Self-configuring feedback loops for sensorimotor control
- Computational Neuroscience Unit, Okinawa Institute of Science and Technology, Japan
Abstract
How dynamic interactions between nervous system regions in mammals performs online motor control remains an unsolved problem. In this paper, we show that feedback control is a simple, yet powerful way to understand the neural dynamics of sensorimotor control. We make our case using a minimal model comprising spinal cord, sensory and motor cortex, coupled by long connections that are plastic. It succeeds in learning how to perform reaching movements of a planar arm with 6 muscles in several directions from scratch. The model satisfies biological plausibility constraints, like neural implementation, transmission delays, local synaptic learning and continuous online learning. Using differential Hebbian plasticity the model can go from motor babbling to reaching arbitrary targets in less than 10 min of in silico time. Moreover, independently of the learning mechanism, properly configured feedback control has many emergent properties: neural populations in motor cortex show directional tuning and oscillatory dynamics, the spinal cord creates convergent force fields that add linearly, and movements are ataxic (as in a motor system without a cerebellum).
Editor's evaluation
This solid modelling study presents a valuable contribution toward understanding the neural control of movement. The authors show that a minimal model comprising key sensorimotor cortical areas as well as a spinal circuits controlling a limb readily replicates landmark observations from behavioural and electrophysiological studies. This work will be of broad interest to motor control researchers, as well as to neurophysiologists interested in testing the predictions derived from this model.
https://doi.org/10.7554/eLife.77216.sa0Introduction
The challenge
Neuroscience has made great progress in decoding how cortical regions perform specific brain functions like primate vision (Kaas and Collins, 2003; Ballard and Zhang, 2021 and rodent navigation Chersi and Burgess, 2015; Moser et al., 2017). Conversely, the evolutionary much older motor control system still poses fundamental questions, despite a large body of experimental work. This is because, in mammals, in addition to areas in cortex like premotor and motor areas and to some degree sensory and parietal ones, many extracortical regions have important and unique functions: basal ganglia, thalamus, cerebellum, pons, brain stem nuclei like the red nucleus and spinal cord (Eccles, 1981; Loeb and Tsianos, 2015). These structures are highly interconnected by fast conducting axons and all show strong dynamic activity changes, related to the ongoing dynamics of the performed motor act. Clinical and lesion studies have confirmed the necessity of each of these regions for normal smooth motor control of arm reaching (Shadmehr and Wise, 2005; Arber and Costa, 2018).
Fully understanding motor control will thus entail understanding the simultaneous function and interplay of all brain regions involved. Little by little, new experimental techniques will allow us to monitor more neurons, in more regions, and for longer periods (Tanaka et al., 2018, e.g.). But to make sense of these data computational models must step up to the task of integrating all those regions to create a functional neuronal machine.
Finally, relatively little is known about the neural basis of motor development in infants (Hadders-Algra, 2018). Nevertheless, a full understanding of primate motor control will not only require explanation of how these brain regions complement and interact with each other but also how this can be learned during childhood.
With these challenges in mind we recently developed a motor control framework based on differential Hebbian learning (Verduzco-Flores et al., 2022). A common theme in physiology is the control of homeostatic variables (e.g. blood glucose levels, body temperature, etc.) using negative feedback mechanisms (Woods and Ramsay, 2007). From a broad perspective, our approach considers the musculoskeletal system as an extension of this homeostatic control system: movement aims to make the external environment conducive to the internal control of homeostatic variables (e.g. by finding food, or shelter from the sun).
Our working hypothesis (see Verduzco-Flores et al., 2022) is that control of homeostatic variables requires a feedback controller that uses the muscles to produce a desired set of sensory perceptions. The motosensory loop, minimally containing motor cortex, spinal cord, and sensory cortex may implement that feedback controller. To test this hypothesis we implemented a relatively complete model of the sensorimotor loop (Figure 1), using the learning rules in Verduzco-Flores et al., 2022 to produce 2D arm reaching. The activity of the neural populations and the movements they produced showed remarkable consistency with the experimental observations that we describe next.
Figure 1
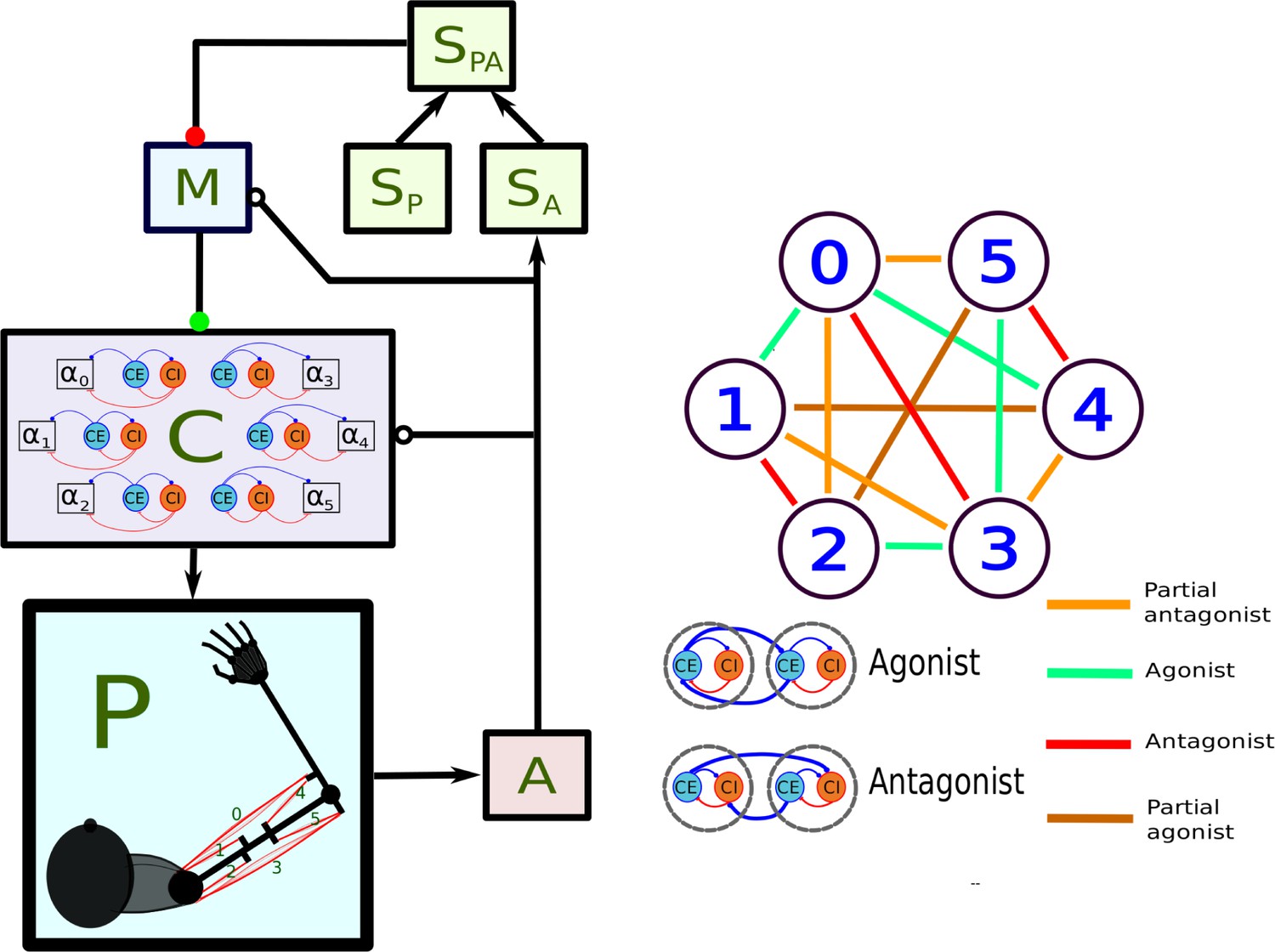
Main components of the model.
In the left panel, each box stands for a neural population, except for P, which represents the arm and the muscles. Arrows indicate static connections, open circles show input correlation synapses, and the two colored circles show possible locations of synapses with the learning rule in Verduzco-Flores et al., 2022. In the spinal learning model the green circle connections are plastic, and the red circle connections are static. In the cortical learning model the red circle connections are plastic, whereas the green circle connections are static. In the static network all connections are static. A : afferent population. : Somatosensory cortex, modulated by afferent input. : somatosensory cortex, prescribed pattern. : population signaling the difference between and : primary motor cortex. : spinal cord. Inside the box the circles represent the excitatory () and inhibitory () interneurons, organized into six pairs. The interneurons in each pair innervate an alpha motoneuron (), each of which stimulates one of the six muscles in the arm, numbered from 0 to 5. The trios consisting of , , units are organized into agonists and antagonists, depending on whether their motoneurons cause torques in similar or opposite directions. These relations are shown in the right-side panel.
Relevant findings in motor control
Before describing our modeling approach, we summarize some of the relevant experimental data that will be important to understanding the results. We focus on three related issues: (1) the role of the spinal cord in movement, (2) the nature of representations in motor cortex, and (3) muscle synergies, and how the right pattern of muscle activity is produced.
For animals to move, spinal motoneurons must activate the skeletal muscles. In general, descending signals from the corticospinal tract do not activate the motoneurons directly, but instead provide input to a network of excitatory and inhibitory interneurons (Bizzi et al., 2000; Lemon, 2008; Arber, 2012; Asante and Martin, 2013; Alstermark and Isa, 2012; Jankowska, 2013; Wang et al., 2017; Ueno et al., 2018). Learning even simple behaviors involves long-term plasticity, both at the spinal cord (SC) circuit, and at higher regions of the motor hierarchy (Wolpaw et al., 1983; Grau, 2014; Meyer-Lohmann et al., 1986; Wolpaw, 1997; Norton and Wolpaw, 2018). Despite its obvious importance, there are comparatively few attempts to elucidate the nature of the SC computations, and the role of synaptic plasticity.
The role ascribed to SC is closely related to the role assumed from motor cortex, particularly M1. One classic result is that M1 pyramidal neurons of macaques activate preferentially when the hand is moving in a particular direction. When the preferred directions of a large population of neurons are added as vectors, a population vector appears, which points close to the hand’s direction of motion (Georgopoulos et al., 1982; Georgopoulos et al., 1986). This launched the hypothesis that M1 represents kinematic, or other high-level parameters of the movement, which are transformed into movements in concert with the SC. This hypothesis mainly competes with the view that M1 represents muscle forces. Much research has been devoted to this issue (Kakei et al., 1999; Truccolo et al., 2008; Kalaska, 2009; Georgopoulos and Stefanis, 2007; Harrison and Murphy, 2012; Tanaka, 2016; Morrow and Miller, 2003; Todorov, 2000, e.g.).
Another important observation is that the preferred directions of motor neurons cluster around one main axis. As shown in Scott et al., 2001, this suggests that M1 is mainly concerned with dynamical aspects of the movement, rather than representing its kinematics.
A related observation is that the preferred directions in M1 neurons experience random drifts that overlap learned changes (Rokni et al., 2007; Padoa-Schioppa et al., 2004). This leads to the hypothesis that M1 is a redundant network that is constantly using feedback error signals to capture the task-relevant dimensions, placing the configuration of synaptic weights in an optimal manifold.
A different perspective for studying motor cortex is to focus on how it can produce movements, rather than describing its activity (Shenoy et al., 2013). One specific proposal is that motor cortex has a collection of pattern generators, and specific movements can be created by combining their activity (Shenoy et al., 2013; Sussillo et al., 2015). Experimental support for this hypothesis came through the surprising finding of rotational dynamics in motor cortex activity (Churchland et al., 2012), suggesting that oscillators with different frequencies are used to produce desired patterns. This begs the question of how the animal chooses its desired patterns of motion.
Selecting a given pattern of muscle activation requires planning. Motor units are the final actuators in the motor system, but they number in the tens of thousands, so planning movements in this space is unfeasible. A low-dimensional representation of desired limb configurations (such as the location of the hand in Euclidean coordinates) is better. Movement generation likely involves a coordinate transformation, from the endpoint coordinates (e.g. hand coordinates) into actuator coordinates (e.g. muscle lengths), from which motor unit activation follows directly. Even using pure engineering methods, as for robot control, computing this coordinate transformation is very challenging. For example, this must overcome kinematic redundancies, as when many configurations of muscle lengths put the hand in the same location.
The issue of coordinate transformation is central for motor control (Shadmehr and Wise, 2005; Schöner et al., 2018; Valero-Cuevas, 2009; motor primitives and muscle synergies are key concepts in this discussion). Representing things as combinations of elementary components is a fundamental theme in applied mathematics. For example, linear combinations of basis vectors can represent any vector, and linear combinations of wavelets can approximate any smooth function (Keener, 1995). In motor control, this idea arises in the form of motor primitives. Motor primitives constitute a set of basic motions, such that that any movement can be decomposed into them (Giszter, 2015; Mussa–Ivaldi and Bizzi, 2000; Bizzi et al., 1991). This is closely related to the concept of synergies. The term ‘synergy’ may mean several things (Kelso, 2009; Bruton and O’Dwyer, 2018), but in this paper, we use it to denote a pattern of muscle activity arising as a coherent unit. Synergies may be composed of motor primitives, or they may be the motor primitives themselves.
A promising candidate for motor primitives comes in the form of convergent force fields, which have been observed for the hindlimbs of frogs and rats (Giszter et al., 1993; Mussa-Ivaldi et al., 1994, or in the forelimbs of monkeys Yaron et al., 2020). In experiments where the limb is held at a particular location, local stimulation of the spinal cord will cause a force to the limb’s endpoint. The collection of these force vectors for all of the limb endpoint’s positions forms a force field, and these force fields have two important characteristics: (1) they have a unique fixed point and (2) simultaneous stimulation of two spinal cord locations produces a force field which is the sum of the force fields from stimulating the two locations independently. It is argued that movement planning may be done in terms of force fields, since they can produce movements that are resistant to perturbations, and also permit a solution to the problem of coordinate transformation with redundant actuators (Mussa–Ivaldi and Bizzi, 2000).
The neural origin of synergies, and whether they are used by the motor system is a matter of ongoing debate (Tresch and Jarc, 2009; de Rugy et al., 2013; Bizzi and Cheung, 2013). To us, it is of interest that single spinal units found in the mouse (Levine et al., 2014 and monkey Takei et al., 2017) spinal cord (sometimes called Motor Synergy Encoders, or MSEs) can reliably produce specific patterns of motoneuron activation.
Model concepts
We believe that it is impossible to understand the complex dynamical system in biological motor control without the help of computational modeling. Therefore, we set out to build a minimal model that could eventually control an autonomous agent, while still satisfying biological plausibility constraints.
Design principles and biological-plausibility constraints for neural network modeling have been proposed before (Pulvermüller et al., 2021; O’Reilly, 1998; Richards et al., 2019). Placing emphasis on the motor system, we compiled a set of characteristics that cover the majority of these constraints. Namely:
Spanning the whole sensorimotor loop.
Using only neural elements. Learning their connection strengths is part of the model.
Learning does not rely on a training dataset. It is instead done by synaptic elements using local information.
Learning arises from continuous-time interaction with a continuous-space environment.
There is a clear vision on how the model integrates with the rest of the brain in order to enact more general behavior.
Our aim is hierarchical control of homeostatic variables, with the spinal cord and motor cortex at the bottom of this hierarchy. At first glance, spinal plasticity poses a conundrum, because it changes the effect of corticospinal inputs. Cortex is playing a piano that keeps changing its tuning. A solution comes when we consider the corticospinal loop (e.g. the long-loop reflex) as a negative control system, where the spinal cord activates the effectors to reduce an error. The role of cortex is to produce perceptual variables that are controllable, and can eventually improve homeostatic regulation. In this regard, our model is a variation of Perceptual Control Theory (Powers, 1973; Powers, 2005), but if the desired value of the controller is viewed as a prediction, then this approach resembles active inference models (Adams et al., 2013). Either way, the goal of the system is to reduce the difference between the desired and the perceived value of some variable.
If cortex creates representations for perceptual variables, the sensorimotor loop must be configured so those variables can be controlled. This happens when the error in those variables activates the muscles in a way that brings the perceived value closer to the desired value. In other words, we must find the input-output structure of the feedback controller implicit in the long-loop reflex. We have found that this important problem can be solved by the differential Hebbian learning rules introduced in Verduzco-Flores et al., 2022. We favor the hypothesis that this learning takes place is in the connections from motor cortex to interneurons and brainstem. Nevertheless, we show that all our results are valid if learning happens in the connections from sensory to motor cortex.
In the Results section we will describe our model, its variations, and how it can learn to reach. Next we will show that many phenomena described above are present in this model. These phenomena emerge from having a properly configured neural feedback controller with a sufficient degree of biological realism. This means that even if the synaptic weights of the connections are set by hand and are static, the phenomena still emerge, as long as the system is configured to reduce errors. In short, we show that a wealth of phenomena in motor control can be explained simply by feedback control in the sensorimotor loop, and that this feedback control can be configured in a flexible manner by the learning rules presented in Verduzco-Flores et al., 2022.
Results
A neural architecture for motor control
The model in this paper contains the main elements of the long-loop reflex, applied to the control of a planar arm using six muscles. The left panel of Figure 1 shows the architecture of the model, which contains 74 firing rate neurons organized in six populations. This architecture resembles a feedback controller that makes the activity in a neural population approach the activity in a different population .
The six firing-rate neurons (called units in this paper) in represent a region of somatosensory cortex, and its inputs consist of the static gamma (II) afferents. In steady state, activity of the II afferents is monotonically related to muscle length (Mileusnic et al., 2006), which in turn can be used to prescribe hand location. Other afferent signals are not provided to in the interest of simplicity.
represents a different cortical layer of the same somatosensory region as , where a ‘desired’ or ‘predicted’ activity has been caused by brain regions not represented in the model. Each firing rate neuron in has a corresponding unit in , and they represent the mean activity at different levels of the same microcolumn (Mountcastle, 1997). is a region (either in sensory or motor cortex) that conveys the difference between activities in and , which is the error signal to be minimized by negative feedback control.
Population represents sensory thalamus and dorsal parts of the spinal cord. It contains 18 units with logarithmic activation functions, each receiving an input from a muscle afferent. Each muscle provides proprioceptive feedback from models of the Ia, Ib, and II afferents. In rough terms, Ia afferents provide information about contraction velocity, and Ib afferents signal the amount of tension in the muscle and tendons.
Population represents motor cortex. Ascending inputs to arise from population , and use a variation of the input correlation learning rule (Porr and Wörgötter, 2006), where the inputs act as a learning signal. The input correlation rule enhances the stability of the controller. More details are presented in Methods. The inputs to can either be static, or use a learning rule to be described below.
To represent positive and negative values, both and use a ‘dual representation’, where each error signal is represented by two units. Let be the error associated with the -th muscle. One of the two units representing ei is a monotonic function of , whereas the other unit increases according to . These opposing inputs, along with mutual inhibition between the two units creates dynamics where sensorimotor events cause both excitatory and inhibitory responses, which agrees with experimental observations (Shafi et al., 2007; Steinmetz et al., 2019; Najafi et al., 2020), and allows transmitting ‘negative’ values using excitatory projections. Dual units in receive the same inputs, but with the opposite sign.
Plasticity mechanisms within the sensorimotor loop should specify which muscles contract in order to reduce an error signaled by . We suggest that this plasticity could take place in the spinal cord and/or motor cortex. To show that our learning mechanisms work regardless of where the learning takes place, we created two main configurations of the model. In the first configuration, called the ‘spinal learning’ model, a ‘spinal’ network transforms the outputs into muscle stimulation. learns to transform sensory errors into appropriate motor commands using a differential Hebbian learning rule (Verduzco-Flores et al., 2022). In this configuration, the error input to each unit comes from one of the activities. A second configuration, called the ‘cortical learning’ model, has ‘all-to-all’ connections from to using the differential Hebbian rule, whereas the connections from to use appropriately patterned static connections. Both configurations are basically the same model; the difference is that one configuration has our learning rule on the inputs to , whereas the other has it on the inputs to (Figure 1).
While analyzing our model we reproduced several experimental phenomena (described below). Interestingly, these phenomena did not arise because of the learning rules. To make this explicit, we created a third configuration of our model, called the ‘static network’. This configuration does not change the weight of any synaptic connection during the simulation. The initial weights were hand-set to approximate the optimal solution everywhere (see Methods). We will show that all emergent phenomena in the paper are also present in the static network.
We explain the idea behind the differential Hebbian rule as applied in the connections from to contains interneurons, whose activity vector we denote as . The input to each of these units is an dimensional vector . Each unit in has an output , where is a positive sigmoidal function. The inputs are assumed to be errors, and to reduce them we want ej to activate ci when ci can reduce ej. One way this could happen is when the weight from ej to ci is proportional to the negative of their sensitivity derivative:
(1)
Assuming a monotonic relation between the motor commands and the errors, relation 1 entails that errors will trigger an action to cancel them, with some caveats considered in Verduzco-Flores et al., 2022. Synaptic weights akin to Equation 1 can be obtained using a learning rule that extracts correlations between the derivatives of ci and ej (see Methods). Using this rule, the commands coming from population can eventually move the arm so that activity resembles activity.
is organized to capture the most basic motifs of spinal cord connectivity using a network where balance between excitation and inhibition is crucial (Berg et al., 2007; Berg et al., 2019; Goulding et al., 2014). Each one of six motoneurons stimulate one muscle, and is stimulated by one excitatory (), and one inhibitory () interneuron. and stimulate one another, resembling the classic Wilson-Cowan model (Cowan et al., 2016). The trios composed of , and neurons compose a group that controls the activation of one muscle, with and receiving convergent inputs from . This resembles the premotor network model in Petersen et al., 2014. () trios are connected to other trios following the agonist-antagonist motif that is common in the spinal cord (Pierrot-Deseilligny and Burke, 2005). This means that units project to the units of agonists, and to the units of antagonists (Figure 1, right panel). When the agonist/antagonist relation is not strongly defined, muscles can be ‘partial’aASaS agonists/antagonists, or unrelated.
Connections from to (the ‘short-loop reflex’) use the input correlation learning rule, analogous to the connections from to .
Direct connections from to alpha motoneurons are not necessary for the model to reach, but they were introduced in new versions because in higher primates these connections are present for distal joints (Lemon, 2008). Considering that bidirectional plasticity has been observed in corticomotoneural connections (Nishimura et al., 2013), we chose to endow them with the differential Hebbian rule of Verduzco-Flores et al., 2022.
Because timing is essential to support the conclusions of this paper, every connection has a transmission delay, and all firing rate neurons are modeled with ordinary differential equations.
All the results in this paper apply to the three configurations described above (spinal learning, cortical learning, and static network). To emphasize the robustness and potential of the learning mechanisms, in the Appendix we introduce two variations of the spinal learning model (in the Variations of the spinal learning model section). All results in the paper also apply to those two variations. In one of the variations (the ‘synergistic’ network), each spinal motoneuron stimulates two muscles rather than one. In the second variation (the ‘mixed errors’ network), the inputs from to are not one-to-one, but instead come from a matrix that combines multiple error signals as the input to each unit.
Since most results apply to all configurations, and since results could depend on the random initial weights, we report simulation results using three means and three standard deviations , with the understanding that these three value pairs correspond respectively to the spinal learning, motor learning, and static network models. The statistics come from 20 independent simulations with different initial conditions.
A reference section in the Appendix (the Comparison of the 5 configurations section) summarizes the basic traits of all different model configurations (including the two variations of the spinal learning model), and compiles all their numerical results.
For each configuration, a single simulation was used to produce all the representative plots in different sections of the paper.
The model can reach by matching perceived and desired sensory activity
Reaches are performed by specifying an pattern equal to the activity when the hand is at the target. The acquisition of these patterns is not in the scope of this paper (but see Verduzco-Flores et al., 2022).
We created a set of random targets by sampling uniformly from the space of joint angles. Using this to set a different pattern in every 40 s, we allowed the arm to move freely during 16 target presentations. To encourage exploratory movements we used noise and two additional units described in the Methods.
All model configurations were capable of reaching. To decide if reaching was learned in a trial we took the average distance between the hand and the target (the average error) during the last four target presentations. Learning was achieved when this error was smaller than 10 cm.
The system learned to reach in 99 out of 100 trials (20 for each configuration). One simulation with the spinal learning model had an average error of 14 cm during the last 4 reaches of training. To assess the speed of learning we recorded the average number of target presentations required before the error became less than 10 cm for the first time. This average number of failed reaches before the first success was: .
Figure 2A shows the error through 16 successive reaches (640 s of in silico time) in a typical case for the spinal learning model. A supplementary video (Appendix 1—Video 1) shows the arm’s movements during this simulation. Figures similar to Figure 2 can be seen for all configurations as figure supplements (Figure 2—figure supplement 1) (Figure 2—figure supplement 2).
Figure 2 with 4 supplements see all
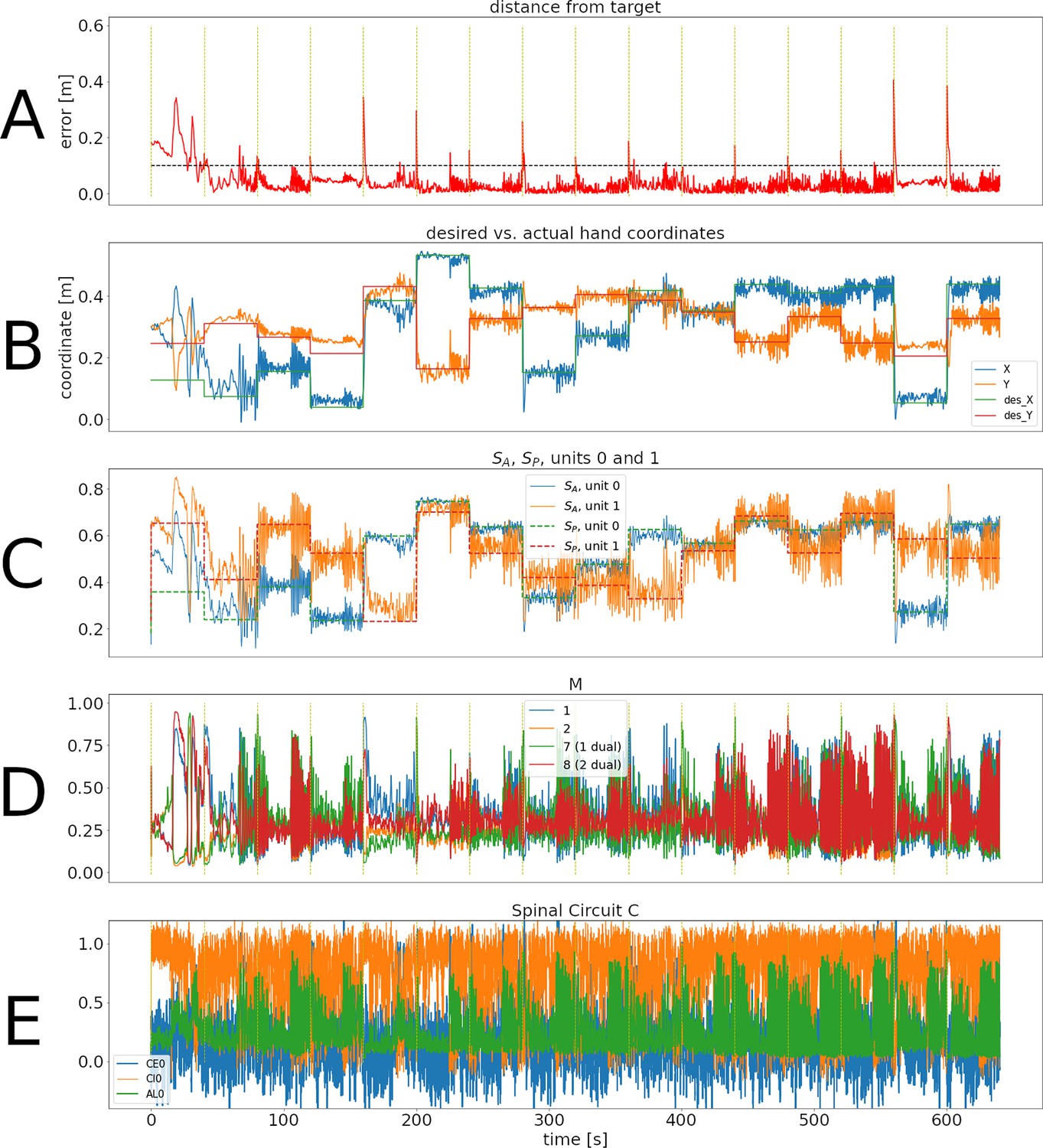
Representative training phase of a simulation for the spinal learning model.
(A) Distance between the target and the hand through 640 s of simulation, corresponding to 16 reaches to different targets. The horizontal dotted line corresponds to 10 cm. The times when changes are indicated with a vertical, dotted yellow line. Notice that the horizontal time axis is the same for all panels of this figure. The average error can be seen to decrease through the first two reaches. (B) Desired versus actual hand coordinates through the training phase. The straight lines denote the desired X (green) and Y (red) coordinates of the hand. The noisy orange and blue lines show the actual coordinates of the hand. (C) Activity of units 0 and 1 in and . This panel shows that the desired values in the units (straight dotted lines) start to become tracked by the perceived values. (D) Activity of units 1, 2, and their duals. Notice that even when the error is close to zero the activity in the units does not disappear. E: Activity of the trio for muscle 0. The intrinsic noise in the units causes ongoing activity. Moreover, the inhibitory activity (orange line) dominates the excitatory activity (blue line).
In Figure 2A, the error increases each time a new target was presented (yellow vertical lines), but as learning continues it was consistently reduced below 10 cm.
Panel B also shows the effect of learning, as the hand’s Cartesian coordinates eventually track the target coordinates whenever they change. This is also reflected as the activity in becoming similar to the activity in (panel C).
Panels D and E of Figure 2 show the activity of a few units in population and population during the 640 s of this training phase. During the first few reaches, shows a large imbalance between the activity of units and their duals, reflecting larger errors. Eventually these activities balance out, leading to a more homogeneous activity that may increase when a new target appears. M1 activation patterns that produce no movement are called the null-space activity (Kaufman et al., 2014). In our case, this includes patterns where units have the same activity as their duals. This, together with the noise and oscillations intrinsic to the system cause the activity in and to never disappear.
In panel E, the noise in the units becomes evident. It can also be seen that inhibition dominates excitation (due to to connections), which promotes stability in the circuit.
We tested whether any of the novel elements in the model were superfluous. To this end, we removed each of the elements individually and checked if the model could still learn to reach. In conclusion, removing individual elements generally deteriorated performance, but the factor that proved essential for all configurations with plasticity was the differential Hebbian learning in the connections from to or from to . For details, see the the Appendix section titled The model fails when elements are removed.
Center-out reaching 1: The reach trajectories present traits of cerebellar ataxia
In order to compare our model with experimental data, after the training phase we began a standard center-out reaching task. Switching to this task merely consisted of presenting the targets in a different way, but for the sake of smoother trajectories we removed the noise from the units in or .
Figure 3A shows the eight peripheral targets around a hand rest position. Before reaching a peripheral target, a reach to the center target was performed, so the whole experiment was a single continuous simulation controlled by the pattern.
Figure 3 with 3 supplements see all

Center-out reaching.
(A) The arm at its resting position, with hand coordinates (0.3, 0.3) meters, where a center target is located. Eight peripheral targets (cyan dots) were located on a circle around the center target, with a 10 cm radius. The muscle lines, connecting the muscle insertion points, are shown in red. The shoulder is at the origin, whereas the elbow has coordinates (0.3, 0). Shoulder insertion points remain fixed. (B-F) Hand trajectories for all reaches in the three configurations. The trajectory’s color indicates the target. Dotted lines show individual reaches, whereas thick lines indicate the average of the 6 reaches.
Peripheral targets were selected at random, each appearing six times. This produced 48 reaches (without counting reaches to the center), each one lasting 5 s. Panels B through D of Figure 3 show the trajectories followed by the hand in the three configurations. During these 48 reaches the average distance between the hand and the target was centimeters.
Currently our system has neither cerebellum nor visual information. Lacking a ‘healthy’ model to make quantitative comparisons, we analyzed and compared them to data from cerebellar patients.
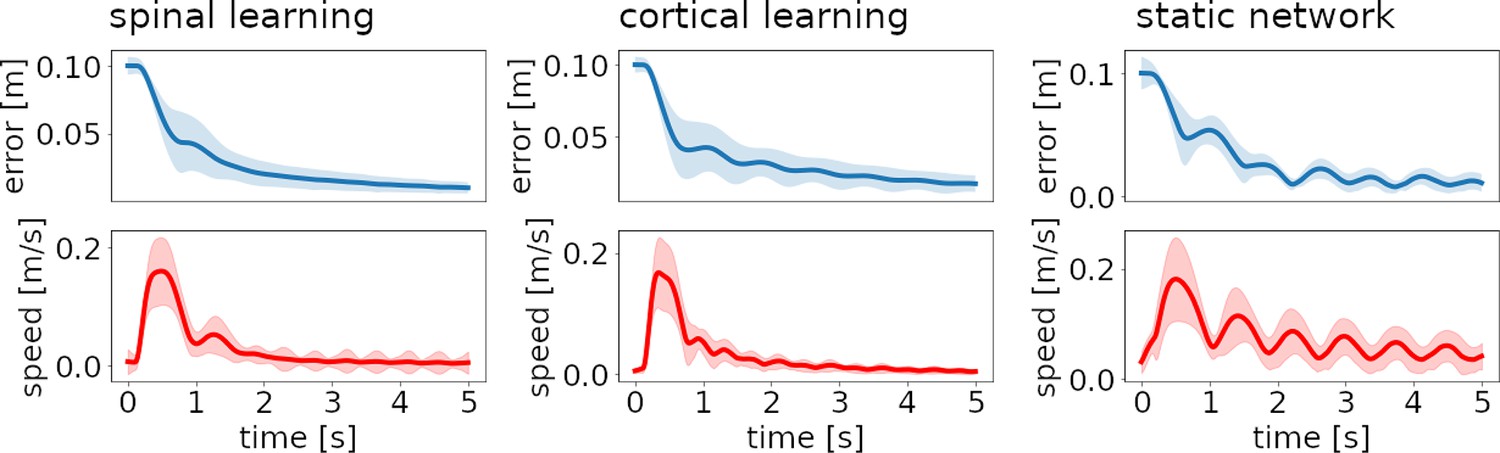
For the sake of stability and simplicity, our system is configured to perform slow movements. Fast and slow reaches are different in cerebellar patients (Bastian et al., 1996). Slow reaches undershoot the target, follow longer hand paths, and show movement decomposition (joints appear to move one at a time). In Figure 3 the trajectories begin close to the 135 degree axis, indicating a slower response at the elbow joint. With the parameters used, the spinal learning and cortical learning models tend to undershoot the target, whereas in the static network the hand can oscillate around the target.
The traits of the trajectories can be affected by many hyperparameters in the model, but the dominant factor seems to be the gain in the control loop. Our model involves delays, activation latencies, momentum, and interaction torques. Unsurprisingly, increasing the gain leads to oscillations along with faster reaching. On the other hand, low gain leads to slow, stable reaching that often undershoots the target. Since we do not have a cerebellum to overcome this trade off, the gain was the only hyperparameter that was manually adjusted for all configurations (See Methods). In particular, we adjusted the slope of the and units so the system was stable, but close to the onset of oscillations. Gain was allowed to be a bit larger in the static network so oscillations could be observed. The figure supplements for Figure 3 shows more examples of configurations with higher gain (See Gain and oscillations in Appendix 1 for details).
The shape of the trajectory also depends on the target. Different reach directions cause different interaction forces, and encounter different levels of viscoelastic resistance from the muscles.
Figure 4 reveals that the approach to the target is initially fast, but gradually slows down. Healthy subjects usually present a bell-shaped velocity profile, with some symmetry between acceleration and deceleration. This symmetry is lost with cerebellar ataxia (Becker et al., 1991; Gilman et al., 1976).
Figure 4
Distance to target and reach velocity through time for the three configurations.
Thick lines show the average over 48 reaches (8 targets, 6 repetitions). Filled stripes show standard deviation. For the spinal and cortical learning configurations (left and center plots) the hand initially moves quickly to the target, but the direction is biased, so it needs to gradually correct the error from this initial fast approach; most of the variance in error and velocity appears when these corrections cause small-amplitude oscillations. In the case of the static network (right plots) oscillations are ongoing, leading to a large variance in velocity.
We are not aware of center-out reaching studies for cerebellar patients in the dark, but (Day et al., 1998) does examine reaching in these conditions. Summarizing its findings:
Movements were slow.
The endpoints had small variation, but they had constant errors.
Longer, more circuitous trajectories, with most changes in direction during the last quarter.
Trajectories to the same target showed variations.
From Figures 3 and 4 we can observe constant endpoint errors when the gain is low, in the spinal and cortical learning models. Circuitous trajectories with a pronounced turn around the end of the third quarter are also observed. Individual trajectories can present variations. A higher gain, as in the static network on the right plots, can increase these variations, as illustrated in the figure supplements for Appendix 1.
Center-out reaching 2: Directional tuning and preferred directions
To find whether directional tuning could arise during learning, we analyzed the population activity for the 48 radial reaches described in the previous subsection.
For each of the 12 units in , Figure 5A shows the mean firing rate of the unit when reaching each of the 8 targets. The red arrows show the Preferred Direction (PD) vectors that arise from these distributions of firing rates. For the sake of exposition, Figure 5 shows data for the simpler case of one-to-one connectivity between and in the spinal learning model, but these results generalize to the case when each unit receives a linear combination of the activities (the ‘mixed errors’ variation presented in the Variations of the spinal learning model section of the Appendix.)
Figure 5
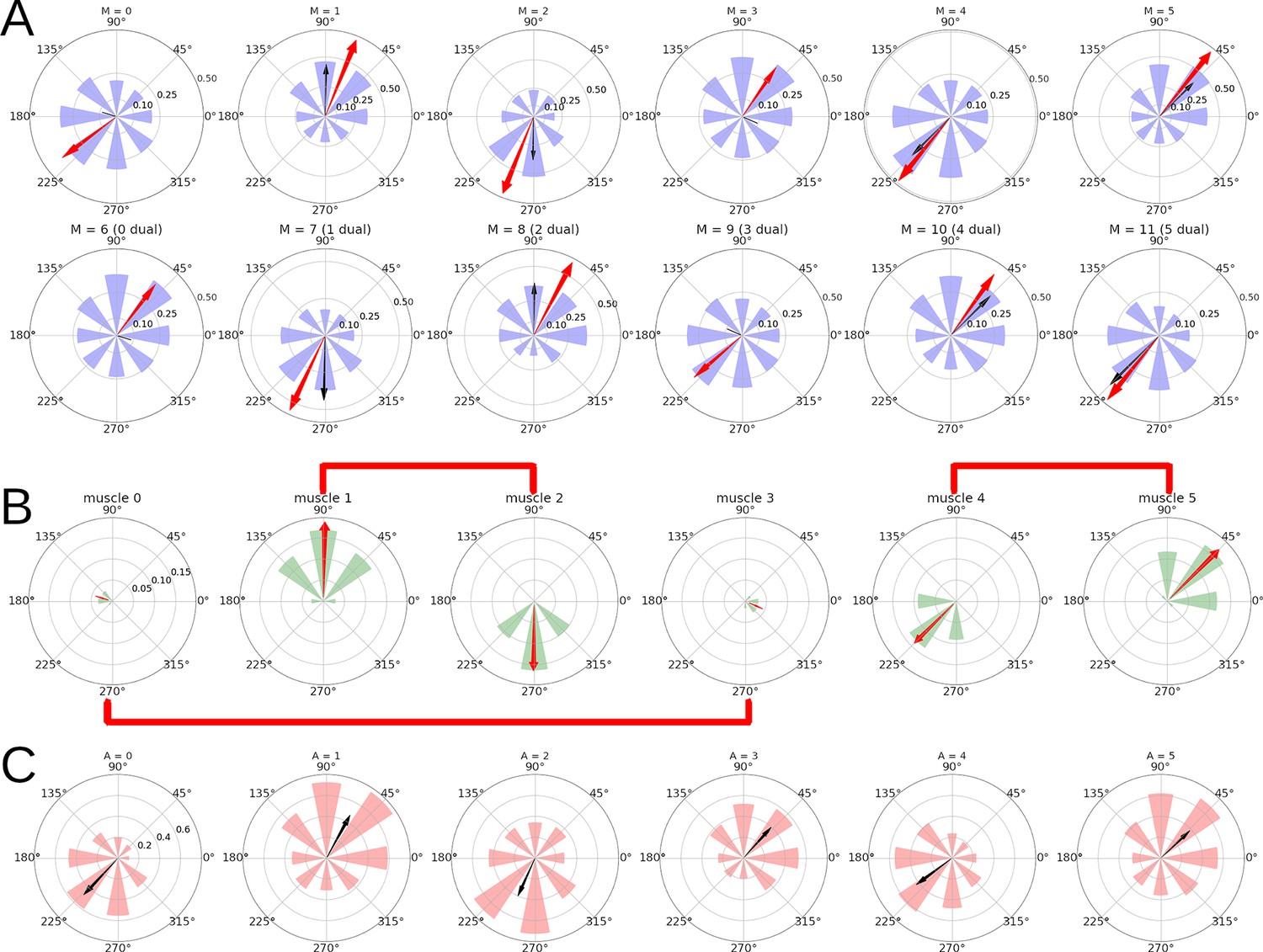
Directional tuning of the units in for a simulation with the spinal learning model.
(A) Average firing rate per target, and preferred direction (see Methods) for each of the 12 units in . Each polar plot corresponds to a single unit, and each of the 8 purple wedges corresponds to one of the 8 targets. The length of a wedge indicates the mean firing rate when the hand was reaching the corresponding target. The red arrow indicates the direction and relative magnitude of the PD vector. The black arrow shows the predicted PD vector, in this case just the corresponding arrows from panel B. (B) For each muscle and target, a wedge shows the muscle’s length at rest position minus the length at the target, divided by the rest position length. The red arrow comes from the sum of the wedges taken as vectors, and represents the muscle’s direction of maximum contraction. Plots corresponding to antagonist muscles are connected by red lines. (C) Average activity of the 6 units indicating muscle tension. The black arrows come from the sum of wedges taken as vectors, showing the relation between muscle tension and preferred direction.
We found that units were significantly tuned to reach direction (, bootstrap test), with PD vectors of various lengths. The direction of the PD vectors is not mysterious. Each unit controls the length error of one muscle. Figure 5B shows that the required contraction length depends on both the target and the muscle. The PD vectors of units 0–5 point to the targets that require the most contraction of their muscle. Units 6–11 are the duals of 0–5, and their PD is in the opposite direction. Figure 5C shows that the PD may also be inferred from the muscle activity, reflected as average tension.
In the case when each unit receives a linear combination of errors, its PD can be predicted using a linear combination of the ‘directions of maximum contraction’ shown in Figure 5B, using the same weights as the inputs. When accounting for the length of the PD vectors, this can predict the PD angle with a coefficient of determination .
As mentioned in the Introduction, the PDs of motor cortex neurons tend to align in particular directions Scott et al., 2001. This is almost trivially true for this model, since the PD vectors are mainly produced by linear combinations of the vectors in Figure 5B.
Figure 6 shows the PD for all the units in a representative simulation for each of the configurations. In every simulation, the PD distribution showed significant bimodality (). The main axis of the PD distribution (see Methods) was degrees.
Figure 6
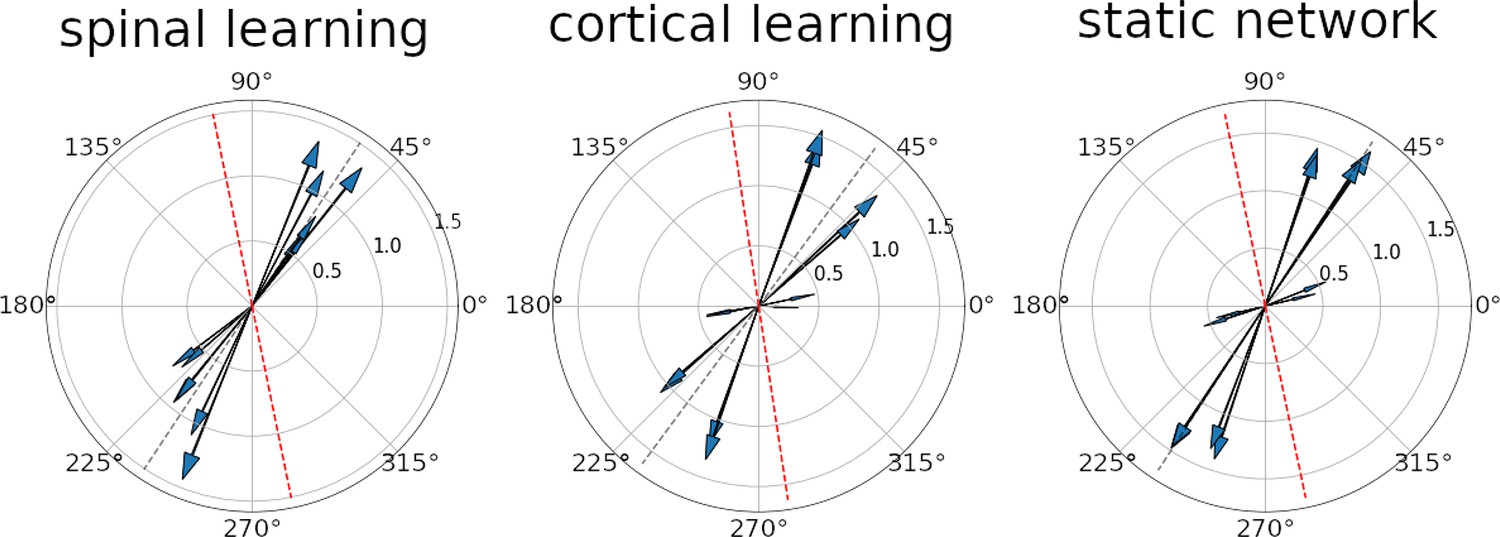
Preferred direction vectors for the 12 units.
In all three plots the arrows denote the direction and magnitude of the preferred direction (PD) for an individual unit. The gray dotted lines shows the main axis of the distribution. The red dotted lines are a 45 degree rotation of the gray line, for comparison with Scott et al., 2001. It can be seen that all configurations display a strong bimodality, especially when considering the units with a larger PD vector. The axis where the PD vectors tend to aggregate is in roughly the same position for the three configurations.
To compare with (Scott et al., 2001) we rotate this line 45 degrees so the targets are in the same position relative to the shoulder (e.g. Lillicrap and Scott, 2013 Figure 1, Kurtzer et al., 2006 Figure 1). This places the average main axes above in a range between 99 and 104 degrees, comparable to the 117 degrees in Scott et al., 2001.
The study in Lillicrap and Scott, 2013 suggested that a rudimentary spinal cord feedback system should be used to understand why the PD distribution arises. Our model is the first to achieve this.
The PD vectors are not stationary, but experience random fluctuations that become more pronounced in new environments (Rokni et al., 2007; Padoa-Schioppa et al., 2004). The brain is constantly remodeling itself, without losing the ability to perform its critical operations (Chambers and Rumpel, 2017). Our model is continuously learning, so we tested the change in the PDs by setting 40 additional center-out reaches (no intrinsic noise) after the previous experiment, once for each configuration.
To encourage changes we set 10 different targets instead of 8. After a single trial for each configuration the change in angle for the 12 PD vectors had means and standard deviations of degrees. Larger changes (around 7 degrees) could be observed in the ‘mixed errors’ variation of the model, presented in the Appendix (Variations of the spinal learning model section). We also measured the change in the preferred directions of the muscles, obtained as in Figure 5C. This yielded differences and standard deviations degrees.
The average distance between hand and target during the 40 reaches was cm, showing that the hand was still moving towards the targets, although with different errors due to their new locations.
Center-out reaching 3: Rotational dynamics
Using a dynamical systems perspective, (Shenoy et al., 2013) considers that the muscle activity (a vector function of time) arises from the cortical activity vector after it is transformed by the downstream circuitry:
(2)
It is considered that the mapping may consist of sophisticated controllers, but for the sake of simplicity this mapping is considered static, omitting spinal cord plasticity. The cortical activity arises from a dynamical system:
(3)
where represents inputs to motor cortex from other areas, and is a function that describes how the state of the system evolves.
A difficulty associated with Equation 3 is explaining how generates a desired muscle pattern when the function represents the dynamics of a recurrent neural network. One possibility is that M1 has intrinsic oscillators of various frequencies, and they combine their outputs to shape the desired pattern. This prompted the search for oscillatory activity in M1 while macaques performed center-out reaching motions. A brief oscillation (in the order of 200ms, or 5 Hz) was indeed found in the population activity (Churchland et al., 2012, and the model in Sussillo et al., 2015) was able to reproduce this result, although this was done in the open-loop version of Equations 2 and 3, where contains no afferent feedback (this is further commented in the Supplemental Discussion).
Recently it was shown that the oscillations in motor cortex can arise when considering the full sensorimotor loop, without the need of recurrent connections in motor cortex (Kalidindi et al., 2021). A natural question is whether our model can also reproduce the oscillations in Churchland et al., 2012 without requiring M1 oscillators or recurrent connections.
The analysis in Churchland et al., 2012 is centered around measuring the amount of rotation in the M1 population activity. The first step is to project the M1 activity vectors onto their first six principal components. These six components are then rotated so the evolution of the activity maximally resembles a pure rotation. These rotated components are called the ‘jPCA vectors’. The amount of variance in the M1 activity explained by the first two jPCA vectors is a measure of rotation. The Methods section provides more details of this procedure.
Considering that we have a low-dimensional, non-spiking, slow-reaching model, we can only expect to qualitatively replicate the essential result in Churchland et al., 2012, which is most of the variance being contained in the first jPCA plane.
We replicated the jPCA analysis, with adjustments to account for the smaller number of neurons, the slower dynamics, and the fact that there is no delay period before the reach (See Methods). The result can be observed in Figure 7, where 8 trajectories are seen in the plots. Each trajectory is the average activity of the 12 units when reaching to one of the 8 targets, projected onto the jPCA plane. The signature of a rotational structure in these plots is that most trajectories circulate in a counterclockwise direction. Quantitatively, the first jPCA plane (out of six) captures of the variance.
Figure 7
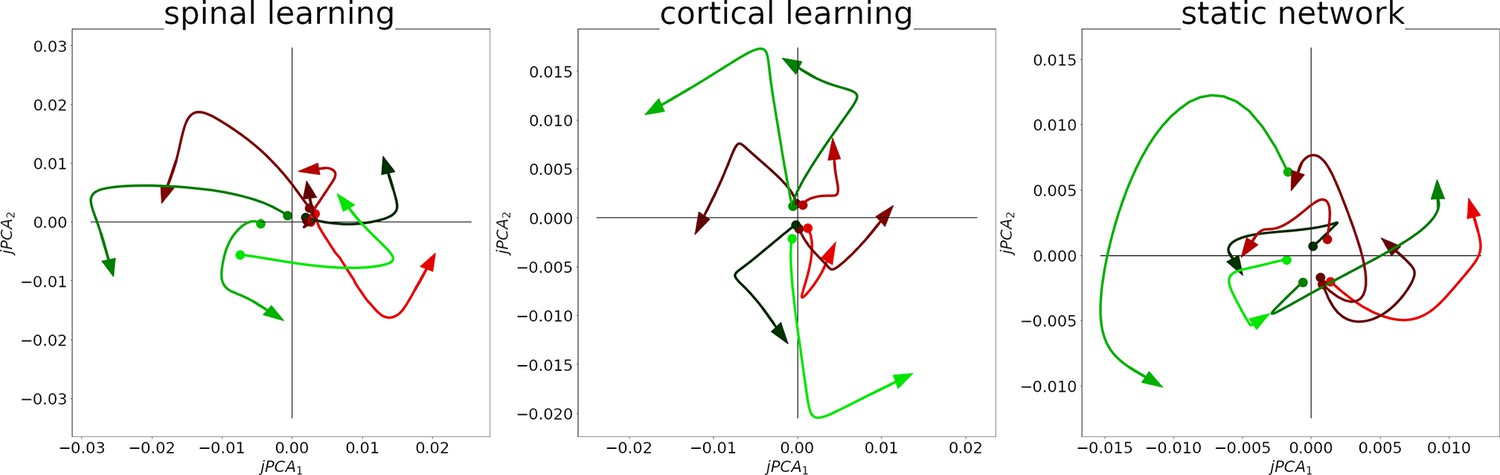
Rotational dynamics in the M population in a representative simulation for all configurations.
Each plot shows the first two jPCA components during 0.25 s, for each of the 8 conditions/targets. Traces are colored according to the magnitude of their initial component, from smallest (green) to largest (red).
With this analysis we show that our model does not require intrinsic oscillations in motor cortex to produce rotational dynamics, in agreement with (Kalidindi et al., 2021 and DeWolf et al., 2016).
The effect of changing the mass
Physical properties of the arm can change, not only as the arm grows, but also when tools or new environments come into play. As a quick test of whether the properties in this paper are robust to moderate changes, we changed the mass of the arm and forearm from 1 to 0.8 kg and ran one simulation for each of the five configurations.
With a lighter arm the average errors during center-out reaching were cm. The hand trajectories with a reduced mass can be seen in the top 3 plots of Figure 8. We can observe that the spinal learning model slightly reduced its mean error, whereas the cortical learning model increased it. This can be understood by noticing that a reduction in mass is akin to an increase in gain. The spinal learning model with its original gain was below the threshold of oscillations at the endpoint, and a slight mass decrease did not change this. The cortical learning model with the original gain was already oscillating slightly, and an increase in gain increased the oscillations.
Figure 8
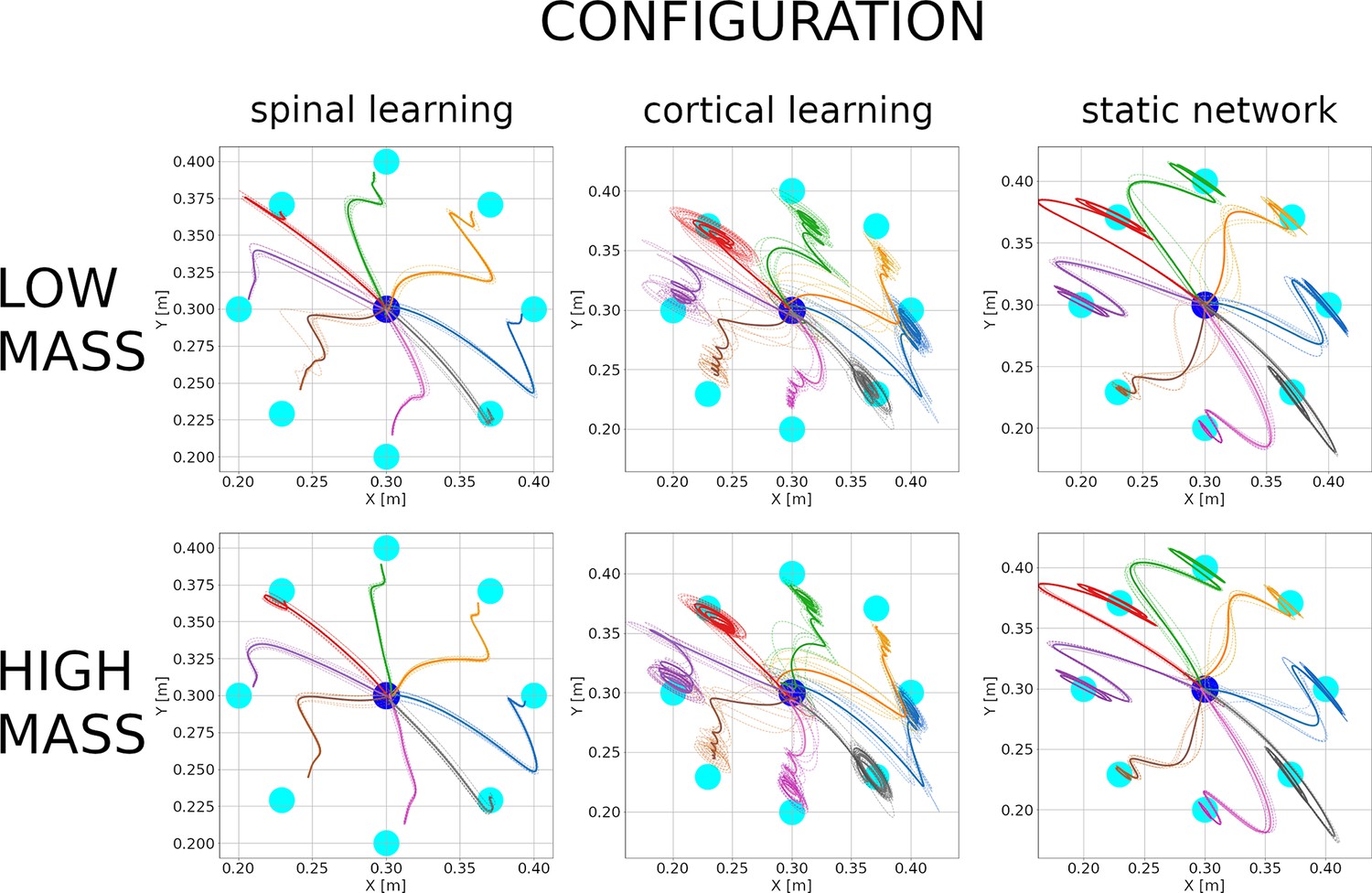
Hand trajectories with low mass (0.8 kg, top 3 plots) and high mass (1.2 kg, bottom 3 plots) for the 3 configurations.
Plots are as in Figure 3. The spinal learning model and the static network show qualitatively similar trajectories compared to those in Figure 3. In contrast, the cortical learning model began to display considerable endpoint oscillations for several targets after its mass was reduced. These oscillations persist after the mass has been increased.
In the same simulation, after the center-out reaching was completed, we once more modified the mass of the arm and forearm, from 0.8 to 1.2 kg, after which we began the center-out reaching again. This time the center-out reaching errors were cm. The hand trajectories for this high mass condition are in the bottom 3 plots in Figure 8. It can be seen that the spinal learning and cortical learning models retained their respectively improved and decreased performance, whereas the static network performed roughly the same for all mass conditions. A tentative explanation is that with reduced mass the synaptic learning rules tried to compensate for faster movements with weights that effectively increased the gain in the loop. After the mass was increased these weights did not immediately revert, leading to similar trajectories after the increase in mass.
The results of the paper still held after our mass manipulations. For all configurations, PD vectors could be predicted with a coefficient of determination between.74 and.92; All units in were significantly tuned to direction; the main axis of the PD distribution ranged between 56 and 61 degrees, and the first jPCA plane captured between 33% and 58% of the variance.
Spinal stimulation produces convergent direction fields
Due to the viscoelastic properties of the muscles, the mechanical system without active muscle contraction will have a fixed point with lowest potential energy at the arm’s rest position. Limited amounts of muscle contraction shift the position of that fixed point. This led us to question whether this could produce convergent force fields, which as discussed before are candidate motor primitives, and have been found experimentally.
To simulate local stimulation of an isolated spinal cord we removed all neuronal populations except for those in , and applied inputs to the individual pairs of units projecting to the same motoneuron. Doing this for different starting positions of the hand, and recording its initial direction of motion, produces a direction field. A direction field maps each initial hand location to a vector pointing in the average direction of the force that initially moves the hand.
The first two panels of Figure 9 show the result of stimulating individual E-I pairs in , which will indeed produce direction fields with different fixed points.
Figure 9
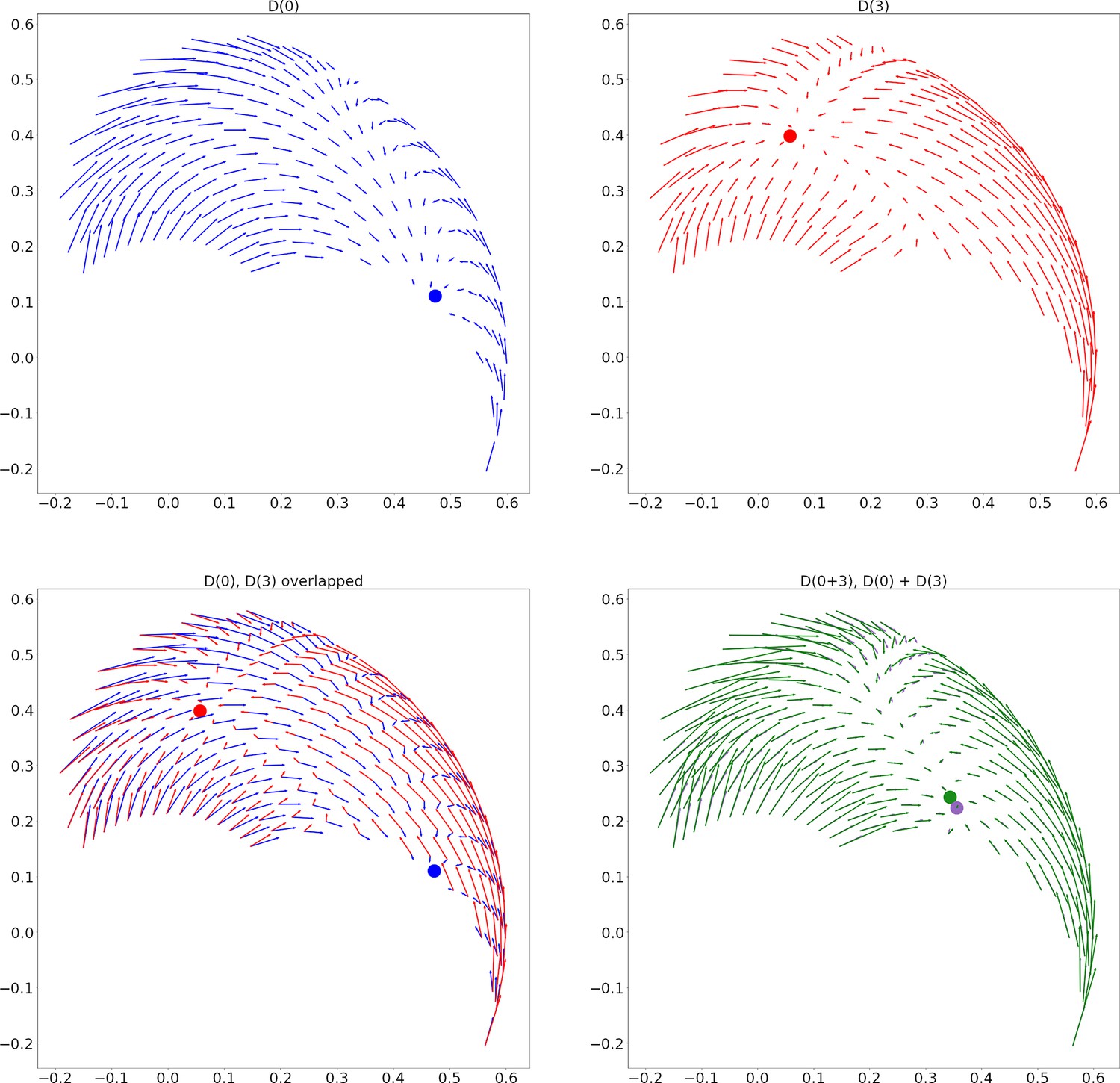
Two sample direction fields and their linear addition for circuit C1.
(A) Direction Field (DF) from stimulation of the interneurons for muscle 0 (biarticular biceps). The approximate location of the fixed point is shown with a blue dot. (B) DF from stimulation of muscle 3 (biarticular triceps) interneurons. A red dot shows the fixed point. (C) Panels A and B overlapped. (D) In green, the DF from stimulating the interneurons for muscles 0 and 3 together. In purple, the sum of the DFs from panels A and B. Dots show the fixed points. The average angle between the green and purple vectors is 4 degrees.
We found that these direction fields add approximately linearly (Figure 9D). More precisely, let be the direction field from stimulating spinal locations and simultaneously, and be the angle of at hand coordinates . Using similar definitions for , we say the direction fields add linearly if .
We define the mean angle difference between and as
(4)
where is the number of sample points. We found that when averaged over the 15 (C1) or 144 (C2) possible pairs, the mean of was 13.5 degrees.
Randomly choosing two possibly different pairs and for the stimulation locations leads to a mean angle difference of 37.6 degrees between the fields and . A bootstrap test showed that these angles are significantly larger () than in the previous case where .
The resting field is defined as the direction field when no units are stimulated. Removing the resting field from , and does not alter these results.
Recent macaque forelimb experiments (Yaron et al., 2020) show that the magnitude of the vectors in the fields is larger than expected from (supralinear summation). We found no evidence for this effect, suggesting that it depends on mechanisms beyond those present in our model.
Discussion
Summary of findings and predictions
We have presented a model of the long loop reflex with a main assumption: negative feedback configured with two differential Hebbian learning rules. One novel rule sets the loop’s input-output structure, and the other rule (input correlation) promotes stability. We showed that this model can make arm reaches by trying to perceive a given afferent pattern.
Our study made two main points:
Many experimental phenomena emerge from a feedback controller with minimally-complete musculoskeletal and neural models (emphasis is placed on the balance between excitation and inhibition).
Even if the feedback controller has multiple inputs and outputs, its input-output structure can be flexibly configured by a differential Hebbian learning rule, as long as errors are monotonic.
The first main point above was made using a feedback control network with no learning (called the static network in the Results). We showed that in this static network: (1) reaching trajectories are similar to models of cerebellar ataxia, (2) motor cortex units are tuned to preferred directions, (3) those preferred directions follow a bimodal distribution, (4) motor cortex units present rotational dynamics, (5) reaching is still possible when mass is altered, and (6) spinal stimulation produces convergent direction fields.
The second main point was made using two separate models, both using the same differential Hebbian learning rules, but applied at different locations. The spinal learning model presents the hypothesis that the spinal cord learns to adaptively configure the input-output structure of the feedback controller. The cortical learning model posits that configuring this structure could instead be a function of motor cortex; this would not disrupt our central claims. These two models should not be considered as incompatible hypotheses. Different elements performing overlapping functions are common in biological systems (Edelman and Gally, 2001).
Two variations of the spinal learning model in the Appendix show that this learning mechanism is quite flexible, opening the doors for certain types of synergies, and for more complex errors (that still maintian the constraint of monotonicity).
We list some properties of the model, and possible implications:
Basic arm reaching happens through negative feedback, trying to perceive a target value set in cortex. Learning the input-output structure of the feedback controller may require spinal cord plasticity.
Cerebellar patients should not be able to adapt to tasks that require fast reactions, as negative feedback alone cannot compensate for delays in the system (Sanguineti et al., 2003). On the other hand, they should be able to learn tasks that require remapping afferent inputs to movements. One example is Richter et al., 2004, where cerebellar patients learned to move in a novel dynamic environment, but their movements were less precise than those of controls.
The shape of reaches is dominated by mechanical and viscoelastic properties of the arm and muscles.
Unfamiliar viscous forces as in Richter et al., 2004 should predictably alter the trajectory (Figure 3) for cerebellar patients, who should not be able to adapt unless they move slowly and are explicitly compensating.
Preferred Directions (PDs) in motor cortex happen because muscles need to contract more when reaching in certain directions.
The PD distribution should align with the directions where the muscles need to contract to reduce the error. These directions depend on which error is encoding. If the error is not related to reaching (e.g. related to haptic feedback), a different PD distribution may arise after overtraining.
Drift in the PD vectors comes from the ongoing adaptation, and it should not disrupt performance.
The oscillations intrinsic to delayed feedback control after the onset of a target are sufficient to explain the quasi-oscillations observed in motor cortex (Churchland et al., 2012; Kalidindi et al., 2021).
Convergent force fields happen naturally in musculoskeletal systems when there is balance in the stimulation between agonists and antagonists. Linear addition of force fields is a result of forces/torques adding linearly.
Since our relatively simple model reproduces these phenomena, we believe it constitutes a good null hypothesis for them. But beyond explaining experimental observations, this model makes inroads into the hard problem of how the central nervous system (CNS) can generate effective control signals, recently dubbed the ‘supraspinal pattern formation’ problem (Bizzi and Ajemian, 2020). From our perspective, the CNS does not need to generate precise activation patterns for muscles and synergies; it needs to figure out which perceptions need to change. It is subcortical structures that learn the movement details. The key to make such a model work is the differential Hebbian learning framework in Verduzco-Flores et al., 2022, which handles the final credit assignment problem.
We chose not to include a model of the cerebellum at this stage. Our model reflects the brain structure of an infant baby who can make clumsy reaching movements. At birth the cerebellum is incomplete and presumably not functional. It requires structured input from spinal cord and cortex to establish correct synaptic connections during postnatal development and will contribute to smooth reaching movements at a later age.
Encompassing function, learning, and experimental phenomena in a single simple model is a promising start towards a more integrated computational neuroscience. We consider that such models have the potential to steer complex large-scale models so they can also achieve learning and functionality from scratch.
Methods
Simulations were run in the Draculab simulator (Verduzco-Flores and De Schutter, 2019). All the parameters from the equations in this paper are presented in the Appendix. Parameters not shown can be obtained from Python dictionaries in the source code. This code can be downloaded from: https://gitlab.com/sergio.verduzco/public_materials/-/tree/master/adaptive_plasticity.
Unit equations
With the exception of the and populations, the activity ui of any unit in Figure 1 has dynamics:
(5)
(6)
where is a time constant, is the slope of the sigmoidal function, is its threshold, and is the sum of delayed inputs times their synaptic weights.
Units in the populations (in the spinal learning model) or in (in the cortical learning model) had an additional noise term, which turned Equation 5 into this Langevin equation:
(7)
where is a Wiener process with unit variance, and is a parameter to control the noise amplitude. This equation was solved using the Euler-Maruyama method. All other unit equations were integrated using the forward Euler method. The equations for the plant and the muscles were integrated with SciPy’s (https://scipy.org/) explicit Runge-Kutta 5(4) method.
Units in the population use a rectified logarithm activation function, leading to these dynamics for their activity:
(8)
where is a time constant, is the scaled sum of inputs, is a threshold, and is the "positive part" function.
Learning rules
The learning rule for the connections from to units in the spinal learning model was first described in Verduzco-Flores et al., 2022. It has an equation:
(9)
In this equation, represents the activity of the -th unit in at time , and is its second derivative. Angle brackets denote averages, so that , where is the number of units. is the derivative of the activity for the postsynaptic unit, and is a time delay ensuring that the rule captures the proper temporal causality. In the Supplementary Discussion of the Appendix we elaborate on how such a learning rule could be present in the spinal cord.
The learning rule in 9 was also fitted with soft weight-bounding to prevent connections from changing sign, and multiplicative normalization was used to control the magnitude of the weights by ensuring two requirements: (1) all weights from projections of the same unit should add to , (2) all weights ending at the same unit should add to . With this, the learning rule adopted the form:
(10)
In this equation is a constant learning rate, is the right-hand side expression of Equation 9, and is a scalar parameter. The value is divided by the sum of outgoing weights from the -th unit, and is divided by the sum of incoming weights on ci. This type of normalization is meant to reflect the competition for resources among synapses, both at the presynaptic and postsynaptic level.
The synapses in the connections from to and from to used the input correlation rule (Porr and Wörgötter, 2006):
(11)
where is the scaled sum of inputs from the population, is the learning rate, is the scaled sum of inputs from or , and is its derivative. Unlike the original input correlation rule, this rule uses soft weight bounding to avoid weights changing signs. Moreover, the sum of the weights was kept close to a value. In practice this meant dividing the each individual value by the sum of weights from -to- (or -to-) connections, and multiplying times at each update. In addition, weight clipping was used to keep individual weights below a value .
The learning rule in the cortical learning model was the same, but the presynaptic units were in , and the postsynaptic units in .
Exploratory mechanism
Without any additional mechanisms the model risked getting stuck in a fixed arm position before it could learn. We included two mechanisms to permit exploration in the system. We describe these two mechanisms as they were applied to the spinal learning model and its two variations. The description below also applies to the case of the cortical learning model, with the units (instead of the units) receiving the noise and extra connections.
The first exploratory mechanism consists of intrinsic noise in the and interneurons, which causes low-amplitude oscillations in the arm. We have observed that intrinsic oscillations in the units are also effective to allow learning (data not shown), but the option of intrinsic noise permits the use of simple sigmoidal units in , and contributes to the discussion regarding the role of noise in neural computation.
The second mechanism for exploration consists of an additional unit, called . This unit acted similarly to a leaky integrator of the total activity in , reflecting the total error. If the leaky integral of the activity crossed a threshold, then would send a signal to all the and units, causing adaptation. The adaptation consisted of an inhibitory current that grew depending on the accumulated previous activity.
To model this, and units received an extra input . When the input from the unit was larger than 0.8, and , the value of would be set to . This is the square of a low-passed filtered version of ui. More explicitly,
(12)
If the input from was smaller than 0.8, or became larger than 0.2, then would decay towards zero:
(13)
With this mechanism, if the arm got stuck then error would accumulate, leading to adaptation in the spinal interneurons. This would cause the most active interneurons to receive the most inhibition, shifting the ‘dominant’ activities, and producing larger amplitude exploratory oscillations.
When a new target is presented, must reset its own activity back to a low value. Given our requirement to fully implement the controller using neural elements, we needed a way to detect changes in . A unit denominated can detect these changes using synapses that react to the derivative of the activity in units. was connected to in order to reset its activity.
More precisely, when inputs from were larger than 0.1, the activity of had dynamics:
(14)
Otherwise it had these dynamics:
(15)
(16)
As before, is a sigmoidal function, and is the scaled sum of inputs other than . When is smaller than a threshold the value of actually decreases, as this error is deemed small enough. When the activity increases, but the rate of increase is modulated by a rate of increase , where is a low-pass filtered version of is a constant parameter.
was a standard sigmoidal unit receiving inputs from , with each synaptic weight obeying this equation:
(17)
where sj represents the synapse’s presynaptic input.
Plant, muscles, afferents
The planar arm was modeled as a compound double pendulum, where both the arm and forearm were cylinders with 1 kg. of mass. No gravity was present, and a moderate amount of viscous friction was added at each joint (3 ). The derivation and validation of the double pendulum’s equations can be consulted in a Jupyter notebook included with Draculab’s source code (in the tests folder).
The muscles used a standard Hill-type model, as described in Shadmehr and Wise, 2005, Pg. 99. The muscle’s tension obeys:
(18)
where is the input, an input gain, the parallel elasticity constant, the series elasticity constant, is the damping constant for the parallel element, is the length of the muscle, and . In here, is the resting length of the series element, whereas is the resting length of the parallel element. All resting lengths were calculated from the steady state when the hand was located at coordinates (0.3, 0.3).
We created a model of the Ia and II afferents using simple structural elements. This model includes, for each muscle one dynamic nuclear bag fiber, and one static bag fiber. Both of these fibers use the same tension equation as the muscle, but with different parameters. For the static bag fiber:
(19)
The dynamic bag fiber uses the same equation, with the superscript replaced by . No inputs were applied to the static or dynamic bag fibers, so they were removed from these equations. The rest lengths of the static and dynamic bag fibers where those of their corresponding muscles times factors , respectively.
The Ia afferent output is proportional to a linear combination of the lengths for the serial elements in both dynamic and static bag fibers. The II output has two components, one proportional to the length of the serial element, and one approximately proportional to the length of the parallel element, both in the static bag fiber. In practice this was implemented through the following equations:
(20)
(21)
In here, and are gain factors. and are constants determining the fraction of and output that comes from the serial element.
The model of the Golgi tendon organ producing the Ib outputs was taken from Lin and Crago, 2002. First, a rectified tension was obtained as:
(22)
is a gain factor, T0 is a constant that can further alter the slope of the tension, and is the tension, half-rectified. The afferent output followed dynamics:
(23)
Static connections
In all cases, the connections to used one-to-one connectivity with the units driven by the II afferents, whereas connections from to and used all-to-all projections from the units driven by the Ia and Ib afferents. Projections from to used one-to-one excitatory connections to the first 6 units, and inhibitory projections to the next six units. Projections from to used the opposite sign from this.
Connections from to were one-to-one, so the -th unit in only sent a projection to unit in . A variation of this connectivity is presented in the Appendix (See Variations of the spinal learning model).
We now explain how we adjusted the synaptic weights of the static network. To understand the projections from to and to the alpha motoneurons it is useful to remember that each trio is associated with one muscle, and the units also control the error of a single muscle. This error indicates that the muscle is longer than desired. Thus, the unit associated with muscle sent excitatory projections to the and units associated with muscle , and to the units of the antagonists of . Additionally, weaker projections were sent to the units of muscle ’s agonists. Notice that only excitatory connections were used.
The reverse logic was used to set the connections from to and . If muscle is tensing or elongating, this can predict an increase in the error for its antagonists, which is the kind of signal that the input correlation rule is meant to detect. Therefore, the afferent (signaling tension) of muscle sent an excitatory signal to the unit associated with muscle , and to the units associated with ’s antagonists. Moreover, this afferent also sent an excitatory projection to the dual of the unit associated with muscle . Connections from afferents (roughly signaling elongation speed) followed the same pattern, but with slightly smaller connection strengths.
Rotational dynamics
We explain the method to project the activity of onto the jPCA plane. For all units in we considered the activity during a 0.5 s sample beginning 50 ms after the target onset. Unlike (Churchland et al., 2012), we did not apply PCA preprocessing, since we only have 12 units in . Let be the activity at time of the unit in , when reaching at target for the -th repetition. By we denote the average over all repeated reaches to the same target, and by we indicate averaging over both targets and repetitions. The normalized average trace per condition is defined as: . Let stand for the number of units in , for the number of time points, and for the number of targets. Following (Churchland et al., 2012), we unroll the set of values into a matrix , so we may represent the data through a matrix that provides the least-squares solution to the problem . This solution comes from the equation . Furthermore, this matrix can be decomposed into symmetric and anti-symmetric components . The jPCA plane comes from the complex conjugate eigenvalues of .
In practice, our source code follows the detailed explanation provided in the Supplementary Information of Churchland et al., 2012, which reformulates this matrix problem as a vector problem.
Parameter search
We kept all parameter values in a range where they still made biological sense. Parameter values that were not constrained by biological data were adjusted using a genetic algorithm, and particle swarm optimization (PSO). We used a separate optimization run for each one of the configurations, consisting of roughly 30 iterations of the genetic and PSO algorithms, with populations sizes of 90 and 45 individuals respectively. After this we manually adjusted the gain of the control loop by increasing or decreasing the slope of the sigmoidal units in the and populations. This is further described in the Appendix (Gain and oscillations section).
The parameters used can affect the results in the paper. We chose parameters that minimized either the error during the second half of the learning phase, or the error during center-out reaching. Both of these measures are agnostic to the other results.
Preferred direction vectors
Next we describe how PD vectors were obtained for the units.
Let denote the firing rate of the -th unit when reaching for the -th target, averaged over 4 s, and across reaches to the same target. We created a function that mapped the X,Y coordinates of each target to its corresponding value, but in the domain of hj the coordinates were shifted so the center location was at the origin.
Next we approximated hj with a plane, using the least squares method, and obtained a unit vector uj normal to that plane, starting at the intersection of the -axis and the plane, and pointing towards the XY plane. The PD vector was defined as the projection of uj on the XY plane.
In order to predict the PD vectors, we first obtained for each muscle the ‘direction of maximum contraction’, verbally described in panel B of Figure 5. More formally, let denote the length of the -th muscle when the hand is at target , and let denote its length when the hand is at the center location. With we denote the unit vector with base at the center location, pointing in the direction of the -th target. The direction of maximum length change for the -th muscle comes from the following vector sum:
(24)
where .
For the -th unit in , its predicted PD vector comes from a linear combination of the vectors. Let the input to this unit be , where ei is the output of the -th SPF unit (representing the error in the -th muscle). The predicted PD vector is:
(25)
To obtain the main axis of the PD distribution, the -th PD vector was obtained in the polar form , with . We reflected vectors in the lower half using the rule: if otherwise. The angle of the main axis was the angle of the average PD vector using these modified angles: .
Statistical tests
To find whether units were significantly tuned to the reach direction we used a bootstrap procedure. For each unit we obtained the length of its PD vector 10,000 times when the identity of the target for each reach was randomly shuffled. We considered there was significant tuning when the length of the true PD vector was longer than 99.9% of these random samples.
To obtain the coefficient of determination for the predicted PD angles, let denote the angle of the true PD for the -th unit, and be the angle of its predicted PD. We obtained residuals for the angles as , where this difference is actually the angle of the smallest rotation that turns one angle into the other. Each residual was then scaled by the norm of its corresponding PD vector, to account for the fact that these were not homogeneous. Denoting these scaled residuals as the residual sum of squares is . The total sum of squares was: , where is the mean of the angles. The coefficient of determination comes from the usual formula .
To assess bimodality of the PD distribution we used a version of the Rayleigh statistic adapted to look for bimodal distributions where the two modes are oriented at 180 degrees from each other, introduced in Lillicrap and Scott, 2013. This test consists of finding an modified Rayleigh statistic defined as:
(26)
where the angles are the angles for the PDs. A bootstrap procedure is then used, where this statistic is produced 100,000 times by sampling from the uniform distribution on the interval. The PD distribution was deemed significantly bimodal if its value was larger than 99.9% of the random values.
We used a bootstrap test to find whether there was statistical significance to the linear addition of direction fields. To make this independent of the individual pair of locations stimulated, we obtained the direction fields for all 15 possible pairs of locations, and for each pair calculated the mean angle difference between and as described in the main text. We next obtained the mean of these 15 average angle deviations, to obtain a global average angle deviation .
We then repeated this procedure 400 times when the identities of the stimulation sites were shuffled, to obtain 400 global average angle deviations . We declared statistical significance if was smaller than 99% of the values.
Appendix 1
Supplementary discussion
Comparison with previous models
There are many other models of reaching and motor control. Most of them have one or more of the following limitations:
They use non-neural systems to produce motor commands.
They control a single degree of freedom, sidestepping the problem of controller configuration, since the error is one-dimensional.
They do not model a biologically plausible form of synaptic learning.
We will contrast our model with some of the work that does not strongly present these limitations, and with a few others. Due to space constraints the contributions of many models will not be addressed, and for those mentioned we will limit ourselves to explain some of their limitations.
The model in DeWolf et al., 2016 is similar has similar goals to our model, but with very different assumptions. In their model, motor cortex receives a location error vector , and transforms it into a vector of joint torques. So that this transformation implements adaptive kinematics, it must approximate a Jacobian matrix that includes the effects of the arm’s inertia matrix, using location errors and joint velocities as training signals. This is accomplished by adapting an algorithm taken from the robotics literature (Cheah et al., 2006), implementing it in a spiking neural network. Additionally a second algorithm from robotics (Sanner and Slotine, 1992) is used to provide an adaptive dynamics component, which is interpreted as the cerebellar contributions.
In order to implement vector functions in spiking neural networks, DeWolf et al., 2016 uses the Neural Engineering Framework (Bekolay et al., 2014). The essence of this approach is to represent values in populations of neurons with cosine-like tuning functions. These populations implement expansive recoding, becoming a massively overcomplete basis of the input space. Implementing a function using this population as the input is akin to using a linear decoder to extract the desired function values from the population activity. This can be done through standard methods, such as least-squares minimization, or random gradient descent. The parameters of the linear decoder then become weights of a feedforward neural layer implementing the function.
The model in DeWolf et al., 2016 has therefore a rather different approach. They use engineering techniques to create a powerful motor control system, using algorithms from robotics, and 30,000 neurons to approximate their computations, which are then ascribed to sensory, motor, and premotor cortices, as well as the cerebellum. In contrast, we use 74 firing rate units, and unlike (DeWolf et al., 2016) we include muscles, muscle afferents, transmission delays, and a spinal cord.
There is nothing intrinsically wrong with using an engineering approach to try to understand a biological function. The crucial part is which model will be experimentally validated. Some differences between the models that may be able to separate them experimentally are: (1) In DeWolf et al., 2016 premotor cortex is required to produce the error signal, whereas we ascribed this to sensory cortex. (2) In DeWolf et al., 2016 direct afferent connections to motor cortex are not considered, whereas in our model they are important to maintain stability during learning (in the absence of a cerebellum). (3) In DeWolf et al., 2016 spinal cord adaptation is not necessary to implement adaptive kinematics. In contrast, spinal cord adaptation is important in one of the interpretations of our model.
The model in Dura-Bernal et al., 2015 uses spiking neurons, and a realistic neuromechanical model in order to perform 2D reaching. The feedback is in term of muscle lengths, rather than muscle afferent signals. There is no mechanism to stop the arm, or hold it on target. Most importantly, learning relies on a critic, sending rewarding or punishing signals depending on whether the hand was approaching or getting away from the target. This is implicitly reducing the error dimension using a hidden mechanism. Furthermore, each single target must be trained individually, and it is not discussed how this can lead to a flexible reaching mechanism without suffering from catastrophic interference.
The model in Todorov, 2000 is used to obtain characteristics of M1 activity given the required muscle forces to produce a movement. It is an open-loop, locally-linear model, where all connections from M1 directly stimulate a linear motoneuron. Among other things, it showed that representations of kinematic parameters can appear when the viscoelastic properties of the muscles are taken into account, giving credence to the hypothesis that M1 directly activates muscle groups. Outside of its scope are neural implementation, learning, or the role of spinal cord.
Li et al., 2005 proposes a 2-level hierarchical controller for a 2-DOF arm. Since this model is based on optimal control theory, it is given a cost function, and proceeds by iteratively approaching a solution of the associated Jacobi-Bellman equation. There is no neural implementation of these computations, nor a description of learning.
Martin et al., 2009 is not properly a neural model, but it is rooted in Dynamic Field Theory, which assumes that the population of neuronal activities encodes "activation variables". For this model activation variables represent kinematic parameters as a virtual joint location vector , which is an internal representation of the arm’s configuration.
The innovative part of Martin et al., 2009 is in describing how is updated and used to control a redundant manipulator. In particular, the kinematic Jacobian, its null-space matrix, their derivatives, and the Moore-Penrose pseudoinverse are all computed analytically in order to obtain differential equations where the joint motions that move the end effector decouple from those which don’t.
Encapsulating the muscle commands into a virtual joint location whose dynamics are decoupled for motions that don’t affect the end-effector location is a very interesting concept. Still, this is far from a neural implementation, and learning is not considered.
The model in Caligiore et al., 2014 studies the long-term development of infant reaching using a PD controller, and an actor critic mechanism implementing a neural version of TD-learning (Sutton and Barto, 2018). The 2-dimensional PD controller receives two desired joint angles (interpreted as an equilibrium position), producing appropriate torques. Since it uses the Equilibrium Point (EP) Hypothesis (Feldman, 1986), the reaching portion of this model is tantamount to associating states with equilibrium positions. This model thus performs at a higher level of analysis. Our model could operate at the same level if we added a reinforcement learning component to learn values allowing the hand to touch a target whose distance is known. (Caligiore et al., 2014) does not consider separate neuronal populations (e.g. spinal cord, sensory cortex), propagation delays, or low-level learning.
The model in Izawa et al., 2004 shows how reinforcement learning can be applied to redundant actuators, such as biological arms. It is, however, not a neural model.
In Mici et al., 2018, a neural network produces predictions of visual input in order to deal with temporal delays in a sensorimotor system. The network used for this study uses non-local learning, and adds or destroys nodes as required during its operation. It is thus not biologically-plausible.
Tsianos et al., 2014 is a reaching model that also considers the spinal cord as a highly-configurable controller. Corticospinal inputs are assumed to be step commands, which means that motor cortex operates in an open-loop configuration. In order to produce reaching based on these constant commands, a biologically-implausible gradient descent mechanism is required, where the same reach is performed for various values of a synaptic weight, keeping the value that led to the best performance. Furthermore, the model learns to reach one target at a time, which would require learning anew when the new target is more than 45 degrees apart.
As mentioned in the main text, in the context of rotational dynamics, the model in Sussillo et al., 2015 was used to produce desired muscle forces using a recurrent neural network. This model uses the FORCE algorithm (Sussillo and Abbott, 2009) to adjust the weights of a neural network with activity vector so it can produce experimentally observed muscle activity . Oscillatory dynamics arise when the model is constrained to be simple.
Although very insightful, this model is limited by the fact that Equations 2 and 3 represent an open-loop configuration, where only the M1 dynamics are considered. In essence, the model is doing a function approximation with the FORCE algorithm. The question of how the training data is produced is not addressed, nor is the role of spinal cord or sensory cortex (but see their Supplementary Figure 1).
Other than the aforementioned model in Tsianos et al., 2014, we are unaware of spinal cord models addressing arm reaching. When these models are coupled with a musculoskeletal system, it is usually for the control of one degree of freedom using antagonistic neural populations. We mention some examples next.
The spinal cord model in Bashor, 1998 inspired much of the subsequent work, organizing the spinal circuit into six pairs of populations controlling two antagonistic muscle groups at one joint. With this model, the effect of Ia and Ib afferent input was studied in various neuronal populations.
Stienen et al., 2007 used a model similar to that in Bashor, 1998 in conjunction with a one DOF musculoskeletal model to study the effect of Ia afferents in the modulation of reflexes. Cutsuridis, 2007 also adapted a similar model, and used it to inquire whether Parkinsonian rigidity arose from alterations in reciprocal inhibition mediated by reduced dopamine.
The model in Cisi and Kohn, 2008 has several features not found in Bashor, 1998, including a heterogeneous motoneuron population, and a mechanism to generate electromyograms. This was used to study the generation of the H-reflex, and response properties of the motor neuron pool (Farina et al., 2014).
The model in Shevtsova et al., 2015 goes beyond models such as Bashor, 1998 by using populations of genetically-identified interneurons. This model is used to study rhythm generating abilities of the spinal circuit, as well as coordination between flexors and extensors (Shevtsova and Rybak, 2016; Danner et al., 2017). Knowledge regarding the role of genetically identified spinal interneurons in movement generation is still evolving (Zelenin et al., 2021; Stachowski and Dougherty, 2021, e.g.).
This paper focuses on mammals, but the spinal cord of simpler organisms is better characterized (Borisyuk et al., 2011; Cangiano and Grillner, 2005, e.g.), and may lead to the first realistic models producing ethological behavior.
Possible implementations of the learning rule
The learning rule in Equation 9 is a Hebbian rule that also presents derivatives, heterosynaptic competition, and normalization (e.g. removing the mean) of its terms. None of these is new in a model claiming biological plausibility (Porr and Wörgötter, 2006; Zappacosta et al., 2018; Fiete et al., 2010; Kaleb et al., 2021, e.g.). We nevertheless mention possible ways for derivatives and normalized terms to appear.
Formally, the time derivative of a function evaluated at time is the limit as . If represents the firing rate of a cell, a measure of change roughly proportional to the derivative can come from for some small value . The most obvious way that such a difference may arise is through feedforward inhibition (for the ej signal), and feedback inhibition (for the ci signal). Feedforward and feedback inhibition are common motifs in spinal circuits (Pierrot-Deseilligny and Burke, 2005).
A somewhat different way to approach a time derivative is by using two low-pass filters with different time constants:
where
These principles are illustrated in Lim and Goldman, 2013, where they are used to explain negative-derivative feedback.
Low-pass filtering can also arise in the biochemical cascades following synaptic depolarization. The most salient case is intracellular calcium concentration, which has been described as an indicator of firing rate with leaky integrator dynamics (Helmchen, 1999). Although the physiology of spinal interneurons has not been characterized with sufficient detail to make specific hypotheses, it is clearly possible that feedback inhibition and low-pass filtering are enough to approximate a second-order derivative.
The terms in our learning rule are mean-centered. The most straightforward way to subtract a mean is to have inhibitory units with converging inputs (e.g. receiving all the ej signals) providing input to the ci units. The Ib interneurons (Pierrot-Deseilligny and Burke, 2005) are one possibility for mediating this. Another possibility is that the mean-subtraction happens at the single unit level when the input (ej) and lateral (ci) connections are located at different parts of the dendritic tree. In particular, a larger level of overall input activation could produce a scarcity of postsynaptic resources flowing from the main branches of the dendritic tree into the individual dendritic spines, resulting in reduced plasticity.
Limitations of the model
A model as simple as ours will undoubtedly be wrong in many details. The main simplifying assumptions of our model are:
Firing rate encoding. Each unit in this model captures the mean-field activity of a neuronal population. This may occlude computations depending on spike timing, as well as fine-grained computations at the neuronal and dendritic level.
Trivial sensory cortex. We assumed that sensory cortex conveyed errors directly based on static gamma afferent activity. Sensory cortex may instead build complex representations of afferent activity. It would be interesting to test how the requirement of controllability could guide learning of these representations.
No visual information. Should a visual error be available, it could be treated by in a similar way to somatosensory errors. If the visual error holds a monotonic relation with the afferent signals, then it should be possible to adjust the long-loop reflex in order to reduce it. When the relation between the visual error and the afferent signals is not monotonic (e.g. in some context the afferent signals correlate positively, and in other negatively), an alternative approach involving reinforcement learning can be pursued (Verduzco-Flores et al., 2022).
Very gross anatomical detail. The detailed anatomical organization of cortex and spinal cord is not considered. Moreover, the proportions for different types of cells are not considered.
Errors must be monotonic. Muscle activation may not monotonically reduce visual errors. Moreover, the haptic perception of contact is dependent on the environment, so it would not make an appropriate error signal.
No cerebellum, basal ganglia, brainstem, or premotor cortex.
Each of these omissions is also a possible route for improving the model. We aim to grow a more sophisticated model, but each new component must integrate with the rest, improve functionality and agree with biological literature.
A final limitation concerns proofs of convergence. Many factors complicate them for this model: transmission delays, noise, synaptic learning, fully neural implementation, as well as complex muscle and afferent models. We tested our results for many initial conditions, but this of course is no guarantee.
50 years ago Marr’s model of the cerebellum became a stepping stone to further theoretical and experimental progress, despite all its shortcomings (Kawato et al., 2021). We aspire our model to be the next step towards a complete model of motor control.
Variations of the spinal learning model
The main text mentions two variations of the spinal learning network that emphasize the robustness and potential of the learning mechanism. We will explain the rationale behind those two variations.
There is evidence for interneurons that drive a set of muscles, possibly setting the circuit foundation for motor synergies (Giszter, 2015; Levine et al., 2014; Bizzi and Cheung, 2013). To explore whether our ideas were compatible with interneurons activating multiple muscles, we explored whether reaching can be learned when the and units send projections to more than one motoneuron. To achieve this we modified the architecture of Figure 1 so that for every combination of two different muscles there was a pair of units that stimulated both of them.
As illustrated in the Appendix 1—figure 1, from the set of 6 muscles there are 15 combinations of 2 muscles, but 3 of them consist of antagonist pairs. Removing these we are left with 12 pairs of muscles, and for each muscle pair we had a Wilson-Cowan-like pair sending projections to the alpha motoneurons of both muscles. Furthermore, for each pair of muscles, there is another pair that contains both their antagonists, and we can use this fact to generalize the concept of antagonists when interneurons project to several motoneurons. The units sent projections to the units of their antagonists. This organization allowed us to maintain the balance between excitation and inhibition in the network, along with the connectivity motifs used previously.
Appendix 1—figure 1
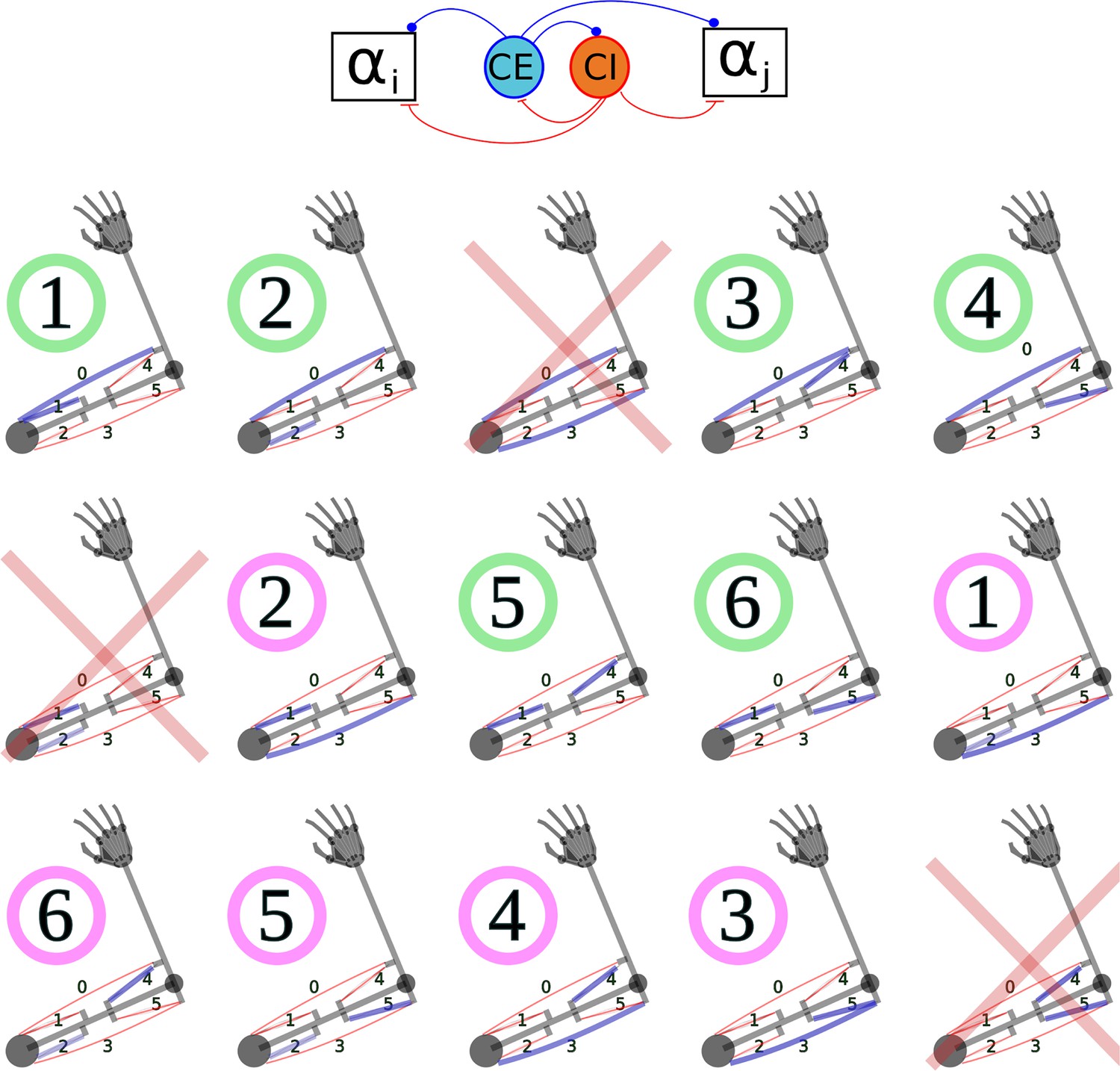
Modified architecture of the population.
Each pair of units projects to two motoneurons (top). There are 15 possible pairs of muscles, corresponding to the blue lines for each arm in the figure. Three of the pairs (marked with red crosses) contain antagonist muscles, and are not included. The remaining 12 pairs can be arranged into 2 groups of 6 units each. The units in the group marked with green circles are the antagonists of the units with the same number, marked with pink circles.
Because this model could be considered a proof-of-concept for the compatibility of our learning mechanisms with this particular type of synergies, we refer to this model as the “synergistic” network.
To introduce the second variation of the spinal learning network, we may notice that in all configurations so far the projections from to use one-to-one connectivity (each unit controls the length error of one muscle). Interestingly, this is not necessary. In a second variation of the spinal learning network, dubbed the “mixed errors” network, each unit in can be driven by a linear combination of errors.
To ensure that the information about the activity was transmitted to , we based our to connections on the following 6-dimensional orthogonal matrix:
(A1)
The rows of this matrix form an orthogonal basis in , and normalizing each row we obtain a matrix whose rows form an orthonormal basis. Connections from the 12 units to the 12 units used this 12 × 12 matrix:
(A2)
The one-to-one connections from to used in our models are unrealistic, but the mixed errors network shows that this simplification can be overcome, since all the results of the paper also apply to this variation.
All numerical tests applied to the 3 configurations in the main text of the paper were also applied to the two variations of the spinal learning model. Results can be seen in this Appendix, in the Comparison of the 5 configurations. Figure 2—figure supplements 3 and 4 illustrate the training phase for the synergistic and mixed error networks.
We also tested whether the stimulation of an isolated spinal cord produced convergent direction fields in the synergistic network, as was done in the main text for the spinal network common to the other four configurations. We found that the mean angle difference between the direction fields and , averaged over the 144 possible pairs, was 19.8 degrees.
Randomly choosing pairs and for the stimulation locations lead to a angle of 72.3 degrees. As before, a bootstrap test showed that this value is significantly different (). Removing the resting field does not alter this result. Moreover, we found no evidence for supralinear summation of force fields in the synergistic network.
The model fails when elements are removed
Due to the larger number of tests, we only used 5 trials for each configuration in this section. The p values reported in this section come from the one-sided t-test. For brevity, the different configurations of the model will be denoted by numbers in the rest of this Appendix: 1=spinal learning, 2=cortical learning, 3=static network, 4=synergistic network, 5=mixed errors network.
A model with fully random connectivity and no plasticity has an exceedingly low probability of having an input-output structure leading it to reduce errors. The configurations of the model with plasticity (configurations 1,2,4,5), however, only have random connections at one of the projections in the sensorimotor loop (either from to , or from to ). This may increase the chance of randomly obtaining a good input-output structure, which could throw the usefulness of the learning rules into question.
Removing both types of plasticity in configurations 1,2,4,5 impaired reaching in all 5 tests for each configuration, as reflected by the inability to reduce the average error below 10 centimeters in any of the last 4 reaches of the learning phase. This was also true when removing only the plasticity in the connections from to (configurations 1, 4, 5) or from to (configuration 2). In each one of the plastic configurations (1,2,4,5) the average error for the last 4 training targets was centimeters, which was significantly higher than the case with normal plasticity ( for configurations 2,4,5, for configuration 1, where the failed trials were not discarded).
Removing plasticity in the connections from to or from to individually had for the most part no statistically significant effects. Removing plasticity in both connections simultaneously, however, roughly duplicated the error in configurations 2 and 4 during center-out reaching (one-sided t-test, ). Error may be slightly increased for configuration 1 (the small sample size allowed no strong conclusions), whereas configuration 5 was seemingly unaffected.
Configurations (1,2,4,5) could still learn to reach after removing the unit. Configuration 4 roughly duplicated its center-out reaching error () and its time to initially reach (). Configuration 1 increased its time to initially reach about 3 times (), and the other two configurations were seemingly unaffected. The unit was essential for previous, less robust versions of the model.
Removing noise made learning too slow, to the point where mean error in the last 4 training reaches could not be reduced below 10 cm in any trial for configurations 4, and 5. It was reduced below 10 cm in a single trial for configuration 2. Configuration 1 managed t learn normally. Center-out reaches were not possible in configurations 2, 4, and 5 with mean errors of centimeters respectively, at least 3 times larger than the models with noise (). Center-out reaches were normal in configuration 1, but the first reach with mean error below 10 centimeters took significantly longer to happen (from 2.5 to 6.4 attempts in average, ).
Removing Ia and Ib afferents, and instead sending the output of II afferents to , , and prevented reaching in configurations 1, 2, 3, and 4 (except for a single trial in configuration 1). Configuration 5 could still learn to reach, but the mean error in the last 4 training reaches and during the center-out reaching was significantly higher ().
Removing the agonist-antagonist connections in prevented reaching in (5| 0| 0| 3| 2) trials for configurations (1,2,3,4,5) respectively. Error in center-out reaching was significantly increased for configurations 4 and 5, and it did not increase significantly for configurations 2 and 3.
Appendix 1—figure 2 is the same as Figure 2 of the main text, but in this case the noise and the ACT units were both removed. The average distance from the hand to the target was roughly 18 cm. A video illustrating this failure to learn is included with the supplementary videos.
Appendix 1—figure 2
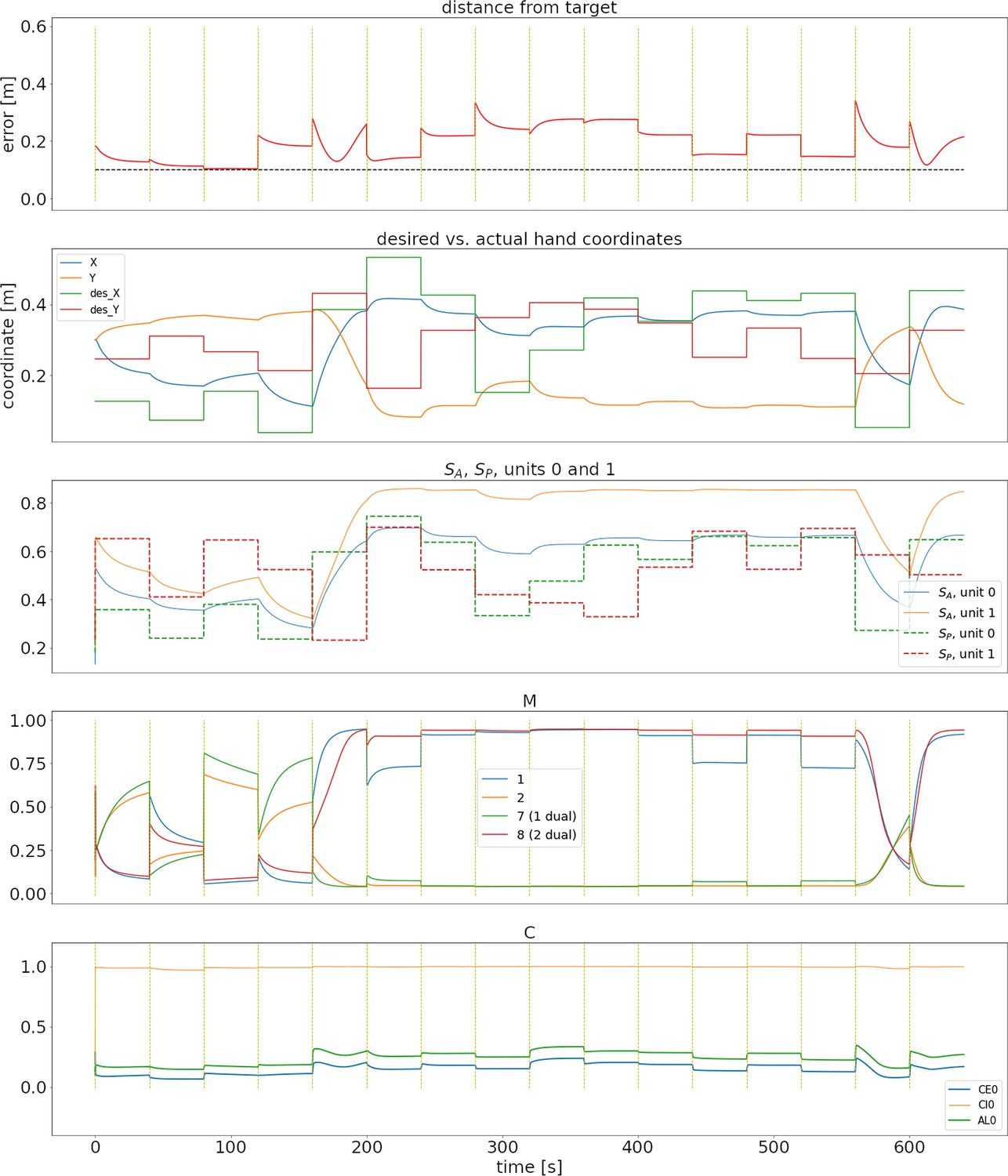
A failure to learn for a simulation of configuration 1 (spinal learning) with no noise and no ACT unit.
Captions are as in Figure 2 of the main text.
Configuration 1 was resilient to removal of noise and the ACT unit individually. The simulation of Appendix 1—figure 2 suggests that removing more than one element will have larger consequences on the performance of the model.
Comparison of the 5 configurations
Once again, the 5 configurations in this paper are represented by a number: 1=spinal learning, 2=cortical learning, 3=static network, 4=synergistic network, 5=mixed errors network. The following table shows the connectivity in each one. Abbreviations: A2A: all-to-all, O2O: one-to-one, DH: the differential Hebbian learning rule from Verduzco-Flores et al., 2022, IC: the Input Correlation learning rule, S: static connections (see section for details on the weights of static connections).
| Configuration | to | to | to , |
|---|---|---|---|
| 1 | O2O, S | A2A, DH | A2A, IC |
| 2 | A2A, DH | S | A2A, IC |
| 3 | O2O, S | S | S |
| 4 | O2O, S | A2A, DH | A2A, IC |
| 5 | S | A2A, DH | A2A, IC |
The spinal learning model (configuration 1) is a “basic” network where the input-output structure of the control loop happens in the spinal cord, in the connections from M to C.
The cortical learning model (configuration 2) is also a “basic” network, but the input-output structure is resolved in the intracortical connections from .
The static network (configuration 3) uses only static connections, and is meant to show that the results in the paper appear in a close to optimal configuration of feedback control, rather than being some sophisticated product of the plasticity rules.
The synergistic network (configuration 4) is an extension of configuration 1, where the spinal cord has 12 CE, CI pairs rather than 6, and each pair stimulates 2α motoneurons.
The mixed errors network (configuration 5) is a different variation of configuration 1, where the connections from are not one-to-one, but instead come from an orthogonal matrix.
The following table summarizes the numerical results for the 5 configurations.
| Measurement | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Failed reaches1 | |||||
| Center-out error2 | |||||
| units tuned | |||||
| to direction | |||||
| forfor | |||||
| predicted PD | |||||
| PD distribution | |||||
| main axis (deg) | |||||
| PD drift | |||||
| angle (deg) | |||||
| Muscle PD | |||||
| drift angle (deg) | |||||
| Center-out error | |||||
| (10 targets) | 3 | 3.6 | 2.9 | 2.6 | 4.5 |
| Variance in | |||||
| first jPCA | |||||
| Center-out error | |||||
| (light arm) | 2.5 | 3.2 | 3 | 6.1 | 2.9 |
| Center-out error | |||||
| (heavy arm) | 2.4 | 3.3 | 2.9 | 5.6 | 3.2 |
Average number of reaches before the first reach when the mean error was below 10 cm. 2 Average distance (in centimeters) between the hand and the target during center-out reaching.
Gain and oscillations
The gain of a feedback loop describes how the amplitude of the error signal increases as it gets transformed into a control signal sent to the plant. As described in the Methods (section), we used a relatively low number of iterations of an optimization algorithm to find suitable parameters for each configuration of the model. This led to configurations with gains that were coarsely tuned. Figure 3—figure supplement 1 is analogous to Figure 3, and shows the hand trajectories right after the optimization algorithm was finished. It can be observed that configurations 2 and 3 were particularly prone to oscillations, and configuration 1 would undershoot many targets.
To improve performance, as well as to facilitate comparison of the 5 configurations, we adjusted their gains. This involved manually adjusting the slope of the sigmoidal units in populations and , until they appeared stable, but on the verge of oscillating (so reaching would be faster). This required from 1 to 3 attempts. The gain of configuration 1 was slightly increased, whereas the gain of configurations 2,3,4 was reduced. Configuration 5 was left with the same parameters.
The trajectories in panels C and D of Figure 3—figure supplement 1 are reminiscent of terminal tremors in cerebellar ataxia. An animation showing the movement of the arm for the 5 configurations before gain adjustment is included among the Supplementary Videos. In addition, Figure 3—figure supplements 2 and 3 show the error and activity of several units during the training reaches for configurations 3 and 4, analogous to Figure 2. It can be observed that the oscillations are present in the whole network, suggesting that the control signals are trying to catch up with an error that keeps reversing direction.
Supplementary videos
To help visualization of the arm’s learning and performance under different conditions, 4 videos were produced. The videos indicate the model configuration using the enumeration from this Appendix: 1=spinal learning, 2=cortical learning, 3=static network, 4=synergistic network, 5=mixed errors network.
To download these videos, please visit https://gitlab.com/sergio.verduzco/public_materials/-/tree/master/adaptive_plasticity
The videos’ content is as follows:
Appendix 1—video 1
Visualization of the arm and the muscles during the learning phase for configuration 1.
Data comes from the simulation shown in Figure 2. Speed is roughly 4 X.
Appendix 1—video 2
Arm animation of the first 180 seconds of center-out reaching for the 5 configurations.
Speed is roughly 4 X.
Appendix 1—video 3
The learning phase for a simulation with configuration 1.
Both noise and the unit were removed, reducing exploration and disrupting learning. Data comes from the same simulation in Appendix 1—figure 2. Speed is 4 X.
Appendix 1—video 4
The first 180 seconds of center-out reaching for the 5 configurations before the gains were adjusted.
Speed is roughly 4 X. Configuration 2 shows target-dependent oscillations after 70 seconds.
Parameter values
Values appear in order for configurations 1–5. A single number means that all configurations use that same value.
Unit parameters
The superscript on a population name indicates that a parameter has heterogeneous values. This means that a random value was added to the parameter for each individual unit. This random value comes from a uniform distribution centered at zero, with a width equal to 1% of the reported parameter value.
| Parameter | Equation | Population | Value |
|---|---|---|---|
| 5 | 10 [ms] | ||
| 20 [ms] | |||
| 140, 70, 150, 180, 110 [ms] | |||
| 50 [ms] | |||
| 6 | 2 | ||
| 1.63, 1.72, 1.70, 3.38, 1.44 | |||
| 4.0, 3.38, 3.44, 2.46, 3.63 | |||
| 1.5, 1.5, 2.0, 2.0, 1.17 | |||
| 3.0, 2.2, 2.0, 2.3, 3.0 | |||
| 9 | |||
| 6 | 1.1 | ||
| 2.0, 1.93, 2.13, 2.31, 1.67 | |||
| 1.5, 1.41, 1.63, 1.72, 1.7 | |||
| 1.3, 1.96, 0.68, 1.19, 1.38 | |||
| 1 | |||
| 0.75 | |||
| units 0,3 | |||
| .4 | |||
| units 1,2,5 | |||
| .3 | |||
| unit 4 | |||
| .25 | |||
| .1 | |||
| 7 | 0.63, 0, 0, 0.69, 0.72 | ||
| 0, 0.62, 0, 0, 0 | |||
| 8 | 10 [ms] | ||
| 8 | .2 | ||
| afferents | |||
| 0 | |||
| afferents | |||
| 12, 13 | 11 [s] | ||
| 15, 16 | .31 | ||
| 16 | 10 [ms] | ||
| 16 | 8 | ||
| 17 | (synapse) | 20 |
Learning rules
| Parameter | Equation | Value |
|---|---|---|
| 9 | 0.33, 0.37, 0.15, 0.36, 0.32 [s] | |
| 10 | 500, 0, 0, 500, 500 | |
| 10 | 0, 527, 0, 0, 0 | |
| 10 | 300, 0, 0, 300, 300 | |
| 10 | .03 | |
| 10 | 2.52 | |
| 10 | 3.23, 3.19, 2.98, 3.23, 3.23 | |
| 10 | 3.29, 2.14, 1.50, 3.69, 0.57 | |
| 10 | 2.86, 2.86, 1.50, 2.86, 2.86 | |
| 11 | 26.17 | |
| 11 | 22.5 | |
| 11 | 0.85, 1.14, 1, 0.53, 0.53 | |
| 11 | 1.68, 2, 2, 1.55, 2.88 | |
| 11 | .48,.22,.2,.25,.33 | |
| 11 | .3,.64,.64,.28,.59 | |
| 1 Constraints in the sum of weights are also used with static connections | ||
Muscles and afferents
| Parameter | Equation | Value |
|---|---|---|
| 18 | 20 [N/m] | |
| 18 | 20 [N/m] | |
| 18 | 1 [N.s / m] | |
| 18 | 67.11 [N] | |
| muscles 0,3 | ||
| 18 | .75 [N] | |
| muscles 1,2,4,5 | ||
| 19,20,21 | 2 [N/m] | |
| 19,20,21 | 2 [N/m] | |
| 19, 21 | .5[Ns / m] | |
| 19,20,21 | 1 [N/m] | |
| 19 | .2 [N/m] | |
| 19 | 2[N. s / m] | |
| 19 | .7 | |
| 19 | .8 | |
| 20 | [7.5, 25, 25, 7.5, 25, 25] | |
| muscles 0–5 | ||
| 20 | 0.1 | |
| 21 | , | |
| muscles 0–5 | ||
| 21 | 0.5 | |
| 22 | 1 | |
| T0 | 22 | 10 [N] |
| 23 | 50 [ms] |
Connection delays and weights
Connections considered "local" used a delay of 10 [ms], unless those those connections implied a not-modeled disynaptic inhibition. All other connections had a delay of 20 [ms].
| Source | Target | Delay |
|---|---|---|
| 20 [ms] | ||
| muscle | ||
| afferents | ||
| 10 [ms] | ||
The next table shows the value of fixed synaptic weights not specified in section. Columns indicate the source of the connection, rows indicate the target. "Aff" stands for the muscle afferents. Potentially plastic connections are marked as "+". If a connection marked “+” is static in one of the configurations, its weight is determined by the parameters of Equations 10, 11.
| Aff. | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | -1 | + | |||||||
| 2 (), | |||||||||
| 4 () | |||||||||
| 1 | |||||||||
| + | + | ||||||||
| + | |||||||||
| + | + | ||||||||
| + | * | + | |||||||
| muscles | 1 | ||||||||
| 1 | |||||||||
| 1 or –1 | 1 or –1 | –1.77 | |||||||
| a Agonist connections, b Partial agonist connections. c Withing the same triplet. d Antagonist connections. e Partial antagonist connections. units inhibited their duals with weights that depended on the configuration: −0.93,–0.74, −1.00,–1.14, 0.0. | |||||||||
All connections whose source is or have a weight of 1.
Data availability
The current manuscript is a computational study, so no data have been generated for this manuscript. The source code to generate all figures is available as two commented Jupyter notebooks. They can be downloaded from the following repository: https://gitlab.com/sergio.verduzco/public_materials/-/tree/master/adaptive_plasticity (copy archived at swh:1:rev:482c0659d6e90b30a4a1acb4ab3e3a03dfd902c4). Instructions are in the "readme.md" file. Briefly: Prerequisites for running the notebooks are: Python 3.5 or above (https://www.python.org); Jupyter (https://jupyter.org); Draculab (https://gitlab.com/sergio.verduzco/draculab). Please see the links above for detailed installation instructions.
References
-
Predictions not commands: active inference in the motor systemBrain Structure & Function 218:611–643.https://doi.org/10.1007/s00429-012-0475-5
-
Circuits for skilled reaching and graspingAnnual Review of Neuroscience 35:559–578.https://doi.org/10.1146/annurev-neuro-062111-150527
-
Connecting neuronal circuits for movementScience 360:1403–1404.https://doi.org/10.1126/science.aat5994
-
The hierarchical evolution in human vision modelingTopics in Cognitive Science 13:309–328.https://doi.org/10.1111/tops.12527
-
A large-scale model of some spinal reflex circuitsBiol Cybern 78:147–157.https://doi.org/10.1007/s004220050421
-
Cerebellar ataxia: abnormal control of interaction torques across multiple jointsJournal of Neurophysiology 76:492–509.https://doi.org/10.1152/jn.1996.76.1.492
-
Multi-joint reaching movements and eye-hand tracking in cerebellar incoordination: investigation of a patient with complete loss of Purkinje cellsCanadian Journal of Neurological Sciences / Journal Canadien Des Sciences Neurologiques 18:476–487.https://doi.org/10.1017/S0317167100032194
-
Nengo: a python tool for building large-scale functional brain modelsFrontiers in Neuroinformatics 7:48.https://doi.org/10.3389/fninf.2013.00048
-
When networks walk a fine line: balance of excitation and inhibition in spinal motor circuitsCurrent Opinion in Physiology 8:76–83.https://doi.org/10.1016/j.cophys.2019.01.006
-
New perspectives on spinal motor systemsNature Reviews. Neuroscience 1:101–108.https://doi.org/10.1038/35039000
-
The neural origin of muscle synergiesFrontiers in Computational Neuroscience 7:51.https://doi.org/10.3389/fncom.2013.00051
-
From motor planning to execution: a sensorimotor loop perspectiveJournal of Neurophysiology 124:1815–1823.https://doi.org/10.1152/jn.00715.2019
-
Modeling the connectome of a simple spinal cordFrontiers in Neuroinformatics 5:20.https://doi.org/10.3389/fninf.2011.00020
-
Synergies in coordination: a comprehensive overview of neural, computational, and behavioral approachesJournal of Neurophysiology 120:2761–2774.https://doi.org/10.1152/jn.00052.2018
-
Adaptive tracking control for robots with unknown kinematic and dynamic propertiesThe International Journal of Robotics Research 25:283–296.https://doi.org/10.1177/0278364906063830
-
Simulation system of spinal cord motor nuclei and associated nerves and muscles, in a web-based architectureJournal of Computational Neuroscience 25:520–542.https://doi.org/10.1007/s10827-008-0092-8
-
Wilson-cowan equations for neocortical dynamicsJournal of Mathematical Neuroscience 6:1.https://doi.org/10.1186/s13408-015-0034-5
-
Does abnormal spinal reciprocal inhibition lead to co-contraction of antagonist motor units? A modeling studyInternational Journal of Neural Systems 17:319–327.https://doi.org/10.1142/S0129065707001160
-
Are muscle synergies useful for neural control?Frontiers in Computational Neuroscience 7:00019.https://doi.org/10.3389/fncom.2013.00019
-
A spiking neural model of adaptive arm controlProceedings. Biological Sciences 283:20162134.https://doi.org/10.1098/rspb.2016.2134
-
Cortical spiking network interfaced with virtual musculoskeletal arm and robotic armFrontiers in Neurorobotics 9:13.https://doi.org/10.3389/fnbot.2015.00013
-
Physiology of motor control in manApplied Neurophysiology 44:5–15.https://doi.org/10.1159/000102178
-
The effective neural drive to muscles is the common synaptic input to motor neuronsThe Journal of Physiology 592:3427–3441.https://doi.org/10.1113/jphysiol.2014.273581
-
Once more on the equilibrium-point hypothesis (lambda model) for motor controlJournal of Motor Behavior 18:17–54.https://doi.org/10.1080/00222895.1986.10735369
-
Local shaping of function in the motor cortex: motor contrast, directional tuningBrain Research Reviews 55:383–389.https://doi.org/10.1016/j.brainresrev.2007.05.001
-
Convergent force fields organized in the frog’s spinal cordThe Journal of Neuroscience 13:467–491.https://doi.org/10.1523/JNEUROSCI.13-02-00467.1993
-
Motor primitives--new data and future questionsCurrent Opinion in Neurobiology 33:156–165.https://doi.org/10.1016/j.conb.2015.04.004
-
Inhibition downunder: an update from the spinal cordCurrent Opinion in Neurobiology 26:161–166.https://doi.org/10.1016/j.conb.2014.03.006
-
Learning from the spinal cord: how the study of spinal cord plasticity informs our view of learningNeurobiology of Learning and Memory 108:155–171.https://doi.org/10.1016/j.nlm.2013.08.003
-
Early human motor development: from variation to the ability to vary and adaptNeuroscience and Biobehavioral Reviews 90:411–427.https://doi.org/10.1016/j.neubiorev.2018.05.009
-
Towards a circuit mechanism for movement tuning in motor cortexFrontiers in Neural Circuits 6:127.https://doi.org/10.3389/fncir.2012.00127
-
BookNeuroscience in the 21st Century: From Basic to ClinicalNew York, NY: Springer.
-
BookThe Primate Visual SystemNew York, United States: John Wiley & Sons, Ltd.https://doi.org/10.1201/9780203507599
-
From intention to action: motor cortex and the control of reaching movementsAdvances in Experimental Medicine and Biology 629:139–178.https://doi.org/10.1007/978-0-387-77064-2_8
-
Cortical activity in the null space: permitting preparation without movementNature Neuroscience 17:440–448.https://doi.org/10.1038/nn.3643
-
BookPrinciples Of Applied Mathematics: Transformation And ApproximationNew York, United States: Avalon Publishing.
-
BookProgress in Motor Control: A Multidisciplinary Perspective, Advances in Experimental Medicine and BiologySternad D, editors. Boston, MA: Springer US.
-
Descending pathways in motor controlAnnual Review of Neuroscience 31:195–218.https://doi.org/10.1146/annurev.neuro.31.060407.125547
-
Identification of a cellular node for motor control pathwaysNature Neuroscience 17:586–593.https://doi.org/10.1038/nn.3675
-
ConferenceHierarchical Feedback and Learning for Multi-joint Arm Movement ControlIn 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference. pp. 4400–4403.https://doi.org/10.1109/IEMBS.2005.1615441
-
Balanced cortical microcircuitry for maintaining information in working memoryNature Neuroscience 16:1306–1314.https://doi.org/10.1038/nn.3492
-
Neural and mechanical contributions to the stretch reflex: a model synthesisAnnals of Biomedical Engineering 30:54–67.https://doi.org/10.1114/1.1432692
-
Major remaining gaps in models of sensorimotor systemsFrontiers in Computational Neuroscience 9:70.https://doi.org/10.3389/fncom.2015.00070
-
Redundancy, self-motion, and motor controlNeural Computation 21:1371–1414.https://doi.org/10.1162/neco.2008.01-08-698
-
Dominance of the short-latency component in perturbation induced electromyographic responses of long-trained monkeysExperimental Brain Research 64:393–399.https://doi.org/10.1007/BF00340475
-
An incremental self-organizing architecture for sensorimotor learning and predictionIEEE Transactions on Cognitive and Developmental Systems 10:918–928.https://doi.org/10.1109/TCDS.2018.2832844
-
Mathematical models of proprioceptors. I. control and transduction in the muscle spindleJournal of Neurophysiology 96:1772–1788.https://doi.org/10.1152/jn.00868.2005
-
Prediction of muscle activity by populations of sequentially recorded primary motor cortex neuronsJournal of Neurophysiology 89:2279–2288.https://doi.org/10.1152/jn.00632.2002
-
Spatial representation in the hippocampal formation: a historyNature Neuroscience 20:1448–1464.https://doi.org/10.1038/nn.4653
-
Motor learning through the combination of primitivesPhilosophical Transactions of the Royal Society of London. Series B 355:1755–1769.https://doi.org/10.1098/rstb.2000.0733
-
Acquisition, maintenance, and therapeutic use of a simple motor skillCurrent Opinion in Behavioral Sciences 20:138–144.https://doi.org/10.1016/j.cobeha.2017.12.021
-
Six principles for biologically based computational models of cortical cognitionTrends in Cognitive Sciences 2:455–462.https://doi.org/10.1016/s1364-6613(98)01241-8
-
Neuronal activity in the supplementary motor area of monkeys adapting to a new dynamic environmentJournal of Neurophysiology 91:449–473.https://doi.org/10.1152/jn.00876.2002
-
BookThe Circuitry of the Human Spinal CordCambridge: Cambridge University Press.https://doi.org/10.1017/CBO9780511545047
-
Biological constraints on neural network models of cognitive functionNature Reviews. Neuroscience 22:488–502.https://doi.org/10.1038/s41583-021-00473-5
-
A deep learning framework for neuroscienceNature Neuroscience 22:1761–1770.https://doi.org/10.1038/s41593-019-0520-2
-
Adaptive motor behavior of cerebellar patients during exposure to unfamiliar external forcesJournal of Motor Behavior 36:28–38.https://doi.org/10.3200/JMBR.36.1.28-38
-
Cerebellar ataxia: quantitative assessment and cybernetic interpretationHuman Movement Science 22:189–205.https://doi.org/10.1016/s0167-9457(02)00159-8
-
Gaussian networks for direct adaptive controlIEEE Transactions on Neural Networks 3:837–863.https://doi.org/10.1109/72.165588
-
BookReaching for Objects: A Neural Process Account in A Developmental PerspectiveOxfordshire, United Kingdom: Taylor & Francis Group Logo.
-
BookThe Computational Neurobiology of Reaching and Pointing: A Foundation for Motor LearningMIT Press.
-
Cortical control of arm movements: a dynamical systems perspectiveAnnual Review of Neuroscience 36:337–359.https://doi.org/10.1146/annurev-neuro-062111-150509
-
Organization of flexor-extensor interactions in the mammalian spinal cord: insights from computational modellingThe Journal of Physiology 594:6117–6131.https://doi.org/10.1113/JP272437
-
Spinal inhibitory interneurons: Gatekeepers of sensorimotor pathwaysInternational Journal of Molecular Sciences 22:2667.https://doi.org/10.3390/ijms22052667
-
Analysis of reflex modulation with a biologically realistic neural networkJournal of Computational Neuroscience 23:333–348.https://doi.org/10.1007/s10827-007-0037-7
-
A neural network that finds a naturalistic solution for the production of muscle activityNature Neuroscience 18:1025–1033.https://doi.org/10.1038/nn.4042
-
Direct cortical control of muscle activation in voluntary arm movements: a modelNature Neuroscience 3:391–398.https://doi.org/10.1038/73964
-
The case for and against muscle synergiesCurrent Opinion in Neurobiology 19:601–607.https://doi.org/10.1016/j.conb.2009.09.002
-
Primary motor cortex tuning to intended movement kinematics in humans with tetraplegiaThe Journal of Neuroscience 28:1163–1178.https://doi.org/10.1523/JNEUROSCI.4415-07.2008
-
Useful properties of spinal circuits for learning and performing planar reachesJournal of Neural Engineering 11:056006.https://doi.org/10.1088/1741-2560/11/5/056006
-
A mathematical approach to the mechanical capabilities of limbs and fingersAdvances in Experimental Medicine and Biology 629:619–633.https://doi.org/10.1007/978-0-387-77064-2_33
-
Draculab: a python simulator for firing rate neural networks with delayed adaptive connectionsFrontiers in Neuroinformatics 13:18.https://doi.org/10.3389/fninf.2019.00018
-
Adaptive plasticity in the spinal stretch reflexBrain Research 267:196–200.https://doi.org/10.1016/0006-8993(83)91059-4
-
The complex structure of a simple memoryTrends in Neurosciences 20:588–594.https://doi.org/10.1016/s0166-2236(97)01133-8
-
Differential contribution of V0 interneurons to execution of rhythmic and nonrhythmic motor behaviorsThe Journal of Neuroscience 41:3432–3445.https://doi.org/10.1523/JNEUROSCI.1979-20.2021
Article and author information
Author details
Sergio Oscar Verduzco-Flores

Funding
No external funding was received for this work.
Acknowledgements
The authors wish to thank Prof. Kenji Doya for helping revise early versions of this manuscript.
Copyright
© 2022, Verduzco-Flores and De Schutter
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,108
- views
-
- 174
- downloads
-
- 8
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Self-configuring feedback loops for sensorimotor control
eLife 11:e77216.
https://doi.org/10.7554/eLife.77216
Further reading
-
- Biochemistry and Chemical Biology
- Computational and Systems Biology
Protein–protein interactions are fundamental to understanding the molecular functions and regulation of proteins. Despite the availability of extensive databases, many interactions remain uncharacterized due to the labor-intensive nature of experimental validation. In this study, we utilized the AlphaFold2 program to predict interactions among proteins localized in the nuage, a germline-specific non-membrane organelle essential for piRNA biogenesis in Drosophila. We screened 20 nuage proteins for 1:1 interactions and predicted dimer structures. Among these, five represented novel interaction candidates. Three pairs, including Spn-E_Squ, were verified by co-immunoprecipitation. Disruption of the salt bridges at the Spn-E_Squ interface confirmed their functional importance, underscoring the predictive model’s accuracy. We extended our analysis to include interactions between three representative nuage components—Vas, Squ, and Tej—and approximately 430 oogenesis-related proteins. Co-immunoprecipitation verified interactions for three pairs: Mei-W68_Squ, CSN3_Squ, and Pka-C1_Tej. Furthermore, we screened the majority of Drosophila proteins (~12,000) for potential interaction with the Piwi protein, a central player in the piRNA pathway, identifying 164 pairs as potential binding partners. This in silico approach not only efficiently identifies potential interaction partners but also significantly bridges the gap by facilitating the integration of bioinformatics and experimental biology.
-
- Computational and Systems Biology
- Neuroscience
Accumulating evidence to make decisions is a core cognitive function. Previous studies have tended to estimate accumulation using either neural or behavioral data alone. Here, we develop a unified framework for modeling stimulus-driven behavior and multi-neuron activity simultaneously. We applied our method to choices and neural recordings from three rat brain regions—the posterior parietal cortex (PPC), the frontal orienting fields (FOF), and the anterior-dorsal striatum (ADS)—while subjects performed a pulse-based accumulation task. Each region was best described by a distinct accumulation model, which all differed from the model that best described the animal’s choices. FOF activity was consistent with an accumulator where early evidence was favored while the ADS reflected near perfect accumulation. Neural responses within an accumulation framework unveiled a distinct association between each brain region and choice. Choices were better predicted from all regions using a comprehensive, accumulation-based framework and different brain regions were found to differentially reflect choice-related accumulation signals: FOF and ADS both reflected choice but ADS showed more instances of decision vacillation. Previous studies relating neural data to behaviorally inferred accumulation dynamics have implicitly assumed that individual brain regions reflect the whole-animal level accumulator. Our results suggest that different brain regions represent accumulated evidence in dramatically different ways and that accumulation at the whole-animal level may be constructed from a variety of neural-level accumulators.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}