Aging and Spatial Navigation: When landmarks are not enough
Including geometric spatial cues in an environment can help reverse the difficulties with spatial navigation experienced by children and older adults.
- Department of Psychology, University of Arizona, United States
Our ability to navigate from place to place, which is essential for our wellbeing and independence, declines as we get older (Head and Isom, 2010). Even in healthy individuals, this decline can have a significant impact on quality of life and can foreshadow the onset of Alzheimer’s disease years before the appearance of clinical symptoms (Levine et al., 2020). Likewise, spatial disorientation is among the earliest behavioral symptoms of Alzheimer’s disease and can lead to a loss of personal autonomy and heightened risk of mental distress, physical injury, or even death. Impaired spatial navigation has therefore gained traction as a promising diagnostic marker of age-related cognitive dysfunction and as a potential target for disease-modifying interventions (Coughlan et al., 2018; Segen et al., 2022).
Successful spatial navigation is typically conceived as relying on two complementary strategies. Allocentric or world-centered navigation requires an individual to learn the relationship between external spatial cues such as landmarks in order to form an internal topographic map of their environment. Egocentric or person-centered navigation strategies place a greater reliance on traversing familiar and well-learned routes, and are generally regarded as less flexible and efficient than allocentric navigation. The dominant theory in the field of aging is that allocentric-based navigation is impaired in older age, resulting in a preference for egocentric-based navigation strategies (Moffat et al., 2006; Moffat and Resnick, 2002).
Now, in eLife, Angelo Arleo and colleagues at Sorbonne Université – including Marcia Bécu as first author – report that the ability to engage in putative allocentric-based navigation may depend largely on the types of spatial cues present in the environment (Bécu et al., 2023). Critically, children and older individuals were just as likely as young adults to use allocentric strategies when geometric spatial cues (as opposed to landmarks) were available to guide navigation. The work adds to mounting evidence that allocentric navigation may show some degree of preservation with age.
Bécu et al. examined the types of strategies children, young adults, and healthy older adults used when navigating a Y-maze using a virtual reality headset that allowed them to move freely (Figure 1). The Y-maze has a long history of being used to examine spatial strategies in rodents. However, the task typically relies exclusively on visual landmarks to guide navigation. Here, participants were randomly assigned to navigate in one of two Y-Maze conditions. In the classic landmark condition, participants navigated an equiangular maze in which three distal landmarks surrounding the maze could be used to infer their location. In the geometry condition, the angles between respective maze arms were not equal, allowing participants to determine their position in the maze in the absence of landmarks. Children and older adults were more likely than young adults to prefer an egocentric strategy when navigating the landmark condition, replicating numerous prior studies. However, this age-related preference for egocentric navigation was eliminated in the geometry condition, with most participants in all three age groups preferring an allocentric search strategy.
Figure 1
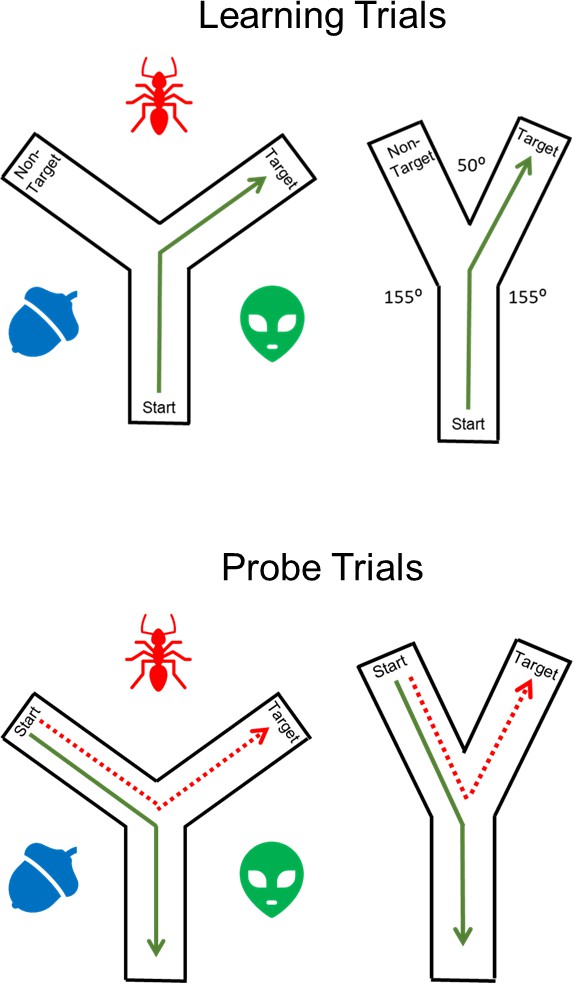
Exploring navigation strategies.
In the Y-maze task, participants first take part in a learning trial (top). Participants are placed at the base of the Y-maze (start) in either the landmark condition (left) or the geometry condition (right). The landmark condition features a Y shape with equal angles between the arms and three landmarks surrounding the maze which are illustrated with blue, red and green shapes. There are no landmarks in the geometry condition: however, the angles in the Y-maze are not equal, and this is a geometric spatial cue that can be used for navigation. Participants are trained to locate the target arm by taking a specific turn at the maze junction (for example, a right turn in this example). The learned route is shown in green. During subsequent probe trials (bottom), participants are asked to locate the target from a new starting position (the non-target arm). The route taken in the probe trial reflects the navigation strategy used by the participant. Allocentric routes (dotted red lines) are those in which participants used the external landmarks or differences in maze angle to navigate to the target arm. Egocentric routes (green lines) are those in which participants repeat the previous learned response (for example, turn right at the junction), resulting in navigation to the non-target arm of the maze.
Next, Bécu et al. analyzed eye-tracking data to examine whether age differences in visual sampling of the environment might account for the age-related preference for egocentric navigation observed in the landmark condition. Young adults and older adults did not differ in the proportion of time spent visually fixating on the landmarks when learning the maze in the landmark condition. Likewise, there was no difference between those who used egocentric navigation and those who used allocentric navigation, independent of age. These results suggest that the age-related preference for egocentric navigation observed during the landmark condition was not caused by a failure to attend to the landmarks during learning. Instead, allocentric navigators, regardless of age, spent a greater proportion of time fixating on the landmarks as they planned a locomotor response during probe trials.
Taken together, the findings reported by Bécu et al. suggest that rather than a selective deficit in allocentric-based navigation, spatial challenges in older individuals may be the result of difficulties processing landmark cues in order to orient in space. These results complement recently published findings from a study of over 37,000 individuals collected using the mobile app Sea Hero Quest, which showed that landmark-based navigation strategies decline linearly with age (West et al., 2023). Critically, this work challenges decades of prior work to suggest that wayfinding deficits in older age are unlikely to be accounted for by a simple dichotomy between allocentric and egocentric navigation.
The finding that older adults seemingly maintain the ability to orient in space as well as their younger counterparts when geometric spatial cues are available offers exciting opportunities for future research. Studies examining the perceptual, cognitive and/or neural basis of geometric cue processing could make significant contributions to the development of more comprehensive models of aging and navigation. It will also be interesting to explore whether longitudinal declines in landmark-based processing are sensitive to pathologic changes associated with Alzheimer’s disease and related dementias. This knowledge could be important when designing accessible environments for vulnerable aging populations.
References
-
Spatial navigation deficits - Overlooked cognitive marker for preclinical Alzheimer disease?Nature Reviews Neurology 14:496–506.https://doi.org/10.1038/s41582-018-0031-x
-
Age effects on wayfinding and route learning skillsBehavioural Brain Research 209:49–58.https://doi.org/10.1016/j.bbr.2010.01.012
-
Spatial navigation ability predicts progression of dementia symptomatologyAlzheimer’s & Dementia 16:491–500.https://doi.org/10.1002/alz.12031
-
Effects of age on virtual environment place navigation and allocentric cognitive mappingBehavioral Neuroscience 116:851–859.https://doi.org/10.1037//0735-7044.116.5.851
-
Path integration in normal aging and Alzheimer’s diseaseTrends in Cognitive Sciences 26:142–158.https://doi.org/10.1016/j.tics.2021.11.001
-
Landmark-dependent navigation strategy declines across the human life-span: evidence from over 37,000 participantsJournal of Cognitive Neuroscience 35:452–467.https://doi.org/10.1162/jocn_a_01956
Article and author information
Author details
Publication history
Copyright
© 2023, Hill
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,592
- views
-
- 74
- downloads
-
- 2
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Aging and Spatial Navigation: When landmarks are not enough
eLife 12:e87771.
https://doi.org/10.7554/eLife.87771
Further reading
-
- Neuroscience
When navigating environments with changing rules, human brain circuits flexibly adapt how and where we retain information to help us achieve our immediate goals.
-
- Neuroscience
Cerebellar dysfunction leads to postural instability. Recent work in freely moving rodents has transformed investigations of cerebellar contributions to posture. However, the combined complexity of terrestrial locomotion and the rodent cerebellum motivate new approaches to perturb cerebellar function in simpler vertebrates. Here, we adapted a validated chemogenetic tool (TRPV1/capsaicin) to describe the role of Purkinje cells — the output neurons of the cerebellar cortex — as larval zebrafish swam freely in depth. We achieved both bidirectional control (activation and ablation) of Purkinje cells while performing quantitative high-throughput assessment of posture and locomotion. Activation modified postural control in the pitch (nose-up/nose-down) axis. Similarly, ablations disrupted pitch-axis posture and fin-body coordination responsible for climbs. Postural disruption was more widespread in older larvae, offering a window into emergent roles for the developing cerebellum in the control of posture. Finally, we found that activity in Purkinje cells could individually and collectively encode tilt direction, a key feature of postural control neurons. Our findings delineate an expected role for the cerebellum in postural control and vestibular sensation in larval zebrafish, establishing the validity of TRPV1/capsaicin-mediated perturbations in a simple, genetically tractable vertebrate. Moreover, by comparing the contributions of Purkinje cell ablations to posture in time, we uncover signatures of emerging cerebellar control of posture across early development. This work takes a major step towards understanding an ancestral role of the cerebellum in regulating postural maturation.




{kind=link}