Assessing the danger of self-sustained HIV epidemics in heterosexuals by population based phylogenetic cluster analysis
- University Hospital Zurich, Switzerland
- University of Zurich, Switzerland
- Geneva University Hospitals, Switzerland
- University Hospital Lausanne, Switzerland
- University of Basel, Switzerland
- University Hospital Basel, Switzerland
- Regional Hospital Lugano, Switzerland
- Lausanne University Hospital, Switzerland
- Bern University Hospital, University of Bern, Switzerland
- Cantonal Hospital St. Gallen, Switzerland
Abstract
Assessing the danger of transition of HIV transmission from a concentrated to a generalized epidemic is of major importance for public health. In this study, we develop a phylogeny-based statistical approach to address this question. As a case study, we use this to investigate the trends and determinants of HIV transmission among Swiss heterosexuals. We extract the corresponding transmission clusters from a phylogenetic tree. To capture the incomplete sampling, the delayed introduction of imported infections to Switzerland, and potential factors associated with basic reproductive number , we extend the branching process model to infer transmission parameters. Overall, the is estimated to be (-confidence interval —) and it is decreasing by per years (—). Our findings indicate rather diminishing HIV transmission among Swiss heterosexuals far below the epidemic threshold. Generally, our approach allows to assess the danger of self-sustained epidemics from any viral sequence data.
https://doi.org/10.7554/eLife.28721.001eLife digest
In epidemiology, the “basic reproductive number” describes how efficiently a disease is transmitted, and represents the average number of new infections that an infected individual causes. If this number is less than one, many people do not infect anybody and hence the transmission chains die out. On the other hand, if the basic reproductive number is larger than one, an infected person infects on average more than one new individual, which leads to the virus or bacteria spreading in a self-sustained way.
Turk et al. have now developed a method to estimate the basic reproductive number using the genetic sequences of the virus or bacteria, and have used it to investigate how efficiently HIV spreads among Swiss heterosexuals. The results show that the basic reproductive number of HIV in this group is far below the critical value of one and that over the last years this number has been decreasing. Furthermore, the basic reproductive number differs for different subtypes of the HIV virus, indicating that the geographical region where the infection was acquired may play a role in transmission. Turk et al. also found that people who are diagnosed later or who often have sex with occasional partners spread the virus more efficiently.
These findings might be helpful for policy makers as they indicate that the risk of self-sustained transmission in this group in Switzerland is small. Furthermore the method allows HIV epidemics to be monitored at high resolution using sequence data, assesses the success of currently implemented preventive measures, and helps to target subgroups who are at higher risk of an infection – for instance, by supporting frequent HIV testing of these people. The method developed by Turk et al. could also prove useful for assessing the danger of other epidemics.
https://doi.org/10.7554/eLife.28721.002Introduction
Epidemics of HIV and other blood-borne and sexually transmitted diseases (for instance syphilis, HBV and HCV) can be subdivided into concentrated and generalized epidemics. While for the former, the rapid infectious agent transmission is restricted to core transmission groups involved in high-risk behaviors (such as men who have sex with men and injecting drug users), the generalized epidemic refers to fast pathogen spreading in the heterosexual (general) population resulting in higher overall disease prevalence. Mechanistically, the key factor explaining whether the HIV transmission is concentrated or generalized, is the ability of HIV to spread among heterosexuals. If the epidemic in this population is not self-sustained, the HIV epidemic remains concentrated; otherwise the virus is spreading rapidly in the broad population leading to a generalized HIV epidemic.
In most resource-rich settings HIV transmission is concentrated, that is, driven mostly by transmission among men who have sex with men (MSM) and injecting drug users (IDU), whereas the limited transmission among heterosexuals is maintained by either imported infections or spillovers from other transmission groups (Kouyos et al., 2010; von Wyl et al., 2011; Ragonnet-Cronin et al., 2016; Xiridou et al., 2010; Esbjörnsson et al., 2016; Sallam et al., 2017). This suggests that in most Western European countries and similar epidemiological settings the basic reproductive number among heterosexuals is below . However, it is not clear how far away from self-sustained the epidemic is in heterosexuals. Moreover, the change in HIV transmission among heterosexuals over time is another important, yet unknown, factor, especially with evidenced increasing risky sexual behavior (Kouyos et al., 2015). It is therefore crucial to assess both the transmission and its time trend in order to obtain meaningful insights into the epidemic.
Assessing the subcritical transmission of HIV in the general population shares some methodological similarities with the analysis of stage III zoonoses, for instance, monkeypox (Wolfe et al., 2007), which also exhibit stuttering transmission chains. Both cases follow a source-sink dynamics, i.e., a flux of infections from a subpopulation in which the disease is self-sustained to a population where it is not. For the case of stage III zoonoses and tuberculosis, it has been shown that the distribution of outbreak sizes can be used to quantify the pathogen spread (Blumberg and Lloyd-Smith, 2013b; Blumberg and Lloyd-Smith, 2013a; Borgdorff et al., 1998). The fundamental approach of our study is to apply this concept to transmission of HIV in the general population. However, there are two key differences between emerging zoonotic pathogens and human-to-human infectious agents. Firstly, while the contact tracing data are not available for many sexually transmitted infections (STI), the viral sequences carry valuable information about the transmission chain size distribution. Thus, the approach of quantifying transmissibility from chain size distributions needs to be combined with a tool to derive clusters from viral sequences. Compared to the animal-human transmission the delayed introduction of the index case of an STI or blood-borne virus to the subpopulation of interest plays an important role, especially in viruses like HIV with long infectious periods in the absence of treatment and higher transmissibility during the acute phase (Marzel et al., 2016; Powers et al., 2011; Rieder et al., 2010; Rodger et al., 2016; Hollingsworth et al., 2008; Cohen et al., 2011b; Cohen et al., 2011a; Cohen et al., 2016). This is especially important because a considerable fraction of HIV cases in heterosexuals is found in migrants (Del Amo et al., 2004; von Wyl et al., 2011; European Centre for Disease Prevention and Control/WHO Regional Office for Europe, 2016). If, for example, a migrant infected with HIV abroad moves to Switzerland in the chronic stage of the infection, he/she has (from the perspective of the Swiss population) lost some transmission potential upon entering Swiss heterosexual transmission network.
In order to quantify the subcritical transmission we combine phylogenetic cluster analysis with an adapted version of a branching process model based estimator that derives the basic reproductive number from the size distribution of transmission chains. We further extend this approach to determine the impact of calendar time and other potential determinants on ; especially in order to assess whether exhibits an increasing time trend or is high in particular subgroups. Applying this method to the phylogenetic transmission clusters among heterosexuals in the Swiss HIV Cohort Study (SHCS), we can assess transmission of HIV in this population and in particular the risk of a generalized HIV epidemic together with the main determinants of transmission.
Results
We developed a method to assess how far HIV transmission in populations with basic reproductive number is from the epidemic threshold, that is, how far it is from being self-sustained in these populations (see Materials and methods). A classical application of this question/method is HIV-1 transmission in heterosexuals in settings with a concentrated epidemic. Heterosexual HIV-1 transmission in Switzerland is a case in point for such a non-self-sustained HIV epidemic. We identified transmission clusters among heterosexuals in the SHCS. These clusters were small in size (Table 1) and comprised individuals of broad demographic background (see Table 2). Based on the most likely geographic origin of the transmission clusters, we classified transmission chains as being of Swiss origin, that is, to represent introductions from other transmission groups in Switzerland into the heterosexual population, and to be of non-Swiss origin. For these latter transmission chains, we assumed that the of the index case was reduced by a factor of (see Materials and methods). To take into account the imperfect sampling density we fixed the subtype-depending sampling probabilities based on the results from the study by Shilaih et al. (2016), corrected by the proportion of the HIV infected individuals linked to care ( based on Kohler et al., 2015) and the fraction of heterosexuals from the SHCS with an HIV sequence in the phylogenetic tree (). The model parameters used in this study are summarized in Table 1 (see Sensitivity analyses, Appendix 1—figure 1 and Appendix 1—figure 2 for the corresponding sensitivity analyses).
Table 1
Transmission chain size distribution and model parameters.
https://doi.org/10.7554/eLife.28721.003| Subtype | Overall | ||||||
|---|---|---|---|---|---|---|---|
| B | C | 01_AE | 02_AG | A | Other | ||
| Total number of chains, (%) | 1643 (53%) | 322 (10%) | 239 (7.7%) | 331 (11%) | 327 (11%) | 238 (7.7%) | 3100 (100%) |
| Chain size, (%) | |||||||
| 1 | 1437 (87%) | 280 (87%) | 206 (86%) | 272 (82%) | 269 (82%) | 195 (82%) | 2659 (86%) |
| 2 | 158 (9.6%) | 34 (11%) | 31 (13%) | 40 (12%) | 44 (13%) | 36 (15%) | 343 (11%) |
| 3 | 30 (1.8%) | 7 (2.2%) | 1 (0.42%) | 10 (3.0%) | 10 (3.1%) | 6 (2.5%) | 64 (2.1%) |
| 4 | 12 (0.73%) | - | 1 (0.42%) | 6 (1.8%) | 3 (0.92%) | 1 (0.42%) | 23 (0.74%) |
| 5 | 1 (0.06%) | 1 (0.31%) | - | 2 (0.6%) | 1 (0.31%) | - | 5 (0.16%) |
| 6 | 1 (0.06%) | - | - | 1 (0.3%) | - | - | 2 (0.06%) |
| 7 | 1 (0.06%) | - | - | - | - | - | 1 (0.03%) |
| 8 | 2 (0.12%) | - | - | - | - | - | 2 (0.06%) |
| 9 | 1 (0.06%) | - | - | - | - | - | 1 (0.03%) |
| Sampling probability, (SD) | 0.39 | 0.29 | 0.34 | 0.26 | 0.33 | 0.29 | 0.35 (0.05) |
| Chain origin, (%) | |||||||
| Swiss () | 948 (58%) | 36 (11%) | 36 (15%) | 36 (11%) | 47 (14%) | 30 (13%) | 1133 (37%) |
| non-Swiss () | 695 (42%) | 286 (89%) | 203 (85%) | 295 (89%) | 280 (86%) | 208 (87%) | 1967 (63%) |
of the HIV transmission in Swiss heterosexuals
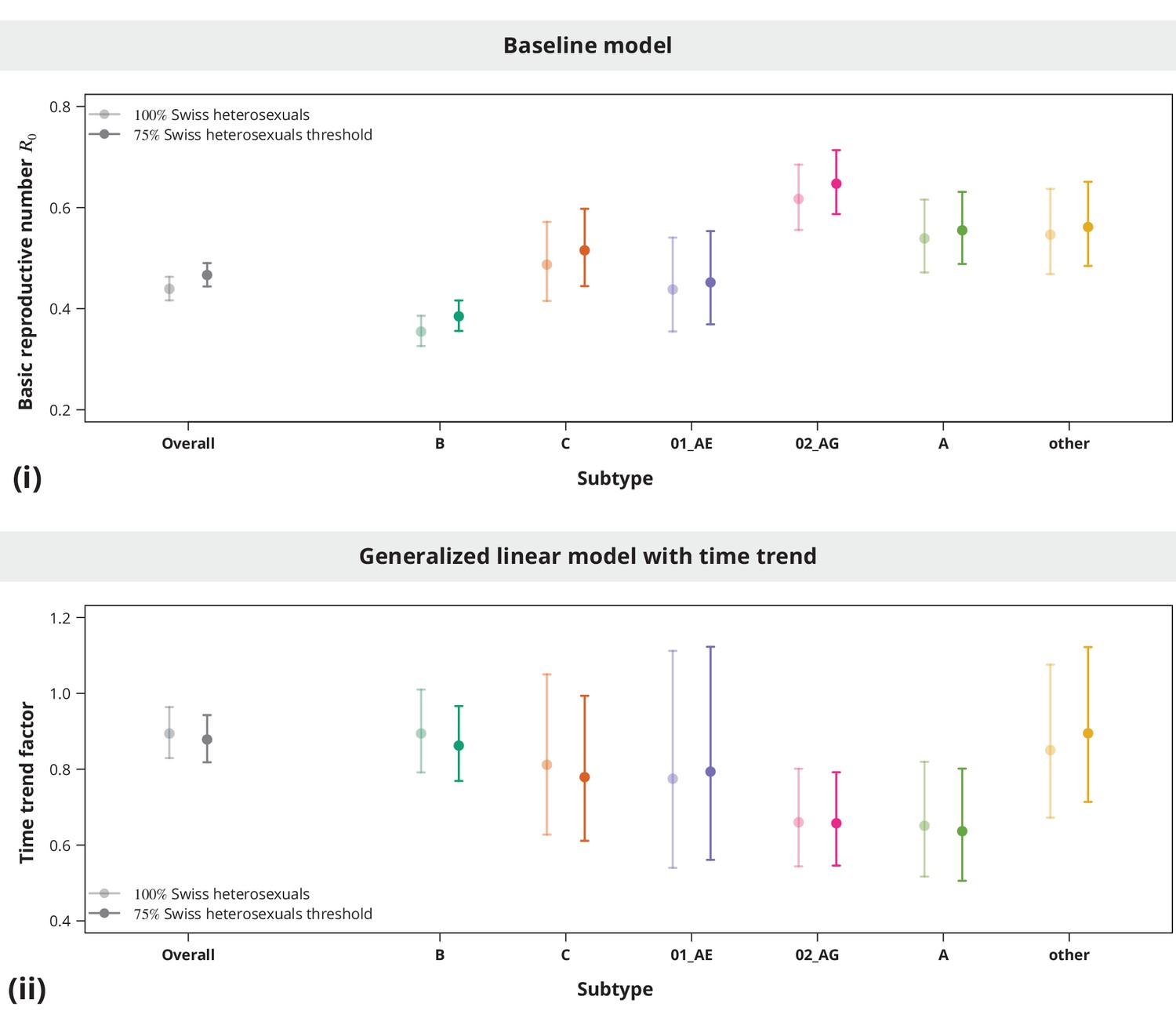
To obtain an overall estimate for the of HIV transmission in Swiss heterosexuals, the baseline model was fitted to all of the previously described transmission chain data. In this baseline model the was estimated to be (-confidence interval (CI) —). The fact that was clearly below (-value from one-sided Wald hypothesis testing against the alternative ) indicated that HIV transmission is far away from a self-sustained epidemic.
Although the overall estimate was clearly below , individual subtypes represent different epidemiological settings and hence individual subtypes may have closer to the epidemic threshold. The subtype-stratified analyses indeed yielded lower of (-CI —) for subtype B as compared to the non-B subtypes (Figure 1). The recombinant form CRF02_AG had the highest estimated of (-CI —). Despite these differences among the estimates for different subtypes they were all significantly below (with all -values from the one-sided test smaller than ). Therefore, we concluded that there is no danger of a self-sustained HIV epidemic in Swiss heterosexuals of any HIV subtype.
Figure 1
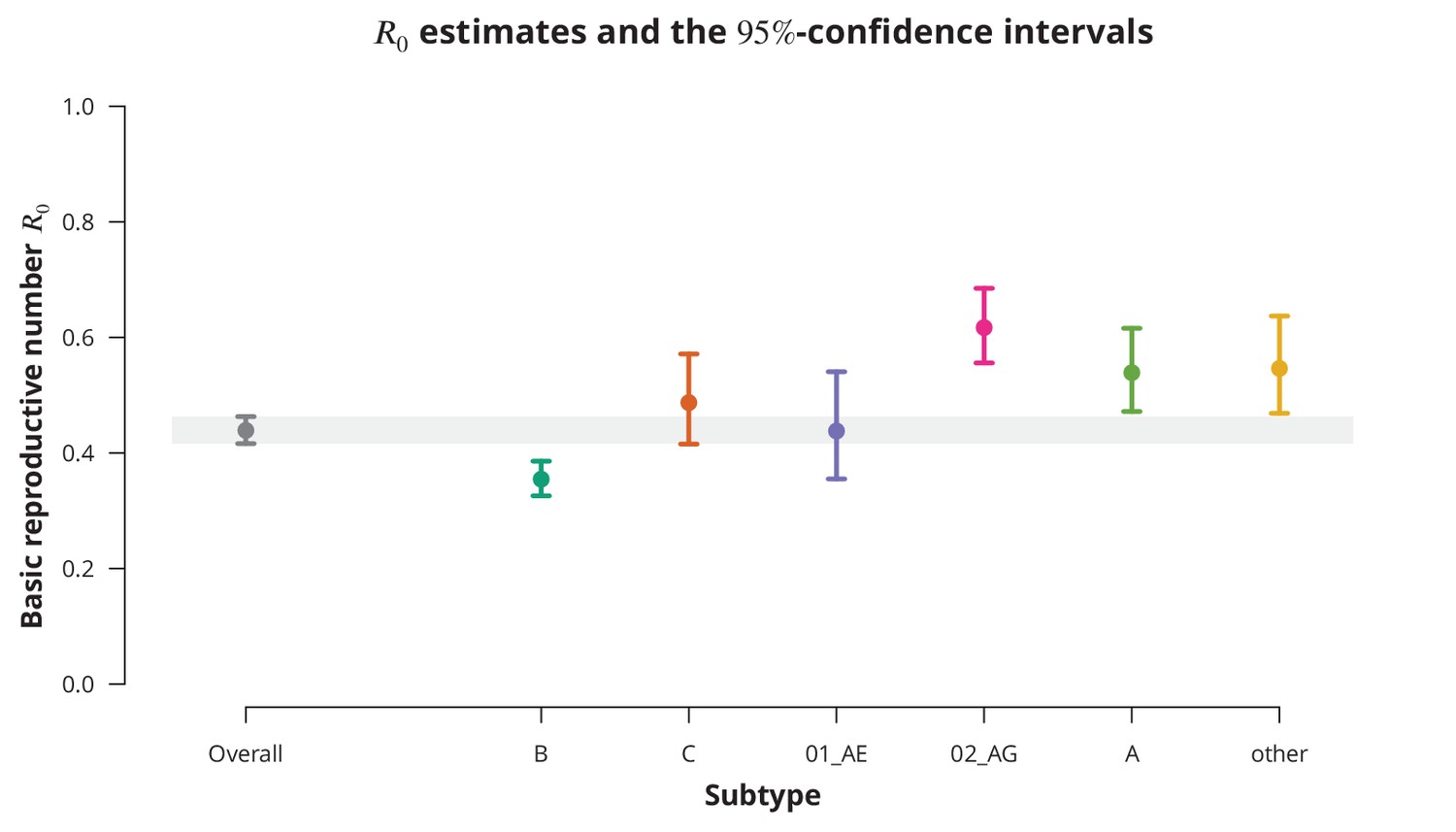
Overall basic reproductive number and per subtype from stratified analysis.
The dark gray point indicates the overall basic reproductive number estimate (by neglecting the transmission chain subtypes) and the corresponding -confidence interval is shown with the dark gray line and the gray-shaded band. The analogous results from the per-subtype stratified analysis are represented by colored points and lines, each color corresponding to one of the subtypes (B, C, CRF01_AE, CRF02_AG or A) or the group of subtypes (other).
Time trend of the
Despite consistently low estimates, an increasing time trend for would impose a potential concern, especially if the time trend would predict a crossing of the epidemic threshold in the near future. To investigate this, we fitted a univariate model with as a linear function of the establishment date of the transmission chain. We found that overall the is decreasing at a factor per years (-CI —). The per subtype-stratified analyses showed the consistently decreasing time trend among the subtypes ranging from factor per years for subtype A to for B-subtype.
To better capture the changes of over time we included higher-order polynomials of the establishment date to our model (Figure 2). With the reference date on the 1st of January 1996 (which corresponds to the median estimated date of infection - see Table 2) a cubic spline (without the linear term) was identified as the optimal model according to the Bayesian information criterion (BIC). This model exhibits a mild increase of the from the mid 1980’s to the mid 1990’s, with a peak- of (-CI —) reached in 1996 and followed by a steep and monotonic decrease. It is noteworthy that the time of peak- coincided with the introduction of highly active antiretroviral therapy. Shortly after the started to rapidly decrease and has never rebounded. This extrapolation should be, however, taken with a grain of salt and seen more as a trend rather than a prognosis, since only a few transmission chains have been observed for the recent years (which is reflected by wide confidence intervals).
Figure 2
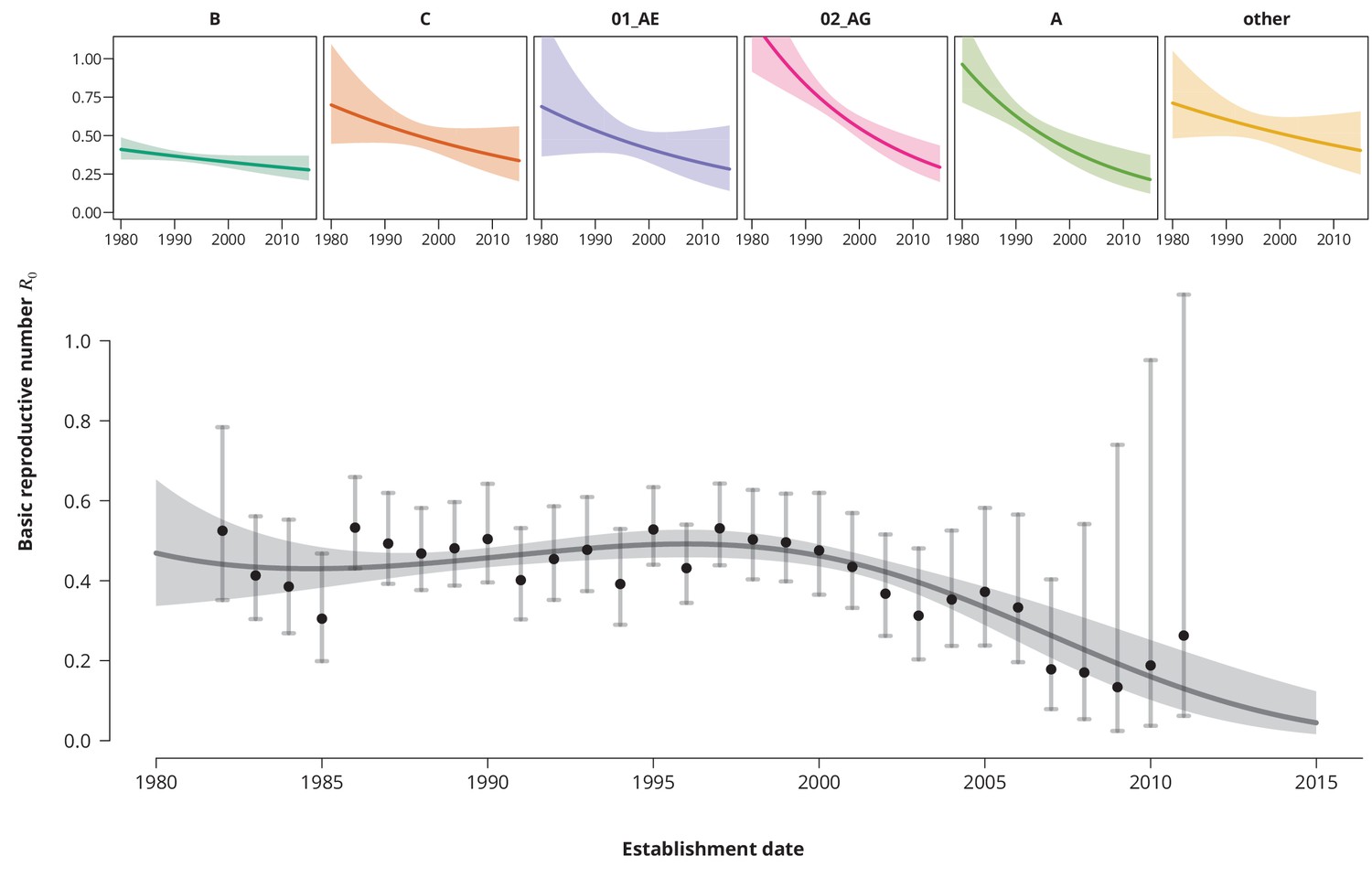
Time trends for .
The upper smaller panels show the time trends for from the subtype-stratified analyses, in which the ’s were modeled as linear functions of establishment date (i.e., for each subtype the time trend rate was assumed to be constant). The colored shaded-bands correspond to the -prediction bands. The (best-fitting) nonlinear time trend for from the overall analysis is displayed in the lower panel (dark gray curve) together with the -prediction band (gray-shaded area). The black points represent the estimates from the per establishment year stratified analyses and the gray vertical lines the corresponding -confidence intervals.
Table 2
Patients’ demographic characteristics.
https://doi.org/10.7554/eLife.28721.006| Patients | Transmission chains | |
|---|---|---|
| Index case | ||
| Total number, | 3698 | 3100 |
| Age at estimated date of infection [in years], median (IQR) | 29.2 (23.1—37.8) | 28.8 (22.8—37.4) |
| Estimated date of infection, median (IQR) | Jun 1996 (Sep 1990—Nov 2001) | Nov 1995 (Sep 1989—May 2001) |
| Time to diagnosis [in years], median (IQR) | 3.40 (1.66—5.24) | 3.54 (1.78—5.43) |
| Reported sex with occasional partner [as fraction of FUPs*], median (IQR) | 0.53 (0.09—0.89) | 0.50 (0.07—0.88) |
| No available FUP†, (%) | 250 (6.8%) | 226 (7.3%) |
| Earliest CD4 count [per μL]‡, median (IQR) | 310 (143—510) | 300 (134—507) |
-
*Follow-up visit (FUP).
†Patients without FUP questionnaire regarding the sexual risk behavior. See Sensitivity analyses.
-
‡One patient did not have any available CD4 cell count. The missing value was imputed with the mean CD4 cell count.
Determinants of the HIV-transmission
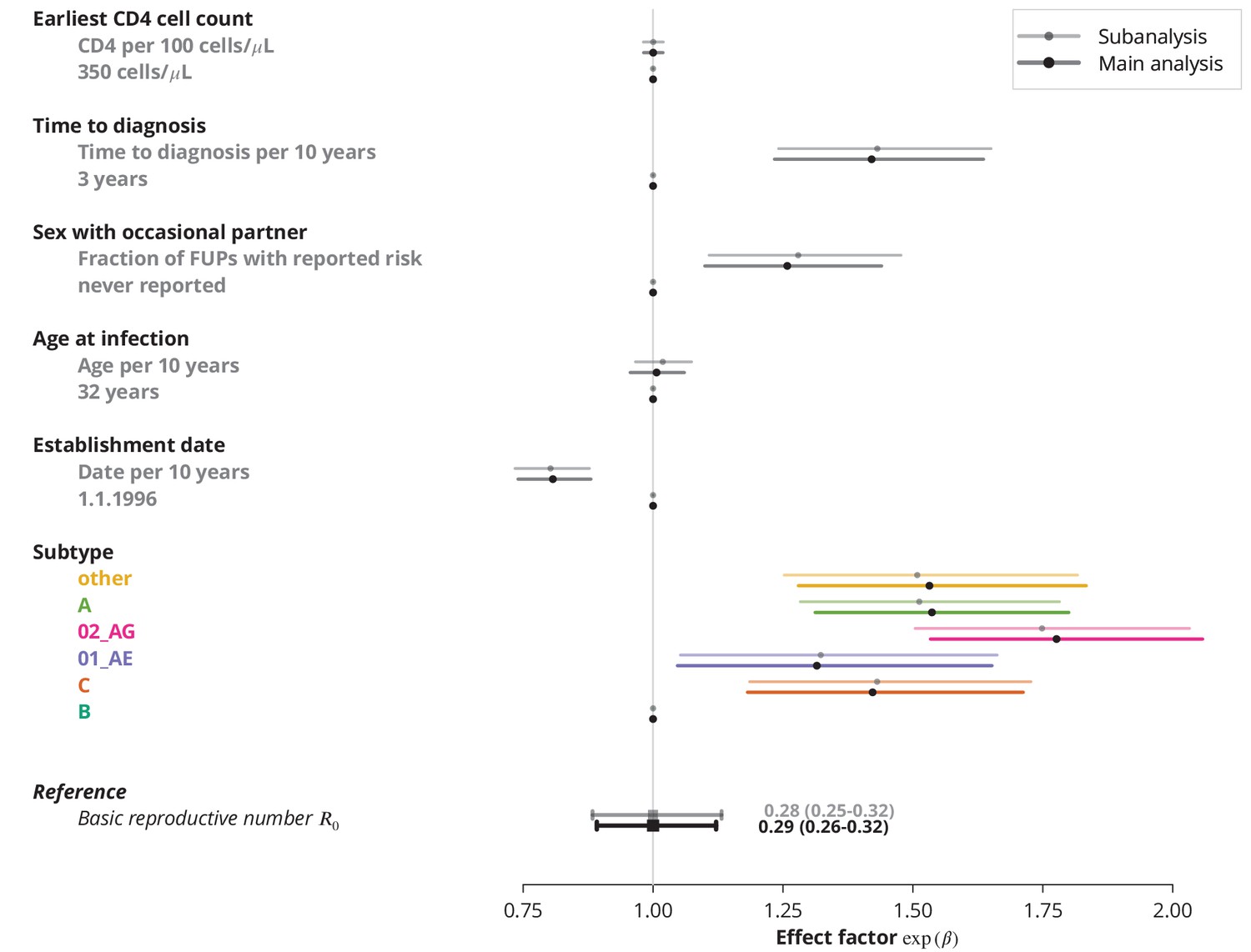
Finally, we identified the characteristics associated with higher and therefore potential focal subpopulations, in which the basic reproductive number could be above . The simplest model containing only the linear terms of risk factors showed that the is decreasing with the establishment date of the transmission chain and that all non-B subtypes have higher compared to subtype B, which was consistent with the findings from the univariate model and per-subtype stratified analyses. Moreover, we found that reporting sex with occasional partners and longer time to HIV diagnosis of the index case are associated with higher , whereas the earliest CD4 cell count and the age do not have significant effects (Figure 3).
Figure 3
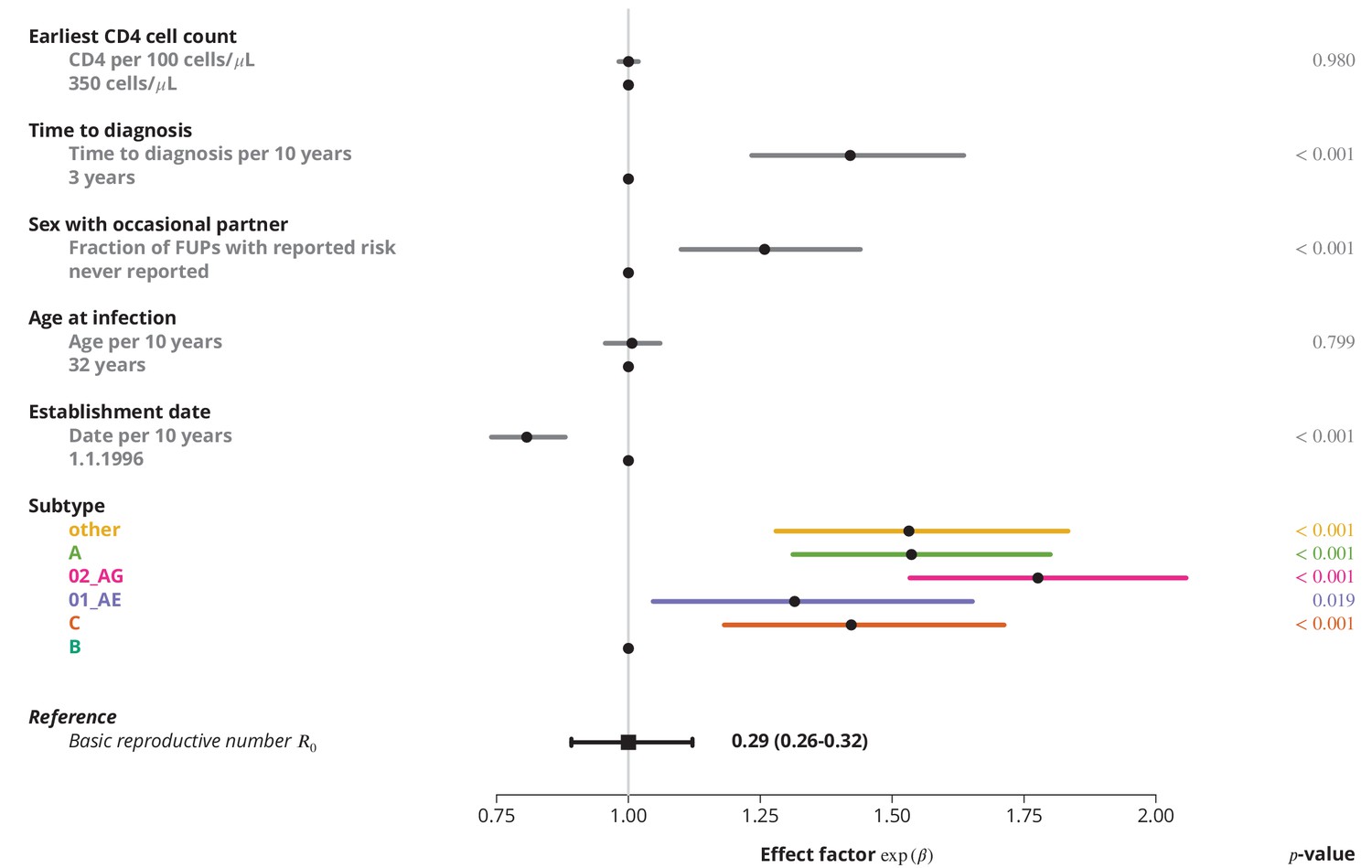
Effect of different factors on the basic reproductive number from the multivariate model with only linear factor terms.
The black square and the black line show the reference basic reproductive number and its -confidence interval (for a transmission chain of subtype B which started on 1.1.1996, and in which the index case was diagnosed 3 years after the infection, was 32 years old upon infection, never reported on having sex with occasional partner and had the earliest CD4 cell count of 350 cells per μL). The vertical gray line separates the factors associated with lower (left; effect factor ) and from the factors contributing to higher (right; effect factor ). The black points on this line refer to the reference transmission chain. The colored and dark gray lines represent the effect sizes from multivariate model (black circles depicting the estimates) for different factors and their -confidence intervals. The corresponding -values are shown in the rightmost column. FUP, follow-up visit.
These trends remained robust (Figure 4) when allowing the covariables to enter the model non-linearly (for instance as polynomials like in the case of the time trend above). The final multivariate model identified subtype, establishment date of the transmission chain, frequency of reporting sex with occasional partner and time to diagnosis of the index case as the significant risk factors associated with (see Selection of the predictive models). Allowing nonlinear terms for the time to diagnosis provided better goodness-of-fit than the linear model. The steep increase of in the early/acute phase (see Figure 4) of the infection indicates the importance of early diagnosis (which is nowadays closely related to early treatment initiation) while the time becomes less relevant in the cases diagnosed late in the chronic phase.
Figure 4
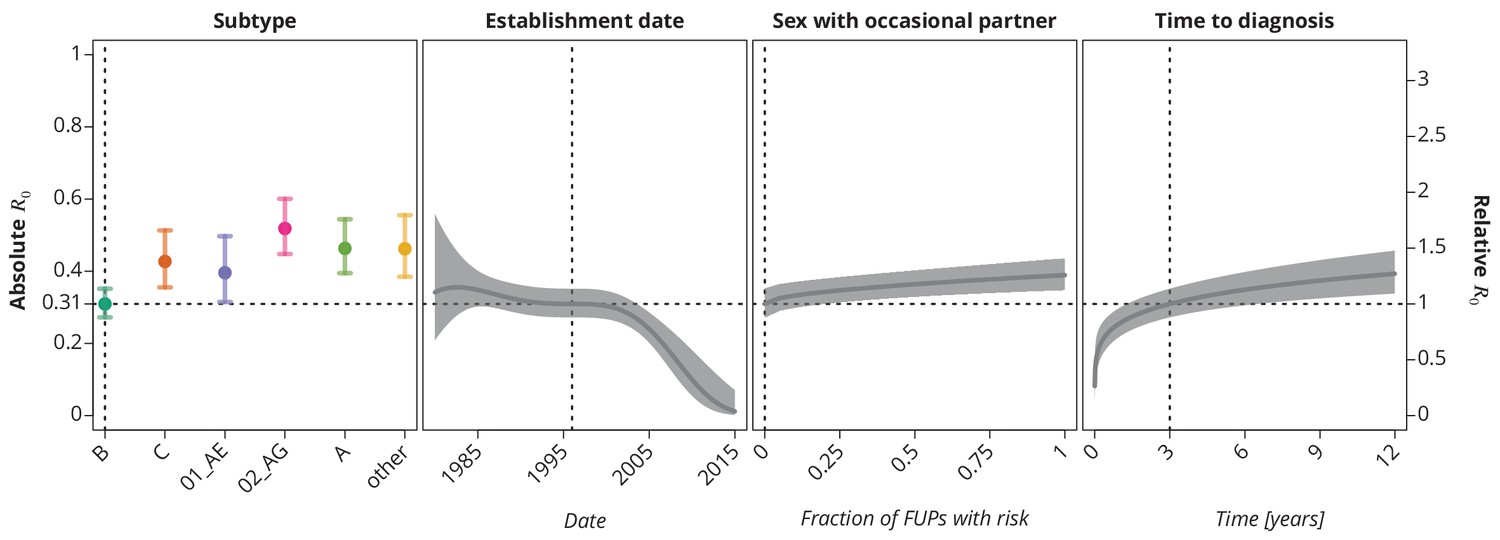
Final multivariate model’s profile plots of factors associated with the basic reproductive number .
The vertical dotted lines depict the reference transmission chain (of subtype B, started on 1.1.1996, in which the observed index case did not report having sex with occasional partner and was diagnosed after 3 years after the infection). The left -axis represents the basic reproductive number whereas the right -axis corresponds to the relative values of as compared to the baseline . The as the function of specific factor (with the other factors held fixed at the reference value) is displayed by the colored (for HIV-1 subtype) and the dark gray (establishment date, sexual risk behavior and time to diagnosis) lines. The vertical bars and the shaded bands, respectively, correspond to the -confidence intervals.
Discussion
Our approach demonstrates that viral sequences combined with basic demographic information can be successfully used not only to estimate the basic reproductive number of HIV in a subcritical setting and thereby assess the danger of a generalized HIV epidemic but also to shed light on the trends and other determinants of viral transmission. As a proof of concept, this approach was applied to HIV transmission in Swiss heterosexuals, for which we found an far below the epidemic threshold with a decreasing time trend - indicating a low and decreasing danger of a generalized epidemic. Even though the Swiss HIV epidemic is captured in outstanding detail and representativeness by the SHCS, our approach can be easily used in other non-self-sustained epidemics since viral sequences from genotypic resistance testing are nowadays routinely produced in most resource-rich settings. Moreover, the generalizability of our approach might be broadened to other settings and viruses due to the increased availability of viral sequences boosted by decreasing sequencing costs and the ability of the method to adjust for imperfect sampling.
To our knowledge our study represents the first systematic assessment of the basic reproductive number for subcritical HIV transmission among heterosexuals, which makes it difficult to compare our results to other estimates. In addition, it was conducted in one of the most densely sampled settings. Most of the studies investigated the transmission route composition of larger transmission clusters across different B and non-B subtypes (Esbjörnsson et al., 2016; Chaillon et al., 2017; Ragonnet-Cronin et al., 2016; Sallam et al., 2017; Kouyos et al., 2010; von Wyl et al., 2011), or focused on homosexual men or injecting drug users as the main drivers of HIV transmission (Amundsen et al., 2004). Stadler et al. (2012) previously presented a birth-death process based analysis of HIV transmission in Switzerland. However, since this approach is restricted to sufficiently large clusters, it is not suitable for subcritical settings and might potentially overestimate due to selection bias. Hence, our approach, which is tailored to subcritical viral transmission, is complementary to theirs. Among other studies specific for heterosexual populations, Hughes et al. (2009) focused on the clusters of size at least across non-B subtypes, and Xiridou et al. (2010) studied the impact of sexual behavior of migrants on the HIV prevalence, while none of them directly assessed the danger of self-sustained epidemics.
Epidemiological differences between the HIV-1 subtypes, especially between B and non-B subtypes, have been pointed out previously (Kouyos et al., 2010; von Wyl et al., 2011). Yet the exact factors contributing to the differences are difficult to identify. On the one hand, the non-B subtypes are often seen in relation to the infections imported from abroad, which could be introduced either by immigrants or by residents who got infected while temporarily abroad. A proportion of these introductions could be attributed to the sex tourism (Rogstad, 2004). However, even the differences between the various non-B subtypes could be substantial, as they represent different epidemiological settings. For instance, the CRF01_AE is often found in Asians and it also most likely originates from Southeastern Asia (Angelis et al., 2015), while subtypes originating from Africa, such as CRF02_AG (Mir et al., 2016), are frequently found in people of black ethnicity. Additionally, poverty and different policies regulating prostitution worldwide also have an impact on the transmission patterns, like on rate of condom use, access to HIV testing and treatment (Shannon et al., 2015). On the other hand, disentangling the effect of different epidemiological characteristics and even of the strains remains challenging, as was significantly affected by the HIV subtype even in the multivariate model (Figure 3).
One of the key components of our model is the index case relative transmission potential , which is also associated with some degree of uncertainty. To illustrate its role and influence on the transmission parameters we performed a range of sensitivity analyses (Appendix 1—figure 1). On the one hand, omitting the reduced transmissibility of the index case, that is, assuming , leads to largely underestimated (overall of , -CI —) affirming the importance of this extension. Then again, the concrete value chosen may be debatable, especially due to arguable infectivity in chronic phase (studied by Bellan et al., 2015); thus a small can be caused both by immigration later during chronic infection and by elevated infectivity in the acute phase. To address this issue we lowered the for the transmission chains of non-Swiss origin to to obtain a more conservative estimate of , which was, nevertheless, still safely below (, -CI —). Furthermore, even though theoretically the transmission potential of some index cases could also be enhanced (i.e., ), for instance for sex workers, we do not expect that this is the case for many transmission chains and would therefore have only marginal effect on our estimates. Besides, since a would lead to even lower , our main conclusions would not change (in fact, the assumption of is conservative with respect to our conclusion of ).
The presented model is based on source-sink dynamics, which is reflected in the importance of the index case and its immigration background, while the role of emigration is neglected. However, in many resource-rich settings similar source-sink patterns can be observed, both in the migration related influxes and the new virus introductions in the heterosexual population from other risk groups. Namely, the immigration from a setting with a generalized epidemic to a setting with a concentrated epidemic is by far more likely than the emigration. Similarly, occasional spillovers from other risk groups, such as MSM and IDU, to the generalized population are more probable than the reverse. Therefore, the assumption of absence of such outflow from the epidemiological setting under consideration is not problematic when considering a country like Switzerland, but might present a potential limitation if the unit of interest is smaller, like a region or a city.
Our approach has theoretically several limitations, which we, however, expect to have only moderate impact. First, we assumed stuttering transmission chains, or in other words, that the basic reproductive number is below . If was larger than the observed transmission chains would have been much longer (see Sensitivity analyses and Appendix 1—figure 5) which is inconsistent with rather small clusters observed in HIV transmission among Swiss heterosexuals (Kouyos et al., 2010; von Wyl et al., 2011 and Shilaih et al., 2016). Second, some transmission chains might still be active, meaning that some patients from the chain could be still infectious and therefore able to further spread the virus. The consequence of this would be an underestimation of for recent years. However, given much higher transmissibility of HIV in the acute and recent infection (Marzel et al., 2016) and estimated mean time to being non-infectious of approximately — years in recent years (Stadler et al., 2012; Hughes et al., 2009) the majority of the observed transmission chains had most likely been stopped by the time of sampling and hence we do expect that this issue will not lead to a major bias of our estimates (see Sensitivity analyses and Appendix 1—figure 4). Third, since our method is based on transmission clusters their misidentification and negligence of their structure could be another constraint. Possible overlapping transmission chains (as it was also noted in Blumberg and Lloyd-Smith, 2013b), that is, misidentifying two transmission chains resulting from two separate introductions of closely related viruses as one single chain, represent the biggest concern in this regard. Failing to identify separate clusters would lead to a higher estimate. However, this means that our method will tend to overestimate and is hence conservative with respect to its main aim of assessing the danger of self-sustained epidemics; thus, if the method predicts an strongly below , the corresponding epidemic will indeed be far away from being self-sustained. Moreover, our method neglects the transmission chain structure and consequently uses only the aggregated number of infections, and assumes the same for the entire chain except for the index case. Yet, this issue is likely to have a weak impact, since we focus on subcritical transmission; the transmission chains are hence short (see Table 1), and their structure conveys only limited information. Indeed, although a huge variation in sexual behavior has been shown previously (Liljeros et al., 2001), our sensitivity analyses exhibited no major impact of varying sexual risk behavior on risk determinants (Sensitivity analyses and Appendix 1—figure 6). Finally, even though the negative binomial model was proposed as the favorable choice for the offspring distribution compared to the Poisson distribution (Blumberg and Lloyd-Smith, 2013b) we did not observe any significant differences in the estimates (see Sensitivity analyses and Appendix 1—figure 7). On the contrary, due to the simplicity of the Poisson distribution we managed to integrate the index case transmission potential reduction and the heterogeneity between the transmission chains into our Poisson-based model in a more systematic manner through the observed variability of the demographic characteristics.
Conclusion
Generally, our approach allows the assessment of the danger of a concentrated epidemic to become generalized based on the viral sequence data. We demonstrated this approach for the case of heterosexual HIV transmission in Switzerland. In particular, even though the study highlighted some heterogeneity between the HIV subtypes, our findings indicate that there is no imminent danger of a self-sustained epidemic among Swiss heterosexuals, but rather diminishing HIV transmission far below the epidemic threshold. Hence, the HIV epidemic in Switzerland is and most likely will remain restricted to high risk core groups, especially MSM. Moreover, the results suggest that integrated prevention measures in Switzerland taken over time were successful within the heterosexual population.
Materials and methods
We combined a phylogenetic cluster detection approach to identify transmission chains in the population under consideration with an adapted version of the model developed in Blumberg and Lloyd-Smith (2013a) to infer the basic reproductive number (Figure 5). In particular, we accounted for both imperfect detection (included in Blumberg and Lloyd-Smith, 2013a) and modified transmissibility of the index case (not included in Blumberg and Lloyd-Smith, 2013a) from the perspective of the setting under consideration because it enters the population only (late) in chronic infection – e.g., via immigration. Moreover, we included the baseline transmission chain characteristics (such as HIV-1 subtype, date of infection, time to diagnosis, risky sexual behavior, etc.) to explain the heterogeneity among transmission chains. Note that our approach in principle estimates the effective reproductive number defined as the number of secondary infections for the current state of population; however, in case of a non-self-sustained epidemic with low prevalence, the vast majority of the population is susceptible and hence the effective reproductive number is a very good approximation for the basic reproductive number.
Figure 5
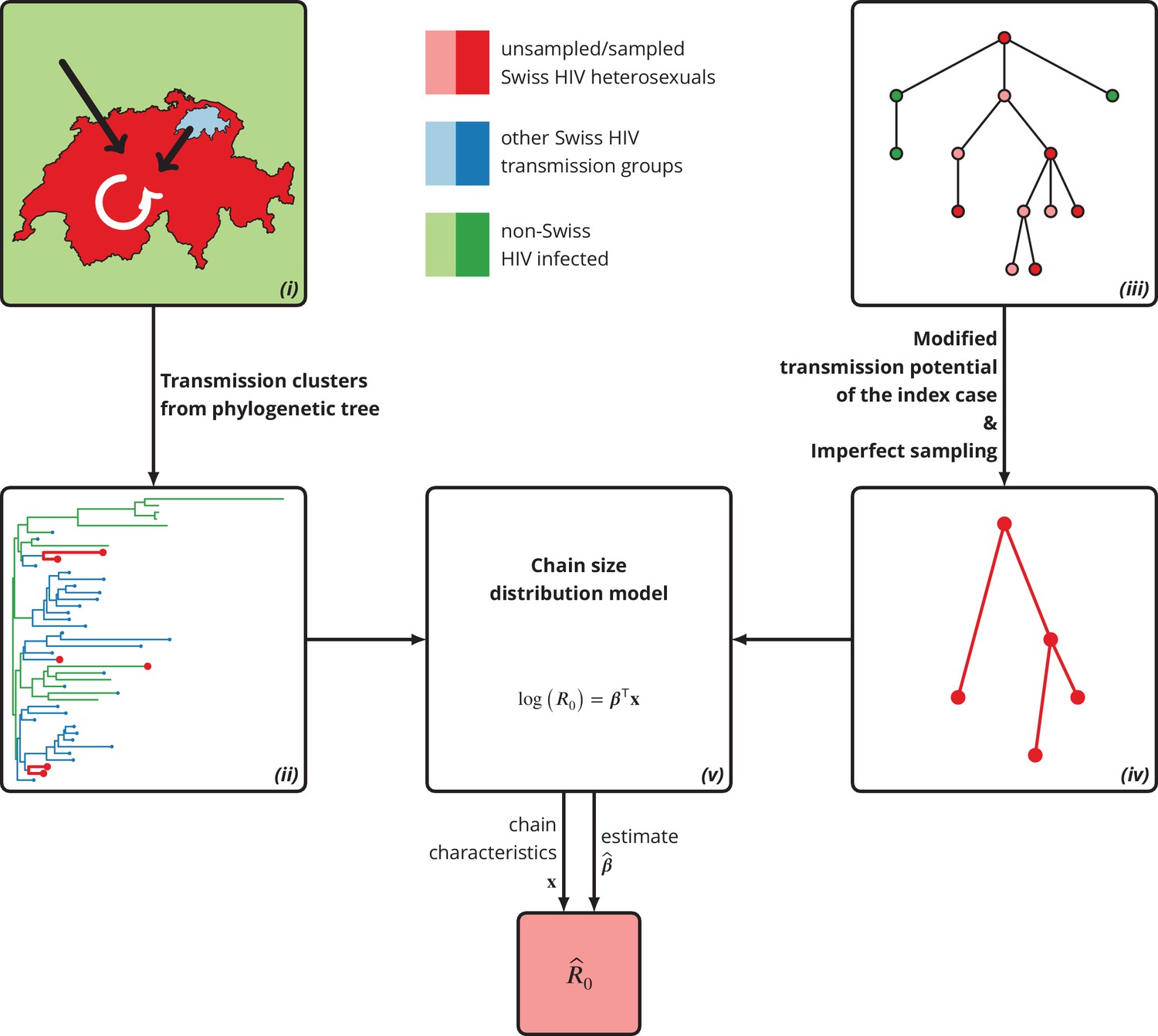
Graphical representation of our phylogeny-based statistical approach.
(i): HIV transmission among heterosexuals in Switzerland (white arrow) has never led to a self-sustained epidemic. However, the unknown potential of imported infections (black arrows) either from abroad or from other transmission groups in Switzerland remains a large concern. (ii): The HIV transmission chains corresponding to Swiss heterosexuals (depicted in red) were identified from the phylogenetic tree containing the SHCS and background viral sequences. (iii): Our mathematical model is based on the discrete-time branching process with nodes of three different types: sampled Swiss infection (red), unsampled Swiss infection (light red) and foreign infection infected by a Swiss index case before moving to Switzerland (green). (iv): Our method for inferring accounts for both imperfect sampling and modified transmission potential of the index case. (v): Moreover, it includes the baseline transmission chain characteristics to assess the determinants of .
SHCS and viral sequences
Request a detailed protocolThe SHCS is a multicenter, nationwide, prospective observational study of HIV infected individuals in Switzerland, established in 1988 (Swiss HIV Cohort Study et al., 2010). The SHCS was approved by the ethics committees of the participating institutions (Kantonale Ethikkommission Bern, Ethikkommission des Kantons St. Gallen, Comite Departemental d’Ethique des Specialites Medicales et de Medicine Communataire et de Premier Recours, Kantonale Ethikkommission Zürich, Repubblica e Cantone Ticino–Comitato Ethico Cantonale, Commission Cantonale d’Étique de la Recherche sur l’Être Humain, Ethikkommission beiderBasel; all approvals are available on http://www.shcs.ch/206-ethic-committee-approval-and-informed-consent), and written informed consent was obtained from all participants. Up to December 2016 over patients have been enrolled. The SHCS is highly-representative as it covers more than HIV-positive individuals on antiretroviral therapy (ART) in Switzerland (Swiss HIV Cohort Study et al., 2010). In addition to the extensive demographic and clinical data collected at biannual/quarterly follow-up (FUP) visits, for approximately of the patients at least one partial pol sequence from the genotypic resistance testing is available (in total sequences from the SHCS resistance database until August 2015). The patients with heterosexual contact as the most likely transmission route comprise about one third of all SHCS participants.
Phylogenetic tree
Request a detailed protocolThe phylogenetic tree was constructed from the Swiss HIV sequences of the SHCS patients and non-Swiss background sequences exported from the Los Alamos National Laboratory, 2016 database ( HIV-1 viral sequences of any subtype and including the circulating recombinant forms 01–74 retrieved on February 23rd, 2016 spanning over the protease and RT regions with fragments of at least nucleotides; the HXB2 sequence and sequences from Switzerland were removed afterwards). The sequences of HIV-1 subtypes and circulating recombinant forms (B, C, CRF01_AE, CRF02_AG, A(1-2)), G, D and F(1-2)) were pairwise aligned to the reference genome HXB2 (accession number K03455) using Muscle v3.8.31 (Edgar, 2004). Sequences with insufficient sequencing quality of the protease region (coverage of less than nucleotides between the positions and of HXB2) or reverse transcriptase region (less than nucleotides between positions and ) were excluded. Using the earliest available of the remaining sequences for each patient, the phylogenetic tree was built with the FastTree algorithm under the generalized time-reversible model of nucleotide evolution (Price et al., 2009) including SHCS and background sequences.
Transmission chains
Request a detailed protocolThe Swiss heterosexual transmission chains were defined as clusters in the phylogenetic tree containing exclusively Swiss HIV sequences from individuals with heterosexual contact as the most likely route of the transmission, regardless of the respective genetic distances and local support values (see Sensitivity analyses and Appendix 1—figure 8 for alternative definition). The transmission chains and the patients enrolled in the SHCS forming them were identified with custom written functions in R (version 3.3.2).
For each transmission chain we determined if it was introduced to the Swiss HIV heterosexuals either as an imported infection from abroad or from other HIV transmission groups within Switzerland. The geographic origin for a given chain was obtained as the country of the closest sequence, which did not belong to Swiss heterosexuals. Specifically, we considered the smallest clade that contained both the transmission chain and either a non-Swiss or non-heterosexual sequence, and chose the sequence with the smallest pairwise genetic distance to the transmission chain (with respect to the Jukes and Cantor (JC69) model).
Additionally, in each extracted transmission chain the observed index case was identified as the patient with the earliest estimated date of infection in the chain. The date of HIV infection for each single individual was imputed with the model described by Taffé et al. (2008) if the patient had enough CD4 cell count measurements before the ART initiation and the estimated date of infection fell within the seroconversion window; otherwise the midpoint of the seroconversion window was used. The demographic characteristics (Table 2) of the index case were extracted from the SHCS, including age at infection, time to diagnosis, first available CD4 cell count and sexual risk behavior. The latter was quantified as the fraction of semiannual follow-up visits at which the patient reported sex with occasional partners. The patients with no available questionnaire regarding the sexual risk behavior were assumed to have never reported on having sex with occasional partner (see Sensitivity analyses and Appendix 1—figure 9 for the corresponding sensitivity analysis). The characteristics of the index case were then used to define the features of each corresponding transmission chain.
Estimating the basic reproductive number from a model
Our model is based on the basic discrete-time branching process. The basic reproductive number was inferred from the model as the expected number of offsprings, therefore the offspring distribution represents the crucial component of the chain size distribution model. In the following sections we describe the main extensions of the basic branching process theory, which were implemented in our model. The detailed derivations can be found in Appendix 3.
Offspring distribution
Request a detailed protocolWe modeled the offspring distribution in a transmission chain using a Poisson distribution, which is a special case of the negative binomial distribution. The latter has been suggested in the literature (Blumberg and Lloyd-Smith, 2013b) in order to infer ; however since we did not observe any large differences between the two distributions (see Sensitivity analyses and Appendix 1—figure 7), we decided to use the simpler Poisson model.
Suppose that denotes the number of secondary infections of transmission degree caused by the th individual from the preceding generation (i.e., infected individuals with transmission degree ), where the transmission degree refers to the number of transmissions needed to transfer the pathogen from the index case (see Appendix 3 for detailed model description). Under the Poisson offspring distribution the number of secondary infections is modeled by
which coincides with the definition of the basic reproductive number . Some index cases may have lower transmission potential, e.g., immigrants that arrive during their chronic infection phase, while other index cases may exhibit enhanced transmissibility, for example, sex workers or foreigners living in Switzerland without a partner. To capture a potentially modified transmissibility of the index case we assumed a different offspring distribution of the root, namely
where denotes the index case relative transmission potential.
To assess the trends and determinants of , we further extended the offspring distribution based on the baseline characteristics of the transmission chain. More precisely, we assumed that the logarithm of can be linearly described by the chain characteristics which resulted in the offspring distributions
for the secondary and the index cases, respectively. Hence, the can be predicted from the effect sizes of factors as
Note that since each transmission chain has its specific baseline characteristics (perhaps even sampling density and index case relative transmission potential ) the notation above represents a simplification. More precisely, the of the th transmission chain equals .
Likelihood function
Request a detailed protocolThe likelihood function was expressed in terms of the probability generating function (PGF) of the transmission chain size distribution assuming independent and stuttering (i.e., assures that each transmission chain goes extinct almost surely) transmission chains. The following assumptions were made when incorporating the incomplete sampling of the sequences:
For each transmission chain at most one observed transmission chain can be extracted from the phylogeny. In other words, all observed cases belonging to the same transmission chain can be identified as the cases forming the corresponding observed transmission chain, although some intermediate transmitters might not have been sampled. For a phylogeny, this represents by a definition a weak assumption; in contrast, for contact tracing approaches missing one ancestor can lead to misidentifying one transmission chain as two or more.
The sampling density is independent of the transmission chain size or the transmission degree of the individual, namely each case of the transmission chain can be observed independently from the rest of the chain with probability .
Let denote the true size of a transmission chain and the size of the corresponding observed transmission chain. The above two assumptions can be summarized as
and the PGF of the observed transmission chain size hence equals
in terms of the PGF of . The probability that a transmission chain has observed size of (where means that none of the cases of the transmission chain is detected) is given by
In particular, the probability that a transmission chain is observed (i.e., the observed size is strictly positive) can be calculated as
However, since only the transmission chains with at least one detected case can be extracted from the phylogeny (and therefore to account for the unobserved transmission chains) we are interested in the probability that an observed transmission chain has a specific size. The probability of observing a transmission chain of size is
Finally, for a set of independent observed transmission chain sizes the likelihood function equals
if the same , and are assumed for all transmission chains. For transmission chains with different baseline characteristics and different parameters, the generalized likelihood function is
Model fit
Request a detailed protocolThe maximum likelihood (ML) estimator for , the predictor for and the corresponding statistics (confidence intervals, -values, etc.) were implemented in the R package PoisTransCh (Turk, 2017, https://github.com/tejaturk/PoisTransCh; copy archived at https://github.com/elifesciences-publications/PoisTransCh). The provided confidence intervals are the Wald-type -confidence intervals (see Sensitivity analyses for the comparison against different types) and the -values are based on the Wald statistic. Initially, we assessed the impact of covariables potentially associated with HIV transmission. Specifically, we considered HIV-1 subtype, establishment date of the transmission chain (i.e., the earliest estimated date of infection in the transmission chain), reported sex with occasional partner, age at infection, first measured CD4 cell count and time to diagnosis of the index case. Final model selection was carried out by the forward selection and backward elimination algorithms based on the Akaike and Bayesian information criterion (AIC and BIC, respectively). The detailed steps are provided in Selection of the predictive models.
Datasets
Request a detailed protocolPreviously published datasets from Kouyos et al. (2010) and von Wyl et al. (2011) were used in this study. As previously discussed in these publications, due to the large sampling density this data would, in principle, allow for the reconstruction of entire transmission networks and could thereby endanger the privacy of the patients. This is especially problematic because HIV-1 sequences frequently have been used in court cases. Therefore, a random subset of 10% of the sequences are accessible via GenBank. These accession numbers are as follows: GU344102-GU344671, EF449787, EF449788, EF449796, EF449798, EF449828, EF449829, EF449838, EF449844, EF449852, EF449853, EF449854, EF449860, EF449880, EF449883, EF449889, EF449895, EF449901, EF449904, EF449905, EF449917, EF449921, EF449928, EF449930, EF449943, EF449950, EF449960, EF449971, EF449980, EF449987, EF450004, EF450005, EF450011, EF450024, EF450026, GQ848113, GQ848120, GQ848140, GQ848145, GQ848149, JF769777-JF769851
Appendix 1
Sensitivity analyses
Relative transmission potential of the index case
To assess the role of the index case relative transmission potential we carried out three different sensitivity analyses regarding parameter . Firstly, we varied the for the transmission chains of non-Swiss origin from to . Secondly, we assumed the same for all transmission chains regardless of their origin and fit the models over a range of values. Finally, we restricted the analysis only to the transmission chains of non-Swiss origin and varied .
Appendix 1—figure 1
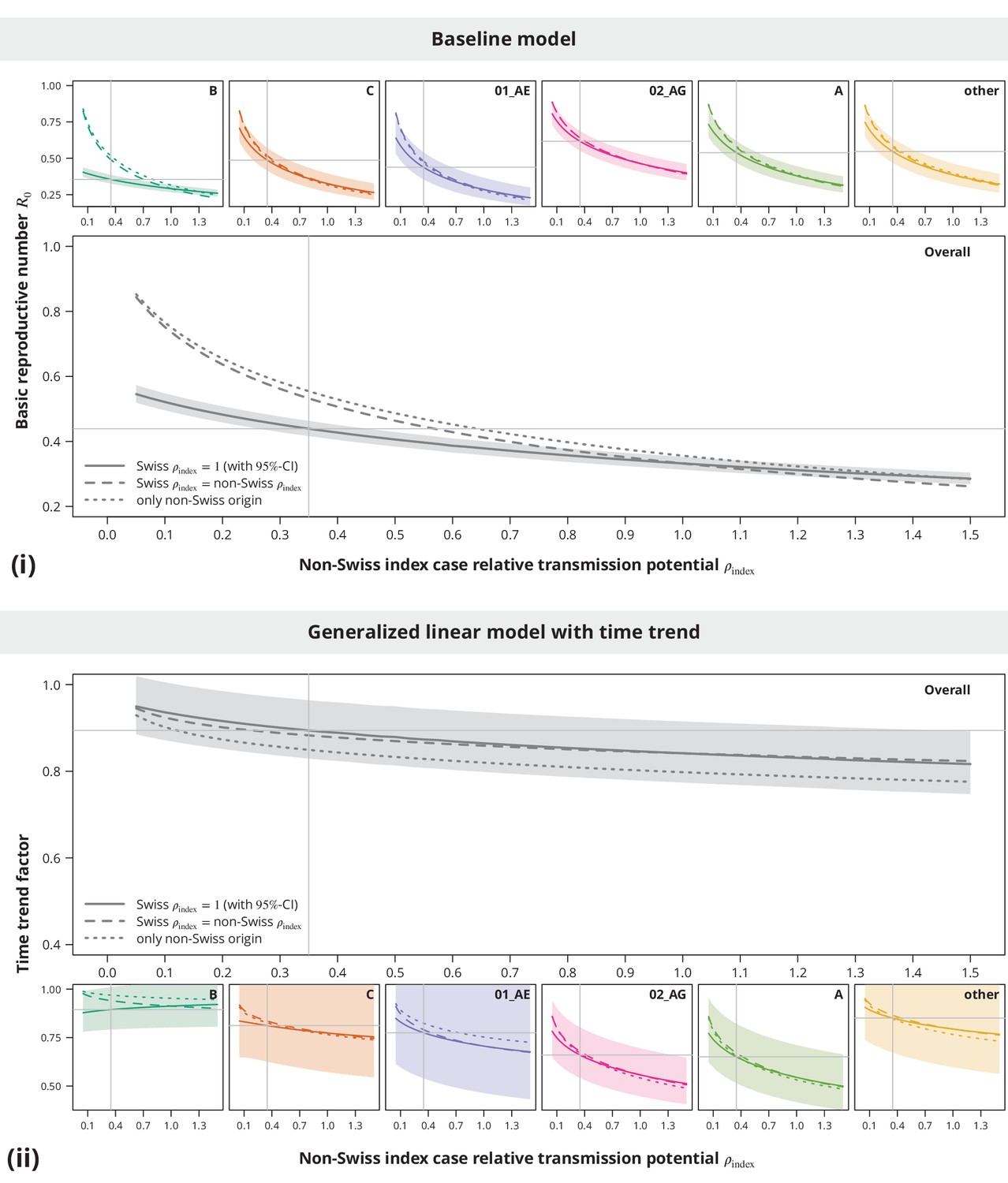
Sensitivity analysis regarding the index case relative transmission potential.
Panel (i) shows the sensitivity of the estimates from baseline model and panel (ii) the sensitivity of the time trend factor. The colored lines represent the subtype-stratified analyses, while the results from the overall models are shown in gray. In the first sensitivity analysis, the of Swiss-originating transmission chains was held at and the of non-Swiss origin varied (solid lines). In the second analysis, the of Swiss and non-Swiss origin was the same (dashed lines). The dotted lines show the results from the sensitivity subanalysis including only the transmission chains of non-Swiss origin. The vertical and horizontal lines depict the parameters and estimates from the main analysis, respectively.
These sensitivity analyses (see Appendix 1—figure 1) implied that the conclusion of no danger for a self-sustained epidemic is stable with respect to even in the case when some of the Swiss-originated transmission chains are misclassified. In addition, while slightly higher estimates in the non-Swiss transmission chain subanalysis were mostly driven by the non-B subtypes, the results were safely below indicating the non-sensitivity of the main conclusion also when some non-Swiss transmission chains would be falsely identified as such.
Sampling density
To study the impact of the sampling densities we performed subtype-stratified sensitivity analyses as well as the overall sensitivity analysis by keeping the sampling density constant among the transmission chains. In all scenarios, we varied the sampling density between and , while remained the same as in the main analyses.
Appendix 1—figure 2
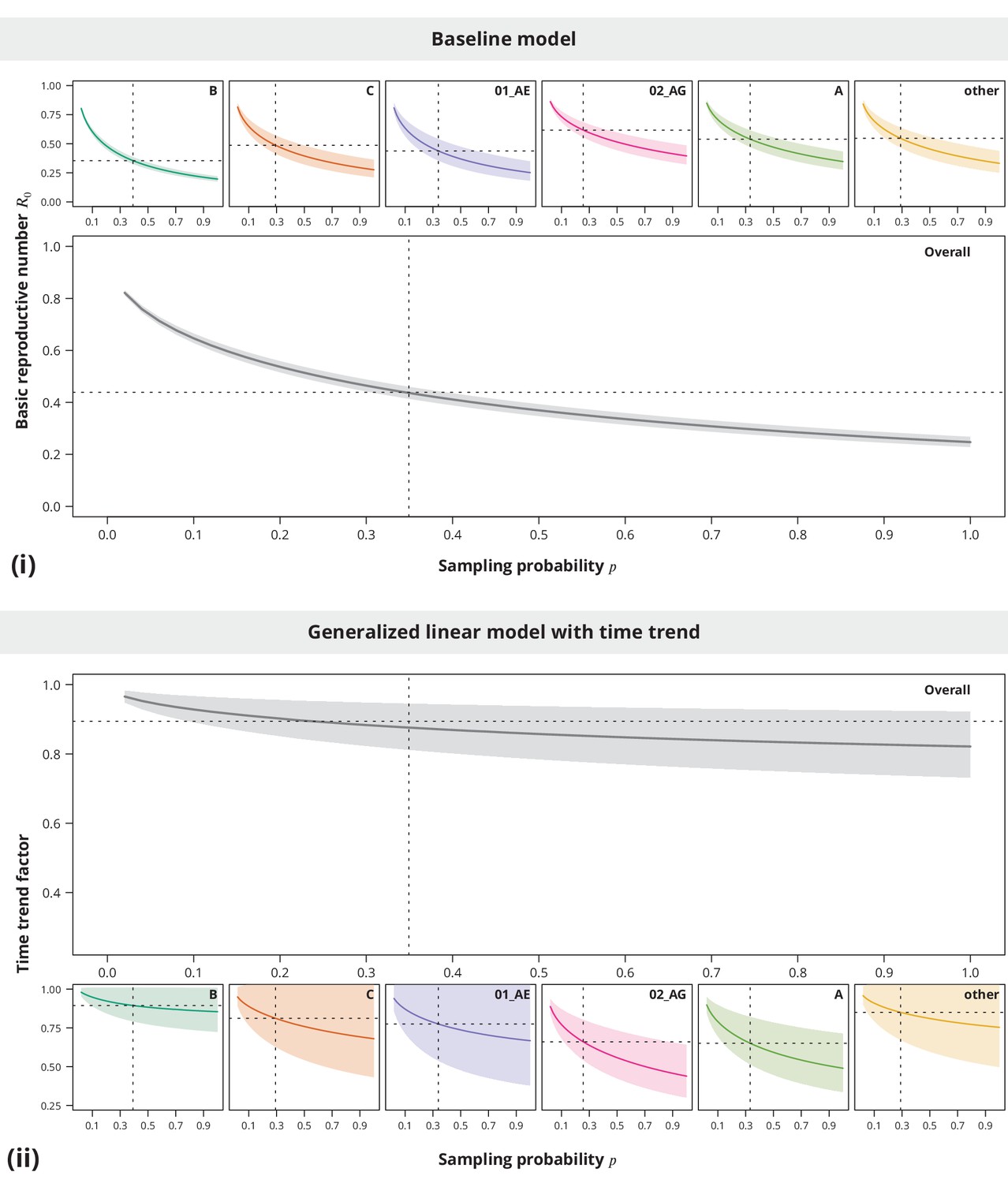
Sensitivity analysis regarding the sampling density.
The index case relative transmission potential parameter was the same as used in the main analyses, while the sampling densities varied (-axis). In the pooled analysis (larger plots) the sampling density was the same for all transmission chains. Panel (i) shows the corresponding estimates of the basic reproductive number and the time trend factor estimates are displayed in panel (ii). The dotted vertical lines depict the sampling densities used for each subtype in our study (subtype-stratified plots) and the mean sampling density over all transmission chains (overall plots). The horizontal dotted lines represent the estimates from the main analysis.
The sensitivity analyses (see Appendix 1—figure 2) showed that neither the from the baseline model nor the time trend are sensitive to the sampling density, namely the conclusions of being significantly below and decreasing time trend could be made even for slightly lower or higher sampling densities.
Ongoing transmission and stuttering transmission chains assumption
Duration of infectious period in relation to ongoing transmission
Some of the observed transmission chains may still experience ongoing transmission due to either not yet diagnosed cases or unsuppressed patients within the transmission chain who still have the ability to spread the virus. The transmission chain sizes might thus be too small and underestimated. However, the gradually increasing treatment success (Castilla et al., 2005; Kohler et al., 2015), benefits of earlier ART initiation (Kitahata et al., 2009; INSIGHT START Study Group et al., 2015) and consequently updated treatment guidelines (Günthard et al., 2016) resulted in a shorter duration of infectious period. Transmission chains which started earlier are thus more strongly affected by ongoing transmission than recent transmission clusters.
One possibility to assess this issue is to investigate the highest possible transmission degree that has completed a transmission at a given time point; that is the maximum number of generations which are not infectious anymore and therefore have used their transmission potential. We assumed that the length of the infectious period is changing linearly with calendar year and fitted a linear regression model to the duration of infectious period of the index cases (measured by time to suppression or treatment start). To ensure a more conservative approach we truncated the fitted infectious period durations from below, such that the minimum was years. Let define the infectious period duration of an individual who became infected at time . The worst-case scenario in the context of ongoing transmission and related potential bias is represented by a transmission chain, in which each infected individual transmits the virus just at the end of his/her infectious period. The (conservative) maximum number of completed transmission degrees at time of a transmission chain that started at therefore equals
where denotes the latest possible time at which the transmission of the th generation was complete and is calculated iteratively as for (Appendix 1—figure 3). If its index case is still infectious at time , it can still produce new infections (which would have a transmission degree ) and hence .
Appendix 1—figure 3
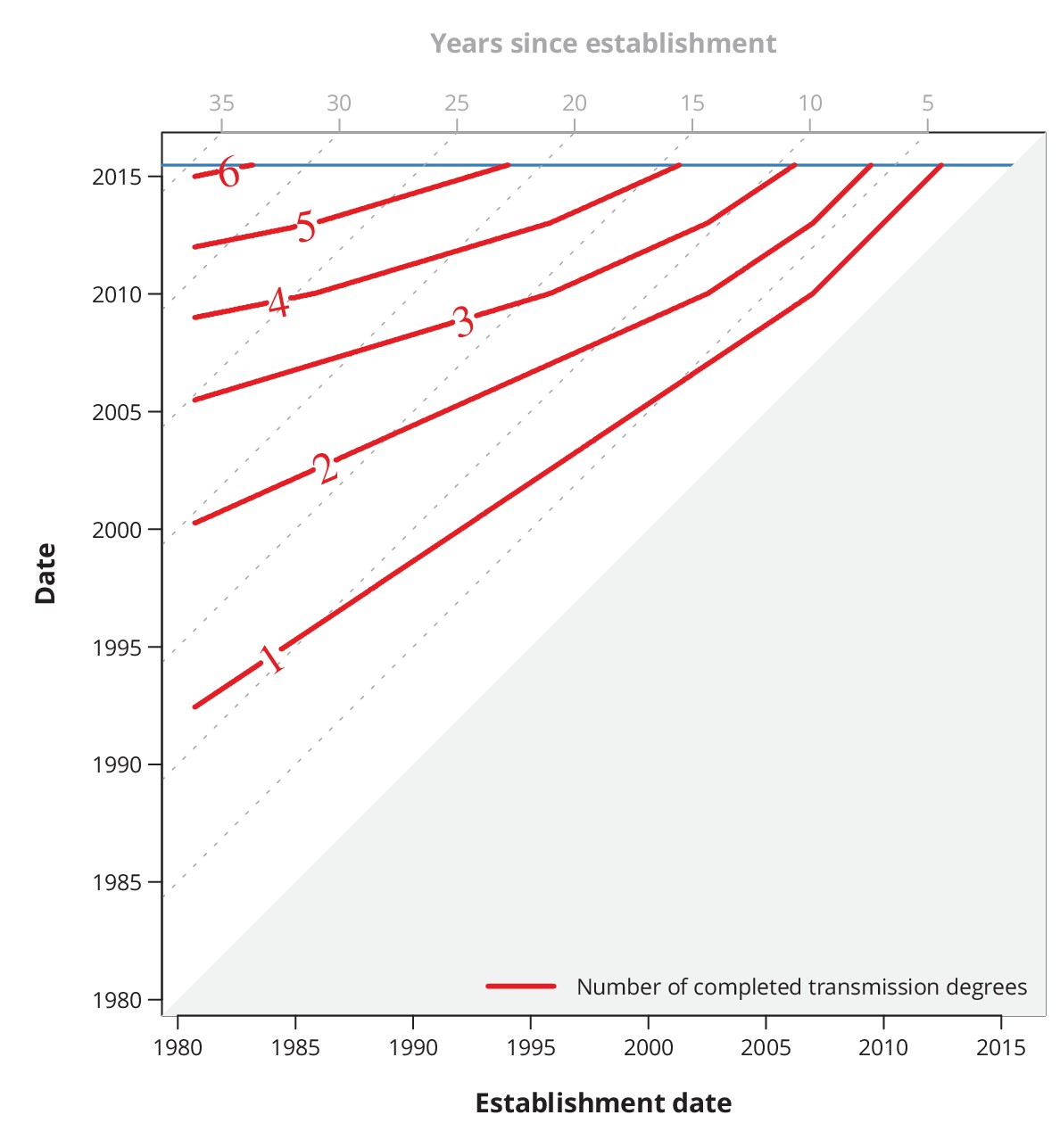
Conservative (with respect to ongoing transmission) maximum number of completed transmission degrees by a given date.
The red lines show the date (-axis) by which at least a certain number (red numbers) of transmission degrees have been completed for a transmission chain with a specific establishment date (-axis). The diagonal dotted gray lines depict the number of years since the establishment date, and the horizontal blue line represents the last sampling date.
Ongoing transmission
To assess the potential bias due to ongoing transmission we compared the estimates based on the transmission chains formed by the cases with the estimated date of infection before a specific date () and based on the transmission chains that had been completed (with respect to the last sampling date) by the same date (). The relative bias arising from neglecting the ongoing transmission hence equals
Appendix 1—figure 4
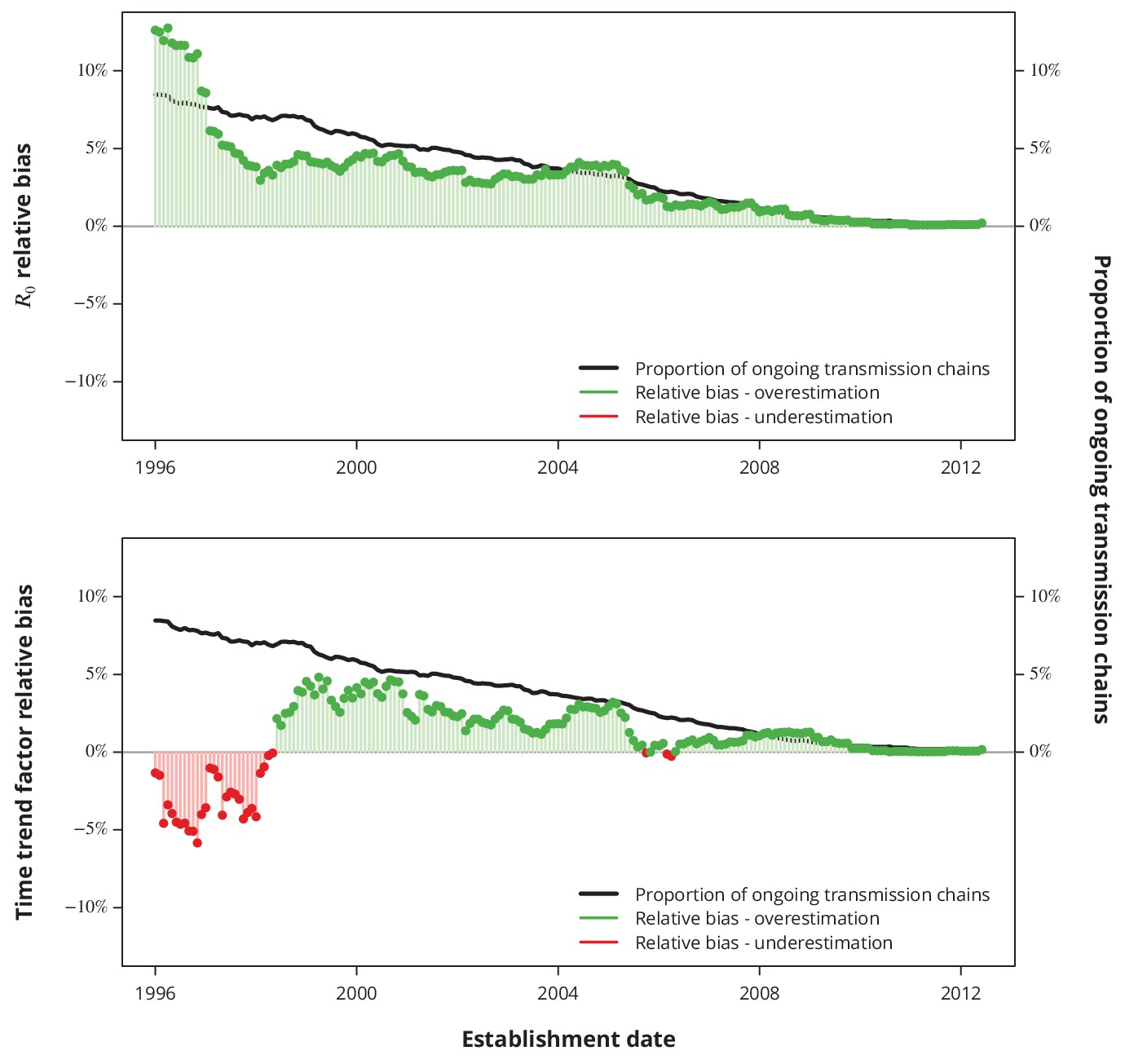
Relative bias due to ongoing transmission.
The upper panel shows the relative bias of the basic reproductive number from the baseline model and the lower panel the relative bias of the linear time trend factor from the corresponding generalized linear model. The proportion of active transmission chains over time is represented by the black line. The relative bias associated with overestimation and underestimation is displayed with green and red bars-points, respectively. Absence of bias is depicted by the horizontal gray lines.
The proportion of ongoing transmission chains is decreasing with time, which is in line with a decreasing duration of infectious period, hence indicating that the ongoing transmission is less of an issue for recent years than for older transmission chains. Our sensitivity analyses revealed that the expected bias stemming from neglecting the ongoing transmission is less than since the early 2000’s for both key questions (Appendix 1—figure 4): the basic reproductive number and its linear time trend factor. Moreover, the relative bias is positive for most of the recent dates, implying that the negligence of ongoing transmission results in rather conservative estimates with respect to our conclusions.
Subcritical transmission assumption
Like the models described by Blumberg and Lloyd-Smith (Blumberg and Lloyd-Smith, 2013b; Blumberg and Lloyd-Smith, 2013a), our model also implicitly assumes subcritical transmission. To justify that the extracted HIV transmission chain sizes of the Swiss heterosexuals did not violate this assumption, we simulated transmission chains for various (including the estimated ) and compared the empirical quantiles between the simulated transmission chain sizes and the transmission chain sizes extracted from the phylogenetic tree. Since some transmission chains (observed or simulated) might still exhibit ongoing transmission at the time of the sampling, we restricted the maximal number of generations (i.e., transmission degrees), which were simulated according to the duration of infectious periods (Appendix 1—figure 3).
More precisely, from each observed Swiss heterosexual transmission chain we kept sampling transmission chains (for different ‘known true’ scenarios) with the maximal number of simulated generations until a simulated transmission chain was observed (i.e., at least one case was observed) to reflect the more realistic observed transmission chain size distribution. We repeated these steps for each extracted Swiss heterosexual transmission chain.
Appendix 1—figure 5
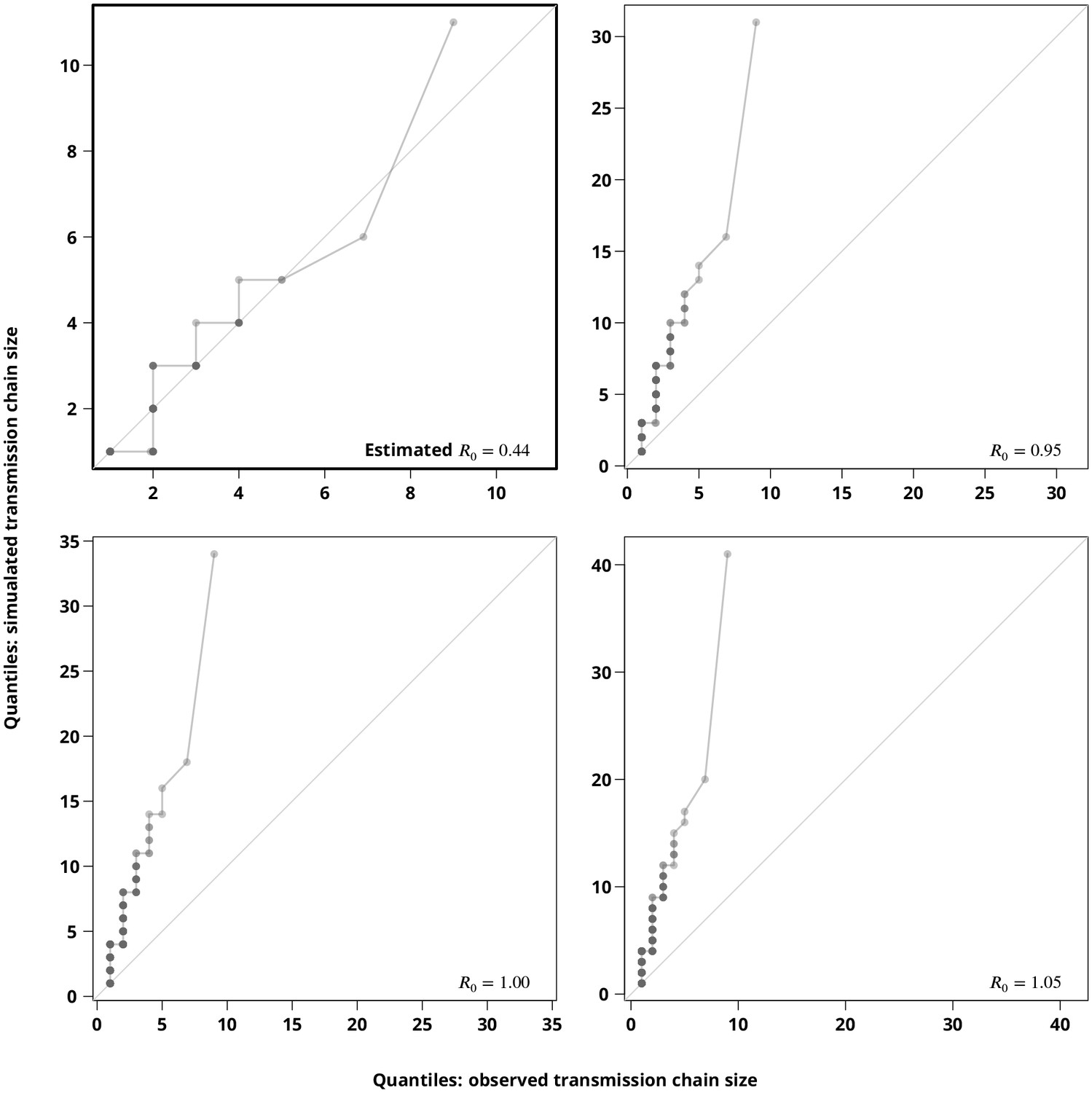
Sensitivity analysis regarding the stuttering transmission chains assumption.
The Q-Q plots compare the hypothetical transmission chain size distributions (-axis showing their empirical permilles) with the transmission chain size distribution (empirical permilles on the -axis) inferred from the phylogeny. The upper left plot compares the distribution of the simulated transmission chain sizes based on the estimated with the (from the phylogeny) observed transmission chain sizes and thus verifies the estimate. The remaining plots compare the simulated transmission chain size distributions against the extracted transmission chain sizes for closer to to justify the subcritical transmission assumption. Each point represents a permille, hence the darker points indicate more overlapping permilles.
Finally, we compared the -quantiles (permilles) of the transmission clusters extracted from the phylogeny against simulated transmission chains (Appendix 1—figure 5). The Q-Q plots clearly show that the extracted transmission chains would be indeed much longer (the largest observed transmission chain would be of size greater than ) if the true were above (or even close to ). Moreover, the size distribution of the transmission chains simulated for the estimated showed a good concordance with the observed transmission chains (upper left Q-Q plot of Appendix 1—figure 5).
Variation in sexual behavior along transmission chains
Our model assumes constant sexual risk behavior along transmission chains. In this sensitivity analysis we assessed how a changing sexual risk behavior would affect our conclusions. We approached this question by slightly changing the definition of the sexual risk behavior of each transmission chain, while the other characteristics stayed the same.
Instead of the index case determining the risk behavior for each transmission chain a randomly sampled infected individual from the transmission chain was chosen to determine the sexual risk behavior of the transmission chain. Noteworthy, this only affects the minority of the transmission chains, namely those with the observed length . The multivariate model including only the linear terms was then fitted to the transmission chains with slightly modified sexual risk behaviors. We repeated this times to get the empirical distribution of the effect sizes on (Appendix 1—figure 6).
We considered the reported sex with an occasional partner on the level of a transmission chain as a proxy for its sexual risk behavior. More precisely, we used the fraction of FUPs of all infected individuals in a transmission chain in which any of these patients reported sex with occasional partner. We then fitted the same multivariate model with only linear terms as in the main analysis and compared the effect sizes and directions (Appendix 1—figure 6).
Appendix 1—figure 6
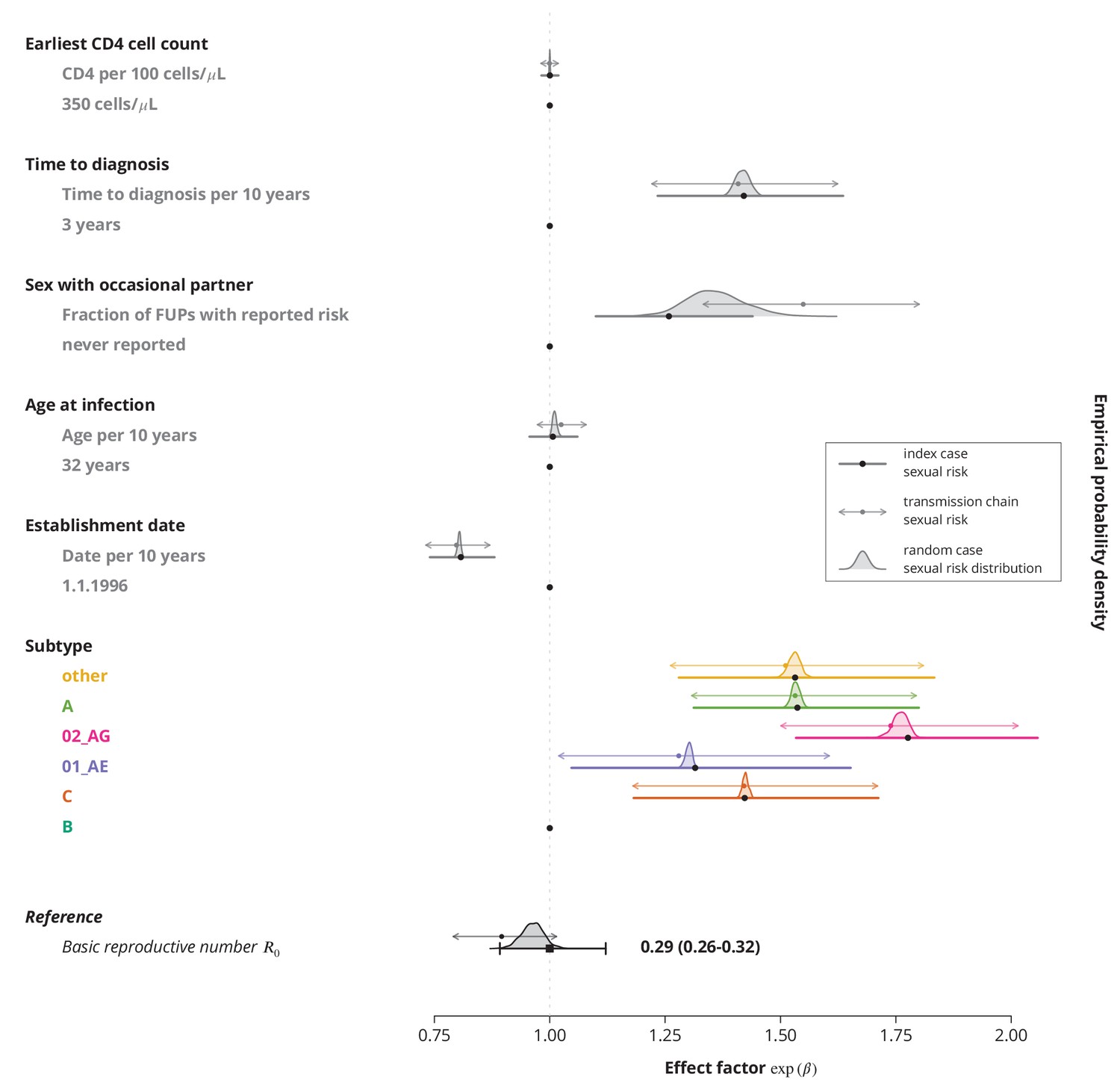
Comparison of effect sizes in the multivariate model with linear terms only for different sexual risk behavior definitions of a transmission chain.
The thick lines with black circles show the original effect sizes (where the index case determined the sexual risk behavior of the transmission chain) and their -confidence intervals. The empirical distribution of the effect sizes where a random individual in a transmission chain determines its sexual risk behavior is displayed by the shaded areas. The thinner horizontal double sided arrows with the filled circles correspond to the effect sizes and their -confidence intervals for the transmission chain level fraction of follow-up visits (FUPs) with reported sex with occasional partner by any of the infected individuals from the transmission chain. The vertical dotted gray line depicts the reference from the original model, i.e., using the index case to define the sexual risk behavior.
Our transmission chains are short in size; therefore we did not expect to see a huge impact of the variations in sexual behavior on the effects. Indeed, the analyses revealed that even with the modified definitions of the risky sexual behavior (and therefore addressing its variation) the effect directions did not change, while the effects sizes did not exhibit a huge difference. In particular, the significance of all risk determinants at the level remained the same.
These findings indicate that the simplification of the equal distribution for the number of secondary infections does not exhibit a dramatic impact on the outcomes in the case of short transmission chains, which dominate in subcritical settings.
Comparison between Poisson and negative binomial offspring distribution based models
To evaluate the rationale of using the simpler Poisson model we compared the estimates from the baseline models over a range of sampling densities for both Poisson and negative binomial offspring distribution. Since an implementation with modified transmission potential of the index case is not available for the negative binomial model, we conducted the sensitivity analyses with a fixed .
Appendix 1—figure 7
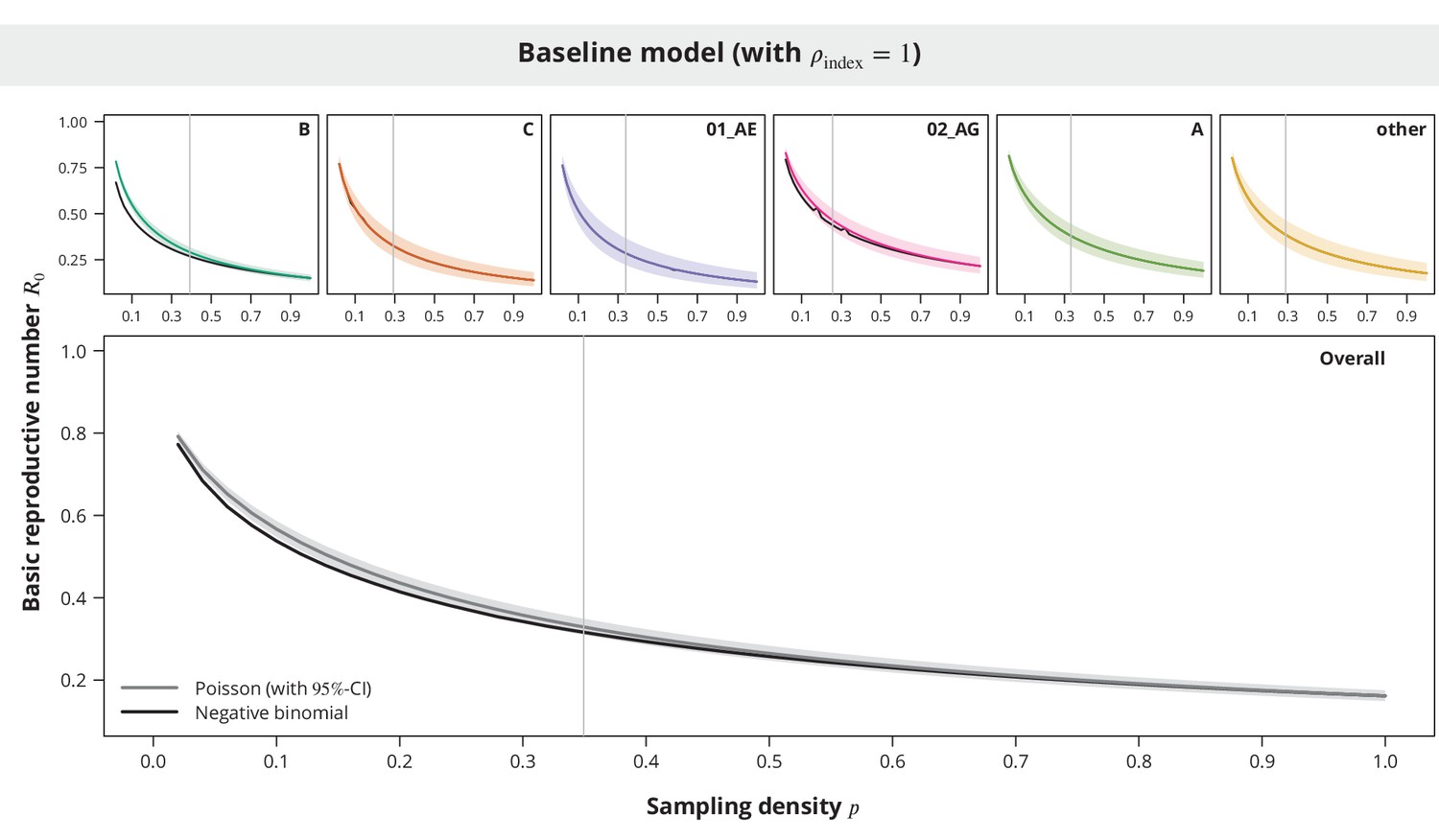
Comparison between the Poisson and the negative binomial offspring distribution baseline model estimates.
The dark gray and colored lines show the estimates from the model with Poisson offspring distribution, while the black lines correspond to the negative binomial distribution. The index case relative transmission potential parameter was fixed to and the sampling density (-axis) varied. In the overall analysis the sampling density was the same for all transmission chains regardless of their subtype. The vertical gray lines depict the sampling densities used for each subtype in our study (above panels) and the mean sampling density in the overall analysis (bottom panel).
While the estimates for the majority of the non-B subtypes were practically equal between the two models (see Appendix 1—figure 7), the observed differences in the overall analysis and in the case of B and 02_AG subtypes were mostly larger for low sampling densities. However, we also found that the Poisson model provided rather conservative estimates and therefore this should not affect our main conclusions.
In addition, we performed a likelihood ratio test to evaluate if the multivariate linear negative binomial model (with ) is significantly better than the corresponding Poisson model (from Figure 3). The -value of indicated no strong preference of the negative binomial over the Poisson model. Noteworthy, this implies that modelling the variability among the transmission chains in terms of their characteristics sufficiently explains the heterogeneity (dispersion parameter of the negative binomial distribution) between the infected heterosexuals forming these transmission chains.
Relaxed transmission cluster definition
We defined the Swiss heterosexual transmission chains as clusters on the phylogeny containing viral sequences belonging to Swiss heterosexuals. To assess the impact of this definition we relaxed the threshold to . All the sequences belonging to the Swiss heterosexuals from these clusters formed more liberally defined transmission chains.
Appendix 1—figure 8
Sensitivity analysis regarding the transmission cluster definition.
The upper panel (i) compares the estimated with the original cluster definition (brighter lines) with the estimated based on the relaxed cluster definition (darker lines) from the overall analysis (in gray) and subtype-stratified analyses (in colors). Similarly, the bottom panel (ii) shows the comparison between the estimated time trend factors obtained from the transmission chain sizes based on different cluster definition thresholds.
With the relaxed threshold, we identified transmission chains and repeated the main analyses (Appendix 1—figure 8). As expected the slightly increased, but stayed below . Overall, we did not observe any noteworthy deviations.
Missing follow-up data for reported sex with occasional partner
In the main analysis of the possible determinants of HIV transmission we imputed missing follow-up information regarding sex with occasional partner with never reporting it (which is equivalent to reporting rate). To evaluate this imputation, we fitted the same multivariate model with linear terms to the subset of the transmission chains in which the data about the sex with occasional partner of the index case was available. However, the effect sizes did not change dramatically; in particular, the effect directions did not change and the same set of determinants was found to be significant (Appendix 1—figure 9).
Appendix 1—figure 9
Subanalysis for the transmission chains with available follow-up information about sex with occasional partner of the index case compared to the main analysis with imputed data.
The effect sizes from the subanalysis are shown in brighter colors and those from the main analysis in dark. In the main analysis, the missing data were replaced by never reporting sex with an occasional partner.
Confidence intervals
In our study we used the normal approximation of the ML estimator to construct the -CIs and the prediction intervals. To verify the reliability of this assumption we considered bootstrap and profile likelihood based CIs for each of the models.
For the parametric bootstrap, we sampled new datasets of transmission chains from the estimated transmission parameters (i.e., under the assumption that our estimated parameters are the true parameters) for each model. To ensure that the newly sampled datasets had the same sample size, in each repetition we kept simulating from each transmission chain until the new transmission chain had at least one observed infection (i.e., such that the observed length was positive). Finally, for each sampled dataset we fitted the same model, extracted the estimated transmission parameters and the corresponding Wald-type -CIs. The overview of the parameters and the models is provided in Appendix 1—table 1.
Appendix 1—table 1
Overview of all the parameters, their estimates and the -confidence intervals fitted in all the models presented in this study.
https://doi.org/10.7554/eLife.28721.021| Subtypes | Parameter number | Parameter name | Parameter estimate | Wald-type -CI | Profile likelihood -CI |
|---|---|---|---|---|---|
| Overall | 1 | ||||
| B | 2 | ||||
| C | 3 | ||||
| 01_AE | 4 | ||||
| 02_AG | 5 | ||||
| A | 6 | ||||
| other | 7 | ||||
| Overall | 8 | ||||
| 9 | |||||
| B | 10 | ||||
| 11 | |||||
| C | 12 | ||||
| 13 | |||||
| 01_AE | 14 | ||||
| 15 | |||||
| 02_AG | 16 | ||||
| 17 | |||||
| A | 18 | ||||
| 19 | |||||
| other | 20 | ||||
| 21 | |||||
| Overall | 22 | ||||
| 23 | |||||
| 24 | |||||
| Overall | 25 | ||||
| 26 | |||||
| 27 | |||||
| 28 | |||||
| 29 | |||||
| 30 | |||||
| 31 | |||||
| 32 | |||||
| 33 | |||||
| 34 | |||||
| 35 | |||||
| Overall | 36 | ||||
| 37 | |||||
| 38 | |||||
| 39 | |||||
| 40 | |||||
| 41 | |||||
| 42 | |||||
| 43 | |||||
| 44 | |||||
| 45 |
For a single parameter (under the assumption that the true value equals the estimated value ) we therefore obtained a sample of ML estimators , from which we estimated the kernel densities and compared them to the normal approximation densities used in the Wald CIs construction (Appendix 1—figure 10). Moreover, from the sample of Wald-type -CIs we calculated the coverage rate as the proportion of these CIs that contained the true value .
Appendix 1—figure 10
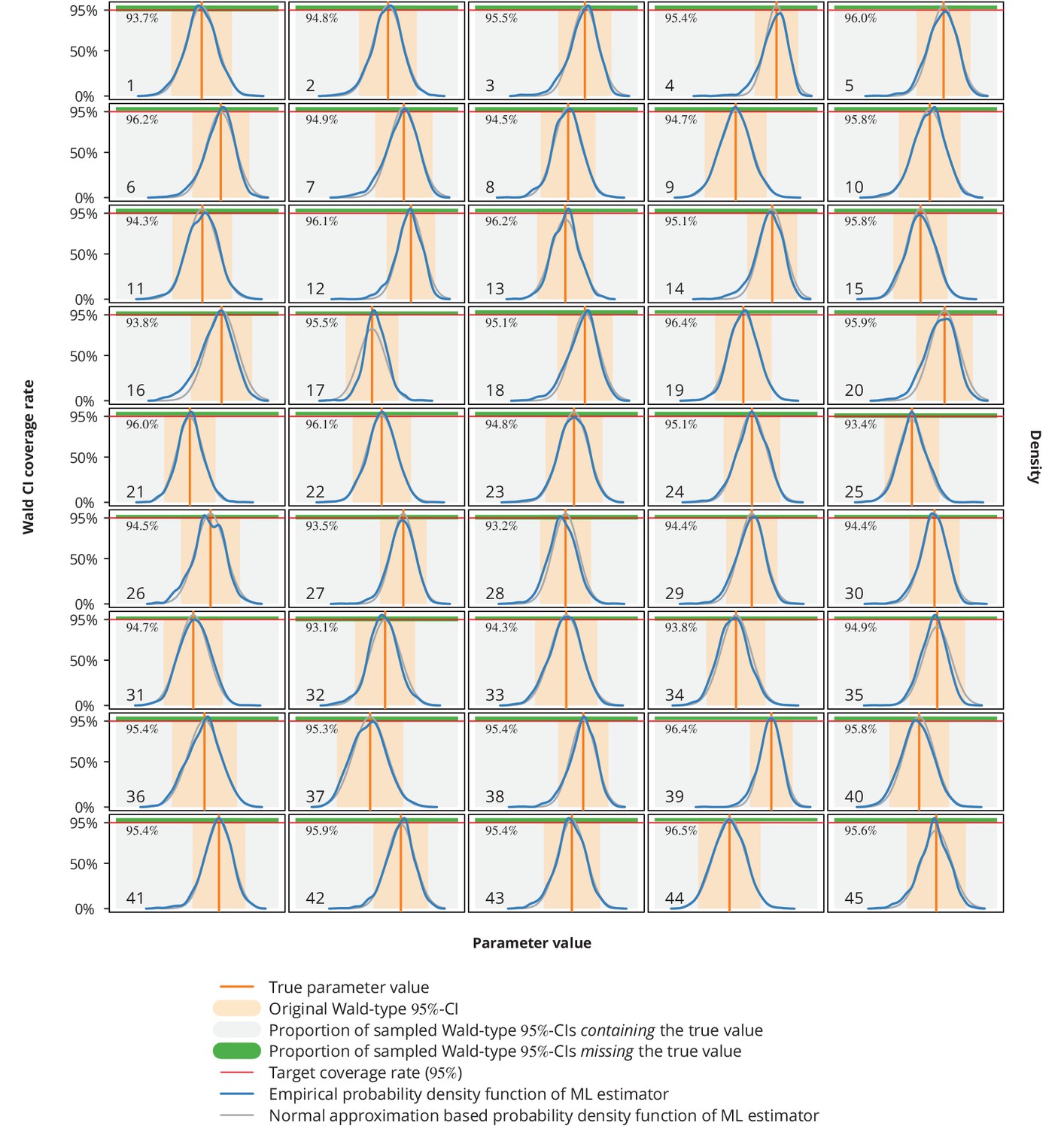
Empirical distribution of maximum likelihood (ML) estimator and the Wald-type confidence intervals (CI) coverage rates.
Each plot represents a single parameter from a single model (see Appendix 1—table 1 for the parameters overview including their values), where the number in the lower left corner denotes the parameter’s consecutive parameter number. The light gray-shaded area represents the proportion of the Wald-type -CIs from the parametric bootstrap simulations which contained the true value (depicted by the vertical orange line), while the green-shaded area corresponds to those CIs from the simulations that missed the true value. The numbers in the upper left corners are the coverage rates from the parametric bootstrap. The original Wald -CIs used in our study are displayed with the light orange-area. The dark blue and gray lines show the empirical distribution of ML estimators from the parametric bootstrap samples and the normal approximation based probability density function, respectively. The horizontal red lines depict the target coverage rate of .
Comparing the empirical distribution of the ML estimator from these simulations (Appendix 1—figure 10) with the normal approximation from the Wald test, we concluded that the latter represents a valid approximation. In addition, the coverage rates were all very close to the target or above.
Next, in addition to the parametric bootstrap as described above, we also performed a nonparametric bootstrap. New datasets were generated by randomly sampling with replacement from the existing dataset. To each newly sampled dataset all the models were fitted to obtain nonparametric bootstrap samples of ML estimators for each individual transmission parameter from Appendix 1—table 1. We then constructed the basic bootstrap -CIs (Davison and Hinkley, 1997) as
where denotes the corresponding percentile of the bootstrap sample . Finally, we constructed the profile likelihood based CIs (Held and Bové, 2013) and compared different types of CIs against the Wald-type CIs (Appendix 1—figure 11).
Appendix 1—figure 11
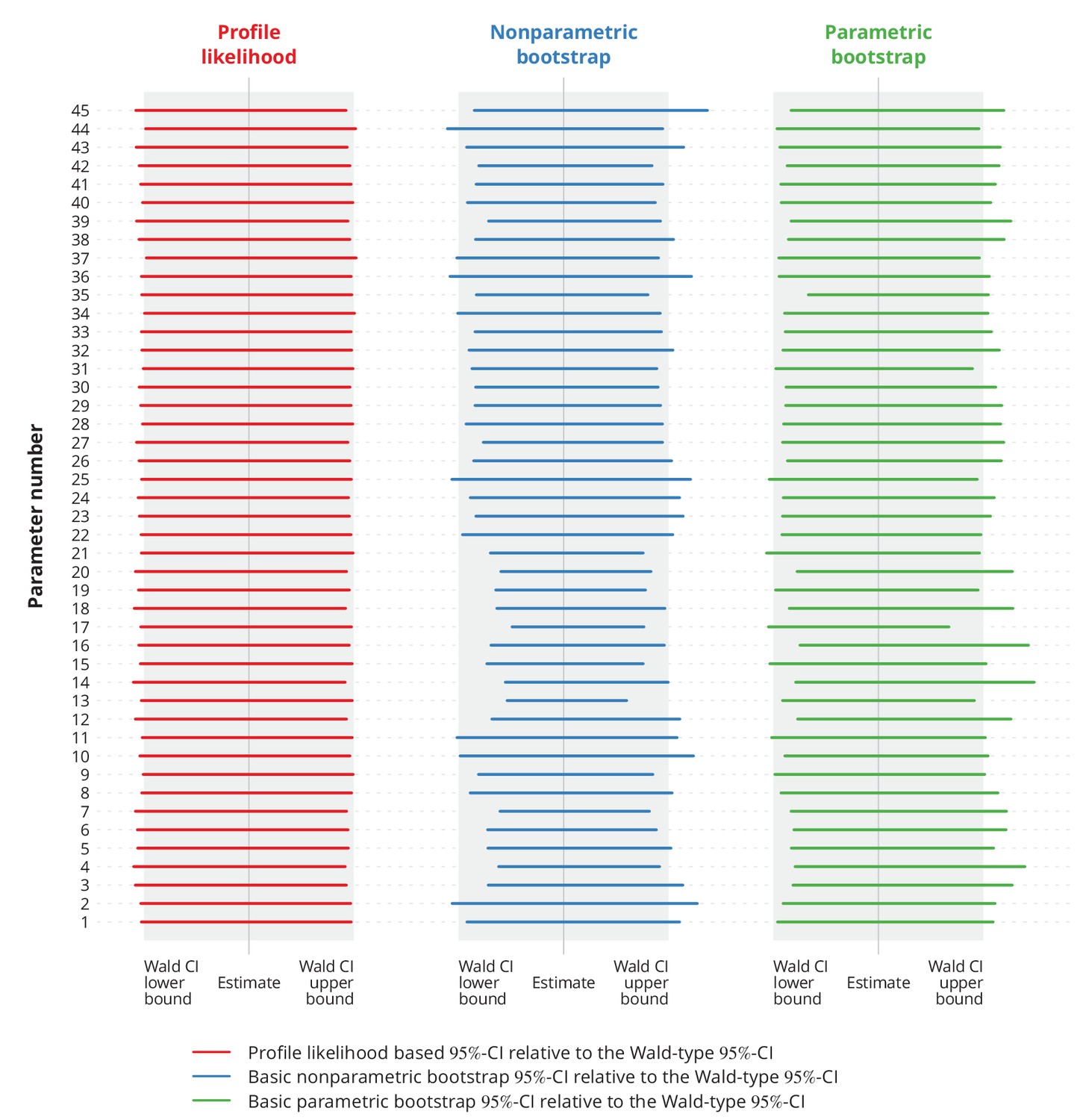
Comparison of different types of -confidence intervals (CI) with the normal approximation based Wald-type -CIs.
Each column corresponds to a different type of CIs, namely the profile likelihood based CIs, the basic nonparametric bootstrap CIs and the basic parametric bootstrap CIs. Each row represents a single parameter (the overview of the parameters is provided in Appendix 1—table 1). The colorful lines show the specific CIs compared to the corresponding Wald-type CIs, namely their relative widths and positions. The gray-shaded areas represent the Wald-type -CIs.
These simulations indicated no significant difference between the widths of Wald-type and profile likelihood based CIs. Besides, the Wald-type CIs did not appear to be systematically wider or narrower compared to the bootstrap CIs.
To summarize, these simulations imply that the normal approximation Wald-type CIs used in our study provide a reliable alternative to other more time-complex types of CIs.
Appendix 2
Selection of the predictive models
Single determinant models
To construct a multivariate predictive model for we first focused on each single determinant. More precisely, to find a best predictive model for a single factor we performed both forward selection and backward elimination based on the AIC and BIC criteria (see Appendix 2—table 1 for the case of establishment date). All terms which appeared in at least one of the single determinant models were later used in the multivariate model.
Appendix 2—table 1
Establishment date models obtained with the AIC/BIC forward selection and backward elimination and their respective AIC and BIC values as well as the -values from the likelihood ratio test compared to the null model without any covariates.
Terms that were part of the respective final model are marked by .
| AIC | BIC | |||
|---|---|---|---|---|
| Forward | Backward | Forward | Backward | |
| AIC | ||||
| BIC | ||||
| -value from LR test | ||||
We chose the model obtained with the backward elimination procedure as the predictive model based solely on the establishment date (Figure 2). It provided both the lowest BIC and AIC value, therefore indicating the best goodness-of-fit (Appendix 2—table 1).
Multiple determinants model
Using the terms obtained in the single determinant predictive models (establishment date, age at infection, earliest CD4 cell count, frequency of reporting sex with occasional partner and time to diagnosis) and a viral subtype indicator, we constructed the final multiple determinants model for the prediction as follows. Like before, we carried out both forward and backward selection algorithms for both criteria. Among the resulting algorithms we picked the one minimizing the BIC, since the BIC penalizes the model complexity stronger than the AIC (Appendix 2—table 2).
Appendix 2—table 2
Multivariate models obtained with the AIC/BIC forward selection and backward elimination algorithms.
The terms listed in the table are the terms identified from the single determinant model selections and the crosses indicate the terms entering the multivariate models. The null model from the likelihood ratio test refers to the baseline model without any covariates (not even the subtype).
| AIC | BIC | |||
|---|---|---|---|---|
| Forward | Backward | Forward | Backward | |
| AIC | ||||
| BIC | ||||
| -value from LR test | ||||
Appendix 3
Detailed derivation of the transmission chain size model and statistical inference
Transmission chain size model
Transmission chains can naturally be modeled as branching processes. The index case corresponds to the root of the process; each new infection represents a new offspring. The generation of an individual in a transmission chain can therefore be interpreted as the transmission degree relative to the index case - the first generation individuals got infected directly from the index case, the second generation indirectly through one mediator, etc. In other words, the transmission degree of a patient is the number of transmission events needed to transfer the virus to this patient from the index case.
Towards probability generating function of the transmission chain size
Let denote the number of secondary infections with transmission degree produced by the th individual from the preceding generation, the total number of new infections of transmission degree and the cumulative number of cases in the transmission chain with the transmission degree at most , that is,
The index case establishes the transmission chain and corresponds to the generation , therefore .
Assuming that the numbers of secondary infections are independent and identically distributed for all patients of the same transmission degree, let denote the probability generating function (PGF) of , namely
for each . The expected number of secondary infections of degree is therefore given by
Furthermore, assume that the numbers of secondary infections caused by different individuals are independent between each other regardless of the transmission degree. The PGF of is
because (a) of the tower property of the conditional expectation, (b) is -measurable, (c) are independent, and (d) are independent from for all . Repeating similar steps iteratively yields
The total size of the transmission chain is denoted by and equals
From the definition of it follows that its PGF equals
(2)
for all .
Probability generating function of a completely observed uniform transmission chain
Assume that the number of secondary infections follows the same distribution with PGF for all infected persons, namely
for every (i.e., the transmission is uniform across different transmission degrees). The PGF (Equation 1) then simplifies to
Using Equation 2, the PGF for each solves the equation
Probability generating function of a transmission chain with modified transmission potential of the index case
From the perspective of the Swiss HIV heterosexual population the index case might have lost some of its potential to transmit the virus prior to establishing the transmission chain in the population under consideration. The follow-up cases are infected while already in the subpopulation and can therefore fully contribute to spreading. Sex workers and lonely foreigners in Switzerland represent two examples of index cases with an enhanced transmission potential. We assume that apart from the index case the numbers of secondary infections are equally and independently distributed for all the other infected individuals. Let denote the index case relative transmission potential (ICRTP). In terms of the model the above assumptions can be summarized as
where and denote the PGF of two distributions, such that
namely for all and . In other words, the ICRTP is the expected number of secondary infections of the index case relative to the expected number of secondary infections of the rest of the transmission chain.
To compute the PGF of the transmission chain with modified transmissibility of the index case we first introduce a skeleton function , which controls the regular part/tail of the transmission chain. Let be the pointwise limit of the iteratively defined functions
The skeleton therefore solves the equation
(3)
Note that in the absence of the modified transmissibility of the index case, the skeleton function coincides with the PGF of the transmission chain size. Having introduced this notation one can rewrite the PGF (Equation 1) as
As , this implies
(4)
for all .
Probability generating function of an incompletely observed transmission chain
Since not every HIV infected person is included in a cohort, linked to care or even diagnosed, we only observe parts of the transmission chains. Suppose that each infection is detected with probability , independently of the others. Furthermore, assume that despite not all cases being observed, the sampled patients belonging to the same true transmission chain could be identified as members of this transmission cluster (and not as members of two or more separate transmission clusters).
The true transmission chain can still be modeled with the branching process as above. Let tilde ( ) denote the observed cases. Since each case is detected at random with probability the following applies to the observed transmission chains.
If is defined as above then denotes the number of secondary infections with transmission degree caused by patient which are actually observed. It follows
Given the numbers of secondary infections with transmission degree of all the patients the observed number of infections of transmission degree equals
and follows a binomial distribution, namely
The observed cumulative number of infected individuals with the transmission degree at most equals
By conditioning on the cumulative number of infections of transmission degree up to and on the numbers of secondary infections of transmission degree , therefore follows a binomial distribution, that is,
Since is the PGF of a -distributed random variable, the PGF of can be expressed as
in terms of the PGF , because (a) of the tower property, (b) of the tower property for -algebras due to the relation , and (c) given and is binomially distributed.
This allows us to obtain the PGF of the observed transmission chain length , namely
where denotes the PGF of the true underlying transmission chain.
Finally, the PGF of the observed transmission chain size with modified transmissibility of the index case equals
(5)
Inferring the transmission parameters
Probability generating functions enable us to obtain the state probabilities, namely the probability of observing a transmission chain of length can be calculated as
where denotes the th derivative. The transmission chains with no observed cases are not observable, therefore we are interested in the probability that an observed chain is of length , which equals
So far, we have not included the basic reproductive number or any other transmission-related parameters in the PGF of transmission chain size . In the following paragraphs we extensively present the statistical inference (following Held and Bové, 2013) of the transmission parameters based on the transmission chain size model described above.
The likelihood function
Let denote a vector of transmission parameters, for instance in case of a single transmission parameter corresponding to the basic reproductive number. Assuming that the transmission chain sizes are independent, the likelihood function of the sample of observed transmission chain sizes is defined by
where denotes the PGF of transmission chain size with transmission parameters . The corresponding log-likelihood function is
(6)
Since the transmission parameters are often required to be positive the log-parameterization is more appropriate. Let denote the transmission parameters on the logarithmic scale, namely . The log-parameterized log-likelihood function is therefore . The Jacobian matrix corresponding to the log-parameterization equals
where denotes a diagonal matrix with vector representing its diagonal elements.
The score function and the Fisher information matrix
The maximum likelihood (ML) estimator maximizes the log-likelihood function and is a root of the score function
or equivalently, the ML estimator solves
where denotes the score function corresponding to the log-parameterized log-likelihood .
The Fisher information matrix is given by
and equals
under the log-parameterization due to the chain rule in higher dimensions and the special form of the transformation corresponding to the log-parameterization. The PGF function and its derivatives are thus crucial (and sufficient) for the statistical inference, since the log-likelihood function , the score function and the Fisher information matrix can be expressed in terms of only.
Confidence intervals and hypothesis testing
Assuming that the regularity conditions are satisfied (Held and Bové, 2013) the ML estimator is unbiased and asymptotically normally distributed with variance equal to the inverse observed Fisher information matrix. Hence, for each parameter we can construct the Wald -confidence interval as
where denotes the -quantile of the standard normal distribution, and the standard error is defined as
and denotes the diagonal element of the inversed observed Fisher information matrix corresponding to parameter . The approximate -confidence interval for the original parameter is obtained by the reverse transformation
Similarly, to test the hypothesis against the alternative , the Wald test statistic
can be used. Assuming the standard normal distribution of the test statistic under null hypothesis, the -value equals
for the alternative hypothesis ,
for the alternative , and
for the alternative ;
where is the cumulative distribution function of the standard normal distribution.
Generalized transmission chain size model
Suppose that the variability of one of the parameters can be explained through a linear combination of different covariates, namely
are the transmission parameters of the th chain with characteristics , where denotes the remaining parameters from which are not modeled as a linear combination. Furthermore, it is plausible to assume that while the transmission chains share all the transmission parameters , their transmission chain size distribution may differ due to different sampling densities or different offspring distribution of the index case (for instance, for the transmission chains originating from other Swiss transmission groups the ICRTP is irrelevant/equals ). Let be the PGF corresponding to the transmission chain and let . The generalized log-likelihood function is hence given by
where
The corresponding Jacobian matrix equals
In the generalized model, the score function is
and the Fisher information matrix as
Prediction intervals
It is tempting to construct an approximate confidence interval for the parameter . Since the parameter is a prediction rather than an estimate, the element of interest is the prediction interval, which takes into account both the characteristics and the uncertainty of all parameter estimates .
Assuming that the ML estimator is asymptotically normally distributed, it follows that the linear combination is also asymptotically Gaussian, specifically
The variance can be approximated by the inverse of the observed Fisher information matrix as
Finally, an approximate -prediction interval for is constructed as
with
Example: Poisson model
Suppose that the number of secondary infections follows the Poisson distribution with parameter . Taking into account the modified transmissibility of the index case (wherever applicable), the PGFs and for the index case and the tail, respectively, are
The skeleton function thus solves
(7)
Consider an imperfectly sampled transmission chain with probability of detection and with ICRTP . The aim is to obtain the Taylor coefficients of around to be able to estimate the transmission parameter with the maximum likelihood approach since they are needed to calculate the log-likelihood (Equation 6).
Let
and
such that and that the Equation 5 of the PGF of observed transmission chain size simplifies to
Taking into account the PGF of the index case implies
Solving for yields
Plugging this into Equation 7 gives
With , the last equation is equivalent to
which is an equation of the form . The latter admits a solution , where is the principal branch of the Lambert function (Corless et al., 1996). Thus
and finally,
Using the relation (which follows from the definition of ), we have
From the Taylor expansion of around (equality (2.36) in Corless et al., 1996), we obtain
In terms of this yields
(8)
Unfortunately, we need Taylor expansion around to derive the state probabilities (and consequently the log-likelihood function). By applying the binomial theorem, can be re-written as
with denoting .
Initial estimate for
Since the optimization problem of maximizing the likelihood does not admit a closed-form solution, the ML estimator is obtained with numerical techniques for which a suited initial estimate for is required. In the following paragraphs we present one possibility for obtaining a useful starting value (which was also implemented and used in our analyses).
Let
be the observed average chain size (based on a sample of observed chains like proposed in Blumberg and Lloyd-Smith, 2013b). represents a reasonable estimate for
The definition of the skeleton function for transmission parameters implies . Implicitly deriving Equation 3 with respect to implies
since (just like for any PGF). Moreover, implicitly deriving Equation 5 with respect to yields
Under the Poisson model, the latter equals to
Next, we can use the first Taylor coefficient of from Equation 8, namely . In order to obtain a quadratic equation with respect to , we further use the approximation , such that . This yields the quadratic equation
with the roots
where
Should none of the roots lie within , we could use the following feature. If the average size of the observed chain equals , the average size of the complete transmission chains would be roughly (since the mean value of the binomial distribution is ). Hence,
Equation 4 then implies
In case of the Poisson model, the initial estimate for can be therefore obtained by solving the equation
which has the solution
Generalized Poisson model
Let be a sample of observed transmission chains where each observed transmission chain carries the following information
namely the observed chain size , the chain characteristics , the probability at which each infection in the chain is observed, and the index case relative transmission potential . In the generalized Poisson transmission chain size distribution model we assume that the heterogeneity of the basic reproductive number can be explained by the variability of the demographic characteristics of the transmission chains, namely
The vector describes the effect of the chain characteristics on the basic reproductive number and it is the same for all transmission chains.
To obtain the maximum likelihood estimates for , we need initial values of the estimates. One possibility is to use the coefficients from the linear regression model, in which the response values are the individual initial estimates for for each transmission chain. More precisely, imagine that each transmission chain is a sample of transmission chains itself and therefore we can obtain the initial estimates as described above. In the next step, we fit the linear regression model
and use as the initial values.
Example: Negative binomial model
Assume that the number of secondary infections caused by an individual is negative binomially distributed with mean and dispersion parameter . Its PGF equals
For the simplicity assume that index case has the same transmission potential as the remaining part of the transmission chain, namely (which coincides with ). The skeleton function is therefore a solution of the equation
which does not admit a closed-form solution. However, as a consequence of the Lagrange inversion theorem its Taylor coefficients around can be explicitly calculated (Blumberg and Lloyd-Smith, 2013b) as
Since we assumed , it follows for all . For a transmission chain in which each case is observed with probability , the PGF of the observed transmission chain size equals
By applying the binomial theorem to the Taylor expansion around of the higher-order derivatives
are obtained (which coincides with the result from Blumberg and Lloyd-Smith, 2013a).
In similar manner as in the case of Poisson model, the generalized negative binomial model can be derived by introducing
The sampling density can vary between the transmission chains (or their characteristics, for instance between the subtypes), while the dispersion parameter is kept constant among all the transmission chains.
References
-
Inference of R(0) and transmission heterogeneity from the size distribution of stuttering chainsPLoS Computational Biology 9:e1002993.https://doi.org/10.1371/journal.pcbi.1002993
-
Effectiveness of highly active antiretroviral therapy in reducing heterosexual transmission of HIVJAIDS Journal of Acquired Immune Deficiency Syndromes 40:96–101.https://doi.org/10.1097/01.qai.0000157389.78374.45
-
Antiretroviral Therapy for the Prevention of HIV-1 TransmissionNew England Journal of Medicine 375:830–839.https://doi.org/10.1056/NEJMoa1600693
-
Prevention of HIV-1 infection with early antiretroviral therapyNew England Journal of Medicine 365:493–505.https://doi.org/10.1056/NEJMoa1105243
-
Acute HIV-1 InfectionNew England Journal of Medicine 364:1943–1954.https://doi.org/10.1056/NEJMra1011874
-
Advances in Computational Mathematics329–359, On the Lambert W Function, Advances in Computational Mathematics, Vol. 5.
-
MUSCLE: multiple sequence alignment with high accuracy and high throughputNucleic Acids Research 32:1792–1797.https://doi.org/10.1093/nar/gkh340
-
HIV-1 transmission, by stage of infectionThe Journal of Infectious Diseases 198:687–693.https://doi.org/10.1086/590501
-
Effect of early versus deferred antiretroviral therapy for HIV on survivalNew England Journal of Medicine 360:1815–1826.https://doi.org/10.1056/NEJMoa0807252
-
Increases in Condomless Sex in the Swiss HIV Cohort StudyOpen Forum Infectious Diseases 2:ofv077.https://doi.org/10.1093/ofid/ofv077
-
Molecular epidemiology reveals long-term changes in HIV type 1 subtype B transmission in SwitzerlandThe Journal of Infectious Diseases 201:1488–1497.https://doi.org/10.1086/651951
-
Initiation of Antiretroviral Therapy in Early Asymptomatic HIV InfectionThe New England Journal of Medicine 373:795–807.https://doi.org/10.1056/NEJMoa1506816
-
Phylodynamics of the major HIV-1 CRF02_AG African lineages and its global disseminationInfection, Genetics and Evolution 46:190–199.https://doi.org/10.1016/j.meegid.2016.05.017
-
FastTree: computing large minimum evolution trees with profiles instead of a distance matrixMolecular Biology and Evolution 26:1641.https://doi.org/10.1093/molbev/msp077
-
Transmission of Non-B HIV Subtypes in the United Kingdom Is Increasingly Driven by Large Non-Heterosexual Transmission ClustersJournal of Infectious Diseases 213:1410–1418.https://doi.org/10.1093/infdis/jiv758
-
Molecular epidemiology of HIV-1 in Iceland: Early introductions, transmission dynamics and recent outbreaks among injection drug usersInfection, Genetics and Evolution 49:157–163.https://doi.org/10.1016/j.meegid.2017.01.004
-
Cohort profile: the Swiss HIV Cohort studyInternational Journal of Epidemiology 39:1179–1189.https://doi.org/10.1093/ije/dyp321
-
Estimating the basic reproductive number from viral sequence dataMolecular Biology and Evolution 29:347.https://doi.org/10.1093/molbev/msr217
-
A joint back calculation model for the imputation of the date of HIV infection in a prevalent cohortStatistics in Medicine 27:4835–4853.https://doi.org/10.1002/sim.3294
-
The role of migration and domestic transmission in the spread of HIV-1 non-B subtypes in SwitzerlandThe Journal of Infectious Diseases 204:1095–1103.https://doi.org/10.1093/infdis/jir491
Article and author information
Author details
Funding
Schweizerischer Nationalfonds zur Förderung der Wissenschaftlichen Forschung (33CS30-148522)
- Huldrych F Günthard
Yvonne-Jacob Foundation
- Huldrych F Günthard
University of Zurich's Clinical Research Priority Program's ZPHI
- Huldrych F Günthard
Schweizerischer Nationalfonds zur Förderung der Wissenschaftlichen Forschung (159868)
- Huldrych F Günthard
Schweizerischer Nationalfonds zur Förderung der Wissenschaftlichen Forschung (PZ00P3-142411)
- Roger D Kouyos
Schweizerischer Nationalfonds zur Förderung der Wissenschaftlichen Forschung (BSSGI0-155851)
- Roger D Kouyos
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Mohaned Shilaih for providing the original data regarding the sampling density. Furthermore, we thank Alex Marzel, Katharina Kusejko, Bruno Ledergerber and Roland R Regoes for fruitful discussions. We thank the patients who participate in the Swiss HIV Cohort Study (SHCS); the physicians and study nurses for excellent patient care; the resistance laboratories for high-quality genotypic drug resistance testing; SmartGene (Zug, Switzerland) for technical support; Johannes Abegglen, Bojana Milosevic, Alexandra U Scherrer, Anna Traytel, and Susanne Wild from the SHCS Data Center (Zurich, Switzerland) for data management; and Danièle Perraudin and Mirjam Minichiello for administrative assistance.
Ethics
Human subjects: The SHCS was approved by the ethics committees of the participating institutions (Kantonale Ethikkommission Bern, Ethikkommission des Kantons St. Gallen, Comite Departemental d'Ethique des Specialites Medicales et de Medicine Communataire et de Premier Recours, Kantonale Ethikkommission Zürich, Repubblica e Cantone Ticino-Comitato Ethico Cantonale, Commission Cantonale d'Étique de la Recherche sur l'Être Humain, Ethikkommission beiderBasel; all approvals are available on http://www.shcs.ch/206-ethic-committee-approval-and-informed-consent), and written informed consent was obtained from all participants.
Copyright
© 2017, Turk et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 16
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Assessing the danger of self-sustained HIV epidemics in heterosexuals by population based phylogenetic cluster analysis
eLife 6:e28721.
https://doi.org/10.7554/eLife.28721
Further reading
-
- Epidemiology and Global Health
Background:
Biological aging exhibits heterogeneity across multi-organ systems. However, it remains unclear how is lifestyle associated with overall and organ-specific aging and which factors contribute most in Southwest China.
Methods:
This study involved 8396 participants who completed two surveys from the China Multi-Ethnic Cohort (CMEC) study. The healthy lifestyle index (HLI) was developed using five lifestyle factors: smoking, alcohol, diet, exercise, and sleep. The comprehensive and organ-specific biological ages (BAs) were calculated using the Klemera–Doubal method based on longitudinal clinical laboratory measurements, and validation were conducted to select BA reflecting related diseases. Fixed effects model was used to examine the associations between HLI or its components and the acceleration of validated BAs. We further evaluated the relative contribution of lifestyle components to comprehension and organ systems BAs using quantile G-computation.
Results:
About two-thirds of participants changed HLI scores between surveys. After validation, three organ-specific BAs (the cardiopulmonary, metabolic, and liver BAs) were identified as reflective of specific diseases and included in further analyses with the comprehensive BA. The health alterations in HLI showed a protective association with the acceleration of all BAs, with a mean shift of –0.19 (95% CI −0.34, –0.03) in the comprehensive BA acceleration. Diet and smoking were the major contributors to overall negative associations of five lifestyle factors, with the comprehensive BA and metabolic BA accounting for 24% and 55% respectively.
Conclusions:
Healthy lifestyle changes were inversely related to comprehensive and organ-specific biological aging in Southwest China, with diet and smoking contributing most to comprehensive and metabolic BA separately. Our findings highlight the potential of lifestyle interventions to decelerate aging and identify intervention targets to limit organ-specific aging in less-developed regions.
Funding:
This work was primarily supported by the National Natural Science Foundation of China (Grant No. 82273740) and Sichuan Science and Technology Program (Natural Science Foundation of Sichuan Province, Grant No. 2024NSFSC0552). The CMEC study was funded by the National Key Research and Development Program of China (Grant No. 2017YFC0907305, 2017YFC0907300). The sponsors had no role in the design, analysis, interpretation, or writing of this article.
-
- Epidemiology and Global Health
- Microbiology and Infectious Disease
Background:
In many settings, a large fraction of the population has both been vaccinated against and infected by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). Hence, quantifying the protection provided by post-infection vaccination has become critical for policy. We aimed to estimate the protective effect against SARS-CoV-2 reinfection of an additional vaccine dose after an initial Omicron variant infection.
Methods:
We report a retrospective, population-based cohort study performed in Shanghai, China, using electronic databases with information on SARS-CoV-2 infections and vaccination history. We compared reinfection incidence by post-infection vaccination status in individuals initially infected during the April–May 2022 Omicron variant surge in Shanghai and who had been vaccinated before that period. Cox models were fit to estimate adjusted hazard ratios (aHRs).
Results:
275,896 individuals were diagnosed with real-time polymerase chain reaction-confirmed SARS-CoV-2 infection in April–May 2022; 199,312/275,896 were included in analyses on the effect of a post-infection vaccine dose. Post-infection vaccination provided protection against reinfection (aHR 0.82; 95% confidence interval 0.79–0.85). For patients who had received one, two, or three vaccine doses before their first infection, hazard ratios for the post-infection vaccination effect were 0.84 (0.76–0.93), 0.87 (0.83–0.90), and 0.96 (0.74–1.23), respectively. Post-infection vaccination within 30 and 90 days before the second Omicron wave provided different degrees of protection (in aHR): 0.51 (0.44–0.58) and 0.67 (0.61–0.74), respectively. Moreover, for all vaccine types, but to different extents, a post-infection dose given to individuals who were fully vaccinated before first infection was protective.
Conclusions:
In previously vaccinated and infected individuals, an additional vaccine dose provided protection against Omicron variant reinfection. These observations will inform future policy decisions on COVID-19 vaccination in China and other countries.
Funding:
This study was funded the Key Discipline Program of Pudong New Area Health System (PWZxk2022-25), the Development and Application of Intelligent Epidemic Surveillance and AI Analysis System (21002411400), the Shanghai Public Health System Construction (GWVI-11.2-XD08), the Shanghai Health Commission Key Disciplines (GWVI-11.1-02), the Shanghai Health Commission Clinical Research Program (20214Y0020), the Shanghai Natural Science Foundation (22ZR1414600), and the Shanghai Young Health Talents Program (2022YQ076).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}