Support for a clade of Placozoa and Cnidaria in genes with minimal compositional bias
- Wellcome Trust Sanger Institute, United Kingdom
- European Molecular Biology Laboratories-European Bioinformatics Institute, United Kingdom
- Max Planck Institute for Marine Microbiology, Germany
- Pacific Biosciences Research Center and the University of Hawaii-Manoa, United States
- University of California, United States
- The Natural History Museum, United Kingdom
- University of Cambridge, United Kingdom
- Harvard University, United States
Abstract
The phylogenetic placement of the morphologically simple placozoans is crucial to understanding the evolution of complex animal traits. Here, we examine the influence of adding new genomes from placozoans to a large dataset designed to study the deepest splits in the animal phylogeny. Using site-heterogeneous substitution models, we show that it is possible to obtain strong support, in both amino acid and reduced-alphabet matrices, for either a sister-group relationship between Cnidaria and Placozoa, or for Cnidaria and Bilateria as seen in most published work to date, depending on the orthologues selected to construct the matrix. We demonstrate that a majority of genes show evidence of compositional heterogeneity, and that support for the Cnidaria + Bilateria clade can be assigned to this source of systematic error. In interpreting these results, we caution against a peremptory reading of placozoans as secondarily reduced forms of little relevance to broader discussions of early animal evolution.
https://doi.org/10.7554/eLife.36278.001eLife digest
Filter-feeding sponges and tiny gliding, pancake-like animals called placozoans are the only two major groups of animals that lack muscles, nerves and an internal gut. Sponges have historically been seen as the first to have branched off in animal phylogeny – the family tree of living organisms that shows how species are related. This is because it is assumed that they split from the other animals before features including muscles, nerves and internal guts evolved.
Sequences of their genetic material (the genome) support this view, although some argue that jellyfish-like animals called ctenophores branched first. One explanation for this disagreement is that ctenophores use different proportions of amino acids in their proteins, known as compositional heterogeneity. Computer algorithms that assume amino acid usage is the same universally throughout evolution may therefore place ctenophores incorrectly. In contrast, so far the only genome from a placozoan shows that they are equally closely related to jellyfish and corals (cnidarians) and bilaterians, which includes worms, insects and vertebrates.
To test whether this view of the first branches of the animal tree of life is correct, Laumer et al. included the genomes from several undescribed species of placozoans in a phylogenetic analysis. These analyses showed a relationship that had not previously been seen. The placozoans were the closest living relative to cnidarians. However, when looking at the level of genes rather than whole genomes, the more usual relationship of placozoans being equally related to cnidarians and bilaterians re-emerged. To resolve this conflict, Laumer et al. focused on the genes that had the least compositional heterogeneity. When doing this, the relationship appeared to be the newly identified one of placozoans being most closely related to cnidarians.
Researchers studying cnidarians often hope to find some clues as to how the complex features they seem to share with bilaterians originated. The findings of Laumer et al. may suggest that the ancestors of the placozoans did in fact have muscles, nerves and guts, but they lost these traits in favor of a simpler lifestyle. An alternative, but controversial possibility is that the ancestor of cnidarians and bilaterians was a simple organism like a placozoan, and the two evolved their complex traits independently. The findings show a complex picture of early animal evolution. Further study of placozoans may well clarify this picture.
https://doi.org/10.7554/eLife.36278.002Introduction
The discovery (Schulze, 1883) and mid-20th century rediscovery (Grell and Benwitz, 1971) of the enigmatic, amoeba-like placozoan Trichoplax adhaerens did much to ignite the imagination of zoologists interested in early animal evolution (Bütschli, 1884). As microscopic animals adapted to extracellular grazing on the biofilms over which they creep (Wenderoth, 1986), placozoans have a simple anatomy suited to exploit passive diffusion for many physiological needs, with only six morphological cell types discernible even to intensive microscopical scrutiny (Grell and Ruthmann, 1991; Smith et al., 2014), albeit a greater diversity of cell types is apparent through single-cell RNA-seq (Sebé-Pedrós, 2018a). They have no conventional muscular, digestive, or nervous systems, yet show tightly-coordinated behaviour regulated by peptidergic signaling (Smith et al., 2015; Senatore et al., 2017; Varoqueaux, 2018; Armon et al., 2018). In laboratory conditions, they proliferate through fission and somatic growth. Evidence for sexual reproduction remains elusive, despite genetic evidence of recombination (Srivastava et al., 2008) and descriptions of early abortive embryogenesis (Eitel et al., 2011; Grell, 1972), with the possibility that sexual phases of the life cycle may occur only under poorly understood field conditions (Pearse and Voigt, 2007; McFall-Ngai et al., 2013)
Given their simple, puzzling morphology and dearth of embryological clues, molecular data are crucial in placing placozoans phylogenetically. The position of Placozoa in the animal tree proved recalcitrant to early standard-marker analyses (Kim et al., 1999; Silva et al., 2007; Wallberg et al., 2004), although this paradigm did reveal a large degree of molecular diversity in placozoan isolates from around the globe, clearly indicating the existence of many cryptic species (Pearse and Voigt, 2007; Eitel et al., 2013; Signorovitch et al., 2007) with up to 27% genetic distance in 16S rRNA alignments (Eitel and Schierwater, 2010). An apparent answer to the question of placozoan affinities was provided by analysis of a nuclear genome assembly (Srivastava et al., 2008), which strongly supported a position as the sister group of a clade of Cnidaria + Bilateria (sometimes called Planulozoa). However, this effort also revealed a surprisingly bilaterian-like (Dunn et al., 2015) developmental gene toolkit in placozoans, a paradox for such a simple animal.
As metazoan phylogenetics has pressed onward into the genomic era, perhaps the largest controversy has been the debate over the identity of the sister group to the remaining metazoans, traditionally thought to be Porifera, but considered to be Ctenophora by Dunn et al (Dunn et al., 2008). and subsequently by additional studies (Hejnol et al., 2009; Moroz et al., 2014; NISC Comparative Sequencing Program et al., 2013; Whelan et al., 2015; Whelan et al., 2017). Others have suggested that this result arises from artifacts with potentially additive effects, such as inadequate taxon sampling, flawed matrix husbandry (undetected paralogy or contamination), and use of poorly fitting substitution models (Philippe et al., 2009; Pick et al., 2010; Pisani et al., 2015; Simion et al., 2017; Feuda et al., 2017). A third view has emphasized that using different sets of genes can lead to different conclusions, with only a small number sometimes sufficient to drive one result or another (Nosenko et al., 2013; Shen et al., 2017). This controversy, regardless of its eventual resolution, has spurred serious contemplation of possibly independent origins of several hallmark traits such as striated muscles, digestive systems, and nervous systems (Moroz et al., 2014; Dayraud et al., 2012; Hejnol and Martín-Durán, 2015; Liebeskind et al., 2017; Moroz and Kohn, 2016; Presnell et al., 2016; Steinmetz et al., 2012).
Driven by this controversy, new genomic and transcriptomic data from sponges, ctenophores, and metazoan outgroups have accrued, while new sequences and analyses focusing on the position of Placozoa have been slow to emerge. Here, we provide a novel test of the phylogenetic position of placozoans, adding draft genomes from three putative species that span the root of this clade’s known diversity (Eitel et al., 2013) (Table 1), and critically assessing the role of systematic error in placing of these enigmatic organisms (Laumer, 2018).
Table 1
Summary statistics describing the contiguity and completeness of the draft host metagenome bins from the three clade A placozoan isolates utilized in this paper, presented in comparison to the reference H1 strain.
https://doi.org/10.7554/eLife.36278.003| H11 | H4 | H6 | H1 | |
|---|---|---|---|---|
| assembly span (Mbp) | 56.63 | 83.39 | 76.7 | 98.06 |
| scaffold number | 5813 | 5337 | 8310 | 1415 |
| scaffold N50 (kbp) | 12.738 | 25.97 | 12.84 | 5790 |
| GC% | 30.76 | 30.84 | 29.9 | 29.37 |
| BUSCO2 Eukaryota complete (of 303) | 220 | 276 | 239 | 294 |
| BUSCO2 Eukaryota complete + partial (of 303) | 246 | 282 | 265 | 298 |
| Average # of hits per BUSCO | 1.00 | 1.04 | 1.00 | 1.00 |
| % of BUSCOs with more than one match | 0.45 | 3.99 | 0.42 | 0.34 |
Results and discussion
Orthology assignment on sets of predicted proteomes derived from 59 genome and transcriptome assemblies yielded 4294 gene trees with at least 20 sequences each, sampling all five major metazoan clades and outgroups, from which we obtained 1388 well-aligned orthologues. Within this set, individual maximum-likelihood (ML) gene trees were constructed, and a set of 430 most-informative orthologues were selected on the basis of tree-likeness scores (Misof et al., 2013). This yielded an amino-acid matrix of 73,547 residues with 37.55% gaps or missing data, with an average of 371.92 and 332.75 orthologues represented for Cnidaria and Placozoa, respectively (with a maximum of 383 orthologues present for the newly sequenced placozoan H4 clade representative; Figure 1).
Figure 1 with 2 supplements see all
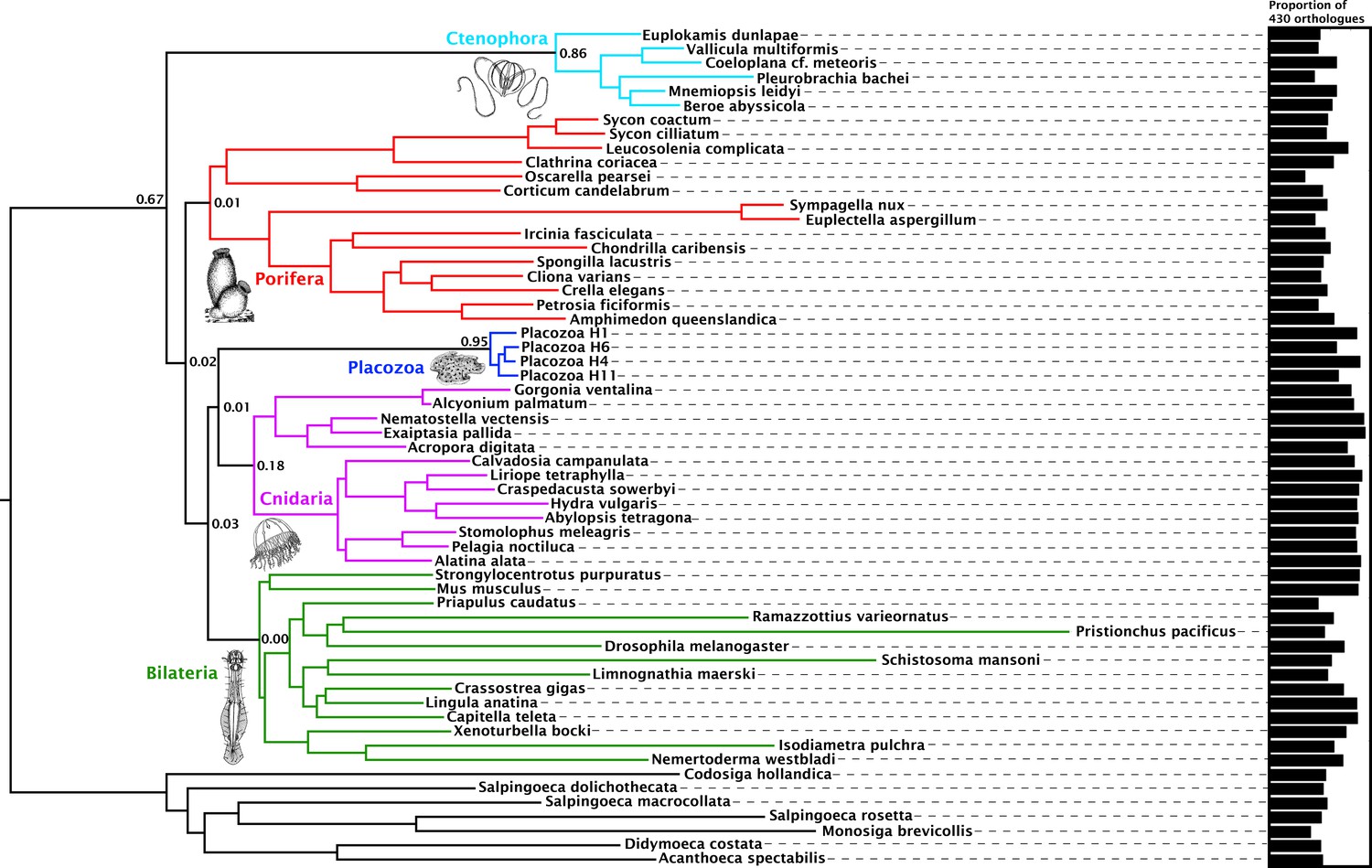
Consensus phylogram showing deep metazoan interrelationships under Bayesian phylogenetic inference of the 430-orthologue amino acid matrix, using the CAT + GTR + Г4 mixture model.
All nodes received full posterior probability. Numerical annotations of given nodes represent Extended Quadripartition Internode Certainty (EQP-IC) scores, describing among-gene-tree agreement for both the monophyly of the five major metazoan clades and the given relationships between them in this reference tree. A bar chart on the right depicts the proportion of the total orthologue set each terminal taxon is represented by in the concatenated matrix. ‘Placozoa H1’ in this and all other figures refers to the GRELL isolate sequenced in Srivastava et al., 2008, which has there and elsewhere been referred to as Trichoplax adhaerens, despite the absence of type material linking this name to any modern isolate. Line drawings of clade representatives are taken from the BIODIDAC database (http://biodidac.bio.uottawa.ca/).
Our Bayesian analyses of this matrix place Cnidaria and Placozoa as sister groups with full posterior probability under the general site-heterogeneous CAT + GTR + Г4 model (Figure 1). Under ML inference with the C60 +LG + FO + R4 profile mixture model (Wang et al., 2018) (Figure 1—figure supplement 1), we again recover Cnidaria + Placozoa, albeit with more marginal resampling support. Both Bayesian and ML analyses show little internal branch diversity within Placozoa. Accordingly, deleting all newly-added placozoan genomes from our analysis has no effect on topology and only a marginal effect on support in ML analysis (Figure 1—figure supplement 2). Quartet-based concordance analyses (Zhou, 2017) show no evidence of strong phylogenetic conflicts among ML gene trees in this 430-gene set (Figure 1), although internode certainty metrics are close to 0 for many key clades including Cnidaria + Placozoa, indicating that support for some ancient relationships may be masked by gene-tree estimation errors, emerging only in combined analysis (Gatesy and Baker, 2005).
Compositional heterogeneity of amino-acid frequencies along the tree is a source of phylogenetic error not modelled by even complex site-heterogeneous substitution models such as CAT+GTR (Blanquart and Lartillot, 2008; Foster, 2004; Lartillot and Philippe, 2004; Lartillot et al., 2013). Furthermore, previous analyses (Nosenko et al., 2013) have shown that placozoans and choanoflagellates in particular, both of which taxa our matrix samples intensively, deviate strongly from the mean amino-acid composition of Metazoa, perhaps as a result of genomic GC content discrepancies. As a measure to at least partially ameliorate such nonstationary substitution, we recoded the amino-acid matrix into the 6 ‘Dayhoff’ categories, a common strategy previously shown to reduce the effect of compositional variation among taxa, albeit the Dayhoff-6 groups represent only one of many plausible recoding strategies, all of which sacrifice information (Feuda et al., 2017; Nesnidal et al., 2010; Rota-Stabelli et al., 2013; Susko and Roger, 2007). Analysis of this recoded matrix under the CAT + GTR model again recovered full support (pp = 1) for Cnidaria + Placozoa (Figure 2). Indeed, under Dayhoff-6 recoding, the only major change is in the relative positions of Ctenophora and Porifera, with the latter here constituting the sister group to all other animals with full support. Similar recoding-driven effects on relative positions of Porifera and Ctenophora have also been seen in other recent work (Feuda et al., 2017), and have been interpreted to indicate a role for compositional bias in misplacing Ctenophora as sister group to all other animals
Figure 2
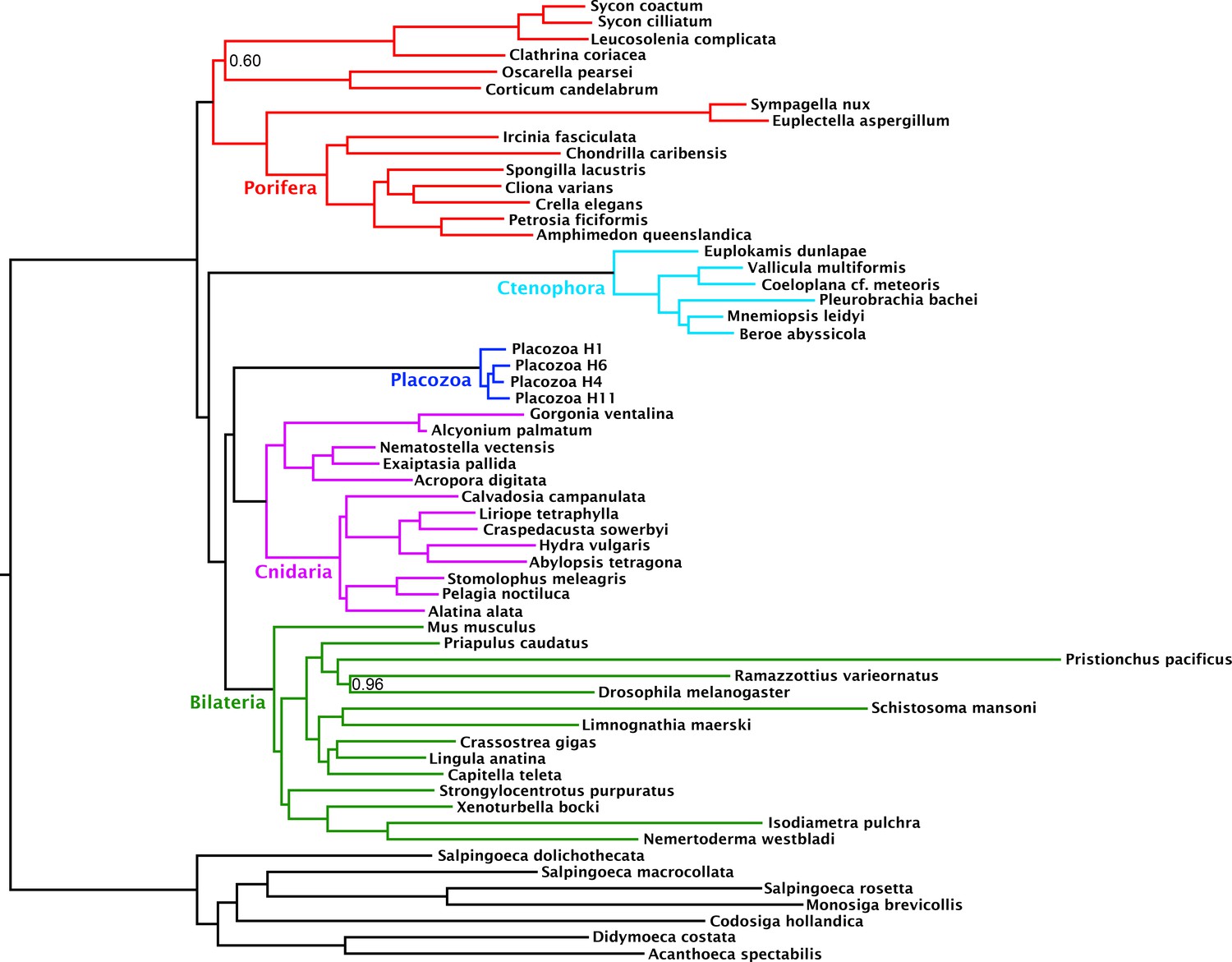
Consensus phylogram under Bayesian phylogenetic inference under the CAT + GTR + Г4 mixture model, on the 430-orthologue concatenated amino acid matrix, recoded into 6 Dayhoff groups.
Nodes annotated with posterior probability; unannotated nodes received full support.
Many research groups, using good taxon sampling and genome-scale datasets, and even recently including data from a new divergent placozoan species (Whelan et al., 2017; Feuda et al., 2017; Eitel, 2017), have consistently reported strong support for Planulozoa under the CAT + GTR model. Indeed, when we construct a supermatrix from our predicted peptide catalogues using a different strategy, relying on complete sequences of 303 pan-eukaryote ‘Benchmarking Universal Single-Copy Orthologs’ (BUSCOs) (Simão et al., 2015), we also see full support in a CAT + GTR + Г analysis for Planulozoa, in both amino-acid (Figure 3a) and Dayhoff-6 recoded alphabets (Figure 3b). Which phylogeny is correct, and what process drives support for the incorrect topology? Posterior predictive tests, which compare the observed among-taxon usage of amino-acid frequencies to expected distributions simulated using the sampled posterior distribution and a single composition vector, may provide insight (Feuda et al., 2017; Lartillot and Philippe, 2004). Both the initial 430-gene matrix and the 303-gene BUSCO matrix fail these tests, but the BUSCO matrix fails it more profoundly, with z-scores (measuring mean-squared across-taxon heterogeneity) scoring in the range of 330–340, in contrast to the range of 176–187 seen in the 430-gene matrix (Table 2). Furthermore, inspecting z-scores for individual taxa in representative chains from both matrices shows that a large amount of this global difference in z-scores can be attributed to placozoans, with additional contributions from choanoflagellates and select isolated representatives of other clades (Figure 3C).
Figure 3
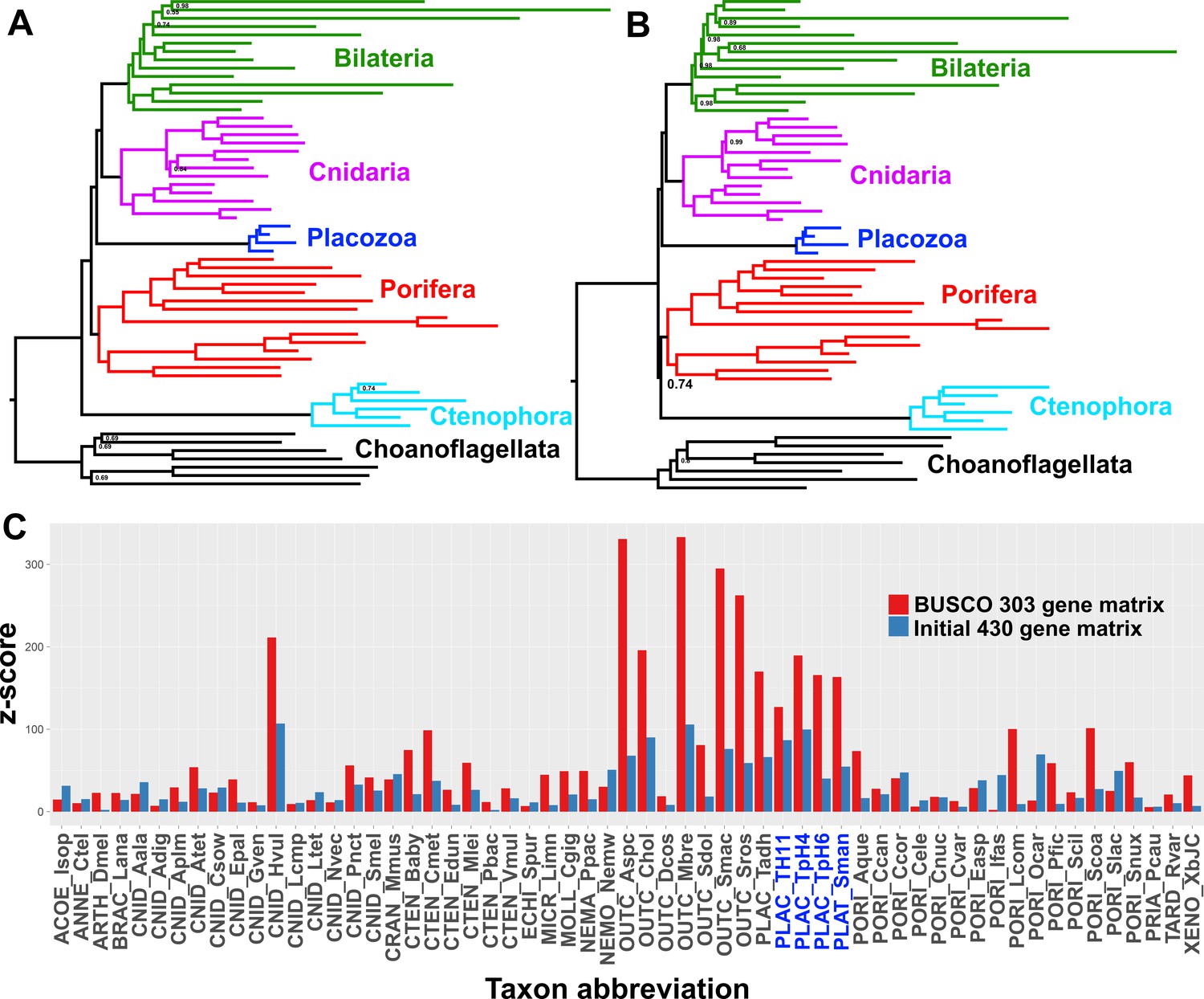
Posterior consensus trees from CAT + GTR + Г4 mixture model analysis of a 94,444 amino acid supermatrix derived from the 303 single-copy conserved eukaryotic BUSCO orthologs, analysed in A.
amino acid space or (B) the Dayhoff-6 reduced alphabet space. Nodal support values comprise posterior probabilities; nodes with full support not annotated. Taxon colourings as in previous Figures. (C) Plot of z-scores (summed absolute distance between taxon-specific and global empirical frequencies) from representative posterior predictive tests of amino acid compositional bias, from both the BUSCO 303-orthologue matrix (red) and the initial 430-orthologue matrix (blue). Placozoan taxon abbreviations are shown in blue font.
Table 2
Mean (and standard deviation of) z-scores from posterior predictive tests of per-site amino acid diversity and among-lineage compositional homogeneity, called for amino-acid alignments using the PhyloBayes-MPI v1.8 readpb_mpi –div and –comp options, respectively, with burn-ins selected as per the posterior consensus summaries shown elsewhere.
Except for the diversity statistic in the test-passing matrix, all tests reject (at p=0.05) the adequacy of the inferred CAT + GTR + Г4 model to describe the data.
| Diversity | Composition (mean) | Composition (maximum) | |
|---|---|---|---|
| 430 matrix | 1.94 (0.09) | 181.35 (7.50) | 105.04 (3.13) |
| BUSCO 303-gene matrix | 11.27 (0.73) | 334.98 (4.56) | 107.56 (6.17) |
| comp-failed matrix | 2.51 (0.19) | 270.16 (12.03) | 173.87 (9.15) |
| comp-passed matrix | 0.81 (0.18) | 107.67 (10.10) | 63.19 (6.95) |
As a final measure to describe the influence of compositional heterogeneity in this dataset, we applied a null-simulation test for compositional bias to each alignment in our set of 1388 orthologues. This test, which compares the real data to a null distribution of amino-acid frequencies simulated along assumed gene trees with a substitution model using a single composition vector, is less prone to Type II errors than the more conventional X (Grell and Benwitz, 1971) test (Foster, 2004). Remarkably, at a conservative significance threshold of α = 0.10, the majority (764 genes or ~55%) of this gene set is identified as compositionally biased by this test, highlighting the importance of using appropriate statistical tests to control this source of systematic error, rather than applying arbitrary heuristic cutoffs (Kück and Struck, 2014). Building informative matrices from gene sets on either side of this significance threshold, and again applying both CAT + GTR mixture models and ML profile mixtures, we see strong support for Cnidaria + Placozoa in the test-passing supermatrix, and conversely, strong support for Cnidaria + Bilateria in the test-failing supermatrix (Figure 4, Figure 4—figure supplement 1, Figure 4—figure supplement 2). Interestingly, in trees built through CAT + GTR + Г4 analysis of the test-failing supermatrix (Figure 4A,C), in both amino-acid and Dayhoff-6 alphabets, we also observe full support for Porifera as sister to all other animals. In contrast, analysis of this amino acid matrix under a profile mixture model recovers support for Ctenophora in this position (Figure 4—figure supplement 1), indicating that, at least for this alignment, compositional heterogeneity need not be invoked to explain why outcomes differ among analyses, as some have argued (Feuda et al., 2017): both CAT + GTR and the C60 +LG + FO + R4 profile mixture model assume a single composition vector over time, but the CAT + GTR model is better able to accommodate site-heterogeneous substitution patterns (Lartillot et al., 2013; Quang et al., 2008). In the context of this experiment, Dayhoff-6 recoding appears impactful only for the test-passing supermatrix (Figure 4B,D), where it obviates support for Ctenophora-sister (Figure 4B, Figure 4—figure supplement 2) in favour of (albeit, with marginal support) Porifera-sister (Figure 4D), and also diminishes support for Placozoa + Cnidaria (in contrast to the 430-gene matrix; Figure 2), perhaps reflecting the inherent information loss of using a reduced amino-acid alphabet for this relatively shorter matrix.
Figure 4 with 2 supplements see all
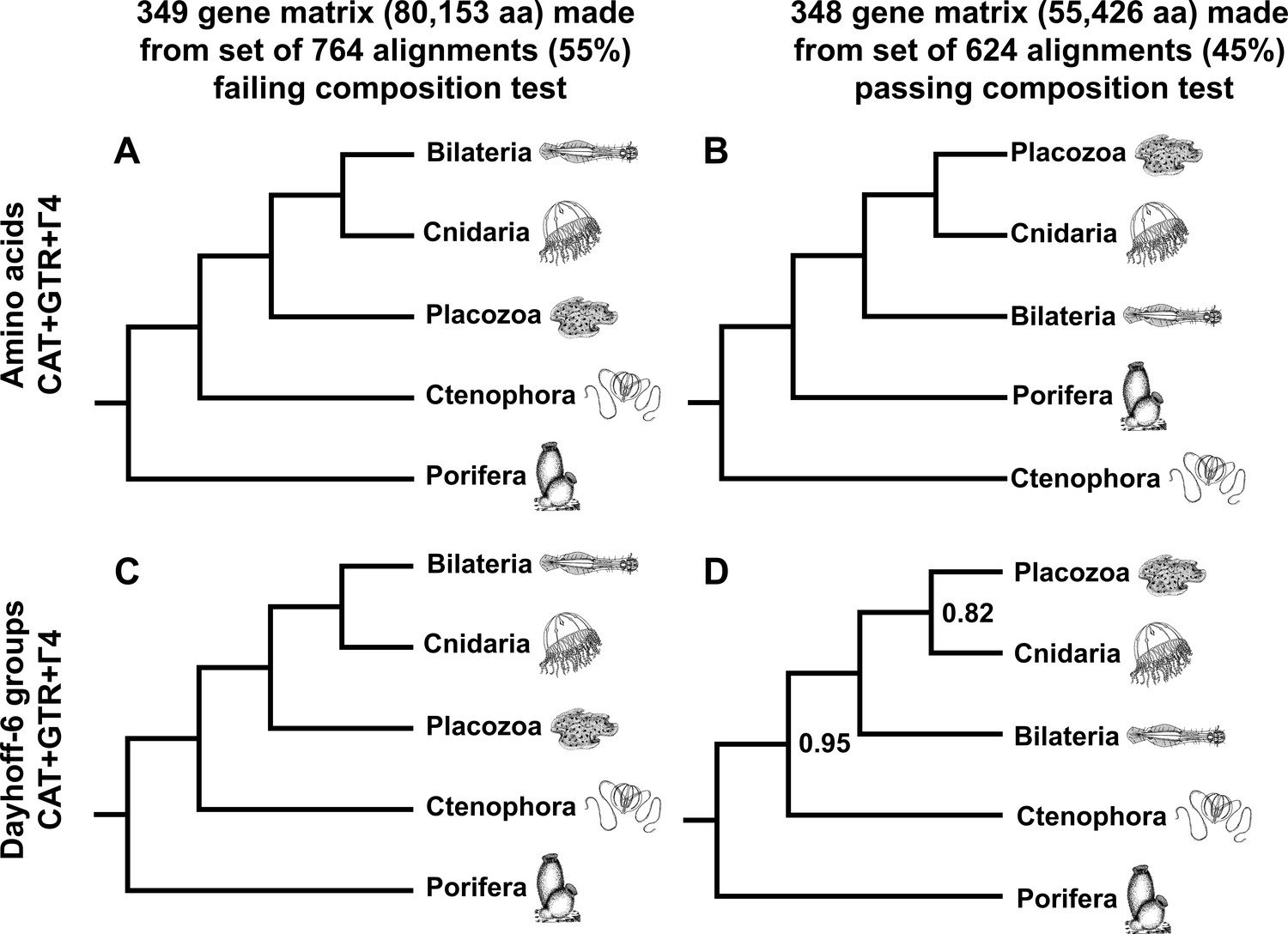
Schematic depiction of deep metazoan interrelationships in posterior consensus trees from CAT + GTR + Г4 mixture model analyses of matrices made from subsets of genes passing or failing a sensitive null-simulation test of compositional heterogeneity.
Panels correspond to (A) the amino acid matrix made within the failing set; (B) the amino acid matrix derived from the passing set; (C) the Dayhoff-6 recoded matrix from the failing set; (D) the Dayhoff-6 recoded matrix from the passing set. Only nodes with posterior probability less than 1.00 are annotated numerically.
A possible hidden variable related to the phylogenetic discordance we describe, the precise significance of which remains unclear, is mean trimmed alignment length: both the test-passing and the original 430-gene matrix are composed of considerably shorter alignments than the test-failing and the 303-gene BUSCO matrix (see Materials and methods). Indeed, alignment length has been previously shown to be predictive of a number of other metrics of phylogenetic relevance (Shen et al., 2016); the generality and directionality of such relationships in empirical datasets at varying scales of divergence is clearly worthy of further investigation.
The previously cryptic phylogenetic link between cnidarians and placozoans seen in gene sets less influenced by compositional bias will require further testing with other analyses and data modalities, such as rare genomic changes, which should be ever more visible as highly contiguous assemblies continue to be reported from non-bilaterian animals (Eitel et al., 2018; Kamm et al., 2018; Jiang, 2018; Leclère, 2018). However, if validated, this relationship must continue to raise questions on the homology of certain traits across non-bilaterians. Many workers, citing the incompletely known development (Eitel et al., 2011; Pearse and Voigt, 2007) and relatively bilaterian-like gene content of placozoans (Srivastava et al., 2008; Eitel, 2017), presume that these organisms must have a still-unobserved, more typical development and life cycle (DuBuc et al., 2018), or else are merely oddities that have experienced wholesale secondary simplification, having scant significance to any evolutionary path outside their own. Indeed, it is tempting to interpret this new phylogenetic position as further bolstering such hypotheses, as much work on cnidarian models in the evo-devo paradigm is predicated on the notion that cnidarians and bilaterians share, more or less, many homologous morphological features, viz. axial organization (Genikhovich and Technau, 2017; DuBuc et al., 2018), nervous systems (Liebeskind et al., 2017; Moroz and Kohn, 2016; Kelava et al., 2015; Kristan, 2016; Arendt et al., 2016), basement-membrane lined epithelia (Fidler et al., 2017; Leys and Riesgo, 2012), musculature (Steinmetz et al., 2012), embryonic germ-layer organisation (Steinmetz et al., 2017), and internal digestion (Presnell et al., 2016; Putnam et al., 2007; Hejnol and Martindale, 2008; Martindale and Hejnol, 2009). While we do not argue, as some have done (Schierwater, 2005; Syed and Schierwater, 2002), that placozoans resemble hypothetical metazoan ancestors, we hesitate to dismiss them a priori as irrelevant to understanding early bilaterian evolution in particular: although apparently simpler and less diverse, placozoans nonetheless have equal status to cnidarians as an immediate extant outgroup. Rather, we see value in testing assumed hypotheses of homology, character by character, by extending pairwise comparisons between bilaterians and cnidarians to include placozoans, an agenda which demands reducing the large disparity in embryological, physiological, and molecular genetic knowledge between these taxa, towards which recent progress has been made using both established methods such as in situ hybridization (DuBuc et al., 2018) and image analysis (Varoqueaux, 2018), as well as new technologies such as single-cell RNA-seq (Sebé-Pedrós, 2018a; Sebé-Pedrós et al., 2018b). Conversely, we emphasize another implication of this phylogeny: characters that can be validated as homologous at any level between Bilateria and Cnidaria must have originated earlier in animal evolution than previously appreciated, and should either cryptically occur in modern placozoans or else have been lost at some point in their ancestry. In this light, paleobiological scenarios of early animal evolution founded on inherently phylogenetically-informed interpretations of Ediacaran fossil forms (Cavalier-Smith, 2018; Cavalier-Smith, 2017; Dufour and McIlroy, 2018; Sperling and Vinther, 2010; Evans et al., 2017) and molecular clock estimates (Cunningham et al., 2017; dos Reis et al., 2015; Dohrmann and Wörheide, 2017; Erwin et al., 2011) may require re-examination.
Materials and methods
Sampling, sequencing, and assembling reference genomes from previously unsampled placozoans
Request a detailed protocolHaplotype H4 and H6 placozoans were collected from water tables at the Kewalo Marine Laboratory, University of Hawaii-Manoa, Honolulu, Hawaii in October 2016. Haplotype H11 placozoans were collected from the Mediterranean ‘Anthias’ show tank in the Palma de Mallorca Aquarium, Mallorca, Spain in June 2016. All placozoans were sampled by placing glass slides suspended freely or mounted in cut-open plastic slide holders into the tanks for 10 days (Pearse and Voigt, 2007). Placozoans were identified under a dissection microscope and single individuals were transferred to 500 µl of RNAlater, stored as per manufacturer’s recommendations.
DNA was extracted from 3 individuals of haplotype H11 and 5 individuals of haplotype H6 using the DNeasy Blood and Tissue Kit (Qiagen, Hilden, Germany). DNA and RNA from three haplotype H4 individuals were extracted using the AllPrep DNA/RNA Micro Kit (Qiagen), with both kits used according to manufacturer’s protocols.
Illumina library preparation and sequencing was performed by the Max Planck Genome Centre, Cologne, Germany, as part of an ongoing metagenomics project in marine symbiosis. In brief, DNA/RNA quality was assessed with the Agilent 2100 Bioanalyzer (Agilent, Santa Clara, USA) and the genomic DNA was fragmented to an average fragment size of 500 bp. For the DNA samples, the concentration was increased (MinElute PCR purification kit; Qiagen, Hilden, Germany) and an Illumina-compatible library was prepared using the Ovation Ultralow Library Systems kit (NuGEN, Leek, The Netherlands) according the manufacturer’s protocol. For the haplotype H4 RNA samples, the Ovation RNA-seq System V2 (NuGen, 376 San Carlos, CA, USA) was used to synthesize cDNA and sequencing libraries were then generated with the DNA library prep kit for Illumina (BioLABS, Frankfurt am Main, Germany). All libraries were size selected by agarose gel electrophoresis, and the recovered fragments quality assessed and quantified by fluorometry. For each DNA library 14 – 75 million 100 bp or 150 bp paired-end reads were sequenced on Illumina HiSeq 2500 or 4000 machines (Illumina, San Diego, U.S.A); for the haplotype H4 RNA libraries 32 – 37 million single 150 bp reads were obtained.
For assembly, adapters and low-quality reads were removed with bbduk (https://sourceforge.net/projects/bbmap/) with a minimum quality value of two and a minimum length of 36 and single reads were excluded from the analysis. Each library was error corrected using BayesHammer (Nikolenko et al., 2013). A combined assembly of all libraries for each haplotype was performed using SPAdes 3.62 (Bankevich et al., 2012). Haplotype four and H11 data were assembled from the full read set with standard parameters and kmers 21, 33, 55, 77, 99. The Haplotype H6 data was preprocessed to remove all reads with an average kmer coverage <5 using bbnorm and then assembled with kmers 21, 33, 55 and 77.
Reads from each library were mapped back to the assembled scaffolds using bbmap (https://sourceforge.net/projects/bbmap/) with the option fast = t. Scaffolds were binned based on the mapped read data using MetaBAT (Kang et al., 2015) with default settings and the ensemble binning option activated (switch –B 20). The Trichoplax host bins were evaluated using metawatt (Strous et al., 2012) based on coding density and sequence similarity to the Trichoplax H1 reference assembly (NZ_ABGP00000000.1). The bin quality metrics were computed with BUSCO2 (Simão et al., 2015) (Table 1) and QUAST (Gurevich et al., 2013). Both the stringent metagenomics binning procedure (a procedure also expedient in other holobiont organisms (Celis et al., 2018)) and the very low proportion of multiple orthologue hits in the BUSCO2 assessment (Table 1) attest to the lack of evidence for residual non-placozoan contamination within the scaffolds used for gene prediction.
Predicting proteomes from transcriptome and genome assemblies
Request a detailed protocolPredicted proteomes from species with published draft genome assemblies were downloaded from the NCBI Genome portal or Ensembl Metazoa in June 2017. For Clade A placozoans, host metagenomic bins were used directly for gene annotation. For the H6 and H11 representatives, annotation was entirely ab initio, performed with GeneMark-ES (Ter-Hovhannisyan et al., 2008); for the H4 representative, total RNA-seq libraries obtained from three separate isolates (BioProject PRJNA505163) were mapped to genomic contigs with STAR v2.5.3a (Dobin et al., 2013) under default settings; merged bam files were then used to annotate genomic contigs and derive predicted peptides with BRAKER v1.9 (Hoff et al., 2016) under default settings. Choanoflagellate proteome predictions (Simion et al., 2017) were provided as unpublished data from Dan Richter. Peptides from a Calvadosia (previously Leucosolenia) complicata transcriptome assembly were downloaded from compagen.org. Peptide predictions from Nemertoderma westbladi and Xenoturbella bocki as used in Cannon et al 2016 (Cannon et al., 2016) were provided directly by the authors. The transcriptome assembly (raw reads unpublished) from Euplectella aspergillum was provided by the Satoh group, downloaded from (http://marinegenomics.oist.jp/kairou/viewer/info?project_id=62). Predicted peptides were derived from Trinity RNA-seq assemblies (multiple versions released 2012–2016) as described by Laumer et al (Laumer et al., 2015). for the following sources/SRA accessions:: Porifera: Petrosia ficiformis: SRR504688, Cliona varians: SRR1391011, Crella elegans: SRR648558, Corticium candelabrum: SRR504694-SRR499820-SRR499817, Spongilla lacustris: SRR1168575, Clathrina coriacea: SRR3417192, Sycon coactum: SRR504689-SRR504690, Sycon ciliatum: ERR466762, Ircinia fasciculata, Chondrilla caribensis (originally misidentified as Chondrilla nucula) and Pseudospongosorites suberitoides from (https://dataverse.harvard.edu/dataverse/spotranscriptomes); Cnidaria: Abylopsis tetragona: SRR871525, Stomolophus meleagris: SRR1168418, Craspedacusta sowerbyi: SRR923472, Gorgonia ventalina: SRR935083; Ctenophora: Vallicula multiformis: SRR786489, Pleurobrachia bachei: SRR777663, Beroe abyssicola: SRR777787; Bilateria: Limnognathia maerski: SRR2131287. All other peptide predictions were derived through transcriptome assembly as paired-end, unstranded libraries with Trinity v2.4.0 (Haas et al., 2013), running with the –trimmomatic flag enabled (and all other parameters as default), with peptide extraction from assembled transcripts using TransDecoder v4.0.1 with default settings. For these species, no ad hoc isoform selection was performed: any redundant isoforms were removed during tree pruning in the orthologue determination pipeline (see below).
Orthologue identification and alignment
Request a detailed protocolPredicted proteomes were grouped into top-level orthogroups with OrthoFinder v1.0.6 (Emms and Kelly, 2015), run as a 200-threaded job, directed to stop after orthogroup assignment, and print grouped, unaligned sequences as FASTA files with the ‘-os’ flag. A custom python script (‘renamer.py’) was used to rename all headers in each orthogroup FASTA file in the convention [taxon abbreviation] + ‘@’ + [sequence number as assigned by OrthoFinder SequenceIDs.txt file], and to select only those orthogroups with membership comprising at least one of all five major metazoan clades plus outgroups, of which exactly 4300 of an initial 46,895 were retained. Scripts in the Phylogenomic Dataset Construction pipeline (Yang and Smith, 2014) were used for successive data grooming stages as follows: Gene trees for top-level orthogroups were derived by calling the fasta_to_tree.py script as a job array, without bootstrap replicates; six very large orthogroups did not finish this process. In the same directory, the trim_tips.py, mask_tips_by_taxonID_transcripts.py, and cut_long_internal_branches.py scripts were called in succession, with ‘./. tre 10 10’, ‘././y’, and ‘./. mm 1 20. /’ passed as arguments, respectively. The 4267 subtrees generated through this process were concatenated into a single Newick file and 1419 orthologues were extracted with UPhO (Ballesteros and Hormiga, 2016). Orthologue alignment was performed using the MAFFT v7.271 ‘E-INS-i’ algorithm, and probabilistic masking scores were assigned with ZORRO (Wu et al., 2012), removing all sites in each alignment with scores below five as described previously (Laumer et al., 2015). 31 orthologues with retained lengths less than 50 amino acids were discarded, leaving 1388 well-aligned orthologues.
Matrix assembly
Request a detailed protocolA full concatenation of all retained 1388 orthogroups was performed with the ‘geneStitcher.py’ script distributed with UPhO available at https://github.com/ballesterus/PhyloUtensils. However, such a matrix would be too large for tractably inferring a phylogeny under well-fitting mixture models such as CAT + GTR; therefore we used MARE v0.1.2 (Misof et al., 2013) to extract an informative subset of genes using tree-likeness scores, running with ‘-t 100’ to retain all taxa and using ‘-d 1’ as a tuning parameter on alignment length. This yielded our 430-orthologue, 73,547 site matrix, with a mean partition length of 202.24 (s.d. 116.96) residues.
As a check on the above procedure, which is agnostic to the identity of the genes assigned into orthologue groups, we also sought to construct a matrix using complete, single-copy sequences identified by the BUSCO v3.0.1 algorithm (Simão et al., 2015), using the 303-gene eukaryote_odb9 orthologue set. BUSCO was run independently on each peptide FASTA file used as input to OrthoFinder, and a custom python script (‘extract.py’) was used to parse the full output table from each species, selecting only those entries identified as complete-length, single-copy representatives of each BUSCO orthologue, and grouping these into unix directories, facilitating downstream alignment, probabilistic masking, and concatenation, as described for the OrthoFinder matrix. This 303-gene BUSCO matrix had a total length of 94,444 amino acids, with 39.6% of sites representing gaps or missing data, with mean partition length 311.70 (standard deviation 202.78).
Within the gene bins nominated by the test of compositional heterogeneity (see below), matrices were constructed again by concatenating and reducing matrices with MARE, using ‘-t 100’ to retain all taxa and setting ‘-d 0.5’ to yield a matrix of an optimal size for inferring a phylogeny under the CAT + GTR model. This procedure gave a 349-gene matrix of 80,153 amino acids (mean partition lengths 228.67 ± s.d. 136.19, 41.64% gaps) within the test-failing gene set, and a 348-gene matrix of 55,426 amino acids (mean partition lengths 158.27 ± s.d. 79.06, 38.92% gaps), within the test-passing set (Figure 4).
Phylogenetic inference
Request a detailed protocolIndividual ML gene trees were constructed on all 1388 orthologues in IQ-tree v1.6beta, with ‘-m MFP -b 100’ passed as parameters to perform automatic model selection and 100 standard nonparametric bootstraps on each gene tree.
For inference on the initial 430-gene matrix, we proceeded as follows: ML inference on the concatenated matrix (Figure 1—figure supplement 1) was performed with IQ-tree v1.6beta, passing ‘-m C60 +LG + FO + R4 bb 1000’ as parameters to specify a profile mixture model and retain 1000 trees for ultrafast bootstrapping; the ‘-bnni’ flag was used to incorporate NNI correction during UF bootstrapping, an approach shown to control misleading inflated support arising from model misspecification (Hoang et al., 2018). ML inference using only the H1 haplotype as a representative of Placozoa (Figure 1—figure supplement 2) was undertaken similarly, albeit using a marginally less complex profile mixture model (C20 +LG + FO + R4). Bayesian inference under the CAT + GTR + Г4 model was performed in PhyloBayes MPI v1.6j (Lartillot et al., 2013) with 20 cores each dedicated to four separate chains, run for 2885–3222 generations with the ‘-dc’ flag applied to remove constant sites from the analysis, and using a starting tree derived from the FastTree2 program (Price et al., 2010). The two chains used to generate the posterior consensus tree summarized in Figure 1 converged on exactly the same tree in all MCMC samples after removing the first 2000 generations as burn-in. Analysis of Dayhoff-6-state recoded matrices in CAT + GTR + Г4 was performed with the serial PhyloBayes program v4.1c, with ‘-dc -recode dayhoff6’ passed as flags. Six chains on the 430- gene matrix were run from 1441 to 1995 generations; two chains showed a maximum bipartition discrepancy (maxdiff) of 0.042 after removing the first 1000 generations as burn-in (Figure 2). QuartetScores (Zhou, 2017) was used to measure internode certainty metrics including the reported EQP-IC, using the 430 gene trees from those orthologues used to derive the matrix as evaluation trees, and using the amino-acid CAT + GTR + Г4 tree as the reference to be annotated (Figure 1).
For inference on the BUSCO 303 gene set, we ran 4 chains of the CAT + GTR + Г4 mixture model with PhyloBayes MPI v1.7a, applying the -dc flag again to remove constant sites, but here not specifying a starting tree; chains were run from 1873 to 2361 generations. Unfortunately, no pair of chains reached strict convergence on the amino-acid version of this matrix (with all pairs showing a maxdiff = 1 at every burn-in proportion examined), perhaps indicating problems mixing among the four chains we ran. However, all chains showed full posterior support for identical relationships among the five major animal groups, with differences among chains assignable to minor differences in the internal relationships within Choanoflagellata and Bilateria. Accordingly, the posterior consensus tree in Figure 3A is summarized from all four chains, with a burn-in of 1000 generations, sampling every 10 generations. For the Dayhoff-recoded version of this matrix, we ran six separate chains again with CAT + GTR + Г4 with the -dc flag, for 5433 – 6010 generations; two chains were judged to have converged, giving a maxdiff of 0.141157 during posterior consensus summary with a burn-in of 2500, sampling every 10 generations (Figure 3B).
For inference on the 348 and 349 gene matrices produced within gene bins defined by the null-simulation test of compositional bias (see below), we ran six chains each for the amino acid and recoded versions of each matrix, under CAT + GTR + Г4 with constant sites removed. In the amino-acid matrix, chains ran from 2709 to 3457 and 1423 – 1475 generations for the test-failing and test-passing matrices, respectively. In the recoded matrix, chains ran from 3893 to 4480 and 4350 – 4812 generations for the test-failing and test-passing matrices, respectively. In selecting chains to input for posterior consensus summary tree presentation (Figure 4A–D), we chose pairs of chains and burn-ins that yielded the lowest possible maxdiff values (all <0.1 with the first 500 generations discarded as burn-in, except for the amino-acid coded test-failing matrix, whose most similar pair of chains gave a maxdiff of 0.202 with 1000 generations discarded as burn-in). We emphasize that the topologies and supports displayed in Figure 4A–D are similar when all chains (and conservative burn-in values) are used to generate consensus trees. For ML trees using profile mixture models for the test-failing (Figure 4—figure supplement 1) and test-passing (Figure 4—figure supplement 2) gene matrices, we used IQ-tree 1.6rc, calling in the same manner (with C60 +LG + FO + R4) as used on our 430-gene matrix (see above).
Tests of compositional heterogeneity
Request a detailed protocolFor posterior predictive tests of compositional heterogeneity and residue diversity using MCMC samples under CAT + GTR (Table 2), we used PhyloBayes MPI v1.8 to test two chains from the initial 430-gene matrix, three chains from the 303-gene BUSCO matrix, and six chains each from the 348 (test-failing) and 349 (test-passing) gene matrices, removing 2000 generations from the first matrix and 1000 from the others as burn-in. Results from tests on representative chains were selected for plotting in Figure 3C and summary in Table 2; however, results from all chains tested are deposited in the Data Dryad accession.
For the per-gene null simulation tests of compositional bias (Foster, 2004), we used the p4 package (https://github.com/pgfoster/p4-phylogenetics), inputting the ML trees inferred by IQ-tree for each of the 1388 alignments, and assuming an LG+Γ4 substitution model with a single empirical frequency vector for each gene; this test was implemented with a simple wrapper script (‘p4_compo_test_multiproc.py’) leveraging the python multiprocessing module. We opted not to model-test each gene individually in p4, both because the range of models implemented in p4 are more limited than those tested for in IQ-tree, and because, as a practical matter, LG (usually with variant of the FreeRates model of rate heterogeneity) was chosen as the best-fitting model in the IQ-tree model tests for a large majority of genes, suggesting that LG+Γ4 would be a reasonable approximation for the purposes of this test. We selected an α-threshold of 0.10 for dividing genes into test-passing and -failing bins as a conservative measure; however, we emphasize that even at a less conservative α = 0.05, 47% of genes would still be detected as falling outside the null expectation.
Source data availability
Request a detailed protocolSRA accession codes, where used, and all alternative sources for sequence data (e.g. individually hosted websites, personal communications), are listed above in the Materials and methods section. A DataDryad accession is available at https://doi.org/10.5061/dryad.6cm1166, which makes available all helper scripts, orthogroups, multiple sequence alignments, phylogenetic program output, and raw host proteomes inputted to OrthoFinder. Metagenomic bins containing placozoan host contigs and gene annotations from H4, H6 and H11 isolates are also provided in this accession. PhyloBayes. chain files, due to their large size, are separately accessioned at in Zenodo at https://doi.org/10.5281/zenodo.1197272.
Data availability
SRA accession codes, where used, and all alternative sources for sequence data (e.g. individually hosted websites, personal communications), are listed above in the Materials and Methods section. A DataDryad accession is available at https://doi.org/10.5061/dryad.6cm1166, which makes available all helper scripts, orthogroups, multiple sequence alignments, phylogenetic program output, and raw host proteomes inputted to OrthoFinder. Metagenomic bins containing placozoan host contigs and raw RNA reads used to derive gene annotations from H4, H6 and H11 isolates are also provided in this accession. PhyloBayes. chain files, due to their large size, are separately accessioned at in Zenodo at https://doi.org/10.5281/zenodo.1197272. Raw RNA-seq data from three separate isolates of Placozoan haplotype H4 have been deposited in NCBI BioProject under accession code PRJNA505163.
-
Dryad Digital RepositoryData from: Placozoa and Cnidaria are sister taxa.https://doi.org/10.5061/dryad.6cm1166
-
ZenodoPhyloBayes chain data from: Placozoa and Cnidaria are sister taxa.https://doi.org/10.5281/zenodo.1197272
-
NCBI BioProjectID PRJNA505163. Amplified total RNA from Placozoan H4 isolates.
References
-
From nerve net to nerve ring, nerve cord and brain--evolution of the nervous systemNature Reviews Neuroscience 17:61–72.https://doi.org/10.1038/nrn.2015.15
-
A new orthology assessment method for phylogenomic data: unrooted phylogenetic orthologyMolecular Biology and Evolution 33:2117–2134.https://doi.org/10.1093/molbev/msw069
-
SPAdes: a new genome assembly algorithm and its applications to single-cell sequencingJournal of Computational Biology 19:455–477.https://doi.org/10.1089/cmb.2012.0021
-
A site- and time-heterogeneous model of amino acid replacementMolecular Biology and Evolution 25:842–858.https://doi.org/10.1093/molbev/msn018
-
Origin of animal multicellularity: precursors, causes, consequences—the choanoflagellate/sponge transition, neurogenesis and the Cambrian explosionPhilosophical Transactions of the Royal Society B: Biological Sciences 372:0476.
-
Vendozoa and selective forces on animal origin and early diversification: reply to Dufour and McIlroy (2017)Philosophical Transactions of the Royal Society B: Biological Sciences 373:0336.https://doi.org/10.1098/rstb.2017.0336
-
STAR: ultrafast universal RNA-seq alignerBioinformatics 29:15–21.https://doi.org/10.1093/bioinformatics/bts635
-
An ediacaran pre-placozoan alternative to the pre-sponge route towards the cambrian explosion of animal life: a comment on Cavalier-Smith 2017Philosophical Transactions of the Royal Society B: Biological Sciences 373:0148.https://doi.org/10.1098/rstb.2017.0148
-
The hidden biology of sponges and ctenophoresTrends in Ecology & Evolution 30:282–291.https://doi.org/10.1016/j.tree.2015.03.003
-
Modeling compositional heterogeneitySystematic Biology 53:485–495.https://doi.org/10.1080/10635150490445779
-
Eibildung und Furchung Von Trichoplax adhaerens F. E. Schulze (Placozoa)Zeitschrift F R Morphologie Der Tiere 73:297–314.https://doi.org/10.1007/BF00391925
-
QUAST: quality assessment tool for genome assembliesBioinformatics 29:1072–1075.https://doi.org/10.1093/bioinformatics/btt086
-
Getting to the bottom of anal evolutionZoologischer Anzeiger - a Journal of Comparative Zoology 256:61–74.https://doi.org/10.1016/j.jcz.2015.02.006
-
Assessing the root of bilaterian animals with scalable phylogenomic methodsProceedings of the Royal Society B: Biological Sciences 276:4261–4270.https://doi.org/10.1098/rspb.2009.0896
-
UFBoot2: improving the ultrafast bootstrap approximationMolecular Biology and Evolution 35:518–522.https://doi.org/10.1093/molbev/msx281
-
Evolution of eumetazoan nervous systems: insights from cnidariansPhilosophical Transactions of the Royal Society B: Biological Sciences 370:20150065.https://doi.org/10.1098/rstb.2015.0065
-
A new perspective on lower metazoan relationships from 18S rDNA sequencesMolecular Biology and Evolution 16:423–427.https://doi.org/10.1093/oxfordjournals.molbev.a026124
-
BaCoCa--a heuristic software tool for the parallel assessment of sequence biases in hundreds of gene and taxon partitionsMolecular Phylogenetics and Evolution 70:94–98.https://doi.org/10.1016/j.ympev.2013.09.011
-
A bayesian mixture model for across-site heterogeneities in the amino-acid replacement processMolecular Biology and Evolution 21:1095–1109.https://doi.org/10.1093/molbev/msh112
-
Inferring ancient relationships with genomic data: a commentary on current practicesIntegrative and Comparative Biology 58:623–639.https://doi.org/10.1093/icb/icy075
-
Epithelia, an evolutionary novelty of metazoansJournal of Experimental Zoology Part B: Molecular and Developmental Evolution 318:438–447.https://doi.org/10.1002/jez.b.21442
-
Evolution of animal neural systemsAnnual Review of Ecology, Evolution, and Systematics 48:377–398.https://doi.org/10.1146/annurev-ecolsys-110316-023048
-
Animals in a bacterial world, a new imperative for the life sciencesProceedings of the National Academy of Sciences 110:3229–3236.https://doi.org/10.1073/pnas.1218525110
-
Independent origins of neurons and synapses: insights from ctenophoresPhilosophical Transactions of the Royal Society B: Biological Sciences 371:20150041.https://doi.org/10.1098/rstb.2015.0041
-
Compositional heterogeneity and phylogenomic inference of metazoan relationshipsMolecular Biology and Evolution 27:2095–2104.https://doi.org/10.1093/molbev/msq097
-
Deep metazoan phylogeny: when different genes tell different storiesMolecular Phylogenetics and Evolution 67:223–233.https://doi.org/10.1016/j.ympev.2013.01.010
-
Field biology of placozoans (Trichoplax): distribution, diversity, biotic interactionsIntegrative and Comparative Biology 47:677–692.https://doi.org/10.1093/icb/icm015
-
Improved phylogenomic taxon sampling noticeably affects nonbilaterian relationshipsMolecular Biology and Evolution 27:1983–1987.https://doi.org/10.1093/molbev/msq089
-
Genomic data do not support comb jellies as the sister group to all other animalsProceedings of the National Academy of Sciences 112:15402–15407.https://doi.org/10.1073/pnas.1518127112
-
Early metazoan cell type diversity and the evolution of multicellular gene regulation. natEcology and Evolution 2:1176–1188.
-
Neuropeptidergic integration of behavior in Trichoplax adhaerens, an animal without synapsesThe Journal of Experimental Biology 220:3381–3390.https://doi.org/10.1242/jeb.162396
-
A Genome-Scale investigation of how sequence, function, and Tree-Based gene properties influence phylogenetic inferenceGenome Biology and Evolution 8:2565–2580.https://doi.org/10.1093/gbe/evw179
-
Contentious relationships in phylogenomic studies can be driven by a handful of genesNature Ecology & Evolution 1:0126.https://doi.org/10.1038/s41559-017-0126
-
Phylogenetic position of placozoa based on large subunit (LSU) and small subunit (SSU) rRNA genesGenetics and Molecular Biology 30:127–132.https://doi.org/10.1590/S1415-47572007000100022
-
Gut-like ectodermal tissue in a sea Anemone challenges germ layer homologyNature Ecology & Evolution 1:1535–1542.https://doi.org/10.1038/s41559-017-0285-5
-
The binning of metagenomic contigs for microbial physiology of mixed culturesFrontiers in Microbiology 3:410.https://doi.org/10.3389/fmicb.2012.00410
-
On reduced amino acid alphabets for phylogenetic inferenceMolecular Biology and Evolution 24:2139–2150.https://doi.org/10.1093/molbev/msm144
-
Trichoplax adhaerens: discovered as a missing link, forgotten as a Hydrozoan, re-discovered as a key to metazoan evolutionVie Et Milieu 52:177–187.
-
Transepithelial cytophagy by Trichoplax adhaerens FE. Schulze (Placozoa) Feeding on Yeast.Z. Für Naturforschung 41:343–347.https://doi.org/10.1515/znc-1986-0316
-
Ctenophore relationships and their placement as the sister group to all other animalsNature Ecology & Evolution 1:1737–1746.https://doi.org/10.1038/s41559-017-0331-3
Article and author information
Author details
Christopher E Laumer

Funding
Max-Planck-Institut fuer Marine Microbiologie
- Harald Gruber-Vodicka
European Bioinformatics Institute
- John C Marioni
Harvard University (Faculty of Arts and Sciences)
- Gonzalo Giribet
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
Nicole Dubilier (Max Planck Institute for Marine Microbiology) contributed resources that permitted the collection and assembly of draft Trichoplax genomes, which were amplified and sequenced at the Max Planck-Genome-Centre Cologne. Dan Richter (King lab) and Kanako Hisata (Satoh lab) provided access to unpublished transcriptomes and peptide predictions. The EMBL-EBI Systems Infrastructure team provided essential support on the EBI compute cluster. Allen Collins, Scott Nichols, and particularly Andreas Hejnol provided useful comments on an earlier version of this manuscript.
Copyright
© 2018, Laumer et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 5,353
- views
-
- 740
- downloads
-
- 93
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Support for a clade of Placozoa and Cnidaria in genes with minimal compositional bias
eLife 7:e36278.
https://doi.org/10.7554/eLife.36278
Further reading
-
- Evolutionary Biology
Cichlid fishes inhabiting the East African Great Lakes, Victoria, Malawi, and Tanganyika, are textbook examples of parallel evolution, as they have acquired similar traits independently in each of the three lakes during the process of adaptive radiation. In particular, ‘hypertrophied lip’ has been highlighted as a prominent example of parallel evolution. However, the underlying molecular mechanisms remain poorly understood. In this study, we conducted an integrated comparative analysis between the hypertrophied and normal lips of cichlids across three lakes based on histology, proteomics, and transcriptomics. Histological and proteomic analyses revealed that the hypertrophied lips were characterized by enlargement of the proteoglycan-rich layer, in which versican and periostin proteins were abundant. Transcriptome analysis revealed that the expression of extracellular matrix-related genes, including collagens, glycoproteins, and proteoglycans, was higher in hypertrophied lips, regardless of their phylogenetic relationships. In addition, the genes in Wnt signaling pathway, which is involved in promoting proteoglycan expression, was highly expressed in both the juvenile and adult stages of hypertrophied lips. Our comprehensive analyses showed that hypertrophied lips of the three different phylogenetic origins can be explained by similar proteomic and transcriptomic profiles, which may provide important clues into the molecular mechanisms underlying phenotypic parallelisms in East African cichlids.
-
- Evolutionary Biology
Mammalian gut microbiomes are highly dynamic communities that shape and are shaped by host aging, including age-related changes to host immunity, metabolism, and behavior. As such, gut microbial composition may provide valuable information on host biological age. Here, we test this idea by creating a microbiome-based age predictor using 13,563 gut microbial profiles from 479 wild baboons collected over 14 years. The resulting ‘microbiome clock’ predicts host chronological age. Deviations from the clock’s predictions are linked to some demographic and socio-environmental factors that predict baboon health and survival: animals who appear old-for-age tend to be male, sampled in the dry season (for females), and have high social status (both sexes). However, an individual’s ‘microbiome age’ does not predict the attainment of developmental milestones or lifespan. Hence, in our host population, gut microbiome age largely reflects current, as opposed to past, social and environmental conditions, and does not predict the pace of host development or host mortality risk. We add to a growing understanding of how age is reflected in different host phenotypes and what forces modify biological age in primates.




{kind=link}
{kind=link}
{kind=link}
{kind=link}