spectral radius of the initial recurrent connectivity ( for initially chaotic, else decaying, activity), and the norm of initial output weights.
Appendix 1—figure 6
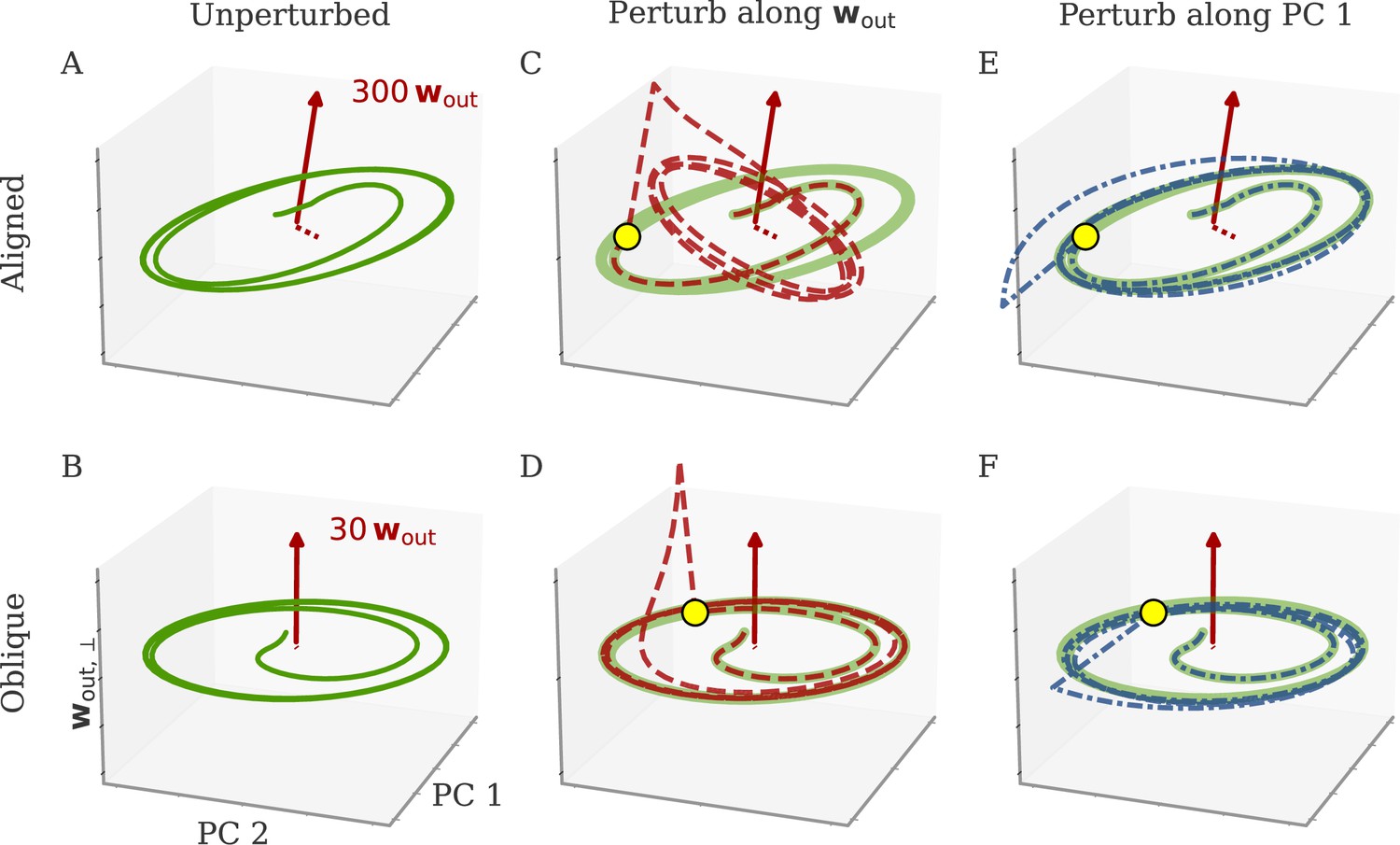
Neural activity in response to the perturbations applied in Figure 5.
Activity is plotted in the space spanned by the leading two principal components (PCs) and the output weights . We first show the unperturbed trajectories in each network (A, B), then the perturbed ones for perturbations along the first output direction (C, D) and along the first PC (E, F). The unperturbed trajectories are also plotted for comparison. Yellow dots indicate the point where the perturbation is applied. All perturbations but the one along the output for aligned lead to trajectories on the same attractor, but potentially with a phase shift. Note that in general, perturbations can also lead to the activity converging on a different attractor. Here, we see a specific example of this happening for the cycling task in the aligned regime.
Appendix 1—figure 7
Noise compression over training time for the cycling task.
Example networks trained on the cycling tasks with and . The network at the end of training is analyzed in Figure 6B. (A) Full loss (gray) and decomposition in bias (golden) and variance (purple) parts over learning time. The bias part decays rapidly (the y-axis is clipped, initial loss ), whereas the variance part needs many more training steps to decrease. Dotted lines indicate the two examples in (B–D). (B) Output fluctuations around the trial-conditioned average . Mean is over 16 samples for each of the two trial conditions (clockwise and anticlockwise rotation). Because both output dimensions are equivalent in scale, we collected both for the histogram. (C, D) Example output trajectories early (C) and late (D) in learning. Shown are the mean (dark) and five samples (light).
Appendix 1—figure 8
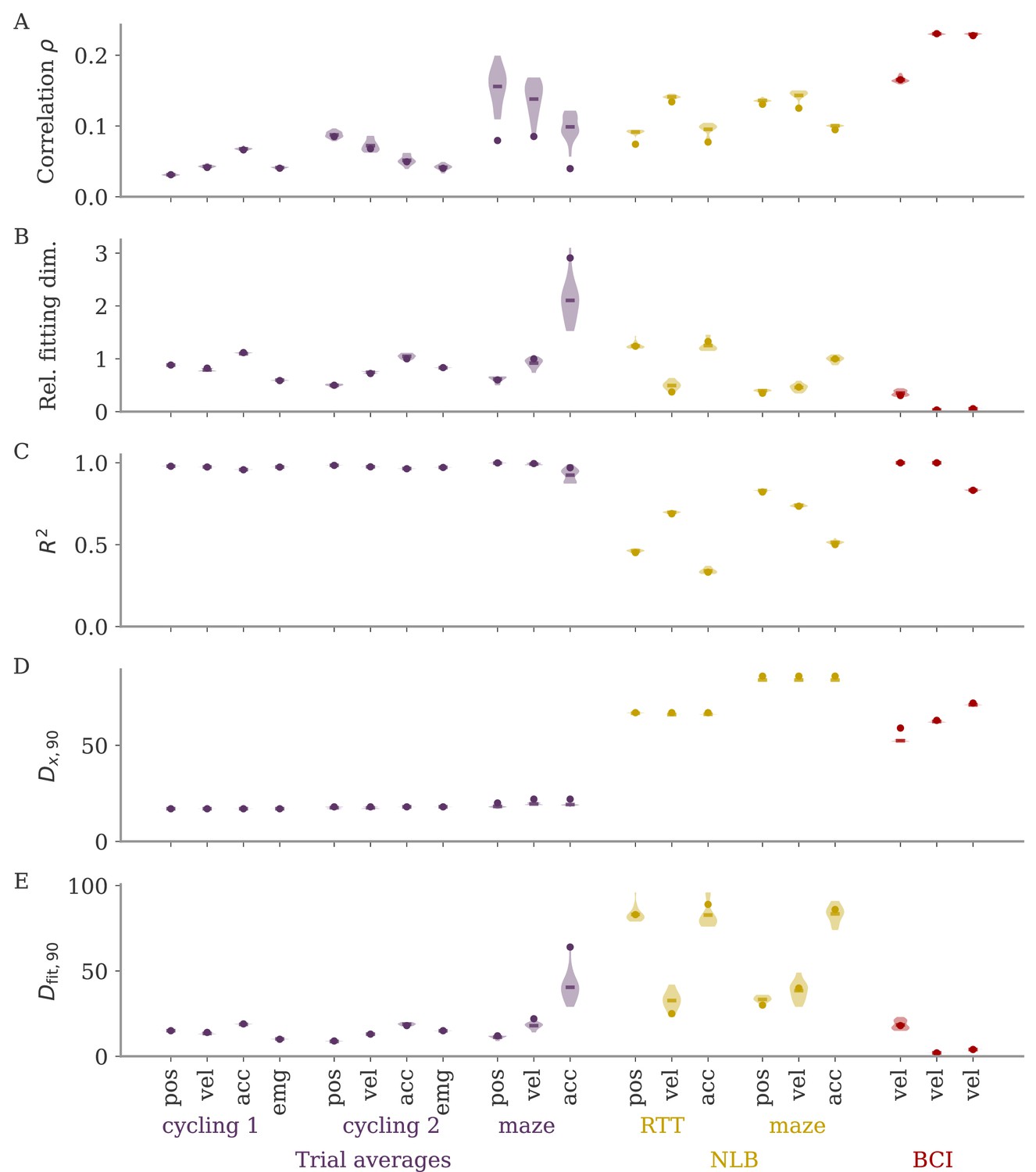
Fitting neural activity to different output modalities (hand position, velocity, acceleration, EMG).
Output modality is indicated by the x-ticks, the corresponding data sets by the color and the labels below. (A, B) Correlation and relative fitting dimension. Similar to Figure 7B, where these are shown for velocity alone. (C–E) Additional details. (C) Coefficient of determination of the linear regression. (D) Number of principal components (PCs) necessary to reach 90% of the variance of the neural activity . (E) Number of PCs necessary to reach 90% of the value of the full neural activity. For each output modality, the delay between activity and output is optimized. Position decodes earlier (300–200 ms) than velocity or acceleration (100–50 ms); no delay for EMG. The data is the same with each data set apart from a potential shift by the respective delay, so that dimension in (D) is almost the same. Note that we also computed trial averages for the Neural Latents Benchmark (NLB) maze task to test for the effect of trial averaging. These, however, have a small sample number (189 data points, but 162 neurons), which leads to considerable discrepancy between the dots (full data) and the subsamples with only 25% of the data points, for example in the correlation (A).
Appendix 1—figure 9
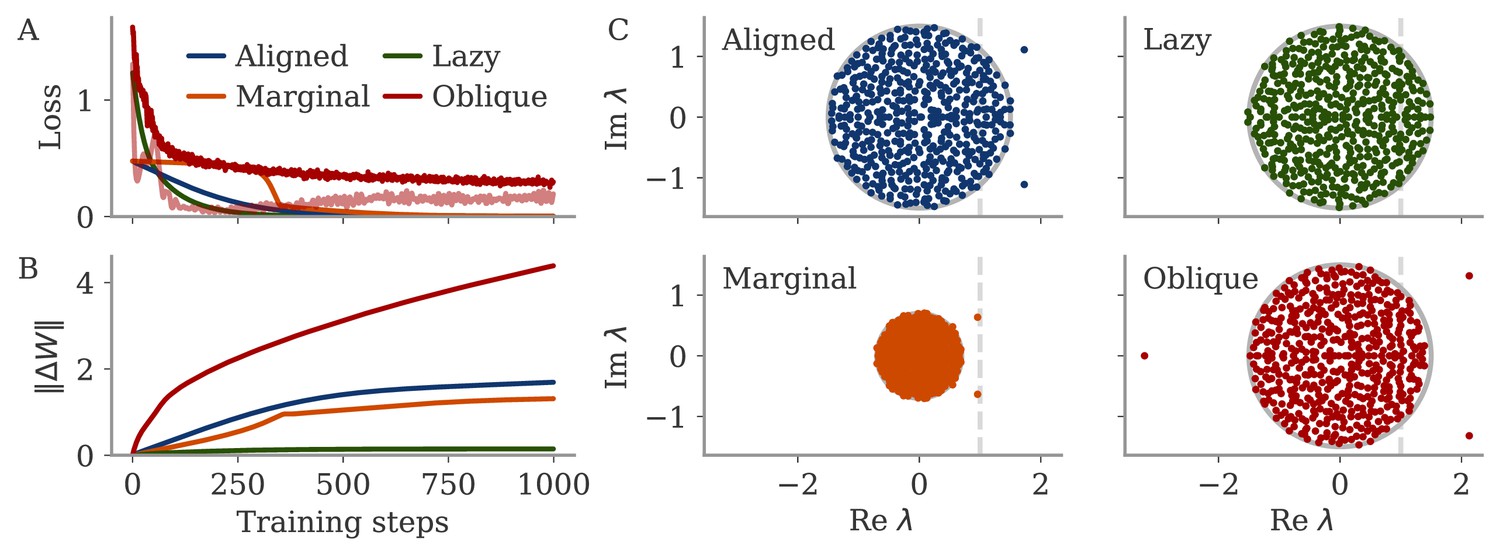
Learning curves and eigenvalue spectra for sine wave task.
(A) Loss over training steps for four networks. The light red line is the bias term of the loss for the oblique network. (B) Norm of weight changes over learning time. (C) Eigenvalue spectra of connectivity matrix after training. The dashed line indicates the stability line for the fixed point at the origin.
Appendix 1—figure 10
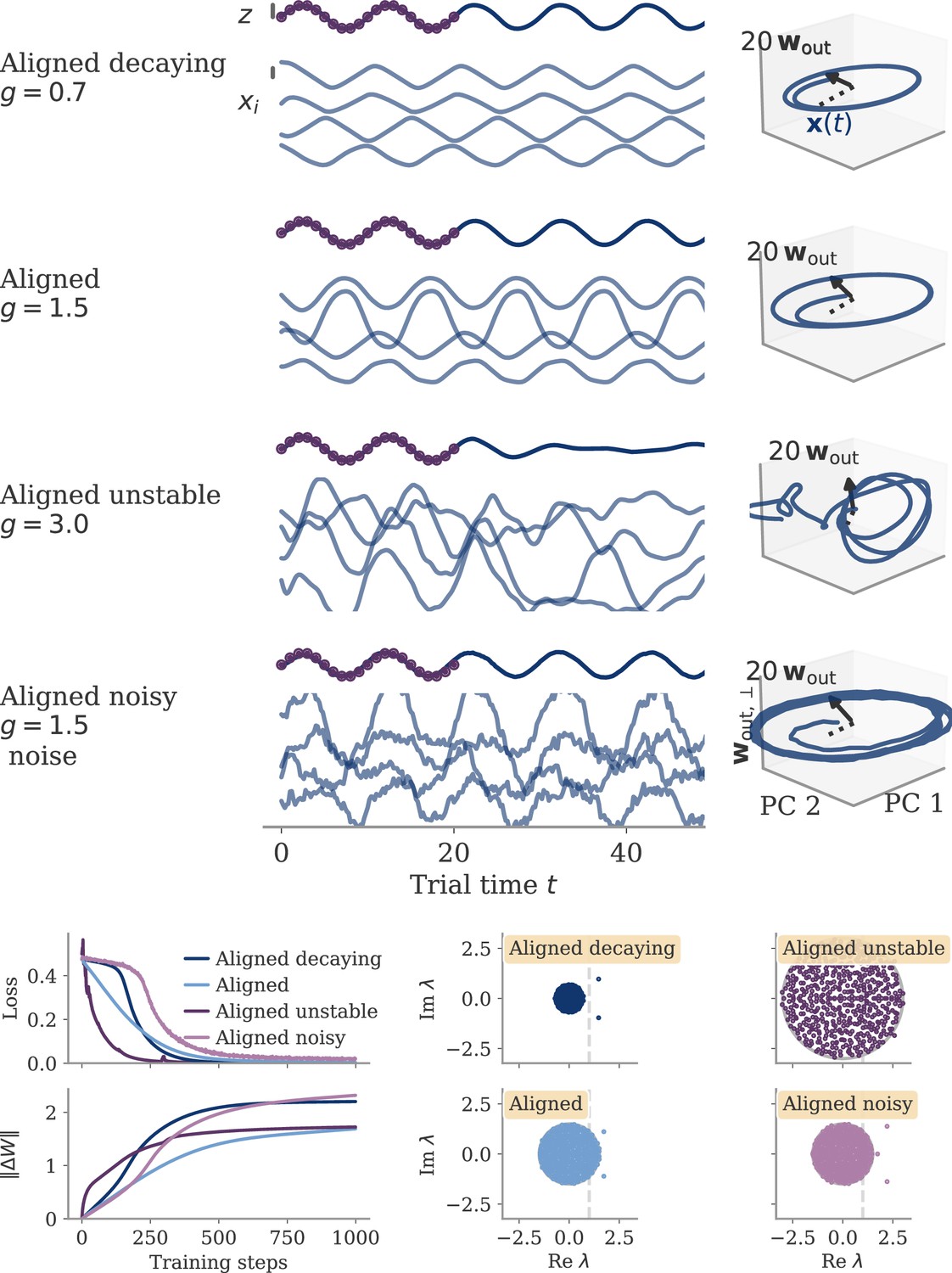
The aligned regime is robust to the choice of other hyperparameters.
Appendix 1—figure 11
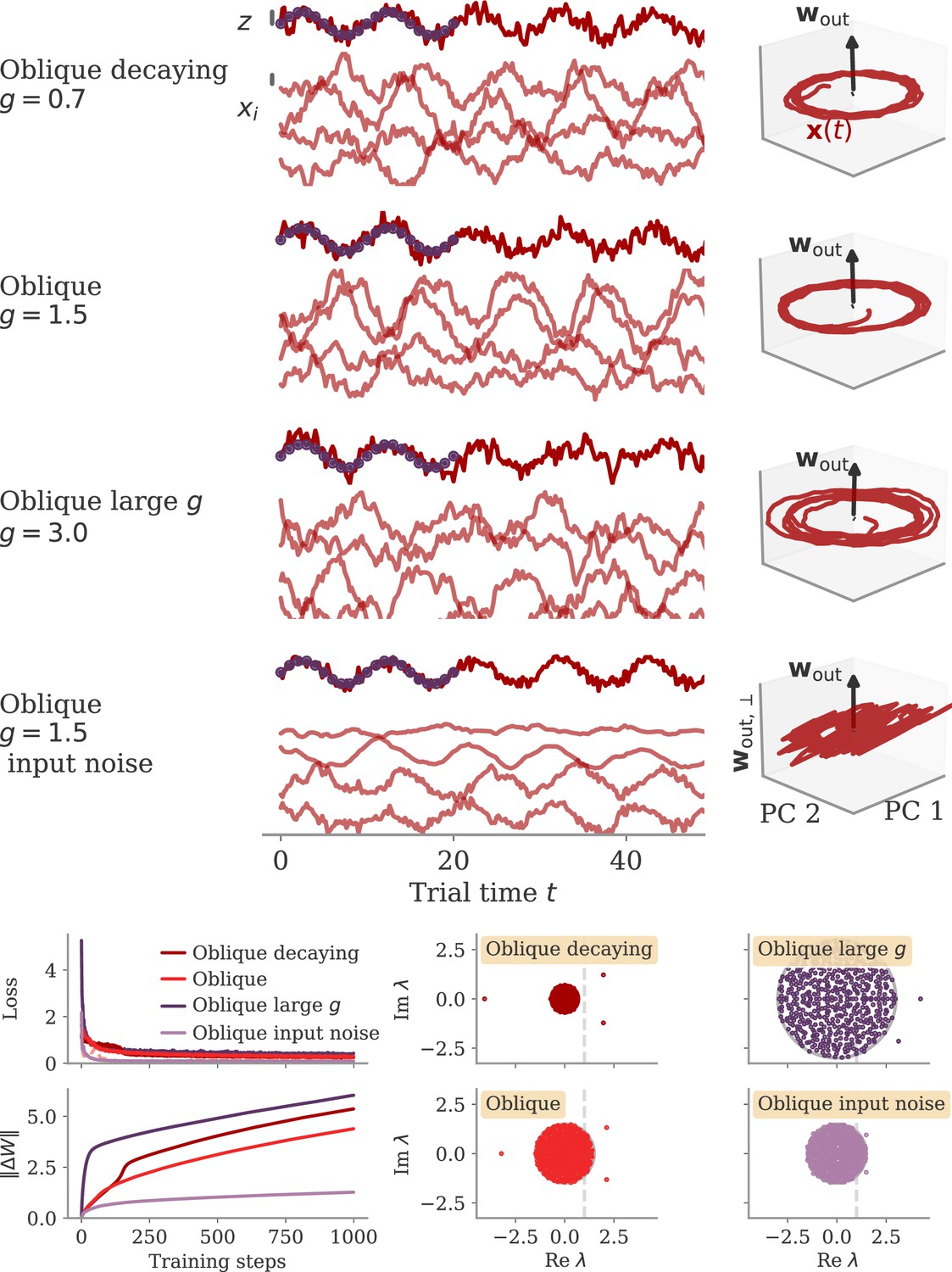
The oblique regime is robust to the choice of other hyperparameters.
Appendix 1—figure 12
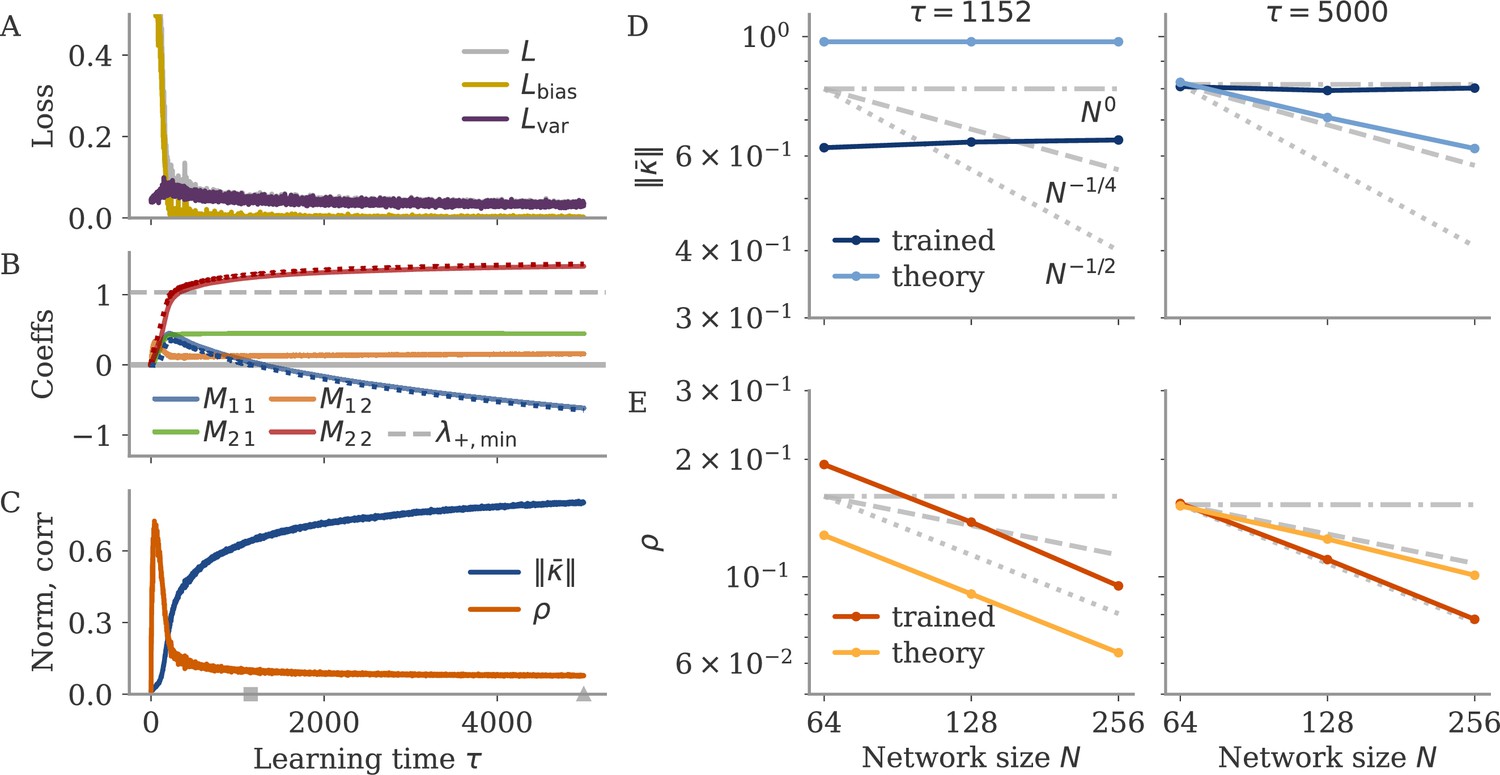
Training history leads to order-one fixed point norm.
We trained recurrent neural networks (RNNs) on the example fixed point task. Similar to Figure 13, but with smaller noise , and with learning rate increased by 2 and number of epochs by 2.5. (A–C) Learning dynamics with gradient descent for one network with neurons. The first 400 epochs are dominated by, and becomes positive. The negative feedback loop , only forms later in learning. The matrix does not become symmetric during learning. (D, E) Fixed point norm and correlation for different evaluated when (left) and at the end of learning (right). The time points are indicated by a square and triangle in (C), respectively. At , simulation and theory agree for the scaling: and . At the end of training, the theory predicts a decreasing fixed point norm, but the simulated networks inherit the order-one norm from the training history.
Data availability
The code to reproduce the results can be accessed via GitHub (copy archived at Schuessler, 2024). No new data has been generated.
References
-
Recurrent neural networks as versatile tools of neuroscience researchCurrent Opinion in Neurobiology 46:1–6.https://doi.org/10.1016/j.conb.2017.06.003
-
Shaping dynamics with multiple populations in low-rank recurrent networksNeural Computation 33:1572–1615.https://doi.org/10.1162/neco_a_01381
-
ConferenceImplicit regularization for deep neural networks driven by an ornstein-uhlenbeck like processConference on Learning Theory. pp. 483–513.
-
Coding with transient trajectories in recurrent neural networksPLOS Computational Biology 16:e1007655.https://doi.org/10.1371/journal.pcbi.1007655
-
State-dependent computations: spatiotemporal processing in cortical networksNature Reviews. Neuroscience 10:113–125.https://doi.org/10.1038/nrn2558
-
ConferenceOn lazy training in differentiable programmingAdvances in Neural Information Processing Systems. pp. 2937–2947.
-
Stabilization of a brain-computer interface via the alignment of low-dimensional spaces of neural activityNature Biomedical Engineering 4:672–685.https://doi.org/10.1038/s41551-020-0542-9
-
Attractor dynamics gate cortical information flow during decision-makingNature Neuroscience 24:843–850.https://doi.org/10.1038/s41593-021-00840-6
-
Residual dynamics resolves recurrent contributions to neural computationNature Neuroscience 26:326–338.https://doi.org/10.1038/s41593-022-01230-2
-
Disentangling feature and lazy training in deep neural networksJournal of Statistical Mechanics 2020:113301.https://doi.org/10.1088/1742-5468/abc4de
-
Learning by neural reassociationNature Neuroscience 21:607–616.https://doi.org/10.1038/s41593-018-0095-3
-
Receptive fields, binocular interaction and functional architecture in the cat’s visual cortexThe Journal of Physiology 160:106–154.https://doi.org/10.1113/jphysiol.1962.sp006837
-
ConferenceNeural tangent kernel: convergence and generalization in neural networksAdvances in Neural Information Processing Systems. pp. 8571–8580.
-
ConferencePredictive Coding in Balanced Neural Networks with Noise, Chaos and DelaysAdvances in Neural Information Processing Systems. pp. 16677–16688.
-
Cortical activity in the null space: permitting preparation without movementNature Neuroscience 17:440–448.https://doi.org/10.1038/nn.3643
-
ConferenceOn the linearity of large non-linear models: when and why the tangent kernel is constantAdvances in Neural Information Processing Systems.
-
ConferenceUniversality and individuality in neural dynamics across large populations of recurrent networksAdvances in Neural Information Processing Systems. pp. 15629–15641.
-
Superior arm-movement decoding from cortex with a new, unsupervised-learning algorithmJournal of Neural Engineering 15:026010.https://doi.org/10.1088/1741-2552/aa9e95
-
Single-trial neural dynamics are dominated by richly varied movementsNature Neuroscience 22:1677–1686.https://doi.org/10.1038/s41593-019-0502-4
-
Scikit-learn: Machine learning in pythonJournal of Machine Learning Research 12:2825–2830.
-
ConferenceNeural latents benchmark ’21: evaluating latent variable models of neural population activityAdvances in Neural Information Processing Systems.
-
ConferenceControllability Gramian spectra of random networks2016 American Control Conference. pp. 3874–3879.https://doi.org/10.1109/ACC.2016.7525517
-
Local dynamics in trained recurrent neural networksPhysical Review Letters 118:258101.https://doi.org/10.1103/PhysRevLett.118.258101
-
All-optical interrogation of neural circuits in behaving miceNature Protocols 17:1579–1620.https://doi.org/10.1038/s41596-022-00691-w
-
Towards the neural population doctrineCurrent Opinion in Neurobiology 55:103–111.https://doi.org/10.1016/j.conb.2019.02.002
-
Cortical control of virtual self-motion using task-specific subspacesThe Journal of Neuroscience 42:220–239.https://doi.org/10.1523/JNEUROSCI.2687-20.2021
-
Optimal sequence memory in driven random networksPhysical Review X 8:041029.https://doi.org/10.1103/PhysRevX.8.041029
-
Dynamics of random recurrent networks with correlated low-rank structurePhysical Review Research 2:013111.https://doi.org/10.1103/PhysRevResearch.2.013111
-
ConferenceThe interplay between randomness and structure during learning in rnnsAdvances in Neural Information Processing Systems. pp. 13352–13362.
-
SoftwareAligned_oblique_in_rnns, version swh:1:rev:9d4c813feda9f772aade3026c1f0893ddb81dd8dSoftware Heritage.
-
Chaos in random neural networksPhysical Review Letters 61:259–262.https://doi.org/10.1103/PhysRevLett.61.259
-
Neural circuits as computational dynamical systemsCurrent Opinion in Neurobiology 25:156–163.https://doi.org/10.1016/j.conb.2014.01.008
-
A neural network that finds A naturalistic solution for the production of muscle activityNature Neuroscience 18:1025–1033.https://doi.org/10.1038/nn.4042
-
ConferenceCharting and navigating the space of solutions for recurrent neural networksAdvances in Neural Information Processing Systems 34.
-
Computation through neural population dynamicsAnnual Review of Neuroscience 43:249–275.https://doi.org/10.1146/annurev-neuro-092619-094115
-
ConferenceGeneralized shape metrics on neural representationsAdvances in Neural Information Processing Systems 34.
-
Adjoint methods of sensitivity analysis for Lyapunov equationStructural and Multidisciplinary Optimization 53:225–237.https://doi.org/10.1007/s00158-015-1323-z
Article and author information
Author details
Friedrich Schuessler

Francesca Mastrogiuseppe
Funding
Deutsche Forschungsgemeinschaft (EXC 2002/1 "Science of Intelligence" - project no. 390523135)
- Friedrich Schuessler
Israel Science Foundation (1442/2)
- Omri Barak
Human Frontier Science Program (RGP0017/2021)
- Omri Barak
Agence Nationale de la Recherche (ANR-17-EURE-0017)
- Srdjan Ostojic
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Version history
- Preprint posted:
- Sent for peer review:
- Reviewed Preprint version 1:
- Reviewed Preprint version 2:
- Version of Record published:
Cite all versions
You can cite all versions using the DOI https://doi.org/10.7554/eLife.93060. This DOI represents all versions, and will always resolve to the latest one.
Copyright
© 2024, Schuessler et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 489
- views
-
- 28
- downloads
-
- 2
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Aligned and oblique dynamics in recurrent neural networks
eLife 13:RP93060.
https://doi.org/10.7554/eLife.93060.3
Further reading
-
- Neuroscience
The circadian clock, an internal time-keeping system orchestrates 24 hr rhythms in physiology and behavior by regulating rhythmic transcription in cells. Astrocytes, the most abundant glial cells, play crucial roles in CNS functions, but the impact of the circadian clock on astrocyte functions remains largely unexplored. In this study, we identified 412 circadian rhythmic transcripts in cultured mouse cortical astrocytes through RNA sequencing. Gene Ontology analysis indicated that genes involved in Ca2+ homeostasis are under circadian control. Notably, Herpud1 (Herp) exhibited robust circadian rhythmicity at both mRNA and protein levels, a rhythm disrupted in astrocytes lacking the circadian transcription factor, BMAL1. HERP regulated endoplasmic reticulum (ER) Ca2+ release by modulating the degradation of inositol 1,4,5-trisphosphate receptors (ITPRs). ATP-stimulated ER Ca2+ release varied with the circadian phase, being more pronounced at subjective night phase, likely due to the rhythmic expression of ITPR2. Correspondingly, ATP-stimulated cytosolic Ca2+ increases were heightened at the subjective night phase. This rhythmic ER Ca2+ response led to circadian phase-dependent variations in the phosphorylation of Connexin 43 (Ser368) and gap junctional communication. Given the role of gap junction channel (GJC) in propagating Ca2+ signals, we suggest that this circadian regulation of ER Ca2+ responses could affect astrocytic modulation of synaptic activity according to the time of day. Overall, our study enhances the understanding of how the circadian clock influences astrocyte function in the CNS, shedding light on their potential role in daily variations of brain activity and health.
-
- Computational and Systems Biology
- Neuroscience
The basolateral amygdala (BLA) is a key site where fear learning takes place through synaptic plasticity. Rodent research shows prominent low theta (~3–6 Hz), high theta (~6–12 Hz), and gamma (>30 Hz) rhythms in the BLA local field potential recordings. However, it is not understood what role these rhythms play in supporting the plasticity. Here, we create a biophysically detailed model of the BLA circuit to show that several classes of interneurons (PV, SOM, and VIP) in the BLA can be critically involved in producing the rhythms; these rhythms promote the formation of a dedicated fear circuit shaped through spike-timing-dependent plasticity. Each class of interneurons is necessary for the plasticity. We find that the low theta rhythm is a biomarker of successful fear conditioning. The model makes use of interneurons commonly found in the cortex and, hence, may apply to a wide variety of associative learning situations.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}