Heterozygote advantage can explain the extraordinary diversity of immune genes
- Department of Ecology and Genetics, Animal Ecology, Uppsala University, Sweden
Abstract
The majority of highly polymorphic genes are related to immune functions and with over 100 alleles within a population, genes of the major histocompatibility complex (MHC) are the most polymorphic loci in vertebrates. How such extraordinary polymorphism arose and is maintained is controversial. One possibility is heterozygote advantage (HA), which can in principle maintain any number of alleles, but biologically explicit models based on this mechanism have so far failed to reliably predict the coexistence of significantly more than 10 alleles. We here present an eco-evolutionary model showing that evolution can result in the emergence and maintenance of more than 100 alleles under HA if the following two assumptions are fulfilled: first, pathogens are lethal in the absence of an appropriate immune defence; second, the effect of pathogens depends on host condition, with hosts in poorer condition being affected more strongly. Thus, our results show that HA can be a more potent force in explaining the extraordinary polymorphism found at MHC loci than currently recognised.
Editor's evaluation
This important theoretical and numerical study deals with a contemporary topic in evolutionary biology, immunology and population genetics. The structure of the models and the analytic framework used are relevant and sound, and the combination of two types of models is a powerful approach that produces compelling evidence to support the hypothesis on the role of heterozygote advantage in maintaining MHC gene polymorphism. The description of the models is easy to follow, and the paper would be of interest to specialists in evolution, immunology, and the general eLife readership.
https://doi.org/10.7554/eLife.94587.sa0Introduction
Heterozygote advantage (HA) is a well-established explanation for single locus polymorphism, with the sickle cell locus as a classical textbook example (Allison, 1954). However, whether HA is generally important for the maintenance of genetic polymorphism is questioned (Hedrick, 2012; Sellis et al., 2016). Genes of the major histocompatibility complex (MHC), responsible for inducing immune defences by recognising the agretopes of the pathogenic antigens, are the most polymorphic loci among vertebrates (Duncan et al., 1979; Apanius et al., 1997; Penn, 2002; Sommer, 2005; Eizaguirre and Lenz, 2010). HA as an explanation for this high level of polymorphism was introduced almost 50 years ago by Doherty and Zinkernagel, 1975. The idea suggests that individuals with MHC-molecules from two different alleles are capable of recognising a broader spectrum of pathogens, resulting in higher fitness. This is especially evident when the MHC-molecules of the two alleles have complementary immune profiles (Pierini and Lenz, 2018), a phenomenon known as divergent allele advantage (Wakeland et al., 1990), and Stefan et al., 2019 show that this allows for the coexistence of alleles with larger variation in their immune efficiencies. Early theoretical work suggested that HA can maintain an arbitrarily high number of alleles if these alleles have appropriately fine-tuned homo- and heterozygote fitness values (Kimura and Crow, 1964; Wright, 1966; Maruyama and Nei, 1981). However, later work suggests that such genotypic fitness values are unlikely to emerge through random mutations (Lewontin et al., 1978). More mechanistic models have also failed to reliably predict very high allele numbers (Spencer and Marks, 1988; Hedrick, 2002; De Boer et al., 2004; Borghans et al., 2004; Stoffels and Spencer, 2008; Trotter and Spencer, 2008; Trotter and Spencer, 2013; Ejsmond and Radwan, 2015; Lau et al., 2015). As a result, HA plays only a minor role in current explanations of polymorphism at MHC loci (Hedrick, 1998; Gould et al., 2004; Wegner, 2008; Kekäläinen et al., 2009; Eizaguirre and Lenz, 2010; Lenz, 2011; Loiseau et al., 2011), despite empirical evidence for its existence (Doherty and Zinkernagel, 1975; Hughes and Nei, 1989; Jeffery and Bangham, 2000; Penn et al., 2002; McClelland et al., 2003; Froeschke and Sommer, 2005; Kekäläinen et al., 2009; Oliver et al., 2009; Lenz, 2011). Consequently, other mechanisms are suggested to be important for the maintenance of allelic diversity, such as Red-Queen dynamics, fluctuating selection, and disassortative mating (Apanius et al., 1997; Hedrick, 1998; Penn, 2002; Borghans et al., 2004; Wegner, 2008; Spurgin and Richardson, 2010; Loiseau et al., 2011; Ejsmond and Radwan, 2015; Ejsmond et al., 2023).
Our study challenges this status quo by demonstrating that HA is a potent force that can drive the evolution and subsequent maintenance of more than 100 alleles. To demonstrate that it is indeed HA that is responsible for allelic diversity in our model, we deliberately keep all aspects of the pathogen community fixed to exclude any Red-Queen dynamics. The novelty of our approach lies in the fact that we do not rely on hand-picked genotypic fitness values. Instead, these fitness values emerge from our eco-evolutionary models, where the allelic values that allow for extraordinary polymorphism are found by evolution in a self-organised process. We do not claim that HA is the only mechanism responsible for the diversity of MHC-alleles in nature. However, our results show that HA can be more important than currently recognised.
Model
We investigate the evolution at an MHC locus using mathematical modelling and computer simulations. In the following sections, we describe how genotypes map to immune response and ultimately to survival, followed by a description of our evolutionary algorithm.
We assume that the MHC-molecules produced by the two alleles at a diploid MHC locus determine the immune response based on antigen recognition against multiple pathogens present in the environment. Our approach is based on the following two key assumptions regarding the relationship between pathogen virulence and host fitness:
Virulent pathogens are lethal in the absence of an appropriate immune defence.
The effect of pathogens on host survival depends on host condition, with hosts in poorer condition being affected more strongly.
An implication of the second assumption is that the combined effect of multiple pathogens on host survival exceeds the sum of the effects of each pathogen alone.
To incorporate these two assumptions, we assume that the effect of pathogen attacks on host survival acts through the intermediary step of the host’s ‘condition’, which is a proxy for a suit of measurements describing an individual’s body composition and physiology (Wilder et al., 2016). In the absence of an adequate immune response, a pathogen attack reduces the condition of a host to zero, causing its death (assumption a). More generally, we assume that the probability to survive is an increasing function of condition and that a host clearing a pathogen is in a weaker condition afterward. Since the survival probability cannot exceed one, the function that maps condition to survival has to be saturating. Consequently, for high values of conditions, where the survival function has saturated, pathogens reducing condition have small effects on survival. As condition decreases, pathogen-induced reductions have larger effects on survival (assumption b). A natural biological intuition for assumption (b) can be drawn from examples like COVID-19 or influenza, where it is well known that these pathogens do not pose a high mortality risk to individuals in good condition, but can significantly increase mortality risk for individuals in poor condition (Thompson, 2004; Zhou et al., 2020).
A further assumption of our model is the existence of a trade-off between the efficiencies of MHC-molecules to induce a defence against different pathogens. Thus, no MHC-molecule can perform optimally with respect to all pathogens and an improved efficiency against one set of pathogens can only be achieved at the expense of a decreased efficiency against another set of pathogens. Under such trade-offs, an MHC-molecule can be specialised to detect a few pathogens with high efficiency, or, alternatively, be a generalist molecule that can detect many pathogens but with low efficiency. There is empirical support for the existence of such trade-offs. First, many MHC-molecules can detect only a certain set of antigens (Wakeland et al., 1990; Froeschke and Sommer, 2012; Eizaguirre et al., 2012; Chappell et al., 2015; Pierini and Lenz, 2018) and therefore provide different degrees of protection against different pathogens (Wakeland et al., 1990; Apanius et al., 1997; Eizaguirre and Lenz, 2010; Froeschke and Sommer, 2012; Eizaguirre et al., 2012; Cortazar Chinarro et al., 2022). Second, it has also been found that specialist MHC-molecules are expressed at higher levels at the cell surface while generalist MHC-molecules that bind less selectively are expressed at lower levels (Chappell et al., 2015), potentially to reduce the harm of binding self-peptides. This could explain the lower efficiency of generalist MHC-molecules.
We employ two approaches to model this trade-off. First, we use unimodal functions to model the match between MHC-molecules and pathogens. This approach has a long history in evolutionary ecology (e.g. Levins, 1968; Sheftel et al., 2018), and, when using Gaussian functions, the model becomes amenable to mathematical analysis. We envisage that these pathogen optima represent distinct pathogen species from diverse taxonomic groups such as fungi, viruses, bacteria, protists, helminths, and prions, among others (Schmid-Hempel, 2021). Hence, we expect these pathogen optima to remain approximately constant over the time scales considered in our model. By keeping all aspects of the pathogen community fixed, we exclude Red-Queen dynamics and ensure that the observed allelic polymorphism is driven solely by HA.
To demonstrate that the allelic diversity evolving in the Gaussian model does not dependent on the specificities of this model but rather results from the model fulfilling the above assumptions (a) and (b), we implement an alternative and more mechanistic approach to model pathogen recognition. Inspired by Borghans et al., 2004, in this approach, while keeping assumptions (a) and (b) intact, immune defence is based on the match between two binary strings (or bit-strings), one representing the MHC-molecule and the other a peptide of the pathogen. In this model, a single MHC-allele has the potential to detect several pathogens, which could be interpreted as the different pathogens being more closely related.
By explicitly modelling MHC efficiencies against various pathogens – rather than assuming a fixed proportion of pathogens detected per MHC-molecule (as, e.g., De Boer et al., 2004) – our model accounts for the possibility that MHC-molecules can have complementary immune profiles. When paired, complementary alleles produce fit heterozygotes able to detect an increased number of pathogen peptides (Pierini and Lenz, 2018), exemplifying the concept of divergent allele advantage in the sense of Wakeland et al., 1990.
Gaussian model
In this approach, we use Gaussian functions to model the ability of MHC-molecules to recognise different pathogens, as illustrated in Figure 1. Here, MHC-alleles and pathogens are represented by vectors and , respectively. The MHC-alleles code for MHC-molecules, and the ability of an MHC-molecule to recognise the kth pathogen is maximal if x=pk. This ability decreases with increasing distance between and . The decrease is modelled using an h-dimensional Gaussian function, as detailed in Equation A14. The nature of the trade-off can be varied by adjusting the positions of the pathogen optima and the shape of the Gaussian functions.
Figure 1

Efficiency against two pathogens (coloured lines in A–B) and three pathogens (coloured cones in C–D) as a function of allelic values .
Efficiencies are modeled with Gaussian functions with pathogen optima at equal distances (indicated by and in A, B). The width of the Gaussian functions, which determine how severely pathogens affect hosts with suboptimal major histocompatibility complex (MHC) molecules, is given by the virulence parameter . With high virulence (, narrow Gaussians in B, D), alleles away from the optima have a low efficiency, while for a low virulence (, wide Gaussians in A, C) efficiency is higher. Grey lines and cones give the condition of homozygote individuals. The generalist allele, maximising condition, is located at the centre with equal distance to all pathogen optima (indicated by in A, B).
Without loss of generality, we can reduce the dimension of the vectors and to , such that and . For example, in Figure 1A and B, where , the x-axis represents the unique line passing through two pathogen optima in a trait space of potentially much higher dimension. Similarly, in Figure 1C and D, where , the two-dimensional coordinate system represented by the grey surfaces describes the unique plane passing through three pathogen optima. Mathematically speaking, linearly independent pathogen optima form the basis of a vector space of dimension , which we choose as the coordinate system for the vectors and . Allelic vectors outside this set are necessarily maladapted for all pathogens along at least one dimension, and owing to our dimensionality reduction we ignore such trait vectors.
We examine two versions of the Gaussian model. The first one is based on two symmetry assumptions and shown in Figure 1: pathogen optima are placed symmetrically such that the distance between any two pathogens equals 1, and the Gaussian functions are isotropic (rotationally symmetric) and of equal width. This allows to simplify the covariance matrix in the Gaussian function (Equation A14) such that it can be replaced with a single parameter (Appendix ‘Model description’),
(1)
where the superscript indicates vector transposition. The parameter , to which we refer as virulence, is the inverse of the width of the Gaussian function. If the Gaussian function is narrow, corresponding to a high virulence , a pathogen causes significant harm if MHC-molecules are not well adapted against it (Figure 1B and D). On the other hand, if the Gaussian function is wide, corresponding to a low virulence , a pathogen causes less harm (Figure 1A and C).
We relax these symmetry assumptions in the second version, where we allow for Gaussian functions with arbitrary shape and position. Since the results for the two versions are similar, we here focus on the case with symmetry and refer to Appendices ‘Deviations from symmetry in the Gaussian model’, ‘Mode description’, and ‘Analytical results for the Gaussian model’ for results based on general Gaussian functions.
Bit-string model
Our second approach is inspired by Borghans et al., 2004, and commonly referred to as a bit-string model. Pathogens are assumed to produce peptides, and for a pathogen to cause virulence, all of its peptides have to avoid detection by the host’s MHC-molecules. We here equate MHC-alleles with the MHC-molecule they code for, and both MHC-molecules and pathogen peptides are represented by binary strings (or bit-strings) of, following Borghans et al., 2004, length 16.
The probability that an MHC-molecule detects a pathogen peptide increases with the maximum match length of consecutive matches between their binary strings. For an MHC-molecule and the kth peptide of the ith pathogen, this match length is denoted , or for short (see Figure 2A). The corresponding detection probability, denoted , is then given by the logistic function
(2)
Here, denotes the required match length for a 50% chance of detection. The parameter has again the interpretation of virulence, with higher values indicating pathogen peptides that are harder to detect by MHC-molecules. The positive parameter governs the steepness of the function . We choose , which results in equalling 10% when and 90% when (Figure 2B). Finally, the realised efficiency of an MHC-molecule against the kth pathogen is given by the probability of detecting at least one of its peptides, which equals
(3)
Figure 2
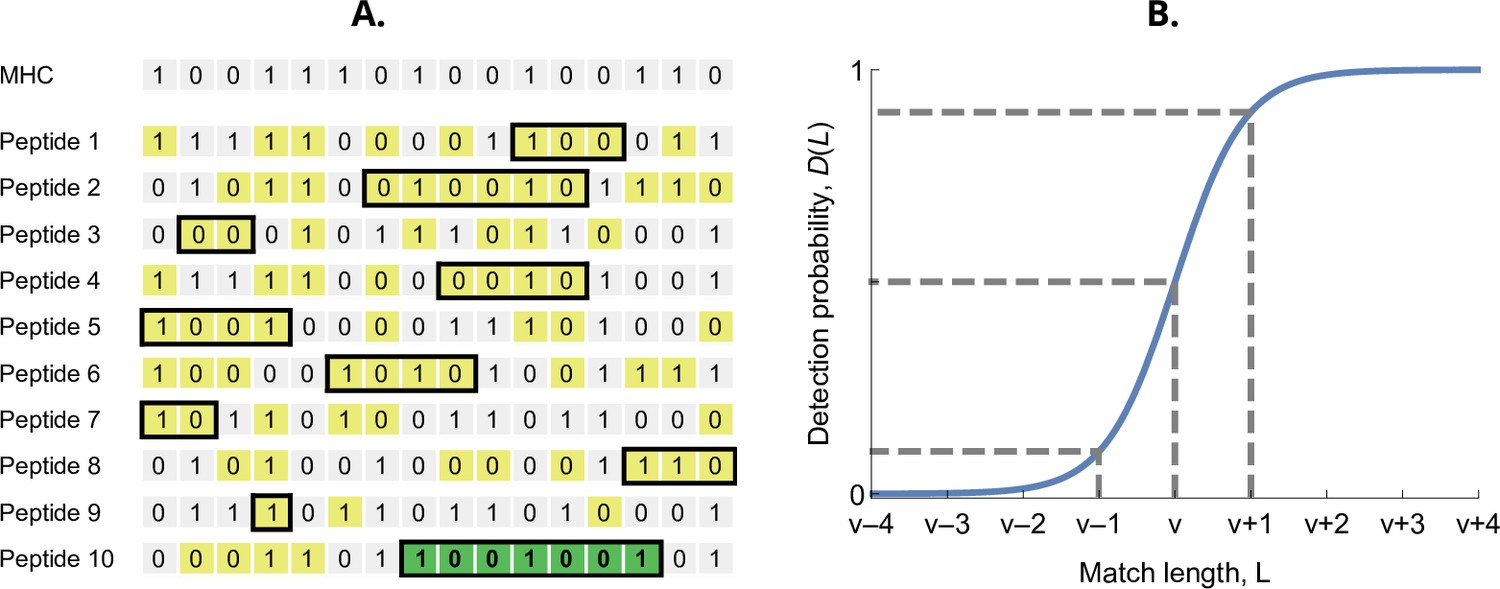
Detection probability in the bit-string model.
(A) Major histocompatibility complex (MHC) bit-string matching against a pathogen with peptides. Yellow indicates a match between MHC and peptide bits. The longest consecutive match per peptide () is indicated with a black box. The longest match over all peptides occurs for the last peptide, marked in green, with match length . (B) Detection probability for peptides as a function of match length (Equation 2 with ). The dashed lines indicate, from left to right, 10%, 50%, and 90% detection probability.
From immune defence to survival
For both versions of our model, we assume that MHC-alleles are co-dominantly expressed (Eizaguirre and Lenz, 2010; Abbas et al., 2014), and an individual’s efficiency to recognise pathogens of type is given by the arithmetic mean of the efficiencies from its two alleles. We want to note that assuming co-dominance gives more conservative results in terms of the number of coexisting alleles, as dominance would increase the degree of HA.
For each pathogen attack, an individual’s condition is reduced by a certain fraction that depends on the efficiency of the defence against that pathogen. Since each individual is exposed to all pathogens during their lifetime, the condition is determined by the product of its defences against all pathogens,
(4)
where and represent the MHC-alleles the host carries at the focal locus, and is the condition of a hypothetical individual with perfect defence against all pathogens (see Appendix ‘Model description’ for more details). Because , condition is reduced with each additional pathogen in a proportional manner. The multiplicative nature of Equation 4 has the effect that a poor defence against a single pathogen is sufficient to severely compromise condition, and therefore survival (see next paragraph), fulfilling assumption (a) above.
Finally, survival is an increasing but saturating function of an individual’s condition ,
(5)
Here, is the survival half-saturation constant, giving the condition required for a 50% chance of survival. This function fulfils assumption (b) above as long as is not too large. Individuals in good health then have a condition far above , and a decrease in condition only has a small effect on survival. If is lower than , then the host is in bad health and any additional pathogen causes a large reduction in survival (orange lines in bottom panel of Figure 3 and 6).
Figure 3
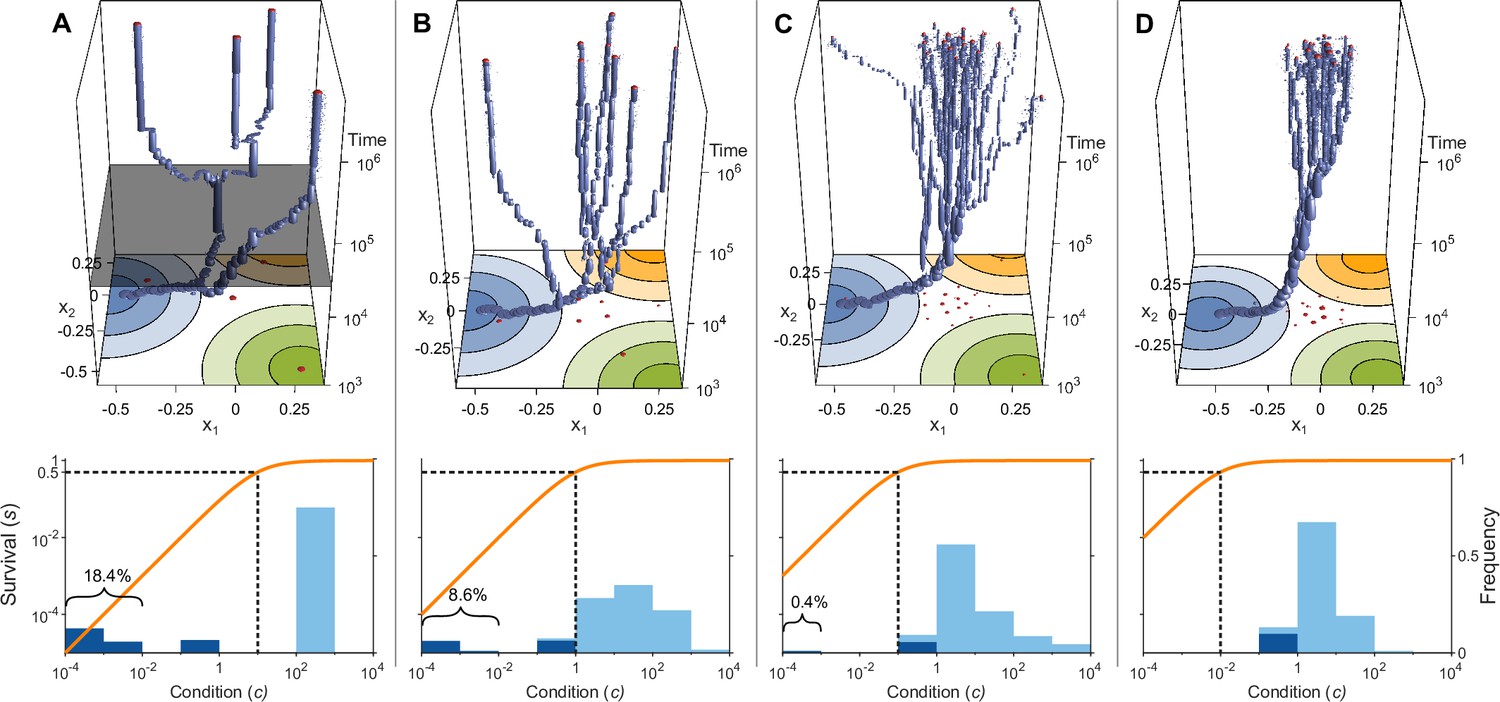
Evolution of allelic values under the Gaussian model in the presence of three pathogens (arranged as in Figure 1D) for four different values of the survival half-saturation constant (A: , B: , C: , D: ; dashed line in lower panel).
The top panel shows individual-based simulations. The two horizontal axes give the two allelic values that characterise an allele, while the vertical axis shows evolutionary time. The thickness of the blue tubes is proportional to allele frequencies. Allelic values at the last generation are projected as red dots on the top as well as on the bottom plane. Coloured circles represent the contour lines of the Gaussian efficiency functions as shown in Figure 1D. In all simulations, gradual evolution leads towards the generalist allele and branching occurs in its neighbourhood, as predicted by our analytical derivations (Appendix ‘The evolutionarily singular point’). In (A) there are three consecutive branching events with the second branching event marked by the grey plane (; for details regarding , see the legend of Figure 4). (B and C) show that, as decreases, the number of branching events increases, resulting in more coexisting alleles ( and , respectively). Finally, (D) reveals that, as decreases even further such that already low condition values result in high survival, the number of branching events decreases again, resulting in a set of alleles closely clustered around the generalist allele (). The bottom panel shows survival as a function of condition as defined by Equation 5 on a log-log scale (orange line, left vertical axis) and the frequencies of individual conditions at the final generation (dark blue bars for homozygotes and light blue bars for heterozygotes, right vertical axis; conditions from 0 to are incorporated into the first bar). These panels show that increased allelic diversity results in a lower proportion of homozygote individuals, which have lower survival. Other parameter values: , , , and .
In summary, Equations 4 and 5 entail that assumptions (a) and (b), as formulated above, are satisfied. Using two distinct models to describe the interaction of hosts and pathogens, which both impose a trade-off between the ability to detect different pathogens – namely the Gaussian and the bit-string model – we demonstrate below that HA emerges as a potent force capable of driving the evolution of a very high number of coexisting alleles.
Analysis
To study the evolutionary dynamics of allelic values in both the Gaussian and the bit-string model, we simulate a diploid Wright-Fisher model with mutation and selection (Fisher, 1930; Wright, 1931). Thus, we consider a diploid population of fixed size with non-overlapping generations and random mating. Individuals produce, independent of their genotype, a large number of offspring, resulting in deterministic Hardy-Weinberg proportions before viability selection. After viability selection, which is based on Equation 5 and adjusts the proportion of genotypes accordingly, stochasticity is introduced by random multinomial sampling of surviving offspring, which constitute the adult population of the next generation. Using this model, we follow the fate of recurrent mutations that occur with a per capita mutation probability µ. The long-term evolutionary dynamics is obtained by iterating this procedure (Figure 3, top panel) until the number of alleles equilibrates. This procedure can result in high numbers of coexisting alleles, where the emerging allelic polymorphism is driven by increasing the alleles’ expected survival (or marginal fitness, see Equations A5–A6 in Appendix ‘Adaptive dynamics and invasion fitness’).
For the Gaussian model, mutations are drawn from an isotropic normal distribution with expected mutational effect size (Appendix ‘Varying the expected mutational step size in the Gaussian model’). We here focus on mutations of small effect ( in Figure 3 and in Figure 4) and thus near-gradual evolution. The effect of smaller and larger effect sizes is investigated in Appendix ‘Varying the expected mutational step size in the Gaussian model’. To minimise computation time, simulations (other than those in Figure 3) are initialised at the trait vector that is given by the mean of the vectors describing the pathogens. In the bit-string model, the pathogens are each given randomly drawn bit-strings at the beginning of a simulation and the host population is initialised with a single MHC-allele given by a randomly drawn bit-string. Mutations change a random bit of the MHC-allele. The bit-string model can indeed only be analysed with computer simulations. In contrast, for the Gaussian model we can analytically derive conditions under which to expect either a single generalist allele or the build-up of allelic diversity through gradual evolution in a process known as evolutionary branching (Metz et al., 1992; Geritz et al., 1998; Kisdi and Geritz, 1999; Doebeli, 2011) (see Appendices ‘Mathematical analysis of the Gaussian model: Preliminaries’ and ‘Analytical results for the Gaussian model’ for details).
Figure 4

Number of coexisting alleles under the Gaussian model for pathogens as a function of pathogen virulence and the survival half-saturation constant .
Figures are based on a single individual-based simulation per pixel and run for 106 generations, assuring that the equilibrium distribution of alleles is reached. Results are reported in terms of the effective number of alleles , which is a conservative measure for the number of alleles, discounting for rare alleles present at mutation-drift balance (see Appendix ‘Effective number of alleles’). The clear pattern in the figures indicates a high degree of determinism in the simulations. Using population size and per capita mutation probability , the expected under mutation-drift balance alone equals 1.2 (see Appendix ‘Effective number of alleles’). Dashed and solid lines give the contours for and , respectively. Red arrows indicate , the threshold for polymorphism to emerge from branching (Equation A46). Accordingly, simulations in the dark blue area result in a single abundant allele with close to one. Other parameters: expected mutational step size .
Results
Gaussian model
In the simulations of the Gaussian model, the evolutionary dynamics first proceed towards a generalist allele with an intermediate efficiency against all pathogens, to which we refer to as . This generalist allele maximises the condition for homozygote genotypes (grey lines and cones in Figure 1, Appendix ‘Absolute convergence stability’). Once this generalist allele is reached, the evolutionary dynamics either stops (Appendix 2—figure 1), resulting in a population where all individuals are homozygous for , or allelic diversification ensues (Figure 3), resulting in the coexistence of specialist and generalist alleles. Based on the adaptive dynamics approximation, we show analytically (Appendix ‘The evolutionarily singular point’) that is given by the arithmetic mean of the vectors describing the pathogen optima (see Equation A26 in Appendix ‘The evolutionarily singular point’) and an attractor of any sequence of allelic substitutions. Whether is an evolutionary stable endpoint or an evolutionary branching point where diversification ensues depends on the covariance matrix of the pathogen optima relative to the covariance matrices of the Gaussian efficiency functions (Appendices ‘Derivation of the Hessian matrix of invasion fitness’, ‘Special case: identically shaped Gaussian efficiency functions’, and ‘Special case: maximal symmetry’). For the special case of identically shaped Gaussian functions, diversification occurs if and only if
(6)
(Appendix ‘Special case: identically shaped Gaussian efficiency functions’). Note, that this expression is independent of the number of pathogens . Under the additional assumption of equally distant pathogens and isotropic Gaussian functions, these covariance matrices are diagonal matrices with identical diagonal entries and , respectively, and Condition 6 simplifies to . When pathogen optima have an equal distance of 1, the variance among the optima decreases with an increasing number of pathogens , and the condition for evolutionary branching can be rewritten as
(7)
where (Appendix ‘Special case: maximal symmetry’).
Figure 4 presents the final number of coexisting alleles as derived from individual-based simulations. It shows that the number of coexisting alleles increases with the number of pathogens and their virulence , but also depends on the survival half-saturation constant (Equation 5). For a large part of the parameter space, more than 100 (solid contour lines in Figure 4) and up to over 200 alleles can emerge and coexist.
In order to better understand the process of allelic diversification, it is useful to inspect our analytical results in more detail. Evolutionary diversification occurs if mutant alleles exist that can invade a population that is monomorphic for the generalist allele . Initially, while still rare, such mutant alleles will always occur in heterozygous individuals, where they are paired with the generalist allele. Thus, our condition for evolutionary diversification, , is equivalent to . Since, as homozygotes, the generalist allele maximises condition and therefore survival (Appendix ‘Absolute convergence stability’), we also have . In conclusion, individuals heterozygous for and have higher survival than either homozygote, , and a polymorphism of these two alleles is maintained by HA, as suggested by Doherty and Zinkernagel, 1975. Furthermore, the generalist allele is an evolutionary branching point in the sense of adaptive dynamics theory (Geritz et al., 1998; Kisdi and Geritz, 1999).
The left-hand side of the diversification condition given byEquation 7 indicates that invasion of more specialised alleles is favoured when pathogen virulence is large (narrow Gaussian functions, see Figure 1A and C). In this case, homozygotes for the generalist allele are relatively poorly protected against pathogens and more specialised alleles enjoy a fitness advantage while invading. The opposite is true when is small (wide Gaussian functions, see Figure 1A and C). The right-hand side of the diversification criterion indicates that the benefit of specialisation decreases with an increasing number of pathogens (compare position of red arrows in Figure 4), because different pathogens require different adaptations. Thus, counter to intuition, initial allelic diversification is disfavoured in the presence of many pathogens.
If initial allelic diversification occurs, it leads to a dimorphism from which new mutant alleles can invade if they are more specialised than the allele from which they originated. Then, two allelic lineages emerge from the generalist allele and subsequently diverge (Figure 3A, up to below grey plane). Increasing the difference between the two alleles present in such a dimorphism has two opposing effects. The condition and thereby the survival of the heterozygote genotype increases because the MHC-molecules of the two more specialised alleles provide increasingly better protection against complementary sets of pathogens, i.e., these alleles are subject to a divergent allele advantage (Wakeland et al., 1990; Pierini and Lenz, 2018). On the other hand, survival of the two homozygote genotypes decreases because they become increasingly more vulnerable to the set of pathogens for which their MHC-molecules do not offer protection. Note that, due to random mating and assuming equal allele frequencies, half of the population are high survival heterozygotes and the remaining half homozygotes with low survival. Since survival is a saturating function of condition (Equation 5), it follows that the increase in survival of heterozygotes slows down with increasing condition (plateau of the orange curves in Figure 3), and the two opposing forces eventually balance each other such that divergence comes to a halt. At this point, our simulations show that the allelic lineages can branch again, resulting in three coexisting alleles. As a result, the proportion of low survival homozygotes decreases, assuming equal allele frequencies, from one-half to one-third. Subsequently, the coexisting alleles diverge further from each other because the increase in heterozygote survival once again outweighs the decreased survival of the (now less frequent) homozygotes (see Figure 3A, at time , grey plane). In Figure 3A, this process of evolutionary branching and allelic divergence repeats itself one more time, resulting in four coexisting alleles. Consequently, 10 genotypes emerge: four homozygotes and six heterozygotes. The homozygotes with specialist alleles have a condition, and thereby a survival, close to zero (two left bars in bottom panel). Conversely, the homozygote for the generalist allele has an intermediate condition (middle bar), and all heterozygote genotypes have a survival close to 1 (right bar).
In Figure 3B–D, the process of evolutionary branching and allelic divergence continues to recur. As a consequence, allelic diversity continues to increase while simultaneously the proportion of vulnerable homozygote genotypes decreases (Figure 3, lower panel). Thus, in contrast to prior approaches (e.g. Kimura and Crow, 1964; Wright, 1966; Lewontin et al., 1978; Maruyama and Nei, 1981), we do not rely on hand-picked genotypic fitness values. Instead, in our approach, fitness values emerge from an eco-evolutionary model where evolution can be viewed as a self-organising process finding large sets of alleles that can coexist (Figure 3, upper panel).
We note that the half-saturation constant does not appear in the branching condition and thus does not affect whether polymorphism evolves. However, does affect the final number of alleles, which is maximal for intermediate values of . This can be understood as follows. If is very large (right-hand side of the panels in Figure 4), then heterozygote survival saturates more slowly with increased allelic divergence so that continued allelic divergence is less counteracted. This hinders repeated branching (compare A and C in Figure 3). On the other hand, if is very small (left-hand side of the panels in Figure 4), then homozygous individuals can have high survival, which decreases the selective advantage of specialisation, leading to incomplete specialisation and a reduced number of branching events (compare D and C in Figure 3).
In summary, high virulence promotes allelic diversification. Increasing the number of pathogens has a dual effect: it hinders initial diversification but facilitates a higher number of coexisting alleles if diversification occurs, especially, for intermediate values of the half-saturation constant .
We perform several robustness checks. First, Appendix 4—figure 1 shows simulations in which we vary the expected mutational step size. These simulations show that the gradual build-up of diversity occurs most readily as long as the mutational step size is neither very small, since then the evolutionary dynamics becomes exceedingly slow, nor very large, since a large fraction of the mutants are then deleterious and end up outside the simplex made up of the pathogen optima (e.g. outside the triangle made up by the three pathogen optima in Figure 1C and D) so that they perform worse against all pathogens.
Second, the results presented in Figures 3 and 4 are based on the assumptions of equally spaced pathogen optima and equal width and isotropic Gaussian functions as shown in Figure 1. In Appendices ‘Analytical results for the Gaussian model’ and ‘Deviations from symmetry in the Gaussian model’, we present analytical and simulation results, respectively, for the non-symmetric case. In particular, Appendix 5—figure 1 shows that the predictions for the number of coexisting alleles presented here are qualitatively robust against deviations from symmetry. This is in line with Condition 6 and its simplification under full symmetry, , showing that the more general condition for the evolution of allelic polymorphism is structurally identical to the condition under full symmetry.
Bit-string model
Evolutionary diversification of MHC-alleles in the bit-string model is analysed with individual-based simulations, and the results are summarised in Figure 5. Similar to the Gaussian model, we find high levels of allelic polymorphism, with over 100 alleles coexisting in a significant portion of the parameter space. Note that we here keep the half-saturation constant fixed at 1. With this choice, the realised conditions occur both in the range where survival changes drastically with condition and where the survival function saturates (Figure 6), fulfilling assumption (b). This allows us to focus on the effect of the number of peptides per pathogen.
Figure 5

Number of coexisting alleles for the bit-string model for four values of virulence as a function of the number of pathogens (increased in steps of 7) and the number of peptides per pathogen .
Figures are based on a single individual-based simulation per pixel and run for 106 generations. Results are reported in terms of the effective number of alleles , which discounts for rare alleles present at mutation-drift balance (see Appendix ‘Effective number of alleles’). Using population size and per capita mutation probability , the expected under mutation-drift balance alone equals 3. Dashed and solid lines give the contours for and , respectively. Evolution started from populations monomorphic for a random allele, and run for generations, assuring that the equilibrium distribution of alleles is reached. Other parameters: half-saturation constant .
Figure 6
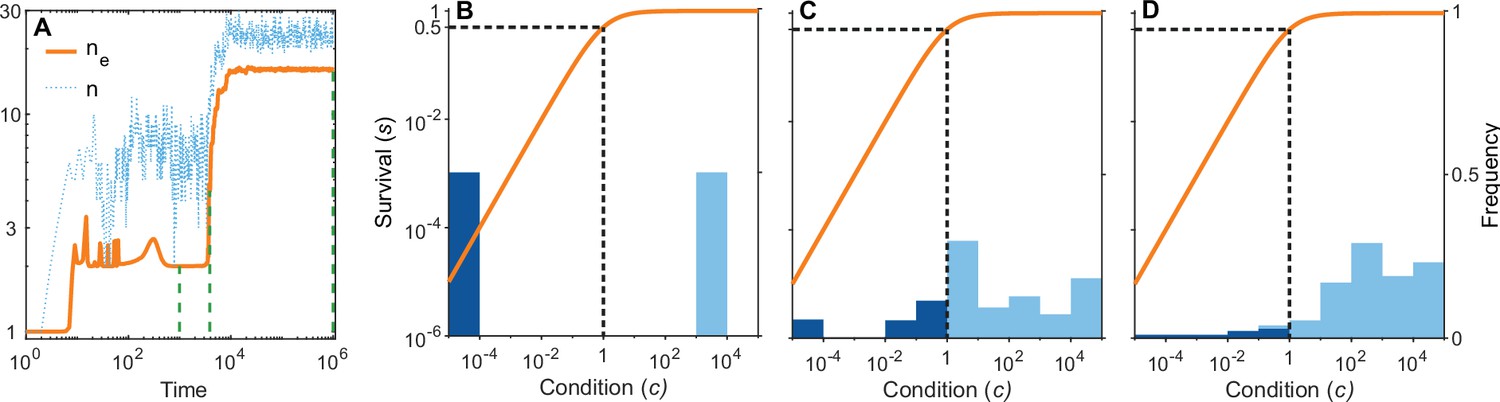
A simulation run showing the evolution of allelic diversity under the bit-string model in the presence of pathogens.
(A) shows the number of alleles and the effective number of alleles as a function of time (on a log-log scale). (B–D) give survival as a function of condition as defined by Equation 5 on a log-log scale (orange line, left vertical axis) and the distribution of conditions at three time points (B , C , D ; vertical green dashed lines in A), with dark blue bars for homozygotes and light blue bars for heterozygotes (right vertical axis; conditions from 0 to are incorporated into the first bar, and conditions from 104 and greater are incorporated in the last bar). This shows that as allelic diversity increases, the frequency of homozygotes with low survival decreases. The black dashed lines indicate the value of . Other parameter values: , , , , .
Our results can be understood as follows. The likelihood that an MHC-molecule can recognise all pathogens is high in the following regions of the parameter space. Firstly, if virulence is low, then peptide recognition is more likely (Equation 2). Secondly, if the number of pathogens is low, then detection of all pathogens is a simpler task. Thirdly, if the number of peptides per pathogen is high, then the potential for successful pathogen detection increases (Equation 3). Although our model is not sufficiently mechanistic to be directly related to parameters observed in nature, it suggests that when pathogens have a high number of peptides, maintaining allelic polymorphism requires a larger number of pathogens under conditions of low virulence (). For higher virulence (), the effect of weakens, and allelic polymorphism evolves seemingly independent of the number of pathogens. Each of these three circumstances facilitates the existence of a single best allele whose MHC-molecule recognises all pathogens with a high probability (dark blue regions in Figure 5).
As virulence or the number of pathogens increases, or as the number of peptides decreases, the task of recognising all pathogens with high probability becomes progressively more challenging. This leaves homozygous individuals vulnerable to an increasing array of pathogens. As homozygotes get more vulnerable, there is a growing advantage for heterozygotes carrying alleles with complementary immune profiles, as these are able to detect up to twice as many pathogens as either homozygote. This increasingly stronger HA, in turn, facilitates coexistence of an increasing number of alleles, illustrated by increasingly warmer colours in Figure 5, and thereby decreases the proportion of vulnerable homozygotes. Thus, similar to the Gaussian model, increasing either the virulence or the number of pathogens enables a higher number of alleles to coexist. However, unlike the Gaussian model, increasing actually facilitates initial diversification rather than hindering it.
Importantly, in the bit-string model, a point mutation, switching the value of an arbitrary bit in the bit-string, can drastically alter the efficiencies against a large set of pathogens. Because of this, and in contrast to the Gaussian model, a polymorphism maintained by HA can emerge from many different alleles. On the other hand, gradual evolution in the Gaussian model is more efficient in finding the evolutionary endpoint of complementary alleles (Figure 3), while for the bit-string model, as the number of alleles increases, this becomes slower due to the lack of fine-tuning as mutations have large effect. To compensate for this, we use, compared to the Gaussian model, a higher mutation probability µ and run simulations for more generations.
Figure 6A shows the build-up of allelic diversity over time in an exemplary simulation run, and Figure 6B–D show the distribution of condition values at three time points, as indicated by green hatched lines in Figure 6A. In Figure 6B the population is dimorphic. Due to random mating, half of the population consists of homozygotes with low condition (dark blue bar), while the remaining half are heterozygotes with high condition (light blue bar). As time proceeds, the number of coexisting alleles increases. Figure 6C depicts a stage with five coexisting alleles (with at least 1% frequency) and an effective number of alleles () of 4.4. Ultimately, evolution results in 19 coexisting alleles (with at least 1% frequency), and an of 16.1, as shown in Figure 6D. In this process, the number of low condition homozygotes decreases, as indicated by the dark blue bars.
Discussion
HA as an explanation for the coexistence of a large number of alleles at a single locus has a long history in evolutionary genetics. Kimura and Crow, 1964, and subsequently Wright, 1966 showed that HA can in principle result in the coexistence of an arbitrary number of alleles at a single locus if two conditions are met: (1) all heterozygotes have a similarly high fitness, and (2) all homozygotes have a similarly low fitness. One special class of genes fulfilling these assumptions occur at self-incompatibility loci, where mating partners need to carry different alleles for fertilisation to be successful (Wright, 1939; Castric and Vekemans, 2004), or loci where homozygosity is lethal (Ding et al., 2021). However, more generally these conditions were deemed unrealistic by Kimura, Crow, and Wright themselves. This assessment was subsequently confirmed by Lewontin et al., 1978, who investigated a model in which the exact fitnesses are determined by drawing random numbers in a manner that all heterozygotes are more fit than all homozygotes. They found that the proportion of fitness arrays that leads to a stable equilibrium of more than six or seven alleles is vanishingly small. Similarly, the idea that the high allelic diversity found at MHC loci can be explained by HA was initially accepted by theoreticians (e.g. Maruyama and Nei, 1981; Takahata and Nei, 1990), but several later authors studying models based on more mechanistic assumptions were unable to reliably predict the coexistence of significantly more than 10 alleles (Spencer and Marks, 1988; Hedrick, 2002; De Boer et al., 2004; Borghans et al., 2004; Stoffels and Spencer, 2008; Trotter and Spencer, 2008; Trotter and Spencer, 2013; Ejsmond and Radwan, 2015; Lau et al., 2015). Thus, currently HA is largely dismissed as an explanation for highly polymorphic loci (Gould et al., 2004; Eizaguirre and Lenz, 2010; Lenz, 2011; Hedrick, 2012).
Our study, while not meant to be a highly realistic mechanistic representations of the interaction between MHC genes and pathogens, serves as a proof of principle that a high number of alleles, matching those found at MHC loci in natural populations, can indeed arise in an evolutionary process driven by HA. Our results thus revive the idea that HA has the potential to explain extraordinary allelic diversity. Importantly, and in contrast to several of the above-mentioned studies, this is achieved without making direct assumptions about homozygote and heterozygote fitnesses. Instead, our results emerge from two assumptions about how pathogens affect a host’s condition and how this, in turn, affect survival. Assumption (a) states that pathogens are lethal in the absence of an appropriate immune response. This assumption is implemented in our model by assuming that each pathogen decreases a host’s condition in a proportional manner (Equation 4), rather than by a fixed amount. Assumption (b) states that the effect of pathogens depends on host condition, with hosts in poorer condition being affected more strongly. Then, the combined effect of multiple pathogens on host survival exceeds the sum of the effects of each pathogen alone. Thus, many pathogens against which a host has an imperfect immune response can collectively push a host’s condition below a threshold where mortality becomes rather high (orange lines in Figures 3 and 6). In our model, this assumption is fulfilled rather naturally. Since the probability to survive can logically not exceed 1, the function that maps condition to survival has to be saturating (Equation 5).
In the following, we detail how assumptions (a) and (b) can result in the emergence of well over 100 alleles such that heterozygotes have similarly high fitness (condition (1) of Kimura and Crow) and homozygotes have similarly low fitness (condition (2) of Kimura and Crow). We start with the observation that the survival probabilities in evolved polymorphic populations vary between individuals (lower panels in Figures 4 and 5B–D). Part of the population consists of individuals that have very low survival probabilities. These are individuals with a condition value considerably less than and they are almost exclusively homozygotes. This is because, whenever polymorphism is favoured, homozygotes are poorly defended against some pathogens and the fact that pathogens affect condition multiplicatively (Equation 4). The remaining part of the population consists of individuals with condition values considerably above . Although the condition of these individuals can differ by several orders of magnitude, their survival is close to 1, which results from the fact that the function that maps condition to survival is saturating. These individuals are almost exclusively heterozygotes. This is because alleles that protect against complementary sets of pathogens, when paired together, offer at least a decent protection against all pathogens. In summary, our assumptions (a) and (b) lead to a set of alleles such that their survival probabilities fall into two clusters as required for conditions (1) and (2) of Kimura and Crow, 1964 to be fulfilled. The larger the number of alleles, the lower becomes the proportion of vulnerable homozygotes, and the population consists increasingly of almost equally fit heterozygotes.
Borghans et al., 2004 use a bit-string model similar to ours with pathogens, peptides, a virulence of and a step function for the probability that an MHC-molecule detects a peptide ( in Equation 2). In contrast to our model, they assume that an individual’s condition equals the proportion of detected pathogens, meaning that each pathogen can reduce fitness by only 2% (thereby not fulfilling our assumption a). Additionally, they assume that survival is proportional to the squared condition (not fulfilling our assumption b). Appendix 6—figure 1 shows a run of our bit-string model with the parameter values used by Borghans et al., 2004, resulting in more than 100 coexisting alleles. In contrast, they find only up to seven coexisting alleles, demonstrating that assumptions (a) and (b) in our model drive the high number of coexisting alleles found by us.
Currently, there are several mechanisms proposed to explain the diversity observed at MHC loci. First, in the presence of an HA, each allele has an advantage when rare because it almost always occurs in heterozygotes. Thus, there is negative frequency-dependent selection acting at the level of the allele. In addition, negative frequency-dependent selection can arise from, for example, Red-Queen dynamics, fluctuating selection, and disassortative mating (Apanius et al., 1997; Hedrick, 1998; Penn, 2002; Borghans et al., 2004; Wegner, 2008; Spurgin and Richardson, 2010; Loiseau et al., 2011; Ejsmond and Radwan, 2015; Lighten et al., 2017; Ejsmond et al., 2023). These mechanisms are similar to HA in the sense that the selective advantage of an allele increases with decreasing frequency. However, they do not result in heterozygotes being more fit than the homozygotes carrying the rare allele. In addition, neutral diversity can be enhanced by recombination (Klitz et al., 2012; Linnenbrink et al., 2018; Robinson et al., 2017). If many individuals are heterozygous, the particularly high levels of gene conversion found at MHC genes can be effective in creating new allelic variants. For instance, for urban human populations with a large effective population size of and a per capita gene conversion probability of an effective number of alleles as high as can theoretically be maintained by gene conversion (Klitz et al., 2012). However, it is important to point out that for gene conversion to increase allelic diversity, some genetic polymorphism due to balancing selection has to exist to start with. We do not claim that the mechanisms listed here do not play an important role in maintaining allelic diversity at MHC loci. Rather, our results show that, contrary to the currently widespread view, HA should not be dismissed as a potent force. In any real system, different mechanisms will jointly affect allelic diversity. For instance, Lighten et al., 2017 present a model in which, for Red-Queen co-evolution to maintain allelic polymorphism, HA in the form of a divergent allele advantage (Wakeland et al., 1990) seems to be a necessary ingredient. Similarly, Borghans et al., 2004 show that pathogen co-evolution can further increase the number of coexisting alleles compared to HA alone.
The aim of our study is to understand how HA on its own can result in allelic polymorphism. For this reason, we kept all aspects concerning pathogens fixed, focusing on a scenario where pathogen optima represent diverse taxonomic groups that remain approximately constant over the time scales considered in our model. This approach excludes Red-Queen dynamics and fluctuating selection. Models of Red-Queen dynamics are based that pathogens evolve to avoid detection by the host’s immune system (Borghans et al., 2004; Ejsmond and Radwan, 2015; Ejsmond et al., 2023). In our model, this would correspond to moving pathogen optima (in the Gaussian model) or changes in the pathogen peptides (in the bit-string model). We expect that incorporating this would hamper the build-up of allelic MHC diversity when driven solely by HA if pathogens evolve quickly. Alleles previously maintained as beneficial would then become disadvantageous and go extinct more rapidly than new advantageous alleles can appear.
Another component of pathogens that can evolve in response to host immune defence is their virulence (Frank and Schmid-Hempel, 2008). The transmission-virulence trade-off hypothesis (Anderson and May, 1982; Frank, 1996; Alizon et al., 2009) predicts that pathogens that cause relatively little harm to their host (i.e. pathogens with low virulence) may evolve towards higher virulence to increase their transmission rate. In line with this hypothesis, we speculate that incorporating virulence evolution leads to higher virulence whenever pathogens inflict little harm on their hosts. This scenario applies in the dark blue parameter regions in Figures 4 and 5, where host populations possess a single effective generalist allele. In these regions, the evolution of increased virulence would shift pathogens into parameter regions where allelic polymorphism becomes adaptive. The ensuing build-up of allelic polymorphism decreases the harm inflicted by pathogens through HA, which, in turn, increases the selection pressure acting on pathogens for an even further increase in virulence. This suggests, in contrast to evolving pathogen optima, a positive feedback loop between virulence evolution and the evolution of allelic diversity.
Our Gaussian model is not restricted to MHC genes, but can apply to any gene that affects several functions important for survival. Examples are genes that are expressed in different ontogenetic stages or different tissues with competing demands on the optimal gene product. However, gene duplication is expected to reduce the potential number of coexisting alleles per locus and eventually lead to a situation where the number of duplicates equals the number of functions (Proulx and Phillips, 2006). Under this scenario, the high degree of polymorphism reported here would be transient. However, for MHC genes evidence exist that other forces limit the number of MHC loci (Penn, 2002; Wegner, 2008; Eizaguirre and Lenz, 2010; Spurgin and Richardson, 2010). But it is important to point out that, while our model focuses on evolution at a single MHC locus, many vertebrates have more than one MHC locus with similar functions (Wegner, 2008; Eizaguirre and Lenz, 2010; Spurgin and Richardson, 2010). The diversity generating mechanism described here still applies if the different loci are responsible for largely non-overlapping sets of pathogens, indicating that the mechanism presented here can in principle explain the high number of coexisting MHC-alleles.
In summary, our research offers a fresh view that can help us to understand allelic diversity at MHC loci. We identify two crucial assumptions related to pathogen-host interactions, under which we show that HA emerges as a potent force capable of driving the evolution of a very high number of coexisting alleles.
Appendix 1
Effective number of alleles
Here, we provide the calculations for the effective number of alleles reported in Figures 4 and 5. The effective number of alleles is given by the reciprocal of the population homozygosity , where denotes the frequency of allele in the population (Kimura and Crow, 1964). Under mutation-drift balance, the expected homozygosity is approximated by (Gillespie, 2004), where is population size and µ the per capita mutation probability.
Thus, under mutation-drift balance, the expected value of equals . For Figure 4, where and , the expected value of is 1.2. In Figure 5, with and , the expected value for is 3. Hence, -values significantly higher than these expectations indicate the presence of alleles maintained by balancing selection.
It is worth noting that when alleles are at equal frequencies , is equal to . In our model, both conditions (1) and (2) of Kimura and Crow, 1964, are approached at evolutionary equilibrium (i.e. heterozygote having similar and high fitness while homozygote having similar and low fitness), as elaborated in the Discussion. As a result, alleles maintained by HA are maintained at roughly similar frequencies. Consequently, gives a good estimate for the number of alleles that coexist in a protected polymorphism due to HA, rather than being maintained in a balance between mutation and drift.
Appendix 2
Evolutionary dynamics without diversification
Appendix 2—figure 1

Evolution of allelic values in the presence of three pathogens.
This figure is analogous to Figure 3 (see that legend for details) but with wider Gaussians (, as in Figure 1C). As a consequence, the condition for evolutionary branching () is not fulfilled and the evolutionary dynamics result in a monomorphic population consisting essentially of only the generalist allele . This result is independent of the half-saturation constant , here chosen to be .
Appendix 3
Table of mathematical notation
List of all mathematical symbols used in the Supplementary Information. Bold italic font indicates vectors (e.g. ) while normal italic font indicates numbers or scalar-valued functions. Capital letters in sans serif font indicate matrices (e.g. ).
| Notation | Explanation |
|---|---|
| condition function | |
| maximum condition | |
| mutational covariance matrix | |
| peptide detection probability (bit-string model) | |
| expected mutational step size (Gaussian model) | |
| efficiency function for pathogen | |
| frequency of allele | |
| dimensionality of the allelic trait space | |
| Hessian matrix | |
| identity matrix | |
| Jacobian matrix | |
| half-saturation constant of survival function | |
| number of pathogens | |
| per capita mutation probability | |
| number of alleles | |
| effective number of alleles | |
| population size | |
| vector describing the kth pathogen (Gaussian model) | |
| survival function | |
| maximum survival | |
| covariance matrix of the Gaussian efficiency function for pathogen (Equation A14) | |
| covariance matrix of the Gaussian efficiency function , assuming equal covariance matrices for all pathogens | |
| variance of the Gaussian efficiency function , assuming full symmetry matrices for all pathogens | |
| covariance matrix of the position of the pathogen vectors (Gaussian model) | |
| variance of the position of the pathogen vectors, assuming equally distant pathogen optima (Gaussian model) | |
| virulence; given by for the Gaussian model and the detection threshold value in the bit-string model | |
| allelic trait vector of allele | |
| allelic trait vector of a resident allele | |
| allelic trait vector of rare mutant allele |
Appendix 4
Varying the expected mutational step size in the Gaussian model
For the Gaussian model, mutations are drawn from an isotropic normal distribution, i.e., a matrix with covariance matrix of dimension . The expected mutational step size is given by times the expected value of the Chi-distribution (Equation 18.14 in Johnson et al., 1994),
(A1)
Appendix 4—figure 1
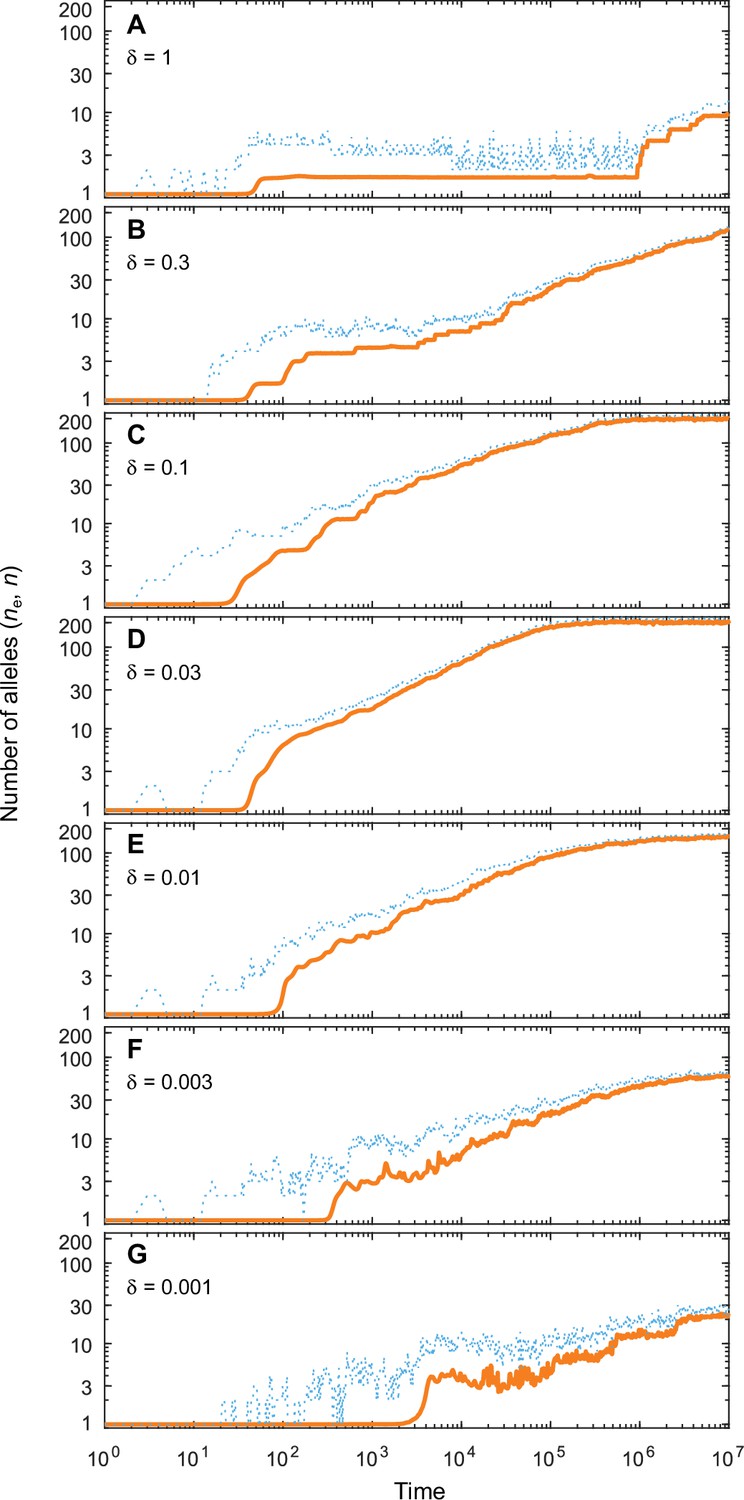
Number of coexisting alleles as they emerge in individual-based simulations for different expected mutational step sizes and eight pathogens ().
Parameters are chosen such that up to 200 alleles can evolve (, ; see bottom right panel in Figure 4 in the main text). Solid orange lines and dotted blue lines give the effective number and the absolute number of alleles, respectively. The number of alleles increases fastest and saturates earliest for an intermediate expected mutational step size of (D; pathogen vectors are average mutational steps apart) as used in Figure 4. Decreasing the average mutational step size slows down the build-up of allelic diversity (E–G). In the extreme case shown in G (pathogen vectors are 1/0.001 = 1000 average mutational steps apart), the evolutionary dynamics is strongly limited by the rate of phenotypic change due to the small step size and the number of alleles after 107 time steps has reached only 10% the number reached in D. Increasing the average mutational step size also slows down the build-up of allelic diversity (A–C). In the extreme case shown in A (pathogen vectors are 1.25 average mutational steps apart), the evolutionary dynamics are strongly limited by the very large proportion of maladapted mutants. Other parameters (as in Figure 4): , .
Appendix 5
Deviations from symmetry in the Gaussian model
The number of coexisting alleles for different parameter combinations are shown in Figure 4 in the main text. These results are based on two symmetry assumptions. First, the points describing by the pathogen vectors are placed equidistantly with , resulting in a regular -simplex. Second, the multivariate Gaussian functions describing the MHC-molecule’s efficiencies against the different pathogens are isotropic and have equal width, as shown in Figure 1. Thus, the covariance matrices in Equation A14 are equal to , where is the identity matrix. Here, we test the robustness of the outcome shown Figure 4 with respect to violations of these symmetry assumptions. We focus on the case with eight pathogens, and the results are summarised in Appendix 5—figure 1. Panel A is identical to the bottom right panel in Figure 4, and shown here for comparison. Panels B–D show the final number of coexisting alleles for increasing deviations from symmetry, as explained in the following. Note that each pixel in the figure is based on a single simulation with a unique random perturbation from symmetry.
In Appendix 5—figure 1B the assumption of symmetrically placed pathogen vectors is perturbed while the Gaussian functions are kept rotationally symmetric with equal width. Section ‘Random placement of pathogen vectors’ describes the procedure how the positions of the pathogen vectors are randomised. The similarity between panels A and B indicates that deviations from a symmetric placement of pathogen vectors has a minor effect on the number of coexisting alleles. The slightly decreased smoothness of the contours corresponding to 50 and 100 coexisting alleles stems from the fact that each simulation (corresponding to a pixel) is based from a unique perturbation. Note that polymorphism can emerge for values of such that the branching condition derived for the symmetric case is not fulfilled (below the red arrow). This can be understood based on the expression for the Hessian matrix given in Equation A43. This Hessian matrix is more likely to be positive definite for asymmetrically placed pathogen vectors.
Appendix 5—figure 1

Number of coexisting alleles for eight pathogens as a function of pathogen virulence and the half-saturation constant for symmetrically (A) and non-symmetrically placed pathogen vectors (B–D).
Figures are based on a single individual-based simulation per pixel and run for 106 generations, assuring that the equilibrium distribution of alleles is reached. (A) shows results for equally spaced pathogen vectors and isotropic functions (Equation A14). It is identical to the bottom right panel in Figure 4 and shown here for comparison. (B–D) show the result for increasing perturbations from symmetry. In (B), pathogen vectors are placed randomly (see Section ‘Random placement of pathogen vectors’ for details) while the functions are kept rotationally symmetric. In (C) and (D), additionally to the non-symmetric placement of pathogen vectors, the functions are independently perturbed from rotational symmetry (see Appendix ‘Random covariance matrices for the pathogen efficiencies’ for details). In (C) the deviations from rotational symmetry are moderate, while in (D) they are strong. Note that in (B–D) pathogen vectors are no longer at a constant distance 1, but instead have the mean variance calculated from the pathogen optima corresponds to the variance of symmetrically placed pathogens optima with distance 1. Results are reported in terms of the effective number of alleles , which discounts for alleles arising from mutation-drift balance (see Appendix ‘Effective number of alleles’). Dashed and solid lines give the contours for and , respectively. Red arrows indicate , the minimal value for polymorphism to emerge from branching under full symmetry (Equation A46). Accordingly, simulations in the dark blue area result in a single abundant allele with close to one. Other parameters: population size , per capita mutation probability , expected mutational step size .
In Appendix 5—figure 1C and D we, additionally to the non-symmetric placement of pathogen vectors, allow for Gaussian functions that are not isotropic. The variances of the perturbed covariance matrices are drawn from the interval and constrained such that the average variance is equal to 1, and then rotated randomly. Section ‘Random covariance matrices for the pathogen efficiencies’ describes this procedure in detail. Panel C shows the result for modest () and panel D for strong () deviations from rotational symmetry. Comparing panels C to B indicates that modest deviations from rotational symmetry have a relatively minor effect on the final number of coexisting alleles. In contrast, in panel D configurations exist where significantly fewer alleles are able to coexist. Interestingly, configurations resulting in a high number of alleles are more likely to occur in combination with high -values. The highly irregular pattern results from each pixel corresponding to a single simulation with a unique random perturbation from symmetry. Furthermore, the threshold for polymorphism decreases even more because the Hessian matrix given in Equation A42 is even more likely to be positive definite with perturbations in .
Random placement of pathogen vectors
We here describe how we randomly place eight pathogen vectors in trait space. In order to keep the results comparable to the symmetric case, we keep the average variance calculated from the position of their mid-points constant. The distribution of eight pathogen vectors can be described by their seven dimensional covariance matrix calculated from the coordinates . Since each diagonal element of describes the variance of the pathogen vectors along a different dimension of the trait space, the average variance equals , where denotes the trace. This measure is unaffected by rotation of the points . For symmetrically placed pathogen vectors , where denotes the identity matrix, and therefore . For the pathogens with perturbed placements (with covariance matrix ), we demand . We achieve this by first choosing eight preliminary points that are placed randomly within a unit 7-sphere, having the covariance matrix . By subsequently multiplying the coordinates of these points by a scalar , the variances in are multiplied by . By setting
(A2)
with , we obtain the final set of pathogen vectors with a covariance matrix fulfilling .
Random covariance matrices for the pathogen efficiencies
We here describe how we create random covariance matrices . In order to keep the results between the symmetric and asymmetric case comparable, we fix the mean variance over all to . We obtain the eight random covariance matrices in the following manner. First, eight random diagonal matrices are determined (one per pathogen vectors) with entries drawn from a uniform distribution . These matrices are then multiplied with the scalar
(A3)
with to obtain the set of matrices obeying . In a final step, we draw eight random rotation matrices and calculate our final covariance matrices as .
Appendix 6
Simulation run of the bit-string model with parameter values as in Borghans et al., 2004
Appendix 6—figure 1
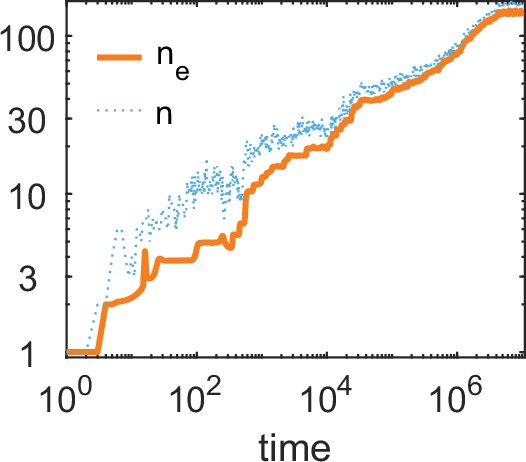
The number of alleles and the effective number of alleles as a function of time (on a log-log plot) for a simulation run of our bit-string model.
Parameters values: and . Other parameters as in Borghans et al., 2004: , , .
We here present a comparison of our bit-string model with that of Borghans et al., 2004. These authors analyse a bit-string model with pathogens (that are allowed to mutate but are not subject to selection), with peptides each, a virulence of (with a step function for the probability that an MHC-molecule detects a peptide), a population size of , and a per capita mutation probability of . In contrast to our model, they assume that condition equals the proportion of detected pathogens, such that each pathogen can lower fitness by only 2% (not fulfilling our assumption a) and that survival is proportional to the squared condition (not fulfilling our assumption b). With these parameters and parameter values, their simulation results in up to seven alleles. We note, that the effective number of alleles in these simulations is likely lower, but no allele frequencies are given.
We contrast their results with those from our model, which, as detailed in the main part, fulfils assumptions (a) and (b). To approximate the step function for the detection probability, we use
(A4)
For this function, is the required match length for a 99% chance of detection, while a match length gives only 1% detection probability. Note, that compared to Equation 2, we here subtract in the denominator and . Then, our model with the exact same parameters (omitting pathogen mutations) results in 18 alleles and , clearly exceeding the number of alleles found by Borghans et al., 2004.
Based on Kimura and Crow, 1964, for the above and the effective number of alleles that can be maintained by HA cannot exceed at mutation-drift-selection balance. This suggests that the allelic diversity found by Borghans et al., 2004, is likely not limited by the parameters affecting mutation and drift, and . In contrast, our final number of alleles (being 95% of the maximum) is likely limited by these parameters. To demonstrate that this is indeed the case, we simulate our model with and , as shown in Appendix 6—figure 1. We find well over 100 alleles ( and ). This demonstrates that the ecological parameter values used by Borghans et al., 2004, , , and , under our model allows for more than a 20-fold higher allelic diversity.
Appendix 7
Mathematical analysis of the Gaussian model: preliminaries
Adaptive dynamics and invasion fitness
For the Gaussian model presented in the main part, we investigate with an evolutionary invasion analysis using the adaptive dynamics formalism (Metz et al., 1992; Dieckmann and Law, 1996; Geritz et al., 1998) whether selection favours a single generalist allele or a polymorphic population. In the language of adaptive dynamics, we ask whether a monomorphic population evolves towards an evolutionary branching point, where two coexisting allelic lineages emerge.
Let us consider a large population of individuals with two segregating alleles and under Wright-Fisher population dynamics (Fisher, 1930; Wright, 1931). The allelic frequencies at time are denoted and , respectively.
The recurrence equation for the change of frequency of an allele is then given by
(A5)
where is the survival of an individual carrying the alleles and (see Equation A12) and
is the population mean survival at time . Note, that the expression within brackets on the right-hand side of Equation A5 describes the marginal fitness of allele .
Consider a resident population carrying allele to which a mutant allele is introduced. In the limit of a mutant allele frequency close to zero, its marginal fitness is given by
(A6)
We refer to as invasion fitness, which is the expected long-term exponential growth rate of an infinitesimally rare mutant allele in a resident population with allele (Metz et al., 1992; Metz, 2008). Allele has a positive probability to invade and increase in frequency if and disappears otherwise.
We denote the gradient of invasion fitness with respect to the mutant allele , evaluated at , with . It has the entries
(A7)
and gives the direction in the h-dimensional allelic trait space in which deviations from result in the fastest increase of invasion fitness.
If mutations rarely occur, a mutant allele will either go extinct or reach an equilibrium frequency before the next mutant appears. If, additionally, and mutational effects are sufficiently small (i.e. for small), then invasion of implies extinction of (Dercole and Rinaldi, 2008; Priklopil and Lehmann, 2020).
In the limit of small mutational steps, the evolutionary dynamics of an allelic lineage becomes gradual and is given by
(A8)
(Dieckmann and Law, 1996; Champagnat et al., 2006; Durinx et al., 2008; Metz and de Kovel, 2013). Here, is the per capita mutation probability and the covariance matrix for the distribution of mutational effects on the trait .
We note that Equation A8 is structurally similar to the gradient equation of quantitative genetics, which is based on the assumption of weak selection or, equivalently, small genetic variances (Lande, 1979; Iwasa et al., 1991; Abrams et al., 1993; Débarre et al., 2014). In this case, characterises the mean of the phenotype distribution, the covariance matrix describes the distribution of the standing genetic variation, and the factor is replaced with a constant.
Allelic trait values where are of special interest, and such are referred to as evolutionarily singular points .
Evolutionarily singular points can be either attractors or repellers of the evolutionary dynamics described by Equation A8. Furthermore, an evolutionarily singular point can be either invadable or uninvadable by nearby mutants. For a resident allele with a one-dimensional trait , a classification of singular strategies is straightforward (Geritz et al., 1998). Evolutionarily singular points that are not approached, irrespective of whether they are invadable or uninvadable, act as repellers, and we do not expect to ever find resident alleles with such values. Evolutionarily singular strategies that are attractors and uninvadable are endpoints of the evolutionary dynamics. Finally, evolutionarily singular points that are attractors and invadable are known as evolutionary branching points. In this case, any nearby mutant can invade the singular point and coexist with it in a protected dimorphism. Further evolution leads to divergence of the alleles present in the dimorphism. Thus, evolutionary branching points are points in trait space at which diversity emerges (Geritz et al., 1998; Rueffler et al., 2006).
The classification of singular points becomes more complicated in multivariate trait spaces or when several strategies coexist in an evolutionarily singular point (Leimar, 2009; Doebeli, 2011; Geritz et al., 2016). First, in multivariate trait spaces or polymorphic populations, whether a singular point is an attractor does not only depend on the direction of the fitness gradient in the vicinity of the singular point but also on the mutational input (Leimar, 2009). Second, in multivariate trait spaces or polymorphic populations, for evolutionary branching it is necessary that a singular point is an attractor and invadable. However, in the multidimensional case, this is generally not sufficient any more (Geritz et al., 2016).
In Section ‘The evolutionarily singular point’, we show for our model that a unique singular point exists. This allele is uninvadable if it is a minimum of as a function of . This is the case if the -dimensional Hessian matrix with entries
(A9)
is negative definite (Leimar, 2009; Doebeli, 2011). In Section ‘Derivation of the Hessian matrix of invasion fitness’ we derive an explicit expression for for the fully general case of our model that allows to determine invadability of as a function of the positions of the pathogen vectors, the half-saturation constant , and the covariance matrices that determine the shape of the efficiency functions .
Whether the singular point is an attractor of the evolutionary dynamics can be evaluated based on the Jacobian matrix of the fitness gradient (Leimar, 2009), which is given by
(A10)
and where is the -dimensional matrix of mixed derivatives with entries
(A11)
Leimar, 2009, shows that if the symmetric part of , i.e., , is negative definite, then the singular point is an attractor of the evolutionary dynamics described by Equation A8 independent of the mutational covariance matrix and he refers to this case as strong convergence stability. For the case that the Jacobian matrix is a symmetric negative definite matrix, a stronger result holds, to which he refers to as absolute convergence stability (Leimar, 2002; Leimar, 2009). In this case, all conceivable gradualistic, adaptive paths starting near the point converge to it. Furthermore, he shows that the condition for absolute convergence stability is equivalent to the existence of a function having a maximum at and a positive function such that the gradient of invasion fitness can be expressed as
In Section ‘Absolute convergence stability’, we show for our model that is indeed absolutely convergence stable.
For the case of two-dimensional trait spaces, results in Geritz et al., 2016, allow us to conclude that if is invadable, then it is indeed an evolutionary branching point. For trait spaces of dimension three or higher, whether convergence stability and invadability imply evolutionary branching is an open problem (Geritz et al., 2016). Individual-based simulations indicate, however, that for our model this is indeed the case.
Model description
In this section, we describe the model ingredients. Survival of a genotype carrying alleles and is a saturating function of condition and described by the well-known Michaelis-Menten equation
(A12)
Here, the half-saturation constant gives the condition at which half of the maximum survival is reached and is the maximum survival probability that is approached when becomes large.
The condition of a genotype is given by
(A13)
where is the condition of a hypothetical individual with perfect defence against all pathogens and is the efficiency of an allele’s MHC-molecule against pathogen in an environment with pathogens.
Without loss of generality, is standardised to 1 (by choosing in Equation A13 appropriately). This is helpful because it allows us to choose an interval of -values where individuals homozygous for the generalist allele have either a condition in the range where survival changes rapidly () or slowly () with condition. In Figure 4, Appendix 5—figure 1, the x-axis can be translated into survival of the generalist genotype using Equation A12, which then varies between 0.01 for and 0.99 for .
We assume that the efficiencies of inducing immune defence against the different pathogens are traded off. This trade-off emerges by describing the efficiencies against different pathogens with multivariate Gaussian functions (see Figure 1) that have pathogen-dependent optima,
(A14)
These function describes how the efficiency of an allele characterised by the -dimensional vector decreases with increasing distance from the pathogen vector . The closer an allelic trait vector is to a pathogen vector, the higher is the efficiency of the MHC-molecule against that pathogen. The magnitude of the decrease in efficiency with increasing distance to the kth pathogen is determined by the shape and width of the Gaussian function as determined by the -dimensional covariance matrix .
In the main part, we consider the special case of rotationally symmetric Gaussian functions . These matrices are thus specified by an inverse matrix-covariance matrix (see Equation A14) that takes the form of a scalar matrix, i.e., a scalar multiple of the identity matrix . Furthermore, we assume that all Gaussians are of equal width. Hence, we have a common scalar for all Gaussians that we denote with , i.e., is the inverse of the width of the Gaussian function. We refer to as virulence (see Section ‘Special case: maximal symmetry’, below).
(A15)
Appendix 8
Analytical results for the Gaussian model
The evolutionarily singular point
In this section, we analyse the evolutionary dynamics of a monomorphic resident population in full generality. By subsequently applying several symmetry assumptions, we then derive the analytical results presented in the main text (see Sections ‘Special case: identically shaped Gaussian efficiency functions’ and ‘Special case: maximal symmetry’). Invasion fitness of a rare mutant allele in a resident population with allele is given by its marginal fitness,
(A16)
(see derivation of Equation A6). Note, that cancels out. It is therefore omitted from all further calculations. The direction of the evolutionary dynamics is governed by the selection gradient. Its ith entry calculates to
(A17)
Using the definitions for (Equation A12) and (Equation A13) and their derivatives,
(A18)
and
(A19)
where Equation A19 is obtained by applying the generalised product rule
(A20)
we obtain
(A21)
In the next step, we calculate the derivative of the function (Equation A14). Applying the chain rule and simplifying results in
(A22)
where the entries of the matrix are denoted by . Using that for and for this further simplifies to
(A23)
Substituting Equation A23 into Equation A21 finally results in
(A24)
and
(A25)
As mentioned in Section ‘Adaptive dynamics and invasion fitness’, singular points are allelic trait vectors for which Equation A25 equals zero. From Equation A25 follows that in our model singular points have to fulfil
(A26)
Solving for yields
(A27)
Thus, the unique singular point equals the arithmetic mean of the pathogen vectors , each weighted by the inverse of their Gaussian covariance matrices . For a one-dimensional trait space () this simplifies to
(A28)
which is the well-known weighted average for scalars. If , then Equation A27 simplifies to the arithmetic mean pathogen vector
(A29)
as stated in the main text.
Absolute convergence stability
Below, we prove that the unique singular point (Equation A27) is absolutely convergence stable. To this end, we first demonstrate that the gradient of invasion fitness can be expressed as , where is a positive function, and then show that is a maximum of .
Gradient of condition
An individual homozygote for has a condition given by
(A30)
and the ith entry of the gradient is given by
(A31)
Substituting Equation A23 into Equation A31 gives
(A32)
and
(A33)
By comparing Equation A33 with Equation A25 we see that
(A34)
where the fraction before is positive. Thus, .
Hessian matrix of condition
The Hessian matrix of a homozygote individual’s condition, evaluated at the singular point, is given by the second-order partial derivative of with respect to the ith and jth entry of .
We obtain this by differentiating Equation A33 with respect of , evaluated at , resulting in
(A35)
and applying the product rule and using that the first derivative at is zero gives
(A36)
where the last simplification uses that for and for , and
(A37)
which is always negative definite. Thus, is a maximum and is absolute convergence stable.
Derivation of the Hessian matrix of invasion fitness
As stated in Equation A9, the entries of the Hessian matrix of invasion fitness are given by
(A38)
The second derivative of the function is obtained by differentiating Equation A18 with respect to , resulting in
(A39)
In the final simplification step we use the conclusion drawn from Equation A21 that and therefore the term after the minus sign disappears.
The second derivative for the function is obtained by differentiating Equation A19 with respect to , resulting in
(A40)
Here, the one but last simplification step again follows from the fact that .
The second derivative for the function is obtained by differentiating Equation A23 with respect to , resulting in
(A41)
where the last simplification uses that for and for .
By recursively substituting Equations A39–A41 into Equation A9 we obtain
where in the last step we substituted Equation A23. This result can be rewritten as a matrix
Finally, substituting with Equation A27, we obtain
(A42)
Special case: identically shaped Gaussian efficiency functions
For the special case that the Gaussian covariance matrices are equal (), fulfilled in Appendix 5—figure 1B, the Hessian matrix simplifies to
(A43)
where we used that is the covariance matrix of the positions of the pathogen vectors. Since the fraction in Equation A43 is positive and is positive definite, it follows that the definiteness of is given by the definiteness of the matrix . Hence, the singular point is uninvadable whenever
(A44)
where the inequality indicates negative definiteness.
Special case: maximal symmetry
For the even more special case that and that the pathogen vectors are arranged symmetrically, resulting in , we obtain
(A45)
In this case, the singular point is a branching point whenever . Assuming that all pathogen vectors have an equal distance to each other implies that they are arranged in an -dimensional regular simplex (see Figure 1). For this case, , and we obtain the branching condition . Assuming pathogen distance and substitute as virulence , we obtain
(A46)
Data availability
All data presented and analysed in this study were generated through individual based simulations using Matlab, with code authored by the first author. The corresponding Matlab script is available at Dryad with DOI: https://doi.org/10.5061/dryad.69p8cz98j.
-
Dryad Digital RepositoryHeterozygote advantage can explain the extraordinary diversity of immune genes.https://doi.org/10.5061/dryad.69p8cz98j
References
-
BookBasic Immunology: Functions and Disorders of the Immune SystemElsevier Health Sciences.
-
Evolutionarily unstable fitness maxima and stable fitness minima of continuous traitsEvolutionary Ecology 7:465–487.https://doi.org/10.1007/BF01237642
-
Virulence evolution and the trade-off hypothesis: history, current state of affairs and the futureJournal of Evolutionary Biology 22:245–259.https://doi.org/10.1111/j.1420-9101.2008.01658.x
-
Protection afforded by sickle-cell trait against subtertian malareal infectionBritish Medical Journal 1:290–294.https://doi.org/10.1136/bmj.1.4857.290
-
Coevolution of hosts and parasitesParasitology 85:411–426.https://doi.org/10.1017/S0031182000055360
-
MHC polymorphism under host-pathogen coevolutionImmunogenetics 55:732–739.https://doi.org/10.1007/s00251-003-0630-5
-
Unifying evolutionary dynamics: From individual stochastic processes to macroscopic modelsTheoretical Population Biology 69:297–321.https://doi.org/10.1016/j.tpb.2005.10.004
-
Multidimensional (co) evolutionary stabilityThe American Naturalist 184:158–171.https://doi.org/10.1086/677137
-
BookAnalysis of Evolutionary Processes: The Adaptive Dynamics Approach and Its ApplicationsPrinceton University Press.https://doi.org/10.1515/9781400828340
-
The dynamical theory of coevolution: a derivation from stochastic ecological processesJournal of Mathematical Biology 34:579–612.https://doi.org/10.1007/BF02409751
-
BookAdaptive Diversification MPB-48Princeton University Press.https://doi.org/10.23943/princeton/9780691128931.001.0001
-
Histocompatibility-2 system in wild miceImmunogenetics 9:261–272.https://doi.org/10.1007/BF01570420
-
Adaptive dynamics for physiologically structured population modelsJournal of Mathematical Biology 56:673–742.https://doi.org/10.1007/s00285-007-0134-2
-
Red queen processes drive positive selection on major histocompatibility complex (MHC) genesPLOS Computational Biology 11:e1004627.https://doi.org/10.1371/journal.pcbi.1004627
-
Adaptive immune response selects for postponed maturation and increased body sizeFunctional Ecology 37:2883–2894.https://doi.org/10.1111/1365-2435.14416
-
BookThe Genetical Theory of Natural SelectionOxford University Press.https://doi.org/10.5962/bhl.title.27468
-
Models of parasite virulenceThe Quarterly Review of Biology 71:37–78.https://doi.org/10.1086/419267
-
Mechanisms of pathogenesis and the evolution of parasite virulenceJournal of Evolutionary Biology 21:396–404.https://doi.org/10.1111/j.1420-9101.2007.01480.x
-
MHC class II DRB variability and parasite load in the striped mouse (Rhabdomys pumilio) in the southern KalahariMolecular Biology and Evolution 22:1254–1259.https://doi.org/10.1093/molbev/msi156
-
The evolution of alloimmunity and the genesis of adaptive immunityThe Quarterly Review of Biology 79:359–382.https://doi.org/10.1086/426088
-
Pathogen resistance and genetic variation at MHC lociEvolution; International Journal of Organic Evolution 56:1902–1908.https://doi.org/10.1554/0014-3820(2002)056[1902:pragva]2.0.co;2
-
What is the evidence for heterozygote advantage selection?Trends in Ecology & Evolution 27:698–704.https://doi.org/10.1016/j.tree.2012.08.012
-
The evolution of costly mate preferences ii. the “handicap” principleEvolution; International Journal of Organic Evolution 45:1431–1442.https://doi.org/10.1111/j.1558-5646.1991.tb02646.x
-
Do infectious diseases drive MHC diversity?Microbes and Infection 2:1335–1341.https://doi.org/10.1016/s1286-4579(00)01287-9
-
Signals of major histocompatibility complex overdominance in a wild salmonid populationProceedings. Biological Sciences 276:3133–3140.https://doi.org/10.1098/rspb.2009.0727
-
New reservoirs of HLA alleles: pools of rare variants enhance immune defenseTrends in Genetics 28:480–486.https://doi.org/10.1016/j.tig.2012.06.007
-
Computational prediction of mhc ii-antigen binding supports divergent allele advantage and explains trans-species polymorphismEvolution; International Journal of Organic Evolution 65:2380–2390.https://doi.org/10.1111/j.1558-5646.2011.01288.x
-
BookEvolution in Changing Environments: Some Theoretical Explorations. MPB-2Princeton University Press.https://doi.org/10.2307/j.ctvx5wbbh
-
Plasmodium relictum infection and MHC diversity in the house sparrow (Passer domesticus)Proceedings. Biological Sciences 278:1264–1272.https://doi.org/10.1098/rspb.2010.1968
-
Major histocompatibility complex heterozygote superiority during coinfectionInfection and Immunity 71:2079–2086.https://doi.org/10.1128/IAI.71.4.2079-2086.2003
-
How should we define ‘fitness’ for general ecological scenarios?Trends in Ecology & Evolution 7:198–202.https://doi.org/10.1016/0169-5347(92)90073-K
-
BookFitnessIn: Jorgensen SE, Jorgensen B, editors. Encyclopedia of Ecology Oxford. Elsevier. pp. 1599–1612.https://doi.org/10.1016/B978-008045405-4.00792-8
-
Major histocompatibility complex (MHC) heterozygote superiority to natural multi-parasite infections in the water vole (Arvicola terrestris)Proceedings. Biological Sciences 276:1119–1128.https://doi.org/10.1098/rspb.2008.1525
-
Divergent allele advantage at human MHC genes: signatures of past and ongoing selectionMolecular Biology and Evolution 35:2145–2158.https://doi.org/10.1093/molbev/msy116
-
Invasion implies substitution in ecological communities with class-structured populationsTheoretical Population Biology 134:36–52.https://doi.org/10.1016/j.tpb.2020.04.004
-
Disruptive selection and then what?Trends in Ecology & Evolution 21:238–245.https://doi.org/10.1016/j.tree.2006.03.003
-
Evolutionary trade-offs and the structure of polymorphismsPhilosophical Transactions of the Royal Society of London. Series B, Biological Sciences 373:20170105.https://doi.org/10.1098/rstb.2017.0105
-
How pathogens drive genetic diversity: MHC, mechanisms and misunderstandingsProceedings. Biological Sciences 277:979–988.https://doi.org/10.1098/rspb.2009.2084
-
Ancestral polymorphisms of MHC class II genes: Divergent allele advantageImmunologic Research 9:115–122.https://doi.org/10.1007/BF02918202
-
Historical and contemporary selection of teleost MHC genes: did we leave the past behind?Journal of Fish Biology 73:2110–2132.https://doi.org/10.1111/j.1095-8649.2008.02051.x
Article and author information
Author details
Funding
No external funding was received for this work.
Acknowledgements
We thank Yvonne Meyer-Lucht and Tobias Lenz for helpful discussions and Göran Arnqvist, Helena Westerdahl, Joachim Hermisson, and Sophie Karrenberg for comments on an earlier version of the manuscript.
Copyright
© 2024, Siljestam and Rueffler
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 457
- views
-
- 55
- downloads
-
- 1
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Heterozygote advantage can explain the extraordinary diversity of immune genes
eLife 13:e94587.
https://doi.org/10.7554/eLife.94587
Further reading
-
- Evolutionary Biology
Mammalian gut microbiomes are highly dynamic communities that shape and are shaped by host aging, including age-related changes to host immunity, metabolism, and behavior. As such, gut microbial composition may provide valuable information on host biological age. Here, we test this idea by creating a microbiome-based age predictor using 13,563 gut microbial profiles from 479 wild baboons collected over 14 years. The resulting ‘microbiome clock’ predicts host chronological age. Deviations from the clock’s predictions are linked to some demographic and socio-environmental factors that predict baboon health and survival: animals who appear old-for-age tend to be male, sampled in the dry season (for females), and have high social status (both sexes). However, an individual’s ‘microbiome age’ does not predict the attainment of developmental milestones or lifespan. Hence, in our host population, gut microbiome age largely reflects current, as opposed to past, social and environmental conditions, and does not predict the pace of host development or host mortality risk. We add to a growing understanding of how age is reflected in different host phenotypes and what forces modify biological age in primates.
-
- Evolutionary Biology
A major question in animal evolution is how genotypic and phenotypic changes are related, and another is when and whether ancient gene order is conserved in living clades. Chitons, the molluscan class Polyplacophora, retain a body plan and general morphology apparently little changed since the Palaeozoic. We present a comparative analysis of five reference quality genomes, including four de novo assemblies, covering all major chiton clades, and an updated phylogeny for the phylum. We constructed 20 ancient molluscan linkage groups (MLGs) and show that these are relatively conserved in bivalve karyotypes, but in chitons they are subject to re-ordering, rearrangement, fusion, or partial duplication and vary even between congeneric species. The largest number of novel fusions is in the most plesiomorphic clade Lepidopleurida, and the chitonid Liolophura japonica has a partial genome duplication, extending the occurrence of large-scale gene duplication within Mollusca. The extreme and dynamic genome rearrangements in this class stands in contrast to most other animals, demonstrating that chitons have overcome evolutionary constraints acting on other animal groups. The apparently conservative phenome of chitons belies rapid and extensive changes in genome.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}