Meta-Research: Lessons from a catalogue of 6674 brain recordings
- Department of Psychological Sciences, University of Liverpool, United Kingdom
- School of Psychology, University of East Anglia, United Kingdom
- Patrick Wild Centre, Division of Psychiatry, Royal Edinburgh Hospital, University of Edinburgh, United Kingdom
- Dipartimento di Psicologia Generale, Università di Padova, Italy
- Article
- Figures and data
- Abstract
- Introduction
- Meta-scientific lessons from the complete Liverpool SPN catalogue
- Horseman one: publication bias
- Horseman two: low statistical power
- Horseman three: P-hacking
- Horseman four: HARKing
- Discussion
- Data availability
- References
- Decision letter
- Author response
- Article and author information
- Metrics
Abstract
It is now possible for scientists to publicly catalogue all the data they have ever collected on one phenomenon. For a decade, we have been measuring a brain response to visual symmetry called the sustained posterior negativity (SPN). Here we report how we have made a total of 6674 individual SPNs from 2215 participants publicly available, along with data extraction and visualization tools (https://osf.io/2sncj/). We also report how re-analysis of the SPN catalogue has shed light on aspects of the scientific process, such as statistical power and publication bias, and revealed new scientific insights.
Introduction
Many natural and man-made objects are symmetrical, and humans can detect visual symmetry very efficiently (Bertamini et al., 2018; Treder, 2010; Tyler, 1995; Wagemans, 1995). Visual symmetry has been a topic of research within experimental psychology for more than a century. In recent decades, two techniques – functional magnetic resonance imaging (fMRI) and electroencephalography (EEG) – have been used to investigate the impact of visual symmetry on a region of the brain called the extrastriate cortex. Since 2011, we have been using EEG in experiments at the University of Liverpool to measure a brain response to visual symmetry called the sustained posterior negativity (SPN; see Box 1 and Figure 1). By October 2020 we had completed 40 SPN projects: 17 of these had been published, and the remaining 23 were either unpublished or under review.
Symmetry and the sustained posterior negativity (SPN).
Visual symmetry plays an important role in perceptual organization (Koffka, 1935; Wagemans et al., 2012) and mate choice (Grammer et al., 2003). This suggests sensitivity to visual symmetry is innate: however, symmetrical prototypes could also be learned from many asymmetrical exemplars (Enquist and Johnstone, 1997). Psychophysical experiments have taught us a great deal about symmetry perception (Barlow and Reeves, 1979; Treder, 2010; Wagemans, 1995), and the neural response to symmetry has been studied more recently (for reviews see Bertamini and Makin, 2014; Bertamini et al., 2018; Cattaneo, 2017). Functional MRI has reliably found symmetry activations in the extrastriate visual cortex (Chen et al., 2007; Keefe et al., 2018; Kohler et al., 2016; Sasaki et al., 2005; Tyler et al., 2005; Van Meel et al., 2019). The extrastriate symmetry response can also be measured with EEG. Visual symmetry generates an event related potential (ERP) called the sustained posterior negativity (SPN). The SPN is a difference wave – amplitude is more negative at posterior electrodes when participants view symmetrical displays compared to asymmetrical displays (Jacobsen and Höfel, 2003; Makin et al., 2012; Makin et al., 2016; Norcia et al., 2002). As shown in Figure 1, SPN amplitude scales parametrically with the proportion of symmetry in the image (Makin et al., 2020c).
Figure 1

The sustained posterior negativity (SPN).
The grand-average ERPs are shown in the upper left panel and difference waves (reflection-random) are shown in the lower left panel. A large SPN is a difference wave that falls a long way below zero. Topographic difference maps are shown on the right, aligned with the representative stimuli (black background). The difference maps depict a head from above, and the SPN appears as blue at the back. Purple labels indicate electrodes used for ERP waves [PO7, O1, O2 and PO8]. Note that SPN amplitude increases (that is, becomes more negative) with the proportion of symmetry in the image. In this experiment, the SPN increased from ~0 to –3.5 microvolts as symmetry increased from 20% to 100%. Adapted from Figures 1, 3 and 4 in Makin et al., 2020c.
The COVID pandemic stopped all our EEG testing in March 2020, and we used this crisis/opportunity to organize and catalogue our existing data. The data from all 40 of our SPN projects are now available in a public repository called “The complete Liverpool SPN catalogue” (available at https://osf.io/2sncj/; see Box 2 and Figure 2). The catalogue allows us to draw conclusions that could not be gleaned from a single experiment. It can also support meta-scientific evaluation of our data and practices, as reported in the current article.
The complete Liverpool SPN catalogue.
The complete Liverpool SPN catalogue was compiled from 40 projects, each of which involved between 1 and 5 experiments (with an experiment being defined as a study producing a dataset composed only of within-subject conditions). Sample size ranged from 12 to 48 participants per experiment (mean = 26.37; mode = 24; median = 24). Each experiment provided 1–8 grand-average SPN waves. In total, we reanalysed 249 grand-average SPNs, 6,674 participant-level SPNs, and 850,312 single trials. SPNs from other labs are not yet included in the catalogue (Höfel and Jacobsen, 2007a; Höfel and Jacobsen, 2007b; Jacobsen et al., 2018; Kohler et al., 2018; Martinovic et al., 2018; Wright et al., 2018). Steady-state visual evoked potential responses to symmetry are also unavailable (Kohler et al., 2016; Kohler and Clarke, 2021; Norcia et al., 2002; Oka et al., 2007). However, the intention is to keep the catalogue open, and the design allows many contributions. In the future we hope to integrate data from other labs. This will increase the generalizability of our conclusions. Anyone wishing to use the catalogue can start with the beginner’s guide, available on open science framework (https://osf.io/bq9ka/).
The catalogue also includes several supplementary files, including a file called “One SPN Gallery.pdf” (https://osf.io/eqhd5/) which has one page for each of the 249 SPNs, along with all technical information about the stimuli and analysis (Figure 2 shows the first SPN from the gallery). Browsing this gallery reveals that 39/40 projects used abstract stimuli, such as dot patterns or polygons (see, for example, Project 1: Makin et al., 2012). The exception was Project 14, which used flowers and landscapes (Makin et al., 2020b). The SPN is generated automatically when symmetry is present in the image (e.g., Project 13: Makin et al., 2020c). However, the brain can sometimes go beyond the image and recover symmetry in objects, irrespective of changes in view angle (Project 7: Makin et al., 2015).
Almost half the SPNs (125/249) were recorded in experiments where participants were engaged in active regularity discrimination (e.g., press one key to report symmetry and another to report random). The other 124 SPNs were recorded in conditions where participants were performing a different task, such as discriminating the colour of the dots or holding information in visual working memory (Derpsch et al., 2021). In most projects the stimuli were presented for at least 1 second and the judgment was entered in a non-speeded fashion after stimulus offset. Key mapping was usually shown on the response screen to avoid lateralized preparatory motor responses during stimulus presentation.
The catalogue is designed to be FAIR (Findable, Accessible, Interoperable and Reusable). For each project we have included uniform data files from five subsequent stages of the pipeline: (i) raw BDF files; (ii) epoched data before ICA pruning; (iii) epoched data after ICA pruning; (iv) epoched data after ICA pruning and trial rejection; (v) pre-processed data averaged across trials for each participant and condition (stage v is the starting point for most ERP visualization and meta-analysis in this article). The catalogue also includes Brain Imaging Data Structure (BIDS) formatted files from stage iv (https://osf.io/e8r95/). BIDS files from earlier processing stages can be compiled from available codes or GUI (https://github.com/JohnTyCa/The-SPN-Catalogue) by users of MATLAB with EEGLAB and BIOSEMI toolbox.
Furthermore, we developed an app that allows users to: (a) view the data and summary statistics as they were originally published; (b) select data subsets, electrode clusters, and time windows; (c) visualize the patterns; (d) export data for further statistical analysis. This is available to Windows or Mac users with a Matlab license, and a standalone version can be used on Windows without a Matlab license. The app, executable and standalone scripts, and dependencies are available on Github (https://github.com/JohnTyCa/The-SPN-Catalogue, copy archived at swh:1:rev:75e729f867c275433b68807bc3f2228c57a3ccac, Tyson-Carr, 2022). This repository and app will be maintained and expanded to accommodate data from future projects.
The folder called “SPN user guides and summary analysis” (https://osf.io/gjpr7/) also contains supplementary files that give all the technical details required for reproducible EEG research, as recommended by the Organization for Human Brain Mapping Pernet et al., 2020. For instance, the file called “SPN effect size and power V8.xlsx” has one worksheet for each project (https://osf.io/c8jgy/). This file documents all extracted ERP data along with details about the electrodes, time windows, ICA components removed, and trials removed. With a few minor exceptions, anyone can now reproduce any figure or analysis in our SPN research. Users can also run alternative analyses that depart from the original pipeline at any given stage. Finally, the folder called “Analysis in eLife paper” contains all materials from this manuscript (https://osf.io/4cs2p/).
Although this paper focuses on meta-science, we can briefly summarize the scientific utility of the catalogue. Analysis of the whole data set shows that SPN amplitude scales with the salience of visual regularity. This can be estimated with the ‘W-load’ from theoretical models of perceptual goodness (van der Helm and Leeuwenberg, 1996). SPN amplitude also increases when regularity is task relevant. Linear regression with two predictors (W-load and Task, both coded on a 0–1 scale) explained 33% variance in grand-average SPN amplitude (SPN (microvolts) = –1.669 W – 0.416Task +0.071). The SPN is slightly stronger over the right hemisphere, but the laws of perceptual organization, that determine SPN amplitude, are similar on both sides of the brain. Source dipole analysis can also be applied to the whole data set (following findings of Tyson-Carr et al., 2021). We envisage that most future papers will begin with meta-analysis of the SPN catalogue, before reporting a new purpose-built experiment. The SPN catalogue also allows meta-analysis of other ERPs, such as P1 or N1, which may be systematically influenced by stimulus properties (although apparently not W-load).
Figure 2
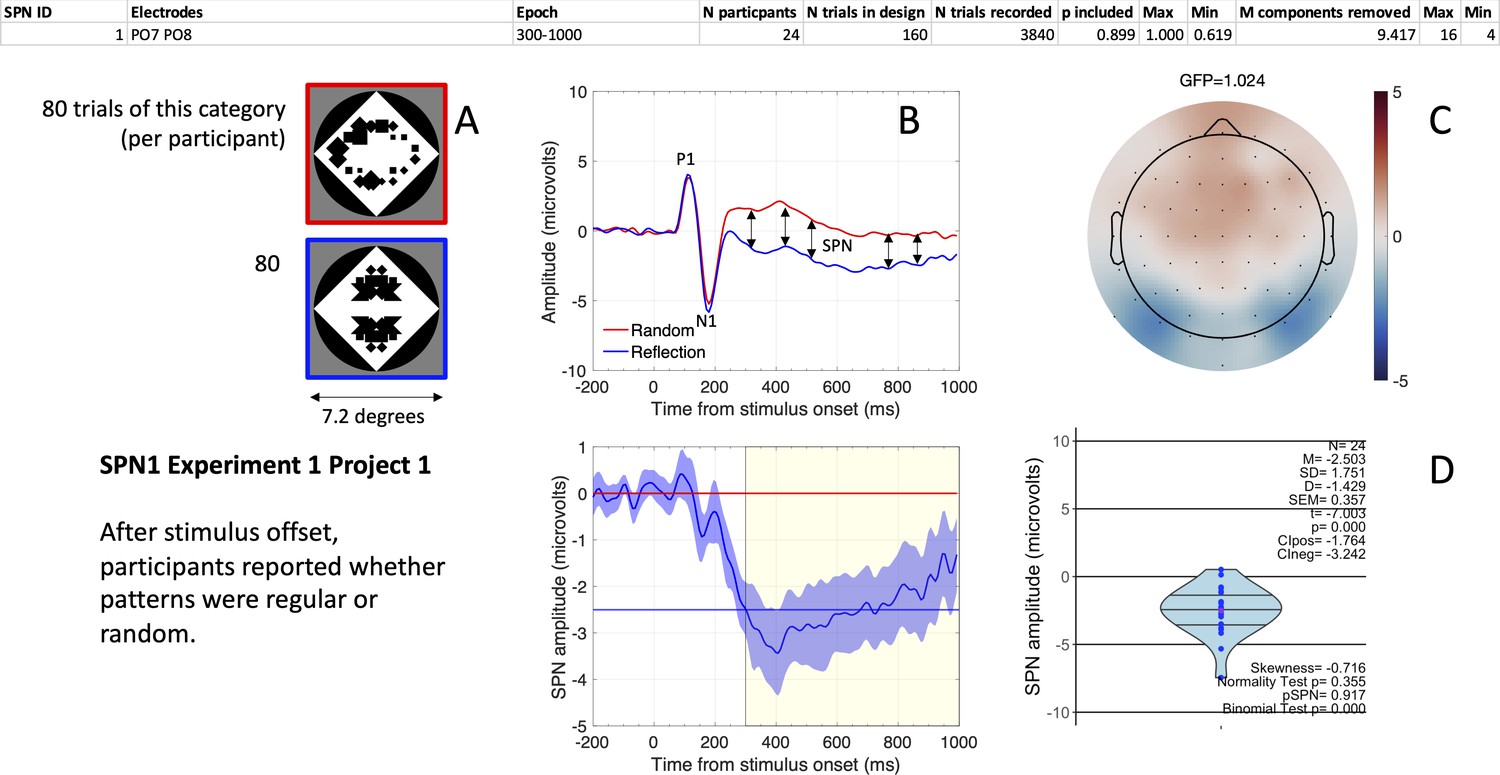
The first SPN from the SPN Gallery.
(A) Examples of stimuli. (B). Grand-average ERP waves from electrodes PO7 and PO8 (upper panel), and the SPN as a reflection-random difference wave (with 95% CI; lower panel). The typical 300–1000ms SPN window is highlighted in yellow. Mean amplitude during this window was –2.503 microvolts (horizontal blue line). (C) SPN as a topographic difference map. (D) Violin plot showing SPN amplitude for each participant plus descriptive and inferential statistics. The file “One SPN Gallery.pdf” (https://osf.io/eqhd5/) contains a figure like this for all 249 SPNs. The analysis details shown at the top of the figure are also explained in this file.
Meta-scientific lessons from the complete Liverpool SPN catalogue
There is growing anxiety about the trustworthiness of published science (Munafò et al., 2017; Open Science Collaboration, 2015; Errington et al., 2021). Many have argued that we should build cumulative research programs, where effects are measured reliably, and the truth becomes clearer over time. However, common practice often falls far short of this ideal. And although there has been a positive response to the replication crisis in psychology (Nelson et al., 2018), there is still – according to the cognitive neuroscientist Dorothy Bishop – room for improvement: “many researchers persist in working in a way almost guaranteed not to deliver meaningful results. They ride what I refer to as the four horsemen of the irreproducibility apocalypse” (Bishop, 2019). The four horsemen are: (i) publication bias; (ii) low statistical power; (iii) p value hacking; (iv) HARKing (hypothesizing after results known).
The “manifesto for reproducible science” includes these four items and two more: poor quality control in data collection and analysis, and the failure to control for bias (Munafò et al., 2017). Such critiques challenge all scientists to answer a simple question: are you practicing cumulative science, or is your research is undermined by the four horsemen of the irreproducibility apocalypse? Indeed, before compiling the SPN catalogue, we were unable to answer this question for our own research program.
One problem with replication attempts is their potentially adversarial nature. Claiming that other people’s published effects are unreliable insinuates bad practice, while solutions such as “adversarial collaboration” are still rare (Cowan et al., 2020). In this context and heeding the call to make research in psychology auditable (Nelson et al., 2018), we decided to take an exhaustive and critical look at the complete SPN catalogue in terms of the four horsemen of irreproducibility.
Horseman one: publication bias
Most scientists are familiar with the phrase “publish or perish” and know it is easier to publish a statistically significant effect (P<.05). Null results accumulate in the proverbial file drawer, while false positives enter the literature. This publication bias leads to systematic overestimation of effect sizes in meta-analysis (Brysbaert, 2019; Button et al., 2013).
The cumulative distribution of the 249 SPN amplitudes is shown in Figure 3A (top panel), along with the cumulative distributions for those in the literature and those in the file drawer (middle panel). The unpublished SPNs were weaker than the published SPNs (mean difference = 0.354 microvolts [95% CI=0.162–0.546], t (218.003)=3.640, P<.001, equal variance not assumed). Furthermore, the published SPNs came from experiments with smaller sample sizes (mean sample sizes = 23.40 vs 29.49, P<.001, Mann-Whitney U test).
Figure 3
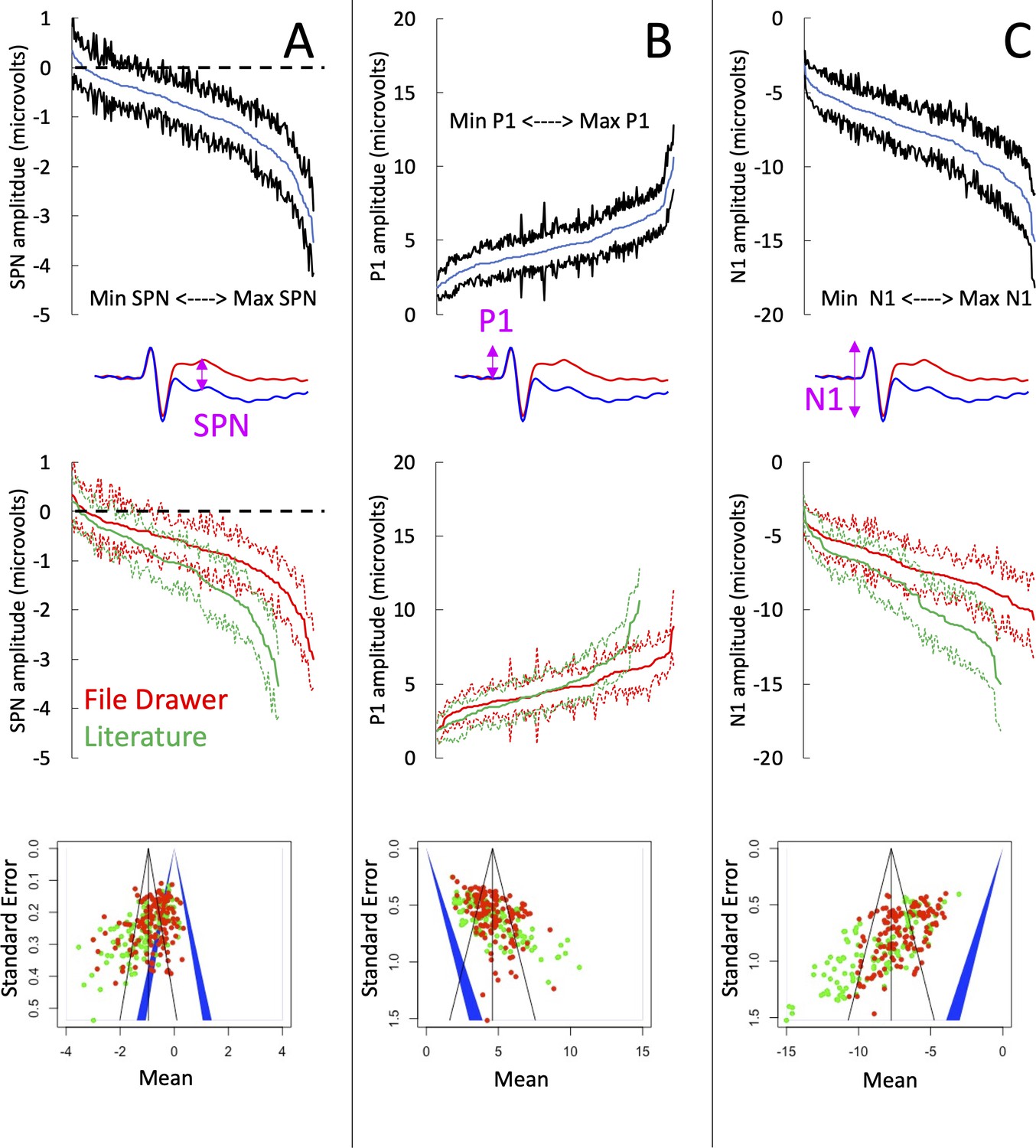
SPN amplitudes in published and unpublished work.
(A) The top panel shows the cumulative distribution of all 249 grand-average SPNs. The smallest SPN is at the left-most end of the x-axis, and the largest SPN is at the right-most end. The blue line is comprised 249 data points, and the black lines show 95% confidence intervals. If the upper confidence interval does not rise above zero, we have a significant SPN (P<.05, two-tailed). The middle panel shows that the 134 unpublished SPNs in the file drawer (red) are smaller (i.e., less negative) than the 115 published SPNs in the literature (green). The bottom panel shows a funnel plot of 249 grand-average SPNs arranged by mean (x-axis) and standard error (y-axis). Red dots are unpublished SPNs, green dots are published SPNs. Dots to the left of the blue central triangle represent significant SPNs (inner edge, P<.05, outer edge, P<.01); if dots are inside the blue triangle, the effect is non-significant. (B) Equivalent set of plots for the peak amplitude P1 on regular trials. (C) Equivalent set of plots for the trough amplitude N1 on regular trials.
To further explore these effects, we ran three meta-analyses (using the metamean function from the dmetar library in R). Full results are described in supplementary materials (https://osf.io/q4jfw/). The weighted mean amplitude of the published SPNs was –1.138 microvolts [95% CI = –1.290; –0.986]. This was reduced to –0.801 microvolts [–0.914; –0.689] for the unpublished SPNs, and to –0.954 microvolts [–1.049; –0.860] for all SPNs. The funnel plot for the published SPNs (Figure 3A; bottom panel) is not symmetrically tapered (less accurate measures near the base of the funnel are skewed leftwards). This is a textbook fingerprint of publication bias. However, the funnel asymmetry was still significant for the unpublished SPNs and for all SPNs, so publication bias cannot be the explanation (see Zwetsloot et al., 2017 for detailed analysis of funnel asymmetry).
The amplitudes of the P1 peak and the N1 trough from the same trials provide an instructive comparison. Our SPN papers do not need large P1 and N1 components, so these are unlikely to have a systematic effect on publication. P1 peak was essentially identical in published and unpublished work (4.672 vs 4.686, t (195.11) = –0.067, P=.946; Figure 3B). This is potentially an interesting counterpoint to the SPN. However, the N1 trough was larger in published work (–8.736 vs. –7.155. t (183.61) = –5.636, P<.001; Figure 3C). The funnel asymmetry was also significant for both P1 and N1.
Summary for horseman one: publication bias
This analysis suggests a tendency for large SPNs to make it into the literature, and small ones to linger in the file drawer. In contrast, the P1 was essentially identical in published and unpublished work. However, we do not think publication bias is a problem in our SPN research. The published and unpublished SPNs are from heterogenous studies, with different stimuli and tasks. We would not necessarily expect them to have the same mean amplitude. In other words, the SPN varies across studies not only due to neural noise and measurement noise, but also due to experimental manipulations affecting the neural signal (although W-load and Task were similar in published and unpublished work, see Box 2). Furthermore, it is not the case that our published papers selectively report one side of a distribution with a mean close to zero. Our best estimate of mean SPN amplitude (–0.954 microvolts) is far below zero [95% CI = –1.049; –0.860]. The file drawer has no embarrassing preponderance of sustained posterior positivity.
Some theoretically important effects can appear robust in meta-analysis of published studies, but then disappear once the file drawer studies are incorporated. Fortunately, this does not apply to the SPN. We suggest that assessment of publication bias is a feasible first step for other researchers undertaking a catalogue-evaluate exercise.
Horseman two: low statistical power
According to Brysbaert, 2019, many cognitive psychologists have overly sunny intuitions about power analysis and fail to understand it properly. The first misunderstanding is that an effect on the cusp of significance (P=.05) has a 95% chance of successful replication, when in fact the probability of successful replication is only 50% (power = 0.5). Researchers often work on the cusp of significance, where power is barely more than 0.5. Indeed, one influential analysis estimated that median statistical power in cognitive neuroscience is just 0.21 (Button et al., 2013). In stark contrast, the conventional threshold for adequate power is 0.8. Although things may be improving, many labs still conduct underpowered experiments without sufficient awareness of the problem.
To estimate statistical power, one needs a reliable estimate of effect size, and this is rarely available a priori. In the words of Brysbaert, 2019, “you need an estimate of effect size to get started, and it is very difficult to get a useful estimate”. It is well known that effect size estimates from published work will be exaggerated because of the file drawer problem (as described previously). It is less well known that one pilot experiment does not provide a reliable estimate of effect size (especially when the pilot itself has a small sample; Albers and Lakens, 2018). Fortunately, we can estimate SPN effect size from many experiments, published and unpublished, and this allows informative power analysis.
For a single SPN, the relevant effect size metric is Cohen’s dz (mean amplitude difference/SD of amplitude differences). Figure 4A shows the relationship between SPN amplitude and effect size dz. The larger (more negative) the SPN in microvolts, the larger dz. The curve tails off for strong SPNs, resulting in a nonlinear relationship. The second order polynomial trendline was a better fit than the first order linear trendline (see the supplementary polynomial regression analysis at https://osf.io/f2659/). The same relationship is found whether regularity is task relevant or not (Figure 4B) and in published and unpublished work (Figure 4C). Crucially, we can now estimate typical effect size for an SPN with a given amplitude using this polynomial regression equation (see the SPN effect size calculator at https://osf.io/gm734/).
Figure 4
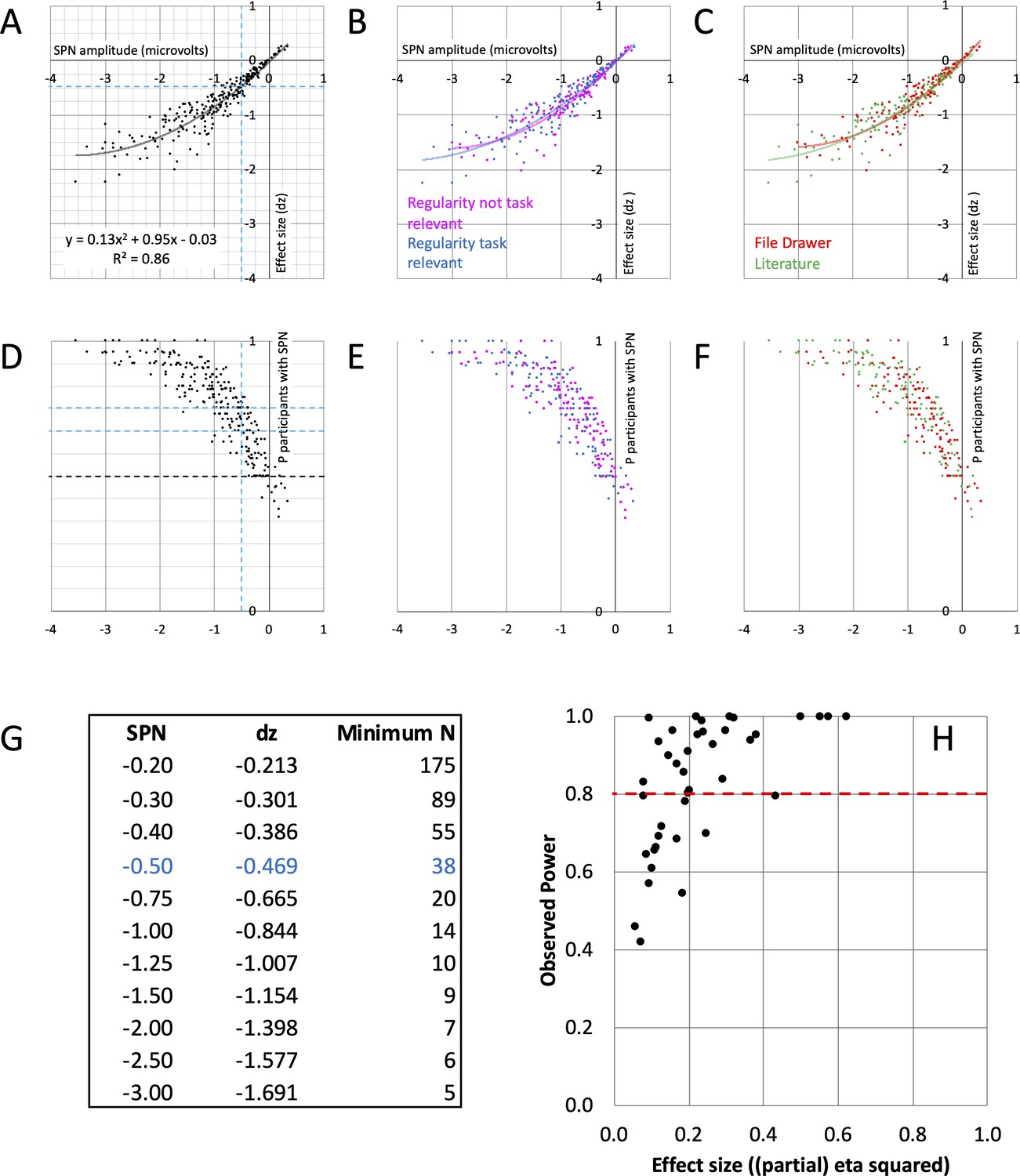
SPN effect size and power.
(A–C) The nonlinear relationship between SPN amplitude and effect size. The equation for the second order polynomial trendline is shown in panel A (y = 0.13x2+0.95 x - 0.03). This explains 86% of variance in effect size (R2=0.86). Using the equation, we can estimate effect size for an SPN of a given amplitude. Dashed lines highlight –0.5 microvolt SPNs, with average effect size dz of –0.469. For an 80% chance of finding this effect, an experiment requires 38 participants. The relationships were similar whether regularity was task relevant or not (B), and in published and unpublished work (C). (D–F) How many participants show the SPN? The larger (more negative) the SPN, the more individual participants show the effect (regular < random). Dashed lines highlight –0.5 microvolt SPNs, which are quite often present in 2/3 but not 3/4 of the participants. The relationships were similar whether regularity was task relevant or not (E), and in published and unpublished work (F). (G) Table of required N for 80% chance of obtaining an SPN of a given amplitude. (H) Observed power and effect size of 40 SPN modulations. 15/40 do not reach the 0.8 threshold (red line).
This approach can be illustrated with 0.5 microvolt SPNs. Although these are at the low end of the distribution (Figure 4A), they can be interpreted and published (e.g., Makin et al., 2020a). The average dz for a 0.5 microvolt SPN is –0.469. Power analysis shows that to have an 80% chance of finding an effect of this size (P<.05, two tailed) we need a sample of 38 participants. In contrast, our median sample size is 24, which gives us an observed power of just 60%. In other words, if we were to choose a significant 0.5 microvolt SPN and rerun the exact same experiment, there is a 100%–60%=40% chance we would not find the significant SPN again. This is not a solid foundation for cumulative research.
Only a third of the 249 SPNs are 0.5 microvolts or less. However, many papers do not merely report the presence of a significant SPN. Instead, the headline effect is usually a within-subjects difference between experimental conditions. As a first approximation, we can assume the same power analysis applies to pairwise SPN modulations. We thus need 38 participants for an 80% chance of detecting an ~0.5 microvolt SPN difference between two regular conditions (and more participants for between-subject designs).
The table in Figure 4G gives required sample size (N) for 80% chance of obtaining SPNs of a particular amplitude (power = 0.8, alpha = 0.05, two-tailed). This suggests relatively large 1.5 microvolt SPNs could be obtained with just 9 participants. However, estimates of effect size are less precise at the high end (see the supplementary polynomial regression analysis at https://osf.io/f2659). A conservative yet feasible approach is to collect at least 20 participants even when confident of obtaining a large SPN or SPN modulation. Alternatively, researchers may require a sample that allows them to find the minimum effect that would still be of theoretical interest. Brysbaert, 2019, suggests this may often be ~0.4 in experimental psychology, and this requires 52 participants. Indeed, the theoretically interesting effect of Task on SPN amplitude could be in this range.
Power of nonparametric tests
Of the 249 SPNs, 9.2% were not normally distributed about the mean according to the Shapiro-Wilk test (8.4% according to Kolmogorov-Smirnov test). Non-parametric statistics could thus be appropriate for some SPN analyses. For a non-parametric SPN, significantly more than half of the participants must have lower amplitude in the regular condition. We can examine this with a binomial test. Consider a typical 24 participant SPN: For a significant binomial test (P<.05, two tailed), we need at least 18/24=3/4 participants in the sample to show the directional effect (regular < random). Next, consider doubling sample size to 48: We now need only 32/48=2/3 participants in the sample to show the directional effect. Figure 4D–F illustrates the proportion of participants showing the directional effect as a function of SPN amplitude. Only 146 of the 249 grand-average SPNs (59%) were computed from a sample where at least 3/4 of the participants showed the directional effect. Meanwhile, 183 (73%) were from a sample where at least 2/3 of the participants showed the directional effect (blue horizontals in Figure 4D). This analysis recommends increasing sample size to 48 in future experiments.
Power of SPN modulation effects
When there are more than two conditions, mean SPN differences may be tested with ANOVA. To assess statistical power, we reran 40 representative ANOVAs from published and unpublished work. This includes all those which support important theoretical conclusions (Makin et al., 2015; Makin et al., 2016; Makin et al., 2020c; see https://osf.io/hgncs/ for a full list of the experiments used in this analysis). Observed power was less than the desired 0.8 in 15 of 40 (Figure 4H). We note that several underpowered analyses are from Project 7 (Makin et al., 2015). This is still an active research area, and we will increase sample size in future experiments.
Increasing the number of trials
Another line of attack is to increase the number of trials per participant. Boudewyn et al., 2018 argue that adding trials is alternative way to increase statistical power in ERP research, even when split-half reliability is apparently near ceiling (as it is in SPN research: Makin et al., 2020b). In one highly relevant analysis, Boudewyn et al., 2018 examined a within-participant 0.5 microvolt ERP modulation with a sample of 24 (our median sample). Increasing the number of trials from 45 to 90 increased the probability of achieving a significant effect from ~.54 to~.89 (see figure eight in Boudewyn et al., 2018). These authors caution that simulations of other ERP components are required to establish generalizability. We typically include at least 60 trials in each condition. However, going up to 100 trials per condition could increase SPN effect size, and this may mitigate the need to increase sample size (Baker et al., 2021). Of course, too many trials could introduce participant fatigue and a consequent drop in data quality. There is likely a sample size X trial number ‘sweet spot’ and are unlikely to have hit it already by luck.
Typical sample sizes in other EEG research
When planning our experiments, we have often assumed that 24 is a typical sample size in EEG research. This can be checked objectively. We searched open-access EEG articles within the PubMed Central database using a text-mining algorithm. A total of 1,442 sample sizes were obtained. Mean sample size was 35 (±22.97) and a median was 28. The most commonly occurring sample size was 20. We also extracted sample sizes from 74 EEG datasets on the OpenNeuro BIDS compliant repository. The mean sample size was 39.34 (±38.56), the median was 24, and the mode was again 20. Our SPN experiments do indeed have typical sample sizes, as we had assumed.
Summary for horseman two: low statistical power
Low statistical power is an obstacle to cumulative SPN research. Before the COVID pandemic stopped all EEG research, we were completing around 10 EEG experiments per year with a median sample of 24. When EEG research starts again, we may reprioritize, and complete fewer experiments per year with more participants in each. Furthermore, one can tentatively assume that other ERPs have comparable signal/noise properties to the SPN. If so, we can plausibly infer that many ERP experiments are underpowered for detecting 0.5 microvolt effects. Figure 4G thus provides a rough sample size guide for ERP researchers, although we stress that more ERP-specific estimates of effect size should always be treated as superior. We also stress that our sample size recommendations do not directly apply to multi-level or multivariate analyses, which are increasingly common in many research fields. Nevertheless, this investigation has strengthened our conviction that EEG researchers should collect larger samples by default. Several benefits more than make up for the extra time spent on data collection. Amongst other things, larger samples reduce Type 2 error, give more accurate estimates of effect size, and facilitate additional exploratory analyses on the same data sets.
Horseman three: P-hacking
Sensitivity of an effect to arbitrary analytical options is called the ‘vibration of the effect’ (Button et al., 2013). An effect that vibrates substantially is vulnerable to ‘P-hacking’: that is, exploiting flexibility in the analysis pipeline to nudge effects over the threshold for statistical significance (for example, P=.06 conveniently becomes P=.04, and the result is publishable). “Double dipping” is one particularly tempting type of P-hacking for cognitive neuroscientists because we typically have such large, multi-dimensional data sets (Kriegeskorte et al., 2009). Researchers can dip into a large dataset, observe where something is happening, then run statistical analysis on this data selection alone. For example, in one early SPN paper, Höfel and Jacobsen, 2007a state that "Time windows were chosen after inspection of difference waves" (page 25, section 2.8.3). It is commendable that Höfel and Jacobsen were so explicit: often double dipping is spread across months where researchers alternate between ‘preliminary’ data visualization and ‘preliminary’ statistical analysis so many times that they lose track of which came first. Double dipping beautifies results sections, but without appropriate correction, it inflates Type 1 error rate. We thus attempted to estimate the extent of P-hacking in our SPN research, with a special focus on double dipping.
Electrode choice
Post hoc electrode choice can sometimes be justified: Why analyse an electrode cluster that misses the ERP of interest? Post hoc electrode choice could be classed as a questionable research practice rather than flagrant malpractice (Agnoli et al., 2017; Fiedler and Schwarz, 2015; John et al., 2012). Nevertheless, we must at least assess the consequences of this flexibility. What would have happened if we had dogmatically stuck with the same electrodes for every analysis, without granting ourselves any flexibility at all?
To estimate this, we chose three a priori bilateral posterior electrode clusters and recomputed all 249 SPNs (Cluster 1 = [PO7 O1, O2 PO8], Cluster 2 = [PO7, PO8], Cluster 3 = [P1 P3 P5 P7 P9 PO7 PO3 O1, P2 P4 P6 P8 P10 PO8 PO4 O2]). The first two clusters were chosen because we have used them often in published research (Cluster 1: Makin et al., 2020c; Cluster 2: Makin et al., 2016). Cluster 3 was chosen because the 16 electrodes cover the whole bilateral posterior region. These three clusters are labelled on a typical SPN topoplot in Figure 5A. Reassuringly, we found that SPN amplitude is highly correlated across clusters (Pearson’s r ranged from .946 to .982, P<.001; Figure 5B). This suggests vibration is low, and flexible electrode choice has not greatly influenced our SPN findings. In fact, mean SPN amplitude would have been slightly higher if we had used Cluster 2 for all projects. Average SPN amplitude was –0.98 microvolts [95% CI = –1.08 to –0.88] with the original cluster, –0.961 [–1.05; –0.87] microvolts for Cluster 1,–1.12 [–1.22; –1.01] microvolts for Cluster 2, and –0.61 [ –0.66; –0.55] microvolts for Cluster 3.
Figure 5
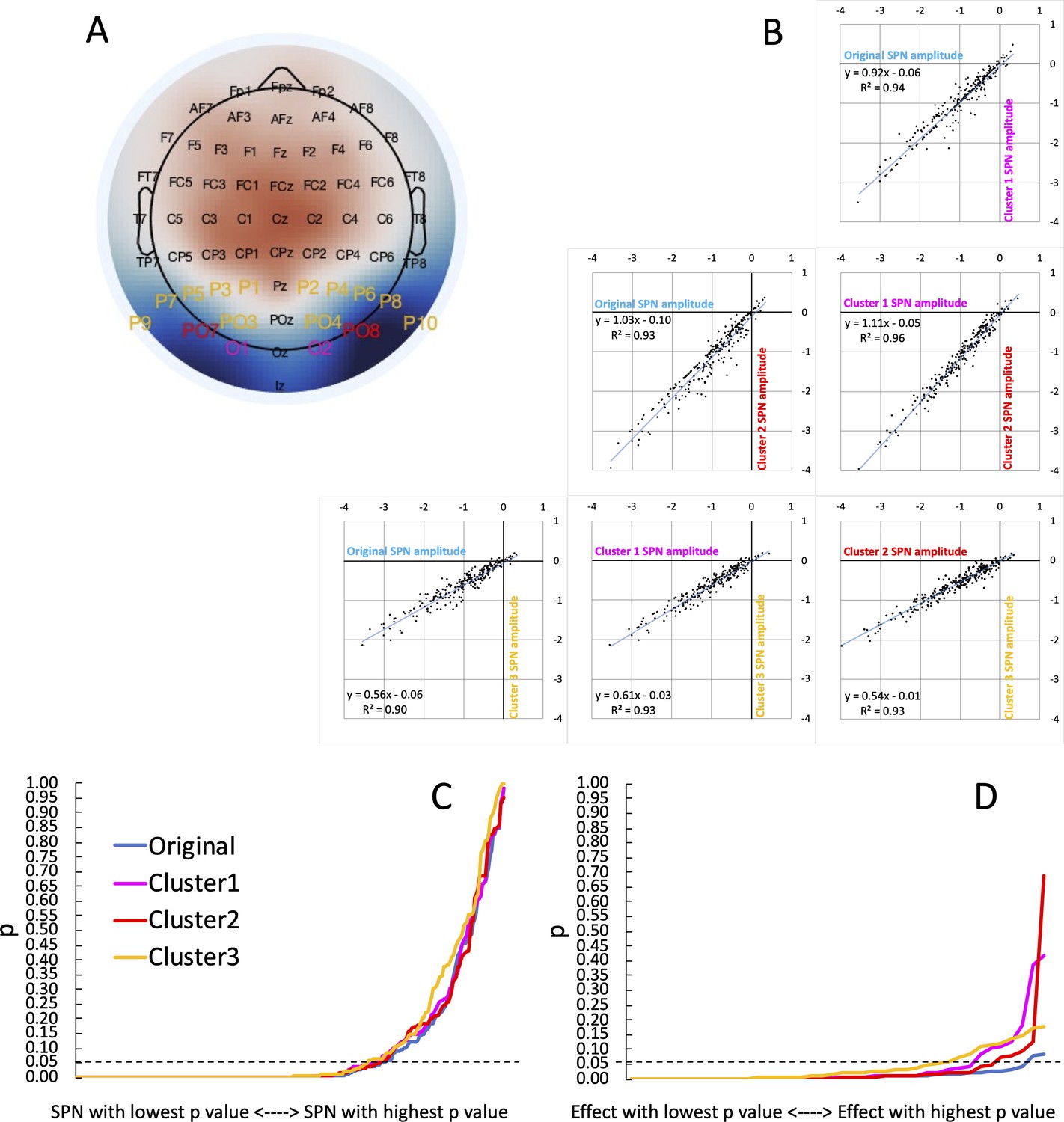
Vibration of the SPN effect.
(A) Typical SPN topographic difference map with labels colour coded to show three alternative electrode clusters, which could have been used dogmatically in all analyses, whatever the observed topography. (B) Scatterplots show SPNs from the original cluster and the three alternatives, which are highly correlated. (C) One-sample t-tests were used to establish whether each SPN is significant. The cumulative distribution of p values is shown here. The smallest p value (from the most significant SPN) is at the left-most end of the x axis, and the largest p value (from the least significant SPN) is at the right-most end. The p values from the original cluster and the three alternatives were very similar. There was a similar number of significant SPNs (169–177). (D) ANOVAs are used to assess SPN modulations. The p values from 40 representative ANOVA effects do not overlap completely. There were more significant SPN modulations when the original electrode cluster was used than any alternative (38 vs 35–29).
Next, we ran one-sample t-tests on the SPN as measured at the 4 alternative clusters. The resulting p values are shown cumulatively in Figure 5C. Crucially, the area under the curve is similar for all cases. The significant SPN count varies only slightly, between 169 and 177 (χ2 (3)=0.779, P=.854). We conclude that flexible electrode choice has not substantially inflated the number of significant SPNs in our research.
To illustrate this in another way, Figure 6 shows a colour-coded table of p values, sorted by original cluster. At the top there are many rows which are significant whichever cluster is used (green rows). At the bottom there are many rows which are non-significant whichever cluster is used (red rows). The interesting rows are in the middle, where there is some disagreement indicating that the original effect was a false positive (some green and some red cells on each row). We can zoom in on the central portion: where, exactly, are the disagreements? Two cases come from Wright et al., 2017 however, this project reported a contralateral SPN, and these are inevitably more sensitive to electrode choice because they only cover half the scalp surface area.
Figure 6

Which SPNs are significant using alternative clusters?
The left column shows a table of all 249 SPNs, colour coded (green, significant; red, non-significant), and sorted by p value obtained using the original cluster. The important part of the table is the centre, where significance thresholds are crossed by some clusters but not others. The central part is expanded, so text is now readable. The important cases are published SPNs that are not significant when either Cluster 1 or 2 is used instead. These 4 cases are all labelled (red boxes).
We applied the same reanalysis to our 40 representative ANOVA main effects and interactions. Here there is more cause for concern: 38 of the 40 effects were significant using the original electrode cluster, however this goes down to 33 with Cluster 1, 35 with Cluster 2, and to just 29 with Cluster 3 (Figure 5D). Flexible electrode choice has thus significantly increased the number of significant SPN modulations (χ2 (3)=8.107, P=.044).
Spatio-temporal clustering
The above analysis examines consequences of choosing different electrode clusters a priori, while holding time window constant. Next, we used a spatio-temporal clustering technique (Maris and Oostenveld, 2007) to identify both electrodes and timepoints where the difference between regular and irregular conditions is maximal. Does this purely data driven approach lead to the same conclusions as the original analysis from a priori electrode clusters?
After obtaining all negative electrode clusters with significant effect (P<.05, two tailed) the single most significant cluster was extracted for each SPN. The proportion of times that each electrode appeared in this cluster is illustrated in Figure 7A (electrodes present in less than 10% of cases are excluded). Findings indicate that electrodes O1 and PO7 are most likely to capture the SPN over the left hemisphere, and O2 and PO8 are most likely to capture the SPN over the right hemisphere. This is consistent with our typical a priori electrode selections. Figure 7B shows activity was mostly confined to the 200 to 1000ms window, extending somewhat to 1500ms. This is consistent with our typical a priori time window selections. Apparently there were no effects at electrodes or at time windows we had previously neglected.
Figure 7
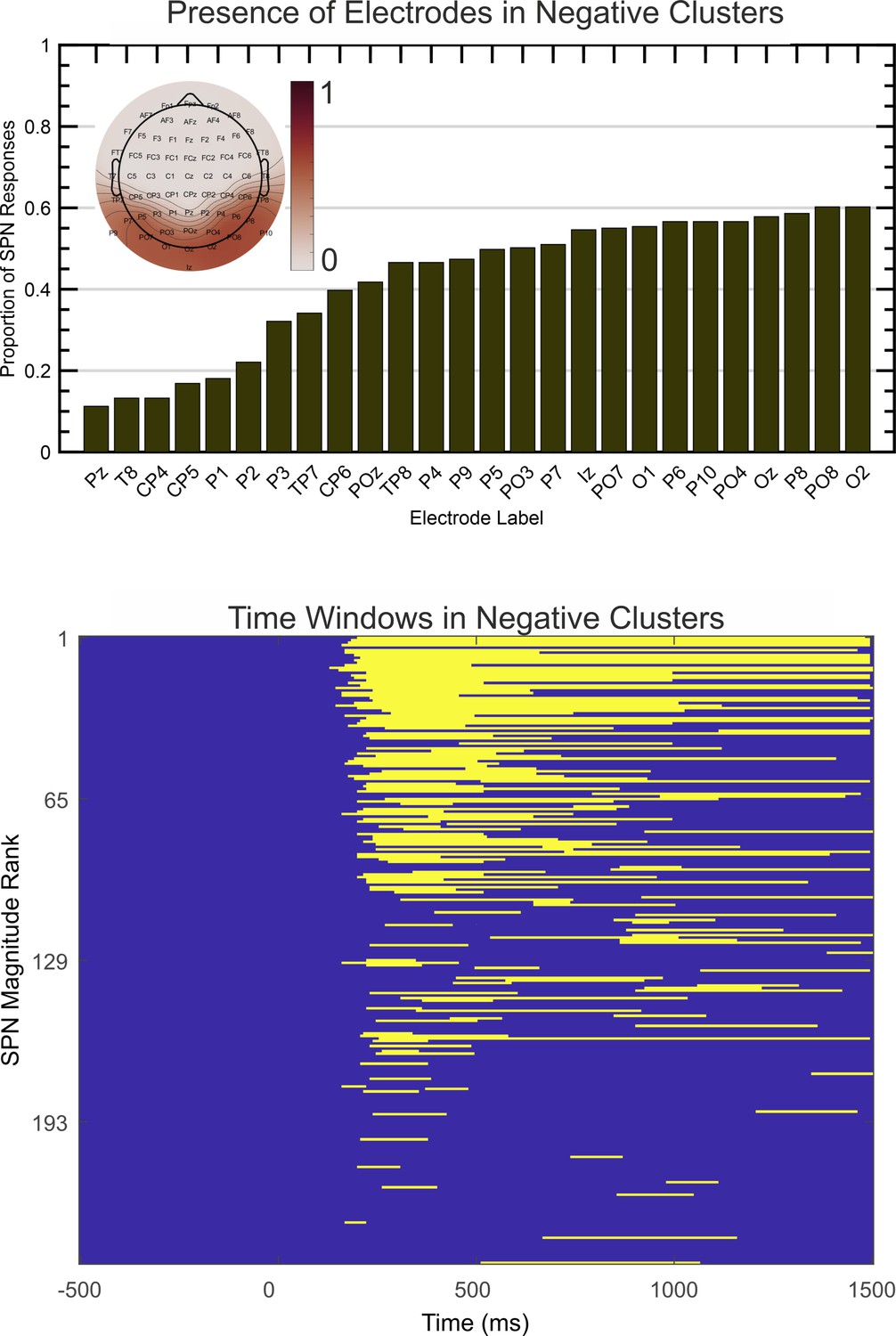
Spatio-temporal clustering results.
The upper image illustrates the proportion of times each electrode appeared in the most significant negative cluster. Electrodes appearing in less than 10% of cases are excluded. The topoplot inset shows proportions on a colour scale for all electrodes. The lower image illustrates the time course over which the same negative clusters were active, ranked by SPN magnitude.
To quantify these consistencies, SPNs were recomputed using the electrode cluster and time window obtained with spatiotemporal cluster analysis. There was a strong correlation between this and SPN from each a priori cluster (Pearson’s r ranged from .719 to .746, P<.001; Figure 8).
Figure 8
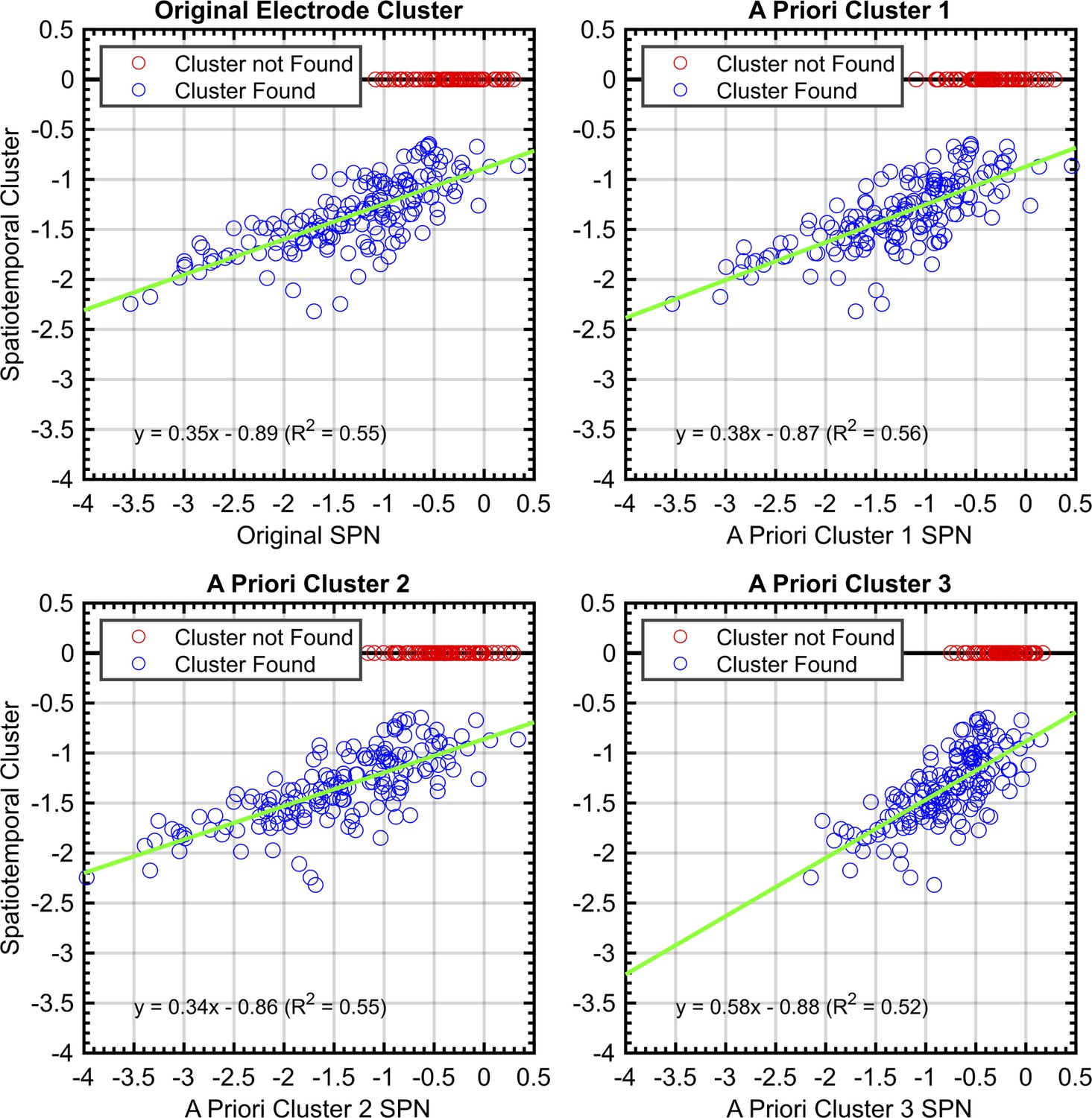
Correlations between SPNs from a priori and data-driven selections.
Red data points indicate no significant negative cluster was found for that SPN. For these points, the mean SPN cluster is plotted as zero and does not influence the green least-squares regression line.
There are two further noteworthy results from spatiotemporal clustering analysis. First, 74% of published data sets yielded a significant cluster, while the figure was only 57% for unpublished data (as of May 2022). This is another estimate of publication bias. Second, we can explain some of the amplitude variation shown in Figure 8. As described in Box 2, 33% of variance in grand-average SPN amplitude can be predicted by two factors called W and Task (SPN (microvolts) = –1.669 W – 0.416Task + 0.071). We also ran this regression analysis on the spatiotemporal cluster SPNs (i.e., the blue data points in Figure 8). The two predictors now explained just 16.8% of variance in grand-average SPN amplitude (SPN (microvolts) = –0.557 W – 0.170Task – 0.939). The reduced R2, shallower slopes and lower intercept are largely caused by the fact that many data sets had to be excluded because they did not yield a cluster (i.e., the red data points in Figure 8). This highlights one disadvantage of spatiotemporal clustering: For many purposes we want to include small and non-significant SPNs in pooled analysis of the whole catalogue. However, these relevant data points are missing or artificially set at zero if SPNs are extracted by spatiotemporal clustering.
Pre-processing pipelines
There are many pre-processing stages in EEG analysis (Pernet et al., 2020). For example, our data is often re-referenced to a scalp average, low pass filtered at 25 Hz, down-sampled to 128 Hz and baseline corrected using a –200 to 0ms pre-stimulus interval. We then remove some blink and other large artifacts with independent components analysis (Jung et al., 2000). We sometimes remove noisy electrodes with spherical interpolation. We then exclude trials where amplitude exceeds +/-100 microvolts at any electrode.
To examine whether these pre-processing norms are consequential, we reanalysed data from 5 experiments from Project 13 in BESA instead of Matlab and EEGLAB, using different cleaning and artifact removal conventions. When using BESA, we employed the recommended pipelines and parameters. Specifically, we used a template matching algorithm to identify eye-blinks and used spatial filtering to correct eye-blinks within the continuous data. Trials were removed that exceeded an amplitude of ±120 microvolts or a gradient of ±75 (with the gradient being defined as the difference in amplitude between two neighbouring samples). Although this trial exclusion takes place on filtered data, remaining trials are averaged across pre-filtered data. High and low pass filters were set to 0.1 and 25 Hz in both EEGLAB and BESA. While EEGLAB used zero-phase filters, filtering in BESA used a forward-filter for the high-pass filter but used a zero-phase filter for the low-pass. As seen in Figure 9, similar grand-average SPNs fall out at the end of these disparate pipelines.
Figure 9
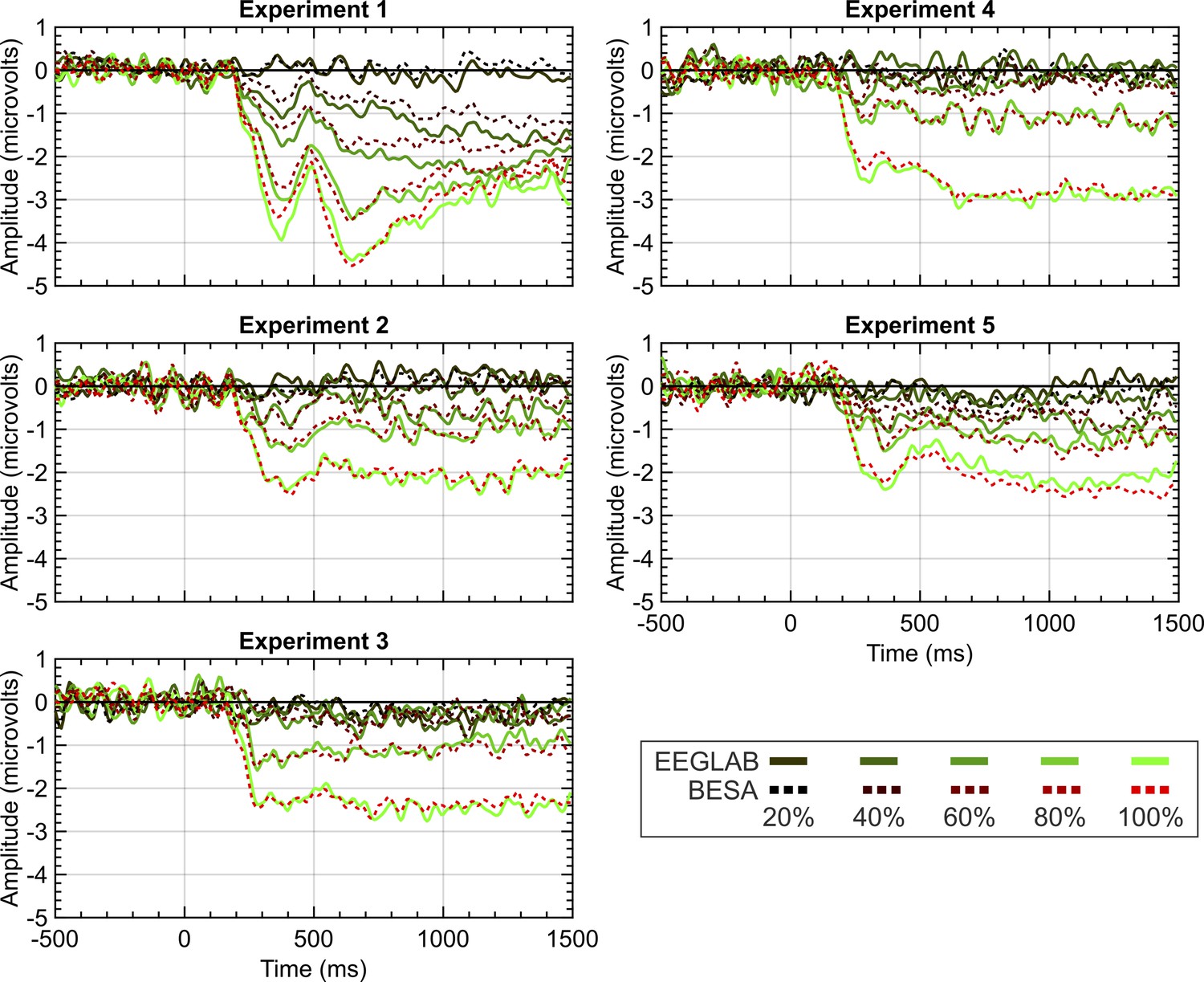
EEGLAB and BESA pipeline comparison.
Panels show SPN waves for each of the 5 experiments in project 13. EEGLAB waves are the solid lines; the BESA waves are the dashed lines. 20%–100% refers to the proportion of symmetry in the stimulus (see Figure 1 for example stimuli).
We conclude that post-hoc selection of electrodes and time windows are weak points that can be exploited by unscrupulous P-hackers. Earlier points in the pipeline are less susceptible to P-hacking because changing them does not predictably increase or decrease the desired ERP effect.
Summary for horseman three: P-hacking
It is easier to publish a simple story with a beautiful procession of significant effects. This stark reality may have swayed our practice in subtle ways. However, our assessment is that P-hacking is not a pervasive problem in SPN research, although some effects rely too heavily on post hoc data selection.
Reassuringly, we found most effects could be recreated with a variety of justifiable analysis pipelines: Data-driven and a priori approaches gave similar results, as did different EEGLAB and BESA pipelines. This was not a foregone conclusion – related analysis in fMRI has revealed troubling inconsistencies (Lindquist, 2020; Botvinik-Nezer et al., 2020). It is advisable that all researchers compare multiple analysis pipelines to assess vibration of effects and calibrate their confidence accordingly.
Horseman four: HARKing
Hypothesizing After Results Known or HARKing (Kerr, 1998; Rubin, 2017), is a potential problem in EEG research. Specifically, it is possible to conduct an exploratory analysis, find something unexpected, then describe the results as if they were predicted a priori. At worst, a combination of P-hacking and HARKing can turn noise into theory, which is then cited in the literature for decades. Even without overt HARKing, one can beautify an introduction section after the results are known, so that papers present a simple narrative (maybe this post hoc beautification could be called BARKing). Unlike the other horses, HARKing and BARKing are difficult to diagnose with reanalysis, which is why this section is shorter than the previous sections.
The main tool to fight HARKing is online pre-registration of hypotheses (for example, on aspredicted.org or osf.io). We have started using pre-registration routinely in the last four years, but we could have done so earlier. An even stricter approach is to use registered reports, where the introductions and methods are peer reviewed before data collection. This can abolish both HARKing and BARKing (Chambers, 2013; Munafò et al., 2017), but we have only just started with this. Our recommendation is to use heavy pre-registration to combat HARKing. Perhaps unregistered EEG experiments will be considered unpublishable in the not-too-distant future.
Discussion
One of the most worrisome aspects of the replication crisis is that problems might be systemic, and not caused by a few corrupt individuals. It seems that the average researcher publishes somewhat biased research, without sufficient self-awareness. So, what did we find when we looked at our own research?
As regards publication bias – the first horseman of irreproducibility – we found that the 115 published SPNs were slightly stronger than the 134 unpublished ones. However, we are confident that there is no strong file drawer problem here. Even the unpublished SPNs are in the right direction (regular < random not random < regular). Furthermore, a complete SPN catalogue itself fights the consequences of publication bias by placing everything that was in the file drawer into the public domain.
We are more troubled by the second horseman: low statistical power. Our most negative conclusion is that reliable SPN research programs require larger samples than those we typically obtain (38 participants are required to reliably measure –0.5 microvolt SPNs and our median sample size is 24). This analysis has lessons for all researchers: It is evidently possible to ‘get by’ while routinely conducting underpowered experiments. One never notices a glaring problem: after all, underpowered research will often yield a lucky experiment with significant results, and this may support a new publication before moving on to the next topic. However, this common practice is not a strong foundation for cumulative research.
The costs of underpowered research might be masked by the third horseman: P-hacking. Researchers often exploit flexibility in the analysis pipeline to make borderline effects appear significant (Simmons et al., 2011). In EEG research, this often involves post-hoc selection of electrodes and time windows. Although some post-hoc adjustment is arguably appropriate, this double dipping certainly inflates false positive rate and requires scrutiny. We found that the same basic story would have emerged if we had rigidly used the same a priori electrode clusters in all projects or used a spatio-temporal clustering algorithm for selection. However, some of our SPN modulations were not so robust, and we have relied on post hoc time windows.
The fourth horseman, HARKing, is the most difficult dimension to evaluate because it cannot be diagnosed with reanalysis. Nevertheless, pre-registration is the best anti-HARKing tool, and we could have engaged with this earlier. We are just beginning with pre-registered reports.
To summarize these evaluations, we would tentatively self-award a grade of A- for publication bias (75%, or lower first class, in the UK system), C+ for statistical power (58%), B+ for P-Hacking (68%), and B for Harking (65%). While some readers may not be interested in the validity of SPN research per se, they may be interested in this meta-scientific exercise, and we would encourage other groups to perform similar exercises on their own data. In fact, such exercises may be essential for cumulative science. It has been argued that research should be auditable (Nelson et al., 2018), but Researcher A will rarely be motivated to audit a repository uploaded by Researcher B, even if the datasets are FAIR. To fight the replication crisis, we must actively look in the mirror, not just passively let others snoop through the window.
Klapwijk et al., 2021 have performed a similar meta-scientific evaluation in the field of developmental neuroimaging and made many practical recommendations. All our themes are evident in their article. We also draw attention to international efforts to estimate the replicability of influential EEG experiments (Pavlov et al., 2020). These mass replication projects provide a broad overview. Here we provide depth, by examining all the data and practices from one representative EEG lab. We see these approaches as complementary: they both provide insight into whether a field is working in a way that generates meaningful results.
The focus on a single lab inevitably introduces some biases and limitations. Other labs may use different EEG apparatus with more channels. This would inevitably have some effect on the recordings. More subtle differences may also matter: For instance, other labs may use more practice trials or put more stress on the importance of blink suppression. However, the heterogeneity of studies and pipelines explored here ensures reasonable generalizability. We are confident that our conclusions are relevant for SPN researchers with different apparatus and conventions.
Curated databases are an extremely valuable resource, even if they are not used for meta-scientific evaluation. Public catalogues are an example of large-scale neuroscience, the benefits of which have been summarized by the neuroscientist Jeremy Freeman as follows: “Understanding the brain has always been a shared endeavour. But thus far, most efforts have remained individuated: labs pursuing independent research goals, slowly disseminating information via journal publications, and when analyzing their data, repeatedly reinventing the wheel” (Freeman, 2015). We tried to make some headway here with the SPN catalogue.
Perhaps future researchers will see their role as akin to expert museum curators, who oversee and update their public catalogues. They will obsessively tidy and perfect the analysis scripts, databases and metafiles. They will add new project folders every year, and judiciously determine when previous theories are no longer tenable. Of course, many researchers already dump raw data in online repositories, but this is not so useful. Instead, we need FAIR archives which are actively maintained, organized, and promoted by curators. The development of software, tools and shared repositories within the open science movement is making this feasible for most labs. We are grateful to everyone who is contributing to this enterprise.
It took more than a year to find all the SPN data, organize it, reformat it, produce uniform scripts, conduct rigorous double checks, and upload material to public databases. However, we anticipate that it will save far more than a year in terms of improved research efficiency. It is also satisfying that unpublished data sets are not merely lost. Instead, they are now contributing to more reliable estimates of SPN effect size and power. It is unlikely that any alternative activity could have been more beneficial for SPN research.
Data availability
All data that supports analysis and Figures, along with codes for analysis, are available on open science framework (https://osf.io/2sncj/). To make it possible for anybody to analyze our data, we developed an app that allows users to: (i) view the data and summary statistics as they were originally published; (ii) select data subsets, electrode clusters, and time windows; (iii) visualize the patterns; (iv) export data for further statistical analysis. This repository and app will be expanded to accommodate data from future projects. The app is available to download for Windows users at https://github.com/JohnTyCa/The-SPN-Catalogue (copy archived at swh:1:rev:75e729f867c275433b68807bc3f2228c57a3ccac).
References
-
When power analyses based on pilot data are biased: Inaccurate effect size estimators and follow-up biasJournal of Experimental Social Psychology 74:187–195.https://doi.org/10.1016/j.jesp.2017.09.004
-
The neural basis of visual symmetry and its role in mid- and high-level visual processingAnnals of the New York Academy of Sciences.https://doi.org/10.1111/nyas.13667
-
Power failure: Why small sample size undermines the reliability of neuroscienceNature Reviews. Neuroscience 14:365–376.https://doi.org/10.1038/nrn3475
-
The neural basis of mirror symmetry detection: A reviewJournal of Cognitive Psychology 29:259–268.https://doi.org/10.1080/20445911.2016.1271804
-
Face configuration processing in the human brain: the role of symmetryCerebral Cortex 17:1423–1432.https://doi.org/10.1093/cercor/bhl054
-
How do scientific views change? Notes from an extended adversarial collaborationPerspectives on Psychological Science 15:1011–1025.https://doi.org/10.1177/1745691620906415
-
Generalization and the evolution of symmetry preferencesProceedings of the Royal Society of London. Series B 264:1345–1348.https://doi.org/10.1098/rspb.1997.0186
-
Questionable research practices revisitedSocial Psychological and Personality Science 7:45–52.https://doi.org/10.1177/1948550615612150
-
Open source tools for large-scale neuroscienceCurrent Opinion in Neurobiology 32:156–163.https://doi.org/10.1016/j.conb.2015.04.002
-
Darwinian aesthetics: Sexual selection and the biology of beautyBiological Reviews of the Cambridge Philosophical Society 78:385–407.https://doi.org/10.1017/s1464793102006085
-
Electrophysiological indices of processing aesthetics: Spontaneous or intentional processes?International Journal of Psychophysiology 65:20–31.https://doi.org/10.1016/j.ijpsycho.2007.02.007
-
Descriptive and evaluative judgment processes: Behavioral and electrophysiological indices of processing symmetry and aestheticsCognitive, Affective & Behavioral Neuroscience 3:289–299.https://doi.org/10.3758/cabn.3.4.289
-
HARKing: hypothesizing after the results are knownPersonality and Social Psychology Review 2:196–217.https://doi.org/10.1207/s15327957pspr0203_4
-
Opportunities for increased reproducibility and replicability of developmental neuroimagingDevelopmental Cognitive Neuroscience 47:100902.https://doi.org/10.1016/j.dcn.2020.100902
-
Representation of maximally regular textures in human visual cortexThe Journal of Neuroscience 36:714–729.https://doi.org/10.1523/JNEUROSCI.2962-15.2016
-
The human visual system preserves the hierarchy of two-dimensional pattern regularityProceedings. Biological Sciences 288:20211142.https://doi.org/10.1098/rspb.2021.1142
-
Circular analysis in systems neuroscience: the dangers of double dippingNature Neuroscience 12:535–540.https://doi.org/10.1038/nn.2303
-
Conditions for view invariance in the neural response to visual symmetryPsychophysiology 52:532–543.https://doi.org/10.1111/psyp.12365
-
An electrophysiological index of perceptual goodnessCerebral Cortex 26:4416–4434.https://doi.org/10.1093/cercor/bhw255
-
Symmetric patterns with different luminance polarity (anti-symmetry) generate an automatic response in extrastriate cortexThe European Journal of Neuroscience 51:922–936.https://doi.org/10.1111/ejn.14579
-
The formation of symmetrical gestalts is task-independent, but can be enhanced by active regularity discriminationJournal of Cognitive Neuroscience 32:353–366.https://doi.org/10.1162/jocn_a_01485
-
Nonparametric statistical testing of EEG- and MEG-dataJournal of Neuroscience Methods 164:177–190.https://doi.org/10.1016/j.jneumeth.2007.03.024
-
Symmetry perception for patterns defined by color and luminanceJournal of Vision 18:1–24.https://doi.org/10.1167/18.8.4
-
A manifesto for reproducible scienceNature Human Behaviour 1:0021.https://doi.org/10.1038/s41562-016-0021
-
Psychology’s renaissanceAnnual Review of Psychology 69:511–534.https://doi.org/10.1146/annurev-psych-122216-011836
-
Temporal dynamics of the human response to symmetryJournal of Vision 2:132–139.https://doi.org/10.1167/2.2.1
-
VEPs elicited by local correlations and global symmetryVision Research 47:2212–2222.https://doi.org/10.1016/j.visres.2007.03.020
-
When does HARKing hurt? Identifying when different types of undisclosed post hoc hypothesizing harm scientific progressReview of General Psychology 21:308–320.https://doi.org/10.1037/gpr0000128
-
Empirical aspects of symmetry perceptionSpatial Vision 9:1–7.https://doi.org/10.1163/156856895x00089
-
SoftwareThe-SPN-Catalogue, version swh:1:rev:75e729f867c275433b68807bc3f2228c57a3ccacSoftware Heritage.
-
Goodness of visual regularities: A non-transformational approachPsychological Review 103:429–456.https://doi.org/10.1037/0033-295x.103.3.429
-
A century of Gestalt psychology in visual perception: I. Perceptual grouping and figure-ground organizationPsychological Bulletin 138:1172–1217.https://doi.org/10.1037/a0029333
Decision letter
-
Peter RodgersSenior and Reviewing Editor; eLife, United Kingdom
In the interests of transparency, eLife publishes the most substantive revision requests and the accompanying author responses.
Decision letter after peer review:
Thank you for submitting your article "Meta-Research: Lessons from a catalogue of 6674 brain recordings" to eLife for consideration as a Feature Article. Your article has been reviewed by three peer reviewers, and the evaluation has been overseen by the eLife Features Editor (Peter Rodgers). The following individuals involved in review of your submission have agreed to reveal their identity: Peter Kohler (Reviewer #1); Cyril Pernet (Reviewer #3).
The reviewers and editor have discussed the reviews and drafted this decision letter to help you prepare a revised submission. While the reviewers were largely positive about your manuscript, there are quite a few important points that need to be addressed to make the article suitable for publication.
Summary
This manuscript comes from a group in Liverpool who for the last decade have used event-related electroencephalography (EEG) to measure a brain response known as the sustained posterior negativity (SPN). The SPN provides a readout of processing of symmetry and other types of visual regularity. The goal of the current paper is not to offer new information about the role of symmetry in visual perception, but rather to provide a meta-analysis of scientific practice based on the thousands of studies, published and unpublished, accumulated by the authors over the years. The authors use this rare dataset to evaluate their own performance on four key concerns that are known to lead to irreproducible results. The conclusions the authors make about their own scientific practice are largely supported by the data, and the findings offer some recommendations on how to best measure the SPN in future studies. The authors succeed in providing an even-handed estimate of the reproducibility of their research over the last 10 years but are less successful in generalizing their conclusions.
The main strength of the manuscript is the data set, which contains every SPN study ever recorded at the University of Liverpool – more than 6000 recordings of the SPN from more than 2000 participants. The authors have obviously put substantial effort into cleaning up and organizing the data and have made the dataset publicly available along with analysis tools. As such, the data represents a herculean exercise in data sharing and open science and should inspire EEG researchers who are interested in following best practices in those domains. Another strength of the paper are the analyses of publication bias and statistical power, which are quite well-done and fairly unique, at least for EEG research.
The dataset clearly has value in itself, but the potential broader interest of the manuscript depends critically on what the authors do with the data and to what extent their findings can provide general recommendations. The main weakness is that the findings are fairly specific to the measurement modality and brain response (SPN) measured by the authors. In my reading there is generally little attempt to relate the conclusions to other event-related EEG signals, much less to other EEG approaches or other measurement modalities. The sections on Publication Bias and Low Statistical Power are arguably inherently difficult to generalize beyond the SPN. The section on P-hacking, however, is directly limited in impact by analyses that are either very simplistic or missing entirely. The electrode choice section attempts to evaluate the impact of that particular approach to dimensionality reduction, but that is only one of many approaches regularly used in EEG research. The authors discuss that the selection of time window is an important parameter that can influence the results, but there is no actual analysis of the effect of time window selection across the many studies in the dataset. Finally, the analysis of the effect of pre-processing in the same section is also fairly limited in impact, because only one experiment is reanalysed, rather than the whole dataset.
In conclusion, the manuscript will clearly be of interest for the relatively narrow range of researchers who study the SPN using event-related EEG. In addition, the dataset will serve as a useful example of large-scale curated sharing of EEG data. Beyond that, I think the impact and utility of the manuscript in its current from will be relatively limited.
Essential Revisions
1 Data sharing
We encourage the authors to make their data available in a way that is FAIR. As it stands the data are Findable and Accessible, but not much Interoperable or Reusable. For example, using BIDS elecrophysiological derivatives and given the authors experience with EEGLAB, they could use the.set format along with a flat structure and proper metadata (particiants.tsv, data_description.json, channels.tsv, electrodes.tsv, etc.) For more detail, see: https://docs.google.com/document/d/1PmcVs7vg7Th-cGC-UrX8rAhKUHIzOI-uIOh69_mvdlw/edit; Pernet et al., 2019; bids.neuroimaging.io.
Many of these can be done using matlab tools to generate data (https://github.com/bids-standard/bids-starter-kit and https://github.com/sccn/bids-matlab-tools).
https://github.com/bids-standard/bids-matlab could be used to make analysis scripts more general.
Do reach out to the BIDS community and/or myself [Cyril Pernet] if you need help.
A classification of experiments could also be useful (using, say, the cognitive atlas ontology [https://www.cognitiveatlas.org/]).
2 Introduction
a) The introduction needs to better explain the SPN – how it is generated, what it is suppose to reflect/measure, how the potential is summarized in a single mean, etc.
b) Please add a paragraph at the end of the introduction telling readers more about the data, how they can get access to them, how they can reproduce your analyses, and what else it is possible to do with the data.
3 Figures
a) Related to the previous point, figures 1-3 are of limited usefulness to the reader. Please replace them with a single figure that includes a small number of illustrative SPN waves and a small number of illustrative topographic difference maps to clarify the explanation of the SPN (see previous point). Please include no more than four panels in reach row of the figure, and please ensure that the caption for the new figure 1 adequately explains all the panels in the figure.
b) The present figure 1 can then become Figure 1—figure supplement 1, and likewise for the present figures 2 and 3.
c) Please consider grouping the panels within each of these three figure supplements according to, say, a cognitive atlas ontology [https://www.cognitiveatlas.org/] (or similar).
d) Also, for the difference maps, please consider avoiding jet and using instead a linear luminance scale (eg, https://github.com/CPernet/brain_colours).
e) Figure 4b. Please delete the bar graph in the inset and give the three mean values (and confidence intervals) in the figure caption.
f) Figure 6. Please delete the bar graph (panel C) and give the four mean values (and confidence intervals) in the figure caption.
4 More complete reporting
a) Please include a table (as a Supplementary file) that provides information about the electrodes and time windows used in each of the studies. If the electrodes and/or time windows varied across the SPN waves within a study, please explain why.
b) Along similar lines, what stimulus types and tasks were used for what fraction of the SPNs in the dataset? SPNs can be measured for many types of regularity and varies with both stimulus parameters and task (as noted by the authors). This means that the SPN varies across studies not just by neural noise and measurement noise, but also by differences in neural signal. This is not necessarily a weakness of the analyses reported here, but it should be noted, so please include a table (as a Supplementary file) that provides information about the stimulus types and tasks used in the studies.
5 Further analyses
a) The Electrode Choice analysis estimates the effect of a priori selection of electrode ROIs, by comparing three such ROIs, each a smaller subset of the other. Perhaps not surprisingly the responses are highly correlated, and the overall effects change little. I would recommend considering more data-driven approaches to spatial filtering and dimensionality reduction. There are many such approaches, but two that come to mind are reliable components analysis (Dmochowski et al., 2012; Dmochowski et al., 2014; Dmochowski and Norcia, 2015) and non-parametric spatiotemporal clustering (Maris and Oostenveld, 2007). It would be interesting to see if approaches such as these would produce different effect sizes or identified a different set of electrodes across the many studies in the dataset. This could also serve as an assessment of the ability of these methods to identify the same spatial filters / clusters of electrodes across a large dataset. Given that these methods are widely used in the EEG/MEG-community, this would considerably enhance the impact of the manuscript. The spatiotemporal approach could also help address the time window selection issue, as outlined in my next point.
b) The authors acknowledge that the selection of time window is an important parameter that can influence the results, but do not include any analysis of this. Please include an analysis of the effect of time window selection across the many datasets. Also, please comment on how it is possible to measure and separate early and late effects using event-related EEG.
c) The analysis of the effect of pre-processing is also of potential broad interest to researchers doing EEG, but it is limited in impact, because only one study is re-analyzed. I understand that it may be impractical to re-analyze every study in the dataset 12 different ways, but re-analyzing a single dataset seems to have limited utility in the context of the current manuscript. Please either extend this analysis or remove it from the manuscript.
d) Re pre-processing pipelines, please consider discussing some of the recommendations in Pernet et al. [doi.org/10.1038/s41593-020-00709-0]
6 Limitations associated with using data from just one group.
The overall approach to the cumulative research program and the specific suggestions to reduce the experimental bias and improve researchers' self-awareness is indeed helpful but in line with the previously known findings on reproducibility limitations. Furthermore, a re-analysis, which specifically relies on single site single group acquisitions, poses additional issues or specific bias (e.g., data acquisition, methodology, experimental design, data pre-processing, etc.) to the generalizability of the results that the authors should have considered. A comparison with an independent sample of data would make the analysis less autoreferential and methodologically stronger. If possible, please include a comparison with an independent sample of data: if such a comparison is not possible, please discuss the limitations and potential biases associated with using data from just one group.
7 Awarding grades
The authors grading their work does not bring anything to our understanding of reproducibility; please remove.
8 Advice for other researchers
The manuscript currently has a strong focus on SPN research and in places almost reads like a 10-year report on scientific practice within a specific research group. This is undoubtedly valuable, but of limited general interest. So, I hope the authors will forgive an open-ended suggestion. Namely that they carefully consider the ways in which their findings might be valuable to researchers outside their own sphere of interest. I have suggested a few ways above, but perhaps the authors can think of others. What recommendations would the authors make to scientists working in other domains of brain imaging, based on the findings?
9 Publication bias
a) Line 145. "A meta-analysis based on the published SPNs along would overestimate...". It is essential that you perform such a meta-analysis. What you have done is compare the means computed from all vs. published, but not set-up a meta-analysis in which the mean is estimated from the means and variances of published studies alone (I suggest dmetar which is super easy to use even if you never used R / R-studio before; https://bookdown.org/MathiasHarrer/Doing_Meta_Analysis_in_R/). That extra analysis will be very useful because, people do not have access to the data to compute the mean and thus use this meta-analytical approach (how much this will differ from -1.17uV?; in theory it should bring the results closer to -0.94uV)
10 Low statistical power
– Power analysis: You need to explain better the analysis. It is also essential that you demonstrate that a 2nd order polynomial fits better than a 1st order using AIC and RMSE. A second aspect is that you cannot predict effect size from amplitude because the polynome you have was obtained for the entire dataset. This is a typical machine learning regression setting: you need to cross-validate to produce an equation than generalizes -- given the goal is to generalize across experiments, a natural cross validation scheme would be the experimental belonging (fit all data but one experiment, test – iterate to optimize parameters).
– Nonlinearity: to further look into that question you need the complementary plot Cohens'd vs. variance (or 3d plot d, variance, amplitude but sometimes it's hard to see). Given that d = mean/std, the nonlinearity arises because there is a 'spot' where variance behave strangely (likely for the midrange amplitude values). This also relates to your discussion on the number of trials because the number of trials increases precision and in principle reduce between subject variance; depending on expected amplitude the number of trials should therefore be adjusted to reduce variance bias.
11 Miscellaneous
a) Please provide links to the code for the analysis presented in the paper.
b) Please consider making the data-viewing app agnostic wrt operating system.
c) Re the headline effects reported in figure 5: the explanation of these effects in the in the repository needs to be more detailed.
d) Line 148. Please say more about the reasons why 68 SPNs "will likely in the file drawer forever".
e) Line 191 onwards. When talking about pilot studies please add references (for instance Lakens (doi.org/10.1016/j.jesp.2017.09.004). Also, please consider discussing the smallest effect size of interest instead of absolute effect size.
https://doi.org/10.7554/eLife.66388.sa1Author response
Essential Revisions
1 Data sharing
We encourage the authors to make their data available in a way that is FAIR. As it stands the data are Findable and Accessible, but not much Interoperable or Reusable. For example, using BIDS elecrophysiological derivatives and given the authors experience with EEGLAB, they could use the.set format along with a flat structure and proper metadata (particiants.tsv, data_description.json, channels.tsv, electrodes.tsv, etc.) For more detail, see: https://docs.google.com/document/d/1PmcVs7vg7Th-cGC-UrX8rAhKUHIzOI-uIOh69_mvdlw/edit; Pernet et al., 2019; bids.neuroimaging.io.
Many of these can be done using matlab tools to generate data (https://github.com/bids-standard/bids-starter-kit and https://github.com/sccn/bids-matlab-tools).
https://github.com/bids-standard/bids-matlab could be used to make analysis scripts more general.
Do reach out to the BIDS community and/or myself [Cyril Pernet] if you need help.
A classification of experiments could also be useful (using, say, the cognitive atlas ontology [https://www.cognitiveatlas.org/]).
We have expanded our catalogue and supporting materials, and made the data as Finable, Accessible, Interoperable and Reusable (FAIR) as possible. As recommended, we have produced BIDS files for each of the 40 projects and included raw data as well as processed data (see Complete Catalogue-BIDS format, https://osf.io/e8r95/). We have now explained this in a new section after the introduction entitled “The complete Liverpool SPN catalogue”. One part reads:
“The SPN catalogue on OSF (https://osf.io/2sncj/) is designed to meet the FAIR standards (Findable, Accessible, Interoperable and Reusable). […] They can also run alternative analyses that depart from the original pipeline at any given stage.”
With all available raw data, the catalogue is now over 900 GB (up from the original 5 GB). This massively increases future possible uses of the catalogue. For instance, one could reanalyse the raw data using an alternative pipeline or run Time-Frequency analysis on cleaned data.
2 Introduction
a) The introduction needs to better explain the SPN – how it is generated, what it is suppose to reflect/measure, how the potential is summarized in a single mean, etc.
We had already included some basics on the SPN and SPN catalogue in BOX 1. We have now provided more in the main manuscript. Furthermore, we have produced an ‘SPN gallery’, with one page for each of the 249 SPNs (This is available on OSF in the SPN analysis and guidebooks folder). The SPN gallery provides all information for anyone who wishes to see how a particular SPN was processed. The new section explains:
“On open science framework (https://osf.io/2sncj/) we provide several supplementary files, including one called ‘SPN gallery’ (see SPN analysis and guidebooks folder). […] Key mapping was usually shown only on the response screen, to avoid anticipation of a motor response.”
b) Please add a paragraph at the end of the introduction telling readers more about the data, how they can get access to them, how they can reproduce your analyses, and what else it is possible to do with the data.
We have now clarified this in a new section (see point 1). We have also elaborated on other things that researchers can do with the data:
“Although this paper focuses on meta-science, we can briefly summarize the scientific utility of the catalogue. […] The SPN catalogue also allows meta-analysis of other ERPs, such as P1 or N1, which may be systematically influenced by stimulus properties (although apparently not W-load).”
3 Figures
a) Related to the previous point, figures 1-3 are of limited usefulness to the reader. Please replace them with a single figure that includes a small number of illustrative SPN waves and a small number of illustrative topographic difference maps to clarify the explanation of the SPN (see previous point). Please include no more than four panels in reach row of the figure, and please ensure that the caption for the new figure 1 adequately explains all the panels in the figure.
b) The present figure 1 can then become Figure 1—figure supplement 1, and likewise for the present figures 2 and 3.
c) Please consider grouping the panels within each of these three figure supplements according to, say, a cognitive atlas ontology [https://www.cognitiveatlas.org/] (or similar).
We agree that these figures were of limited use, and we have replaced them with one representative Figure 1. Importantly, Figure 1 is a sample from the ‘SPN gallery’ on OSF, which has one such page for each of the 249 SPNs. The SPN gallery gives all information about stimuli and details of each experiment – and is thus far more informative than the original illustrative figures in the paper.
d) Also, for the difference maps, please consider avoiding jet and using instead a linear luminance scale (eg, https://github.com/CPernet/brain_colours).
Using the code provided, we obtained the luminance corrected scale and applied it to all topoplots in the SPN gallery and in the manuscript.
e) Figure 4b. Please delete the bar graph in the inset and give the three mean values (and confidence intervals) in the figure caption.
Figure 4 is now Figure 2 in the revised manuscript. We have deleted the bar graph and added a funnel plot of results from the new meta-analysis. The three mean values are now incorporated in text about meta-analysis. We feel these would not work in the caption now that the section has been expanded (see point 9 for new section on meta-analysis with Figure and caption).
f) Figure 6. Please delete the bar graph (panel C) and give the four mean values (and confidence intervals) in the figure caption.
Figure 6 is now Figure 4 in the revised manuscript (note also revised topoplot):
Again, we feel the text is a better place for the means than the Figure caption:
“Average SPN amplitude was -0.98 microvolts [95%CI = -0.88 to -1.08] with the original cluster, -0.961 [-0.87, -1.05] microvolts for cluster 1, -1.12 [-1.01, -1.22] microvolts for cluster 2, -0.61 [-0.55, -0.66] microvolts for cluster 3.”
4 More complete reporting
a) Please include a table (as a Supplementary file) that provides information about the electrodes and time windows used in each of the studies. If the electrodes and/or time windows varied across the SPN waves within a study, please explain why.
On OSF we had already included a supplementary database of all electrodes and time windows used in each study (SPN effect size and power.xlsx). This is now referenced more prominently (see also point 1):
“We have enhanced reusability with several Supplementary files on OSF (see SPN analysis and guidebooks folder). These give all the technical details required for reproducible EEG research, as provided by OHBM COBIDAS MEEG committee in the Organization for Human Brain Mapping (Pernet et al., 2020). For instance, the file ‘SPN effect size and power V8.xlsx’ has one worksheet for each project. This file documents all extracted ERP data along with details about the electrodes, time windows, ICA components removed, and trials removed.”
The new SPN gallery also provides more information about electrodes and time windows, along with uniform visualizations of all 249 SPNs.
Electrodes and time windows did vary between studies, as discussed at length in the p-hacking section. However, they did not vary between SPN waves within an experiment. We do not think it would be feasible to work through all between-experiment inconsistencies on a case-by-case basis in the manuscript.
b) Along similar lines, what stimulus types and tasks were used for what fraction of the SPNs in the dataset? SPNs can be measured for many types of regularity and varies with both stimulus parameters and task (as noted by the authors). This means that the SPN varies across studies not just by neural noise and measurement noise, but also by differences in neural signal. This is not necessarily a weakness of the analyses reported here, but it should be noted, so please include a table (as a Supplementary file) that provides information about the stimulus types and tasks used in the studies.
The new SPN gallery provides all details about stimuli and tasks used for each of the 249 SPNs. We have also added this summary in the manuscript:
“On open science framework (https://osf.io/2sncj/) we provide several supplementary files, including one called ‘SPN gallery’ (see SPN analysis and guidebooks folder). […] Key mapping was usually shown only on the response screen, to avoid anticipation of a motor response.”
We now elaborate the point about signal and noise in the section on publication bias:
“In other words, the SPN varies across studies not only due to neural noise and measurement noise, but also due to experimental manipulations affecting the neural signal (although W-load and Task were similar in unpublished work).”
Finally, the new meta-analysis covers this point about study heterogeneity much more explicitly (see point 9).
5 Further analyses
a) The Electrode Choice analysis estimates the effect of a priori selection of electrode ROIs, by comparing three such ROIs, each a smaller subset of the other. Perhaps not surprisingly the responses are highly correlated, and the overall effects change little. I would recommend considering more data-driven approaches to spatial filtering and dimensionality reduction. There are many such approaches, but two that come to mind are reliable components analysis (Dmochowski et al., 2012; Dmochowski et al., 2014; Dmochowski and Norcia, 2015) and non-parametric spatiotemporal clustering (Maris and Oostenveld, 2007). It would be interesting to see if approaches such as these would produce different effect sizes or identified a different set of electrodes across the many studies in the dataset. This could also serve as an assessment of the ability of these methods to identify the same spatial filters / clusters of electrodes across a large dataset. Given that these methods are widely used in the EEG/MEG-community, this would considerably enhance the impact of the manuscript. The spatiotemporal approach could also help address the time window selection issue, as outlined in my next point.
b) The authors acknowledge that the selection of time window is an important parameter that can influence the results, but do not include any analysis of this. Please include an analysis of the effect of time window selection across the many datasets. Also, please comment on how it is possible to measure and separate early and late effects using event-related EEG.
A and B are interesting points, and we treat them together. One problem with our original analysis in the P-hacking section was that it conflated space and time – inter-cluster correlations were less than 1, but we could not determine the extent to which variability in electrode cluster and time window were responsible for the imperfect correlation. We have now removed this problem by redoing our analysis of a priori electrode clusters on consistent time windows (results are in what is now Figure 4).
Following this, our new spatio-temporal clustering analysis addresses issues with space and time together. Crucially, we found that this data-driven approach homed in on the same clusters and time windows as our a priori posterior electrode choice. There were no surprising symmetry related responses at frontal electrodes or at unexpected time points. The new section in the manuscript reads:
“Spatio-temporal clustering
The above analysis examines consequences of choosing different electrode clusters a priori, while holding time window constant. […] There was a strong correlation between this and SPN from each a priori cluster (Pearson’s r ranged from 0.719 to 0.746, p <.001, Figure 7).”
c) The analysis of the effect of pre-processing is also of potential broad interest to researchers doing EEG, but it is limited in impact, because only one study is re-analyzed. I understand that it may be impractical to re-analyze every study in the dataset 12 different ways, but re-analyzing a single dataset seems to have limited utility in the context of the current manuscript. Please either extend this analysis or remove it from the manuscript.
We agree this section was of limited value in the previous version. We elected to replace it with something far more ambitious rather than removing it. After all, pipeline comparison is a pertinent topic for all neuroscience researchers. We thus reanalysed all of the 5 experiments (from project 13) using BESA, and our familiar EEGLAB and Matlab. In BESA there was no ICA cleaning, and low pass filters were different. As we can see in the new Figure 8, the waves are similar. This increases confidence that our SPNs are not overly altered by conventions in the pre-processing pipeline. The following paragraph has been added to the manuscript to describe the two different pipelines:
“Pre-processing pipelines
There are many pre-processing stages in EEG analysis (Pernet et al., 2020). For example, our data is re-referenced to a scalp average, low pass filtered at 25Hz, downsampled to 128 Hz and baseline corrected using a -200 to 0 ms pre-stimulus interval. [..] Earlier analysis stages are less susceptible to P Hacking because changing them does not predictably increase or decrease the desired ERP effect.”
In sum, we can demonstrate convergence between results obtained with different pipelines. This was not a foregone conclusion: Neuroimaging results can vary greatly when pipelines and software are used on the same raw data. We have now made this point in the manuscript:
“Reassuringly, we found most effects could be recreated with a variety of justifiable analysis pipelines. Data-driven and a priori approaches gave similar results, and different EEGLAB and BESA pipelines gave similar results. This was not a foregone conclusion – related analysis in fMRI has revealed troubling inconsistencies (Lindquist, 2020). It is advisable that all researchers compare multiple analysis pipelines to assess vibration of effects and calibrate their confidence accordingly.”
d) Re pre-processing pipelines, please consider discussing some of the recommendations in Pernet et al. [doi.org/10.1038/s41593-020-00709-0]
We have now cited this paper as an authoritative source of advice EEG pipelines:
“We have enhanced reusability with several Supplementary files on OSF (see SPN analysis and guidebooks folder). These give all the technical details required for reproducible EEG research, as provided by OHBM COBIDAS MEEG committee in the Organization for Human Brain Mapping (Pernet et al., 2020). For instance, the file ‘SPN effect size and power V8.xlsx’ has one worksheet for each project. This file documents all extracted ERP data along with details about the electrodes, time windows, ICA components removed, and trials removed.”
More significantly, we have followed some these recommendations when expanding the catalogue and upgrading supplementary material. For instance, we have added 95% CI around all SPNs in the SPN gallery and in Box 1.
6 Limitations associated with using data from just one group.
The overall approach to the cumulative research program and the specific suggestions to reduce the experimental bias and improve researchers' self-awareness is indeed helpful but in line with the previously known findings on reproducibility limitations. Furthermore, a re-analysis, which specifically relies on single site single group acquisitions, poses additional issues or specific bias (e.g., data acquisition, methodology, experimental design, data pre-processing, etc.) to the generalizability of the results that the authors should have considered. A comparison with an independent sample of data would make the analysis less autoreferential and methodologically stronger. If possible, please include a comparison with an independent sample of data: if such a comparison is not possible, please discuss the limitations and potential biases associated with using data from just one group.
We have now mentioned this limitation in the new section on the SPN catalogue:
“SPNs from other labs are not yet included in the catalogue (Höfel and Jacobsen, 2007a, 2007b; Jacobsen, Klein, and Löw, 2018; Martinovic, Jennings, Makin, Bertamini, and Angelescu, 2018; Wright, Mitchell, Dering, and Gheorghiu, 2018). Steady state visual evoked potential responses to symmetry are also unavailable (Kohler, Clarke, Yakovleva, Liu, and Norcia, 2016; Kohler and Clarke, 2021; Norcia, Candy, Pettet, Vildavski, and Tyler, 2002; Oka, Victor, Conte, and Yanagida, 2007). However, the intention is to keep the catalogue open, and the design allows many contributions. In the future we hope to integrate data from other labs. This will increase the generalizability of our conclusions.”
And in the discussion
“The focus on a single lab inevitably introduces some biases and limitations. Other labs may use different EEG apparatus with more channels. This would inevitably have some effect on the recordings. More subtle differences may also matter: For instance, other labs may use more practice trials or put more stress on the importance of blink suppression. However, the heterogeneity of studies and pipelines explored here ensures reasonable generalizability. We are confident that our conclusions are relevant for SPN researchers with different apparatus and conventions.”
7 Awarding grades
The authors grading their work does not bring anything to our understanding of reproducibility; please remove.
We have removed this and instead included more advice for other researchers, as described next.
8 Advice for other researchers
The manuscript currently has a strong focus on SPN research and in places almost reads like a 10-year report on scientific practice within a specific research group. This is undoubtedly valuable, but of limited general interest. So, I hope the authors will forgive an open-ended suggestion. Namely that they carefully consider the ways in which their findings might be valuable to researchers outside their own sphere of interest. I have suggested a few ways above, but perhaps the authors can think of others. What recommendations would the authors make to scientists working in other domains of brain imaging, based on the findings?
We feel this is perhaps the most substantial criticism. We have addressed it in two ways. First, at the end of each section, we have replaced the auto-referential grades with a one paragraph recommendation for other researchers.
At the end of Publication bias:
“Some theoretically important effects can appear robust in meta-analysis of published studies, but then disappear once the file drawer studies are incorporated. Fortunately, this does not apply to the SPN. We suggest that assessment of publication bias is a feasible first step for other researchers undertaking a catalogue-evaluate exercise.”
At the end of Low statistical Power, we went beyond the original article by comparing sample sizes in may published ERP papers and drawing more general conclusions:
“When planning our experiments, we have often assumed that 24 is a typical sample size in EEG research. […] Larger samples reduce type II error, give more accurate estimates of true effect size, and facilitate additional exploratory analyses on the same data sets.”
At the end of P-hacking
“It is easier to publish a simple story with a beautiful procession of significant effects. […] It is advisable that all researchers compare multiple analysis pipelines to assesvibration of effects and calibrate their confidence accordingly”
At the end of HARKing
“Our recommendation is to use pre-registration to combat HARKing. Perhaps unregistered EEG experiments will be considered unpublishable in the not-too-distant future.”
These four recommendations are locally important. Our one overarching recommendation is simply for other researchers to do what we have done: They should compile complete public catalogues and then use them to evaluate their own data and practices using Bishop’s four horsemen framework. In informal terms, we want readers to think “Good question – am I delivering meaningful results or not? This is rather important, and nobody else is going to check for me, even if I make all my data sets publicly available. Maybe I should also do a big catalogue-evaluate exercise like this”. We previously left this overarching recommendation implicit because actions speak louder than words, and there are already many authoritative meta-science commentaries urging improvement. However, we have now added one more advice paragraph Discussion section:
“While some readers may not be interested in the validity of SPN research per se, they may be interested in this meta-scientific exercise. Our one overarching recommendation is that researchers could consider conducting comparable catalogue – evaluate exercises on many phenomena. In fact, this may be essential for cumulative science. It has been argued that research should be auditable (Nelson et al., 2018), but Researcher A will rarely be motivated to audit a repository uploaded by Researcher B, even if the datasets are FAIR. To fight the replication crisis, we must actively look in the mirror, not just passively let others snoop through the window.”
9 Publication bias
a) Line 145. "A meta-analysis based on the published SPNs along would overestimate...". It is essential that you perform such a meta-analysis. What you have done is compare the means computed from all vs. published, but not set-up a meta-analysis in which the mean is estimated from the means and variances of published studies alone (I suggest dmetar which is super easy to use even if you never used R / R-studio before; https://bookdown.org/MathiasHarrer/Doing_Meta_Analysis_in_R/). That extra analysis will be very useful because, people do not have access to the data to compute the mean and thus use this meta-analytical approach (how much this will differ from -1.17uV?; in theory it should bring the results closer to -0.94uV)
We have conducted the meta-analysis and added funnel plots to Figure 2. Weighted mean SPN amplitude was found to be -0.954 μV. The funnel plots showed some asymmetry, but this cannot be the result of publication bias because it was still present when all SPN in the file drawer were incorporated. We also found it instructive to meta-analyse P1 and N1 peaks, because these signals are not likely to influence publication success in the same way. The publication bias section now includes details of this meta-analysis:
“To further explore these effects, we ran three random-effects meta-analyses (using metamean function from the dmetar library in R). The first was limited to the 115 published SPNs (as if they were the only ones available). Weighted mean SPN amplitude was -1.138 microvolts [95%CI = -1.290 to -0.986]. These studies could be split in groups, as they use different types of stimuli and tasks, but here we focus on the overall picture.”
The funnel plot in Figure 2A shows published SPNs as green data points. These are not symmetrically tapered: Less accurate measures near the base of the funnel are skewed leftwards. This is a textbook fingerprint of publication bias, and Egger’s test found that the asymmetry was significant (bias = -6.866, t (113) = -8.45, p <.001). However, a second meta-analysis, with all SPNs, found mean SPN amplitude was reduced, at -0.954 microvolts [-1.049; -0.860], but asymmetry in the funnel plot was still significant (bias = -4.546, t (247) = -8.20, p <.001). Furthermore, the asymmetry was significant in a third meta-analysis on the unpublished SPNs only (Weighted mean SPN = -0.801 microvolts [-0.914; -0.689], bias = -2.624, t (132) = -3.51, p <.001).
P1 peak and N1 trough amplitudes from the same trials provide an instructive comparison. P1 peak was measured as maximum amplitude achieved between 100 and 200 ms post stimulus onset. The N1 trough was measured as the minimum between 150 and 250 ms, as a difference from P1 peak (see inset ERP waveforms Figure 2). Our papers do not need large P1 and N1 components, so these are unlikely to have a systematic effect on publication. P1 peak was essentially identical in published and unpublished work (4.672 vs. 4.686, t (195.11) = 0.067, p = .946, Figure 2B). This is potentially an interesting counterpoint to the SPN. However, the N1 trough was larger in published work (-8.736 vs. -7.155. t (183.61) = -5.636, p <.001, Figure 2C). Funnel asymmetry was also significant for P1 (bias = 5.281, t (247) = 11.13, p< 0.001) and N1 (bias = -5.765, t (247) = -13.15, p <.001).
We conclude that publication bias does not explain the observed funnel plot asymmetry. It could be that larger brain responses are inherently more variable between trials and participants. This could cause funnel asymmetry which may be erroneously blamed on publication bias. Furthermore, larger sample sizes may have been selected based on the expectation of a small effect size (see Zwetsloot et al., 2017 for detailed analysis of funnel asymmetry).
This analysis was based on publication status in October 2020. Four more studies have since escaped the file drawer and joined the literature. By January 2022, published and unpublished SPNs had similar samples (26.17 vs 26.81, p = .596). However, recategorizing these 4 studies does not dramatically alter the results (File drawer weighted mean SPN = -0.697 [-0.818; -0.577], funnel asymmetry = -2.693; t (98) = -3.23, p = .002); Literature weighted mean SPN = – 1.127 [-1.256; -0.997] funnel asymmetry = -5.910, t (147) = -8.66, (p <.001). Finally, one can also take a different approach using 84 SPNs from 84 independent groups. Results were very similar, as described in Supplementary independent groups analysis (available in the SPN analysis and guidebooks folder on OSF).
10 Low statistical power
– Power analysis: You need to explain better the analysis. It is also essential that you demonstrate that a 2nd order polynomial fits better than a 1st order using AIC and RMSE. A second aspect is that you cannot predict effect size from amplitude because the polynome you have was obtained for the entire dataset. This is a typical machine learning regression setting: you need to cross-validate to produce an equation than generalizes -- given the goal is to generalize across experiments, a natural cross validation scheme would be the experimental belonging (fit all data but one experiment, test – iterate to optimize parameters).
– Nonlinearity: to further look into that question you need the complementary plot Cohens'd vs. variance (or 3d plot d, variance, amplitude but sometimes it's hard to see). Given that d = mean/std, the nonlinearity arises because there is a 'spot' where variance behave strangely (likely for the midrange amplitude values). This also relates to your discussion on the number of trials because the number of trials increases precision and in principle reduce between subject variance; depending on expected amplitude the number of trials should therefore be adjusted to reduce variance bias.
These are very important points. We have included a new supplementary document on OSF that covers these topics. In the manuscript we link to it with this new sentence:
“The curve tails off for strong SPNs, resulting in a nonlinear relationship. The second order polynomial trendline was a better fit than the first order linear trendline (see supplementary polynomial regression in the SPN analysis and guidebooks folder on OSF).”
The new supplementary polynomial regression analysis is based on the above recommendations.
11 Miscellaneous
a) Please provide links to the code for the analysis presented in the paper.
On OSF we now have a folder explicitly dedicated to the analysis used in this paper (see compressed ‘Analysis in eLife paper’ in the SPN apps and guidebooks folder, https://osf.io/2sncj/). This link is now included in the manuscript.
b) Please consider making the data-viewing app agnostic wrt operating system.
Done
c) Re the headline effects reported in figure 5: the explanation of these effects in the in the repository needs to be more detailed.
We have taken this part of the figure out because it may be a case of dwelling on SPN-specific issues. In the repository we have now added a DOI and a longer description of each effect (see Famous ANOVA effect sizes.xlsx > sheet2).
d) Line 148. Please say more about the reasons why 68 SPNs "will likely in the file drawer forever".
As part of our attempts to make the paper less self-referential we removed this future publication bias section, which was a bit speculative anyway. A common reason some projects will be in the file drawer forever is because other more conclusive versions end up being published instead.
e) Line 191 onwards. When talking about pilot studies please add references (for instance Lakens (doi.org/10.1016/j.jesp.2017.09.004). Also, please consider discussing the smallest effect size of interest instead of absolute effect size.
We have now cited this paper when making the point about the low value of pilot studies for estimating effect size and power.
“It is less well-known that one pilot experiment does not provide a reliable estimate of effect size (especially when the pilot itself has a small sample; Albers and Lakens, 2018).”
We have also added this about smallest effect size:
“Alternatively, researchers may require a sample that allows them to find the minimum effect that would still be of theoretical interest. Brysbaert (2019) suggests this may often be ~0.4 in experimental psychology, and this requires 52 participants. Indeed, the theoretically interesting effect of Task on SPN amplitude could be in this range.”
https://doi.org/10.7554/eLife.66388.sa2Article and author information
Author details
Funding
Economic and Social Research Council (ES/S014691/1)
- Alexis DJ Makin
- John Tyson-Carr
- Giulia Rampone
- Marco Bertamini
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
Many people contributed to the complete Liverpool SPN catalogue. One notable past contributor was Dr Letizia Palumbo (who was a postdoc 2013–2016). Many undergraduate, postgraduate and intern students have also been involved in data collection.
Ethics
This was meta-analysis of previously published work (and unpublished work). All datasets were electrophysiological recordings taken from human participants. All experiments had local ethics committee approval and were conducted according to the Declaration of Helsinki (Revised 2008). Therefore all participants gave informed consent.
Publication history
- Received:
- Accepted:
- Version of Record published:
Copyright
© 2022, Makin et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 966
- views
-
- 114
- downloads
-
- 13
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Meta-Research: Lessons from a catalogue of 6674 brain recordings
eLife 11:e66388.
https://doi.org/10.7554/eLife.66388

Further reading
-
- Neuroscience
When holding visual information temporarily in working memory (WM), the neural representation of the memorandum is distributed across various cortical regions, including visual and frontal cortices. However, the role of stimulus representation in visual and frontal cortices during WM has been controversial. Here, we tested the hypothesis that stimulus representation persists in the frontal cortex to facilitate flexible control demands in WM. During functional MRI, participants flexibly switched between simple WM maintenance of visual stimulus or more complex rule-based categorization of maintained stimulus on a trial-by-trial basis. Our results demonstrated enhanced stimulus representation in the frontal cortex that tracked demands for active WM control and enhanced stimulus representation in the visual cortex that tracked demands for precise WM maintenance. This differential frontal stimulus representation traded off with the newly-generated category representation with varying control demands. Simulation using multi-module recurrent neural networks replicated human neural patterns when stimulus information was preserved for network readout. Altogether, these findings help reconcile the long-standing debate in WM research, and provide empirical and computational evidence that flexible stimulus representation in the frontal cortex during WM serves as a potential neural coding scheme to accommodate the ever-changing environment.
-
- Neuroscience
When navigating environments with changing rules, human brain circuits flexibly adapt how and where we retain information to help us achieve our immediate goals.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}