Computational Neuroscience: A faster way to model neuronal circuitry
Artificial neural networks could pave the way for efficiently simulating large-scale models of neuronal networks in the nervous system.
- Institut des Neurosciences Paris-Saclay, Université Paris-Saclay, CNRS, France
Computational modelling and simulation are widely used to help understand the brain. To represent the billions of neurons and trillions of synapses that make up our nervous system, models express electrical and chemical activity mathematically, using equations that they solve with computational methods.
Coarse-grained models of the brain – where each equation represents the collective activity of hundreds of thousands or millions of neurons – have been valuable in helping us understand the coordination of activity across the whole brain (Sanz Leon et al., 2013). The equations from these models can be solved using a normal computer that any researcher might have on their desk. But if we start to investigate how individual neurons and synapses interact to give rise to the collective activity of the brain, the number of equations to be solved becomes enormous. In this case, even powerful supercomputers running flat out for many hours can only simulate the activity of a few cubic millimeters of brain for a few seconds (Billeh et al., 2020; Markram et al., 2015).
Now, in eLife, Viktor Oláh, Nigel Pedersen and Matthew Rowan from the Emory University School of Medicine report on a promising new technique that relies on machine learning tools to greatly accelerate simulations of networks of biologically realistic neurons, without the need for supercomputers (Oláh et al., 2022).
Machine learning approaches have become ubiquitous in recent years, whether it be in self-driving cars, computer-generated art or in the computers that have beat grandmasters in chess and Go. One of the most widely-used tools for machine learning is the artificial neural network, or ANN.
First developed around the middle of the 20th century, ANNs are based on a highly simplified model of how real neurons work (McCulloch and Pitts, 1943; Rosenblatt, 1958). However, it was only in the early 2000s that their use really took off, due to a combination of increased computing power and theoretical advances that allowed ‘deep learning’ (which involves training ANNs with many layers of artificial neurons; reviewed in Schmidhuber, 2015). Each layer in an ANN takes the data from the previous layer as an input, transforms it and feeds it into the next layer, allowing the ANN to perform complex computations (Figure 1).
Figure 1
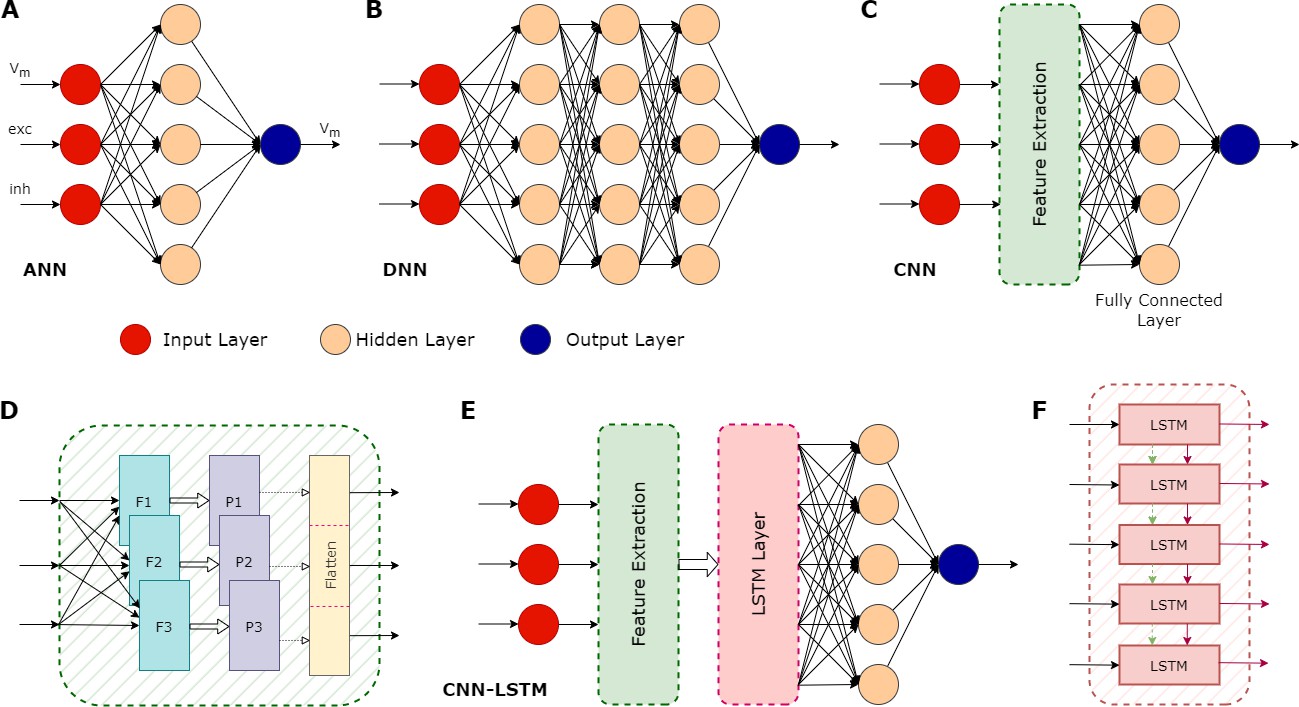
Illustration of various types of artificial neural networks (ANN) and their associated components.
(A) A basic ANN consists of an input layer (red circles), one or more hidden layers (peach circles), and an output layer (blue circle). In the case of neuronal modelling, the input could be features such as the membrane potential (Vm), and the excitatory (exc) and inhibitory (inh) synaptic inputs. The hidden layers perform computations on the inputs, with the actual operations depending on the type of ANN. Their objective is to identify features in the inputs and use these to correlate a given input and the correct output. An ANN can have multiple outputs: in this example, the output is a prediction of the membrane potential. (B) A deep neural network (DNN) is an ANN with multiple hidden layers. (C) A convolutional neural network (CNN) is a type of DNN that can be trained to extract important features contained in the input data, which can then be used as inputs to the other hidden layers, significantly improving the performance of the overall network. (D) Some details of the feature extraction process of a CNN, which consists of several hidden layers. First, it has multiple filters (F1, F2, F3), each configured to capture specific features. This process can greatly increase the size of the data, so a pooling layer (P1, P2, P3) is then used to reduce this size. The pooling process does not lead to the loss of valuable data; instead, it helps remove noise and consolidate meaningful data. The flattening layer converts the pooled data into a 1-dimensional stream. This serves as an input for the subsequent fully connected layer, which does the final evaluation to produce the output based on the features extracted by the convolution layers. (E) A CNN with a long short-term memory (LSTM) layer. The additional LSTM layer enables the network to benefit from long-term memory, in addition to the existent short-term working memory. (F) The LSTM layer achieves this long-term memory through its ability to relay both the cell state (dashed green arrows) and the output generated by each module (solid maroon arrows) across its several modules, allowing the flow of useful information. This enables the network to better identify context in the input data over longer time periods. CNN-LSTMs have been found useful for predicting time series data.
A type of ANN known as a recurrent network has proven to be highly effective at learning to predict changes over time (Hewamalage et al., 2021). In these networks, the activity of a layer of neurons is fed back into itself or into earlier layers, allowing the network to integrate new inputs with its own previous activity. Such ANNs have been used for stock market predictions, machine translation, to accelerate weather and climate change simulations (review in Chantry et al., 2021), and to predict the electrical activity of individual biological neurons (Beniaguev et al., 2021; Wang et al., 2022). Oláh et al. have now developed ANNs that can predict the activity of entire networks of biologically realistic neurons with good levels of accuracy.
First, the team tested several different ANN architectures, and found that a particular type of recurrent neural network – which they call a convolutional neural network with long short-term memory (CNN-LSTM) – was able to accurately predict not only the sub-threshold activity but also the shape and timing of action potentials of neurons. For single neurons, their approach was comparable in speed to traditional simulators. However, when they simulated networks made up of many similar neurons, the performance of the CNN-LSTM was much better, becoming over 10,000 times faster than traditional simulators in certain cases.
In summary, the work of Oláh et al. shows that ANNs are a promising tool for greatly increasing the scope of what can be modelled with generally available computing hardware, reducing the bottleneck of supercomputer availability. Further studies will be needed to better understand the tradeoffs between performance and accuracy for this approach. By clearly describing the successful CNN-LSTM model and providing their source code in a public repository, Oláh et al. have laid a strong foundation for such future exploration.
References
-
Opportunities and challenges for machine learning in weather and climate modelling: hard, medium and soft AIPhilosophical Transactions. Series A, Mathematical, Physical, and Engineering Sciences 379:20200083.https://doi.org/10.1098/rsta.2020.0083
-
Recurrent neural networks for time series forecasting: current status and future directionsInternational Journal of Forecasting 37:388–427.https://doi.org/10.1016/j.ijforecast.2020.06.008
-
A logical calculus of the ideas immanent in nervous activityThe Bulletin of Mathematical Biophysics 5:115–133.https://doi.org/10.1007/BF02478259
-
The perceptron: a probabilistic model for information storage and organization in the brainPsychological Review 65:386–408.https://doi.org/10.1037/h0042519
-
The virtual brain: a simulator of primate brain network dynamicsFrontiers in Neuroinformatics 7:10.https://doi.org/10.3389/fninf.2013.00010
-
Predicting spike features of hodgkin-huxley-type neurons with simple artificial neural networkFrontiers in Computational Neuroscience 15:800875.https://doi.org/10.3389/fncom.2021.800875
Article and author information
Author details
Shailesh Appukuttan

Publication history
Copyright
© 2022, Davison and Appukuttan
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 2,093
- views
-
- 146
- downloads
-
- 1
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Computational Neuroscience: A faster way to model neuronal circuitry
eLife 11:e84463.
https://doi.org/10.7554/eLife.84463
Further reading
-
- Neuroscience
Circuit function results from both intrinsic conductances of network neurons and the synaptic conductances that connect them. In models of neural circuits, different combinations of maximal conductances can give rise to similar activity. We compared the robustness of a neural circuit to changes in their intrinsic versus synaptic conductances. To address this, we performed a sensitivity analysis on a population of conductance-based models of the pyloric network from the crustacean stomatogastric ganglion (STG). The model network consists of three neurons with nine currents: a sodium current (Na), three potassium currents (Kd, KCa, KA), two calcium currents (CaS and CaT), a hyperpolarization-activated current (H), a non-voltage-gated leak current (leak), and a neuromodulatory current (MI). The model cells are connected by seven synapses of two types, glutamatergic and cholinergic. We produced one hundred models of the pyloric network that displayed similar activities with values of maximal conductances distributed over wide ranges. We evaluated the robustness of each model to changes in their maximal conductances. We found that individual models have different sensitivities to changes in their maximal conductances, both in their intrinsic and synaptic conductances. As expected, the models become less robust as the extent of the changes increases. Despite quantitative differences in their robustness, we found that in all cases, the model networks are more sensitive to the perturbation of their intrinsic conductances than their synaptic conductances.
-
- Neuroscience
When navigating environments with changing rules, human brain circuits flexibly adapt how and where we retain information to help us achieve our immediate goals.




{kind=link}