Bayesian inference of kinetic schemes for ion channels by Kalman filtering
- Institut für Physiologie II, Universitätsklinikum Jena, Friedrich Schiller University Jena, Germany
- Department of Biochemistry and Molecular Biology, University of Chicago, United States
Figures
Box 1—figure 1
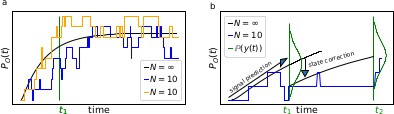
The First-order Markov property of the data requires a recursive prediction of the signal (by the model) and correction (by the data) scheme of the algorithm.
(a) Idealized patch-clamp (PC) data in the absence of instrumental noise for either ten (colored) or an infinite number of channels generating the mean time trace (black). The fluctuations with respect to the mean time trace (black) reveal autocorrelation (b) Conceptual idea of the Kalman Filter (KF): the stochastic evolution of the ensemble signal is predicted and the prediction model updated recursively.
Box 1—figure 2
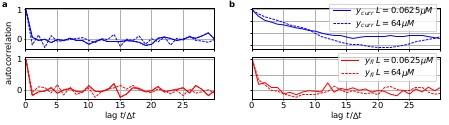
The residuals between model prediction and data reveal long autocorrelations if the analysis algorithm ignores the first-order Markov property.
(a) Autocorrelation of the residuals of two ligand concentrations of currents (blue) and of the fluorescence (red) after the data have been analyzed with the KF approach. (b) autocorrelation of after analysing with he RE approach.
Figure 1
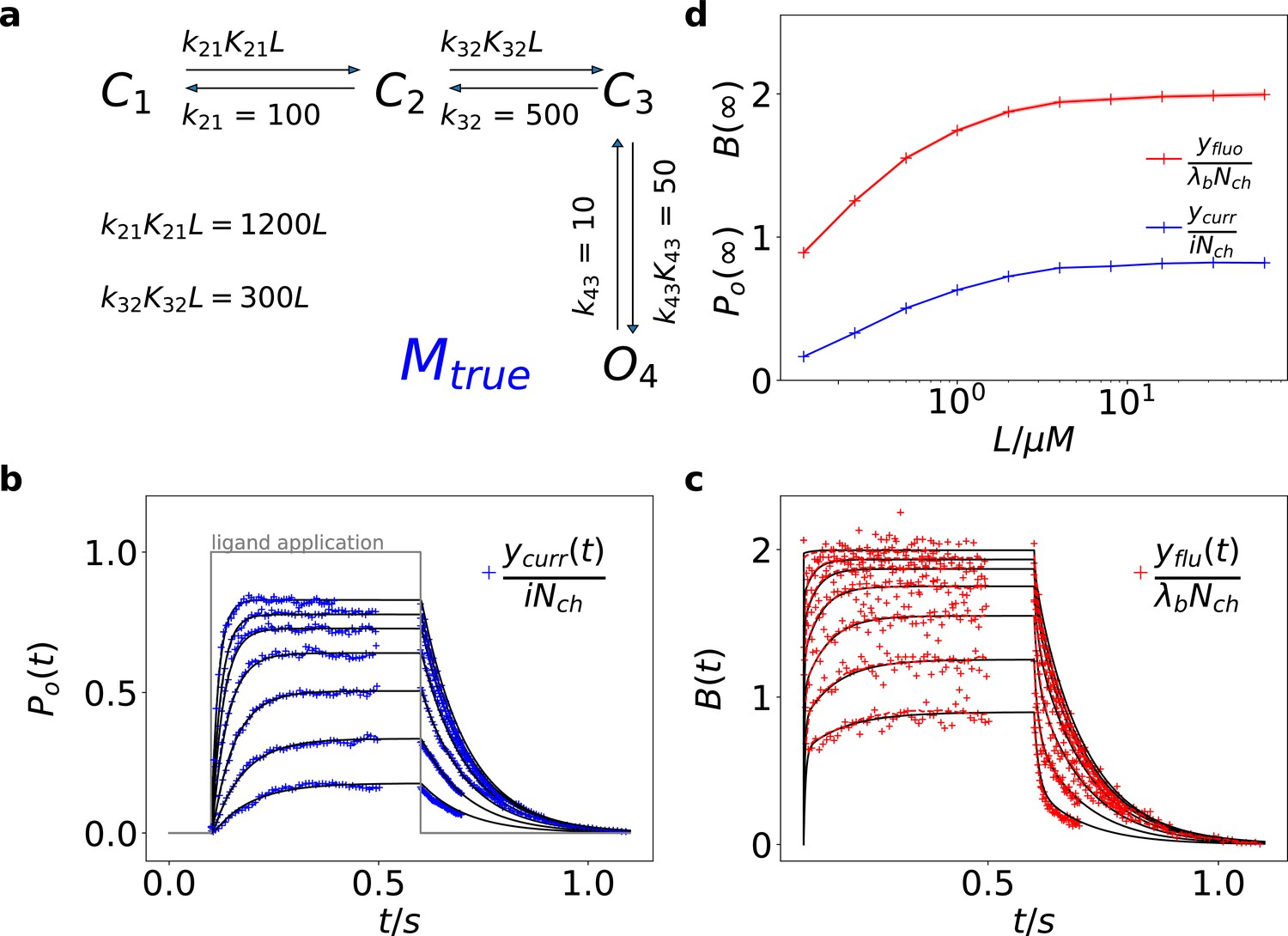
Kinetic scheme and simulated data.
(a) The Markov state model (kinetic scheme) consists of two binding steps and one opening step. The rate matrix is parametrized by the absolute rates , the ratios between on and off rates (i.e. equilibrium constants) and , the ligand concentration in the solution. The units of the rates are and , respectively. The liganded states are C2, C3, O4. The open state O4 conducts a mean single-channel current . Note, that absolute magnitude of the single channel current is irrelevant regarding this study what matters is its relative magnitude compared with and . Simulations were performed with 10 kHz or 100 kHz (for Figures 11 and 12) sampling, KF analysis frequency fana for cPCF data is in the range of (200-500) Hz while pure current data is analyzed at 2-5 kHz. (b-c) Normalized time traces of simulated relaxation experiments of ligand concentration jumps with channels, mean photons per bound ligand per frame and single-channel current , open-channel noise with and an instrumental noise with the variance . The current ycurr and fluorescence yflu time courses are calculated from the same simulation. For visualization, the signals are normalized by the respective median estimates of the KF. The black lines are the theoretical open probabilities and the average binding per channel for of the used model. Typically, we used 10 ligand concentrations which are (0.0625, 0.125, 0.25, 0.5, 1, 2,4, 8, 16, 64) . d, Equilibrium binding and open probability as function of the ligand concentration .
-
Figure 1—source data 1
The example data is provided.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig1-data1-v3.zip
Figure 2
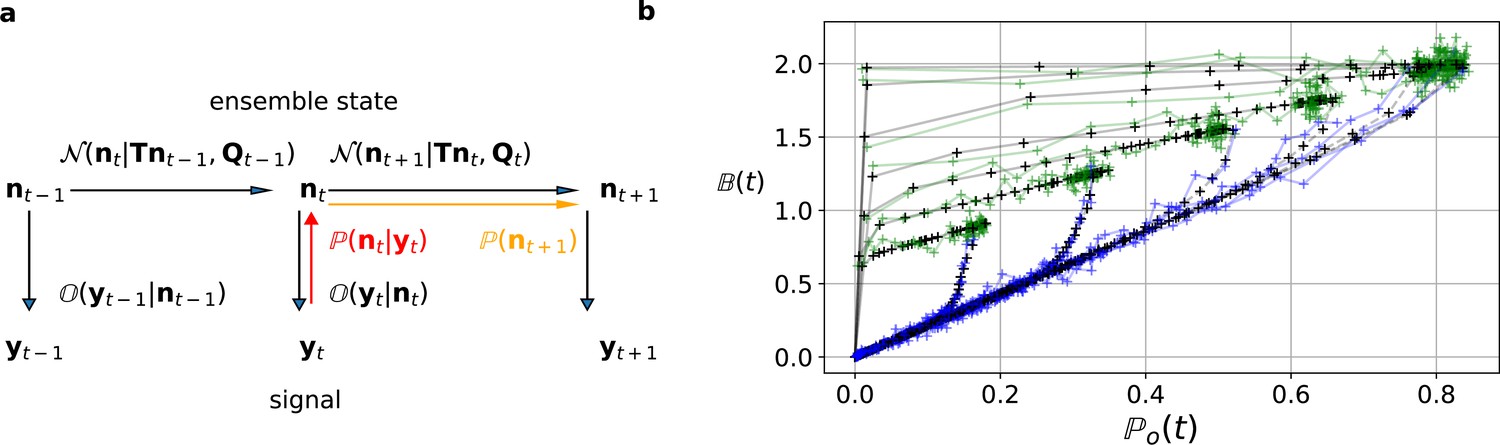
The first-order hidden Markov structure is explicitly used by the Bayesian filter.
The filter can be seen as continuous state analog of the forward algorithm. (a) Graphical model of the conditional dependencies of the stochastic process. Horizontal black arrows represent the conditional multivariate normal transition probability of a continuous state Markov process. Notably, it is which is treated as the Markov state by the KF. The transition matrix and the time-dependent covariance characterise the single-channel dynamics. The vertical black arrows represent the conditional observation distribution . The observation distribution summarizes the noise of the experiment, which in the KF is assumed to be multivariate normal. Given a set of model parameters and a data point , the Bayesian theorem allows to calculate in the correction step (red arrow). The posterior is propagated linearly in time by the model, predicting a state distribution (orange arrow). The propagated posterior predicts together with the observation distribution the mean and covariance of the next observation. Thus, it creates a multivariate normal likelihood for each data point in the observation space. (b) Observation space trajectories of the predictions and data of the binding per channel vs. open probability for different ligand concentrations. The curves are normalized by the median estimates of , and and the ratio of open-channels which approximates the open probability . The black crosses represent the predicted mean signal , which is calculated by multiplying the observational matrix with the mean predicted state . For clarity, we used the mean value of the posterior of the KF. The green and blue trajectories represent the part of the time traces with after the jump to non-zero ligand concentration and after jumping backt to zero ligand concentration in the bulk, respectively.
Figure 3
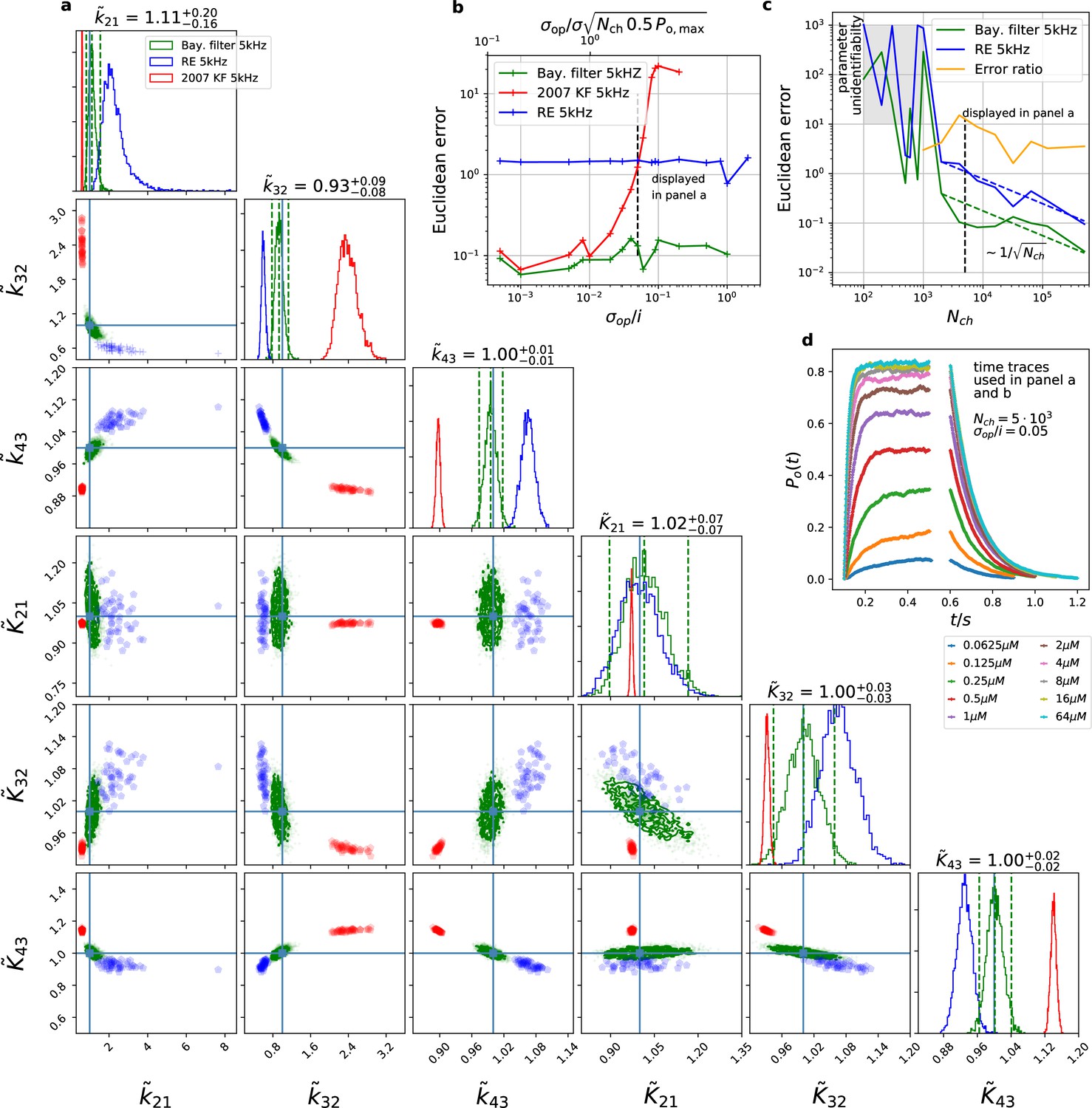
The Bayesian filter overcomes the sensitivity to varying (open-channel) noise of the classic Kalman filter and does not show the overconfidence of the RE-approach.
Overall it shows the highest accuracy and the posterior covers the true values. The classical deterministic RE (blue), 2007 Kalman filter (red) and our Bayesian filter (green) are implemented as a full Bayesian version and the obtained posterior distributions are compared. For all PC data sets in the figure the analysing frequencies ranges within 2-5. (a) Posterior of the parameters for the 3 algorithms for the data set displayed in panel d. The blue crosses indicate the true values. All samples are normalized by their true values which is indicated by the ∼ above the parameters. For clarity, we only show a fraction of the samples of the posterior for blue and red. b, Effect of open channel noise: The Euclidean error for all three approaches is plotted vs. (low axis).The upper axis displays the ratio of the ‘typical’ standard deviation of the open channel excess noise of the ensemble of channels to the standard deviation of instrumental noise. c, Influence of patch size: Scaling of the Euclidean error vs. follows indicated by the dashed lines for for the RE and the Bayesian filter approach. The data indicates a constant error ratio (orange) for large . For samples of the posteriors for many data sets suggest an improper posterior. An instrumental noise of and was used. (d) The time traces on which the posteriors of panel a are based (for the ligand concentrations see Figure 1). Panel b used the same data too, but σ and were varied.
-
Figure 3—source data 1
The data folder includes all 15 sets of time traces.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig3-data1-v3.zip
Figure 4
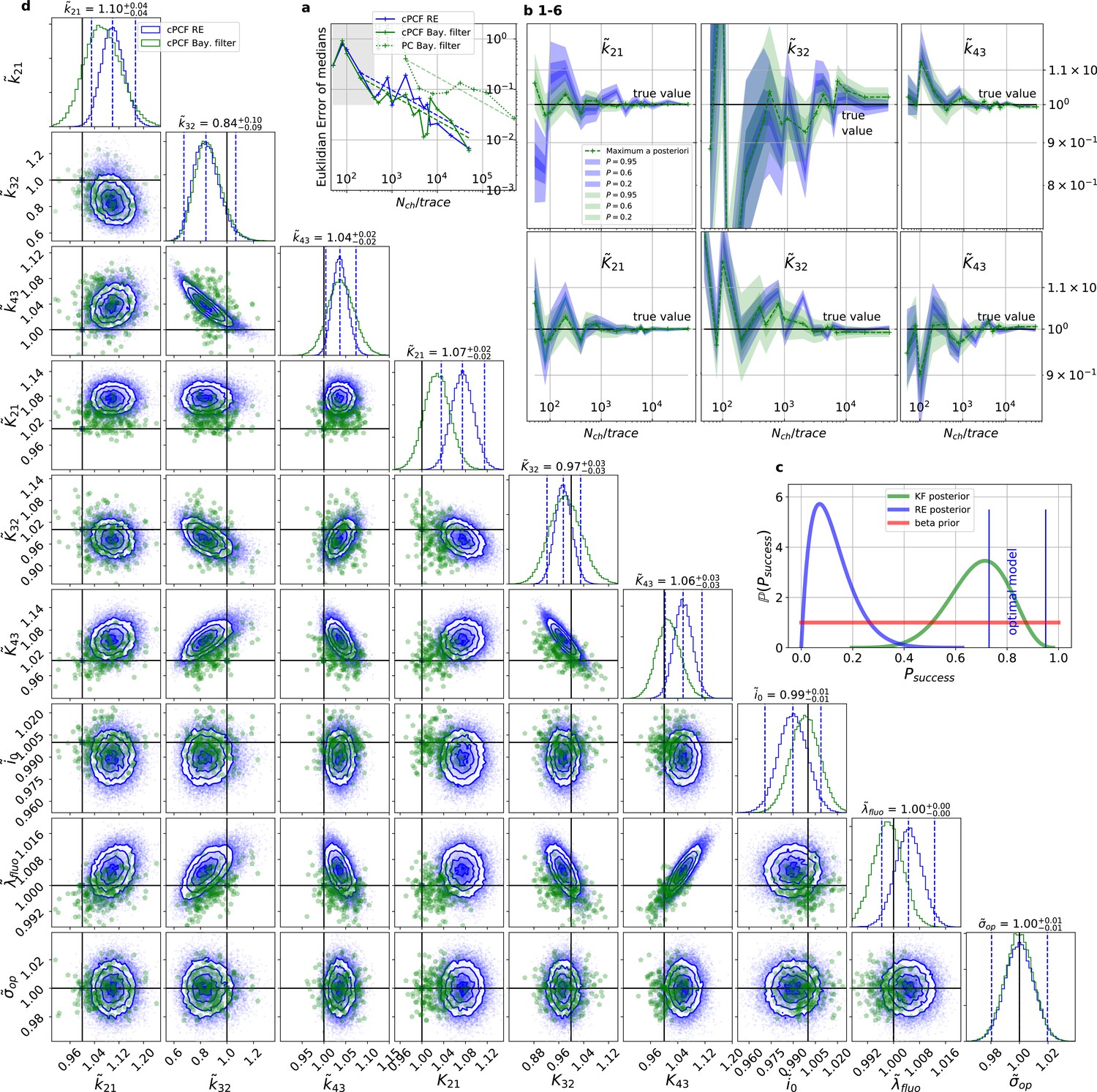
For multidimensional data (cPCF) the RE approach almost approaches the accuracy (Euclidean error) of the Bayesian Filter.
However, only the Bayesian filter covers the true value in a reasonable HDCV while RE based posteriors are too narrow. All samples are normalized by their true values which is indicated by the ∼ above the parameters. (a) Euclidean errors of the maximum for the rate and equilibrium constants obtained by the KF (green) and from the REs (blue) are plotted against for , and . Both algorithms scale like (dashed lines) for larger which is the expected scaling For smaller (gray range) the error is roughly the same indicating that limitations of the normal approximation to the multinomial distribution dominate the overall error in this regime. The combination of fluorescence and current data(cPCF) decreases the eucleadian error for both approaches compared to current data alone(PC). (b), HDCI and the mode of the 3 and 3 plotted vs. revealing that the maximum is a consistent estimator (converges in distribution to the true value with increasing data quality). While the KF (green) 0.95-HDCI includes usually the true value, the RE HDCI (blue) is too narrow and, thus, the real values are frequently not included. (c) Bayesian estimation of true success probability for the event that all 6 0.95-HDCI include the respective true values at the same time by a binomial likelihood. Since the data sets have different and the model approximations become better with increasing , we use a cut-off for . d, Comparison of 1-D and combinations of 2-D marginal posteriors of the parameters of interest for both algorithms calculated from a simulation. Blue lines indicate the true value. We depict that in two dimensions the disproportion of the deviation of the mode and the spread of RE (blue) approach is worsened while KF (green) posterior includes the true values with more reasonable probability mass.
-
Figure 4—source data 1
6µMol.
Each of the source data folders contains for a specific ligand concentration the time traces of cPCF data for all .
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig4-data1-v3.zip
-
Figure 4—source data 2
64µMol.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig4-data2-v3.zip
-
Figure 4—source data 3
32µMol.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig4-data3-v3.zip
-
Figure 4—source data 4
8µMol.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig4-data4-v3.zip
-
Figure 4—source data 5
4µMol.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig4-data5-v3.zip
-
Figure 4—source data 6
1µMol.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig4-data6-v3.zip
-
Figure 4—source data 7
2µMol.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig4-data7-v3.zip
-
Figure 4—source data 8
025µMol.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig4-data8-v3.zip
-
Figure 4—source data 9
05µMol.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig4-data9-v3.zip
-
Figure 4—source data 10
00625µMol.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig4-data10-v3.zip
-
Figure 4—source data 11
003125µMol.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig4-data11-v3.zip
-
Figure 4—source data 12
0125µMol.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig4-data12-v3.zip
Figure 5
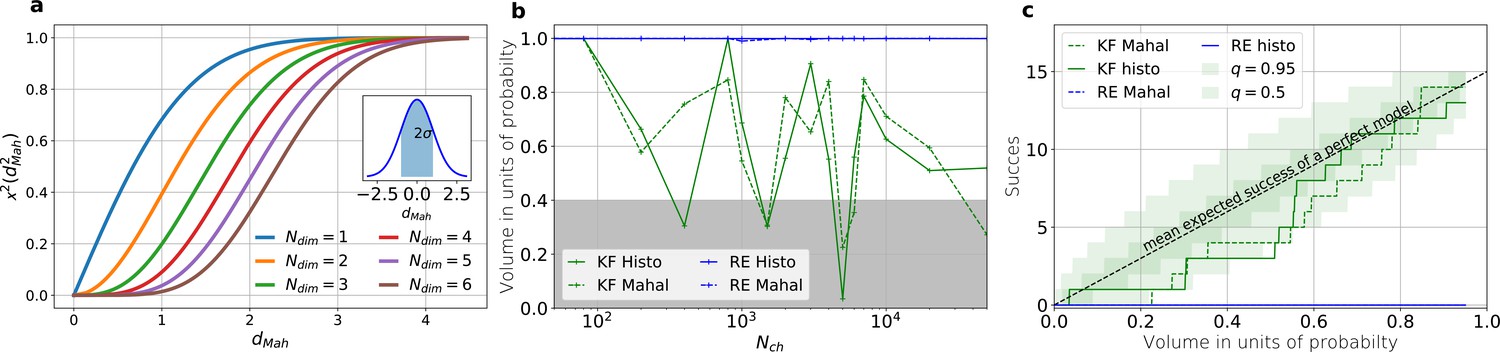
The HDCV of the posterior of the KF follows the requested binomial statistics while the HDCVs of the RE approach are too narrow.
(a) Cumulative χ-square distribution vs. the Mahalanobis distance . The y axis denotes the probability mass which is counted by moving away from the maximum before an ellipsoid with distance is reached. The different colours represent the changes of the cdf with an increasing number of rate parameters. The blue cdf at represents how much probability mass can be found from , see inset. In one dimension, we can expect to find the true value within around the mean with the usual probability of for univariate normally distributed random variables. The six parameters (brown) of the full rate matrix will almost certainly be beyond . The higher the dimensions of the space the less important becomes the maximum of the probability density distribution for the typical set which is by definition the region where the probability mass resides. The mathematical reason for this is that the probability mass is the integrated product of volume and probability density. b, The two methods to count volume in units of probability mass for the KF (green) and the RE (blue). The gray area indicates which data sets are considered a success if one chooses to evaluate a proababilty mass of 0.4 of each posterior around its mode. All data sets in the white area are considered a failure. For the optimistic noise assumptions , and a mean photon count per bound ligand per frame the RE approach (blue) distributes the probability mass such that the HDCV never includes the true rate matrix. From both HDCV estimates of the KF posterior (green curves) include the true value within a reasonable volume and show a similar behaviour. c, Binomial success statistics of HDCV to cover the true value vs. the expected probability constructed from the data of (b). Calculated for and and and minimal background noise.
Figure 6
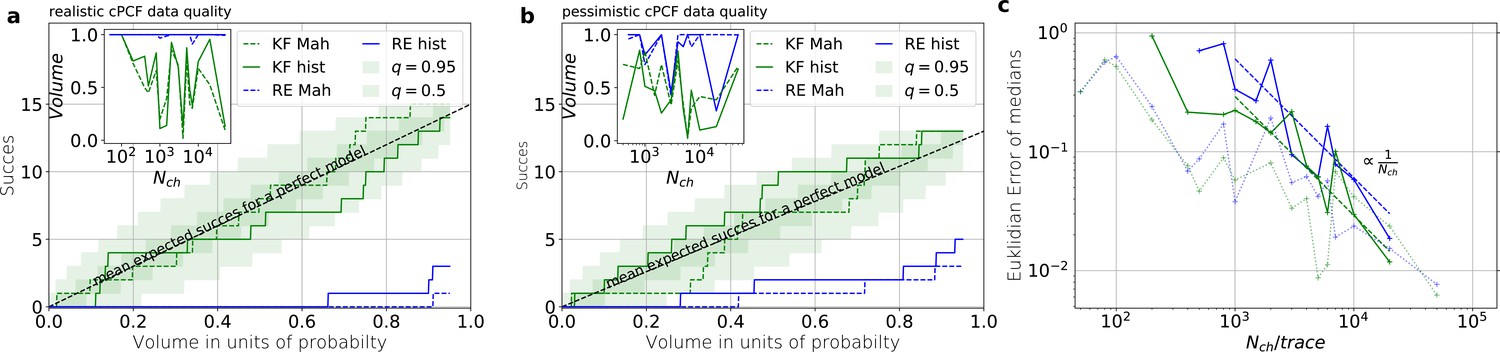
Even for the highest tested experimental noise the RE approach does not follow the required binomial statistics, generating an underestimated uncertainty.
(a) Binomial success statistics of HDCV to cover the true value vs. the expected probability. Calculated for and and and a strong background noise. (b) Binomial success statistics of HDCV to cover the true value vs. the expected probability. For and and and a strong background noise. For both algorithms, the adaptation of the sampler of the posterior was more fragile for small , leading to differences in the posterior if the posterior is constructed from different independent sampling chains. Those data sets were then excluded. We assume that these instabilities are induced in both algorithms by the shortcomings of the multivariate normal assumptions. (c) Comparison of the Euclidean error vs. for the pessimistic noise case (solid lines) with Euclidean error for the optimistic noise case (dotted lines).
Figure 7
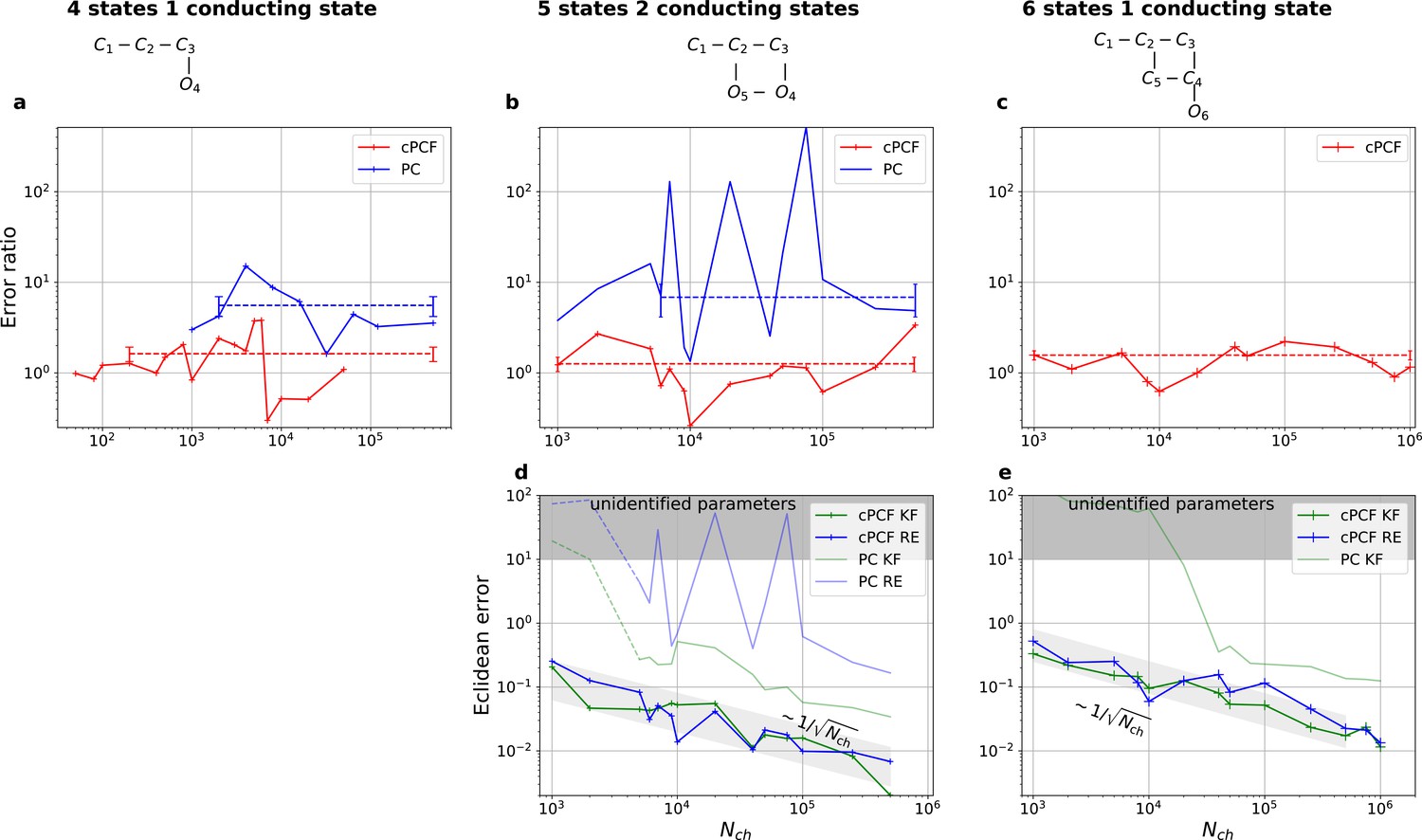
Higher model complexity drastically increases the minimal requirements of the data.
With PC data the RE approach is frequently incapable to identify all parameters while the Bayesian filter is more robust. cPCF data alleviate the parameter unidentifiabilities for patch sizes for which PC data are insufficient. Each panel column corresponds to a particular true process with increasing complexity from left to right, as indicated by the model schemes on top. Within all kinetic schemes, each transition to the right adds one bound ligand. Each transition to left is an unbinding step. Vertical transitions are either conformational or opening transitions. Plots in each row share the same y-axis respectively. Each column shares the same abscissa. (a-c) Error ratio for PC data (blue) and cPCF data (red). The dashed lines indicate the mean error ratio under the simplifying assumption that the error ratio does not depend on The vertical bars are the standard deviations of the mean values. Theses values were calculated from the Euclidean errors shown in Figures 3c and 4a for a, and panels (d-e), for (b-c), respectively. Results from the KF algorithm (green) and the RE algorithm (blue) are compared for PC (lighter shades) and cPCF (strong lines). The diagonal gray areas indicate a proportionality. For simulating the underlying PC data, we used standard deviations of and and for the cPCF data additionally a ligand of brightness . To facilitate the inference for the two more complex models, we assumed that the experimental noise and the single channel current are well characterized, meaning , and . In the models containing loops (last 2 columns), a prior was used to enforce microscopic-reversibility and set to multiplied by .
-
Figure 7—source data 1
The folder of the five-state model includes 15 sets of time traces in the interval .
Each of them has 10 ligand concentrations. The number in the file name reports the amount of ion channels in the patch.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig7-data1-v3.zip
-
Figure 7—source data 2
The folder of the six-state model includes 14 sets of time traces in the interval .
Each of them has 10 ligand concentrations. The number in the file name reports the amount of ion channels in the patch.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig7-data2-v3.zip
Figure 8
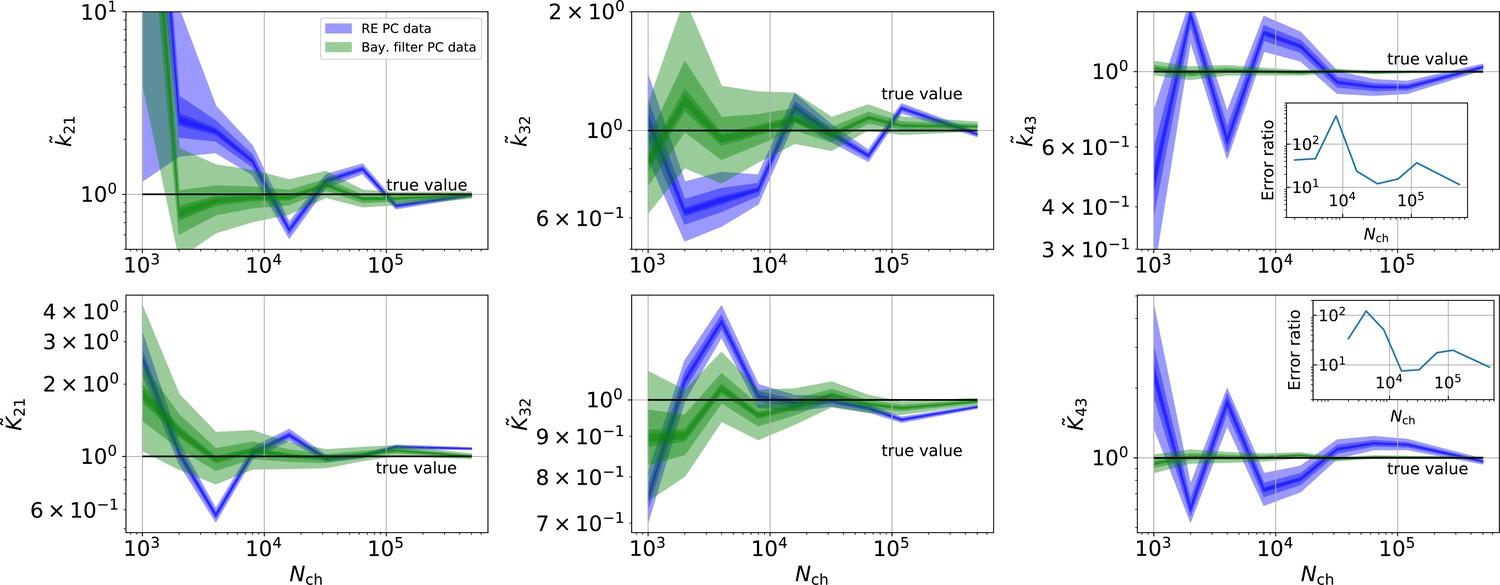
Revisiting the PC data obtained by the 4-state-1-open-state model shows that the KF succeeds to produce realistic uncertainty quantification, while the overconfidence problem (unreliable uncertainty quantification) of the RE approach remains.
Comparison of a series of HDCIs shown as functions of for each parameter of the rate matrix obtained by the KF (green) and the RE algorithm (blue). The differing shades of green and blue indicate the set of -HDCIs. Only the interval in which all parameters are identified is displayed. The data are taken from the KF vs. RE benchmark of Figures 3c and 7a . The first row corresponds to three rates the second row to the equilibrium constants . All parameters are normalized by their true value. The insets show the error ratios of the respective single parameter estimates. Note that the error ratios on the single-parameter level can be even of the order of magnitude of 102. Thus, they can be much larger than the error ratios calculated from the Euclidean error if the errors of the respective parameters are small compared to other error terms in the Euclidean error Equation 15 .The lowest Euclidean error for this kinetic scheme has cPCF data analyzed with the KF. (Figure 7d). A 6-state-1-open-states model with cPCF data has again an error ratio of the the usual scale (Figure 7c). As expected, the Euclidean error continuously increases with model complexity (Figure 7d and e). For PC data of the 6-state-1-open-states model even the likelihood of the KF is that weak (Figure 7e) that it delivers unidentified parameters even for and we can detect heavy tailed distributions up until . Using RE on PC data alone does not lead to parameter identification, thus no error ratio can be calculated.
Figure 9
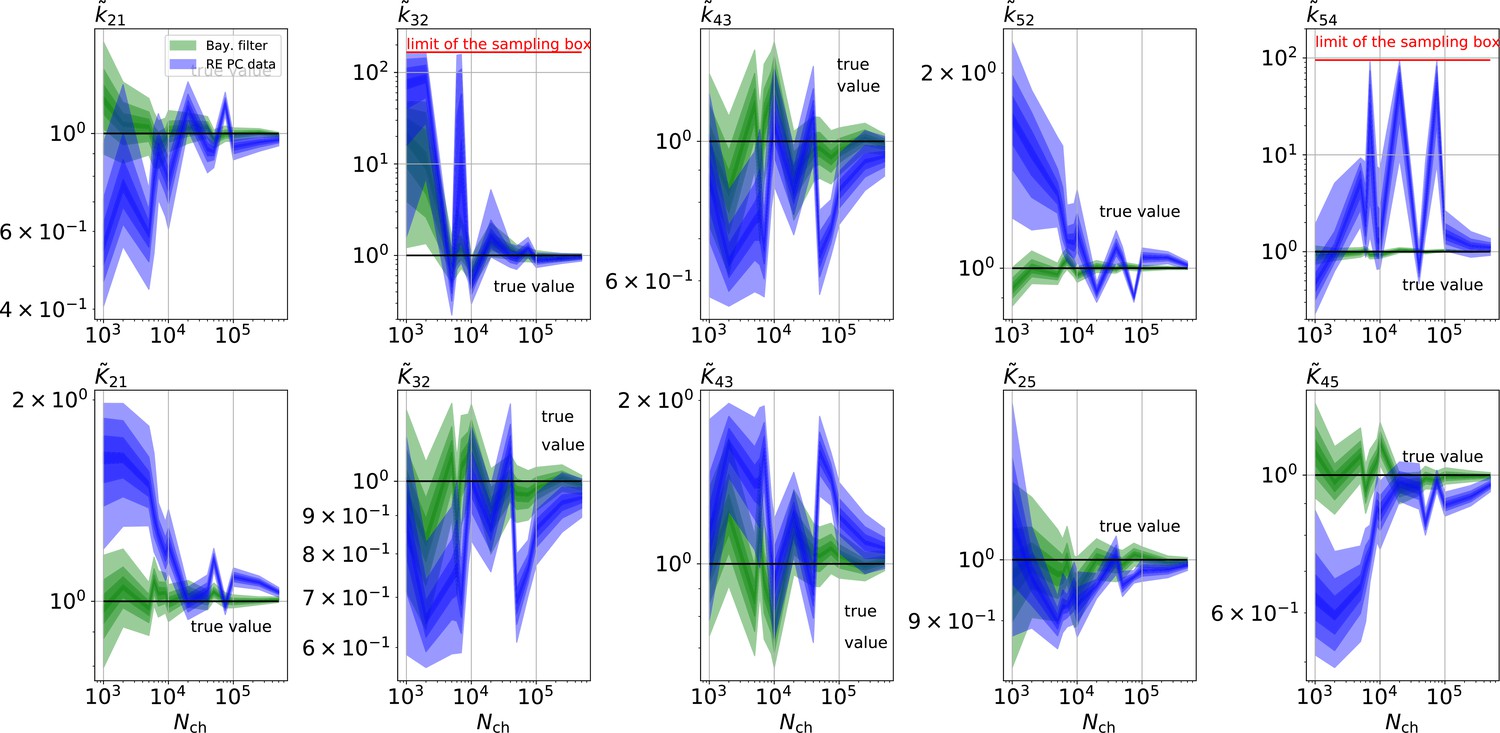
The HDCIs for PC data for a 5-state-2-open-states model show negligible bias for the KF with the true value being included.
In contrast, the HDCE for RE approach frequently does not include the true value and in general appears biased and frequently leaves certain parameters unidentified. Comparison of a series of -HDCIs as functions of for each parameter of the rate matrix obtained by the KF (green) and the RE algorithm (blue). The HDCIs correspond to the PC data displayed in Figure 7b and d . The first row corresponds to three rates the second row to the equilibrium constants . All parameters are normalized by their true value. is because of the microscopic-reversibility prior a parameter which is strongly dependent on the other rates and ratios. Refer to the caption of Figure 7 for details about the prior that enforces microscopic-reversibility. Thus, the deviations of are inherited from the other parameters. The rate is frequently not identified by the RE approach and only the limits of the sampling box confines he posterior.
Figure 10

The Benchmark of the KF for PC versus cPCF data with different bright ligands shows that even adding a weak fluorescence binding signal can add enough information to identify before unidentified parameters.
(a) Posteriors of PC data (blue), cPCF data with (orange) and cPCF data with (green). For the data set with , we additionally accounted for the superimposing fluorescence of unbound ligands in solution. In all cases . The black lines represent the true values of the simulated data. The posteriors for cPCF are centered around the true values that are hardly visible on the scale of the posterior for the PC data. The solid lines on the diagonal are kernel estimates of the probability density. (b) Accuracy and precision of the median estimates visualized by a violin plot for the parameters of the rate matrix for 5different data sets. Four of the five data sets are used a second time with different instrumental noise, with and superimposing bulk signal. The blue lines represent the median, mean and the maximal and minimal extreme value. (c) The 95th percentile of the marginalized posteriors vs. normalized by the true value of each parameter. A regime with is shown for and K1, while other parameters show a weaker dependency on the ligand brightness. (d) Histograms of the residuals of cPCF with data and PC data. The randomness of the normalized residuals of the cPCF or PC data is well described by . The estimated variance is . Note that the fluorescence signal per frame is very low such that the normal approximation to Poisson counting statistics does not hold. e, Posterior of the open-channel noise for PC data with (green) and (blue) as well as for cPCF data with (red) with . We assumed as prior for the instrumental variance .
-
Figure 10—source data 1
Five different sets of time traces of panel b.
All instrumental noise is already added.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig10-data1-v3.zip
-
Figure 10—source data 2
Eighteen sets of time traces of panel c.
The number in the file name indicates the brightness.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig10-data2-v3.zip
Figure 11
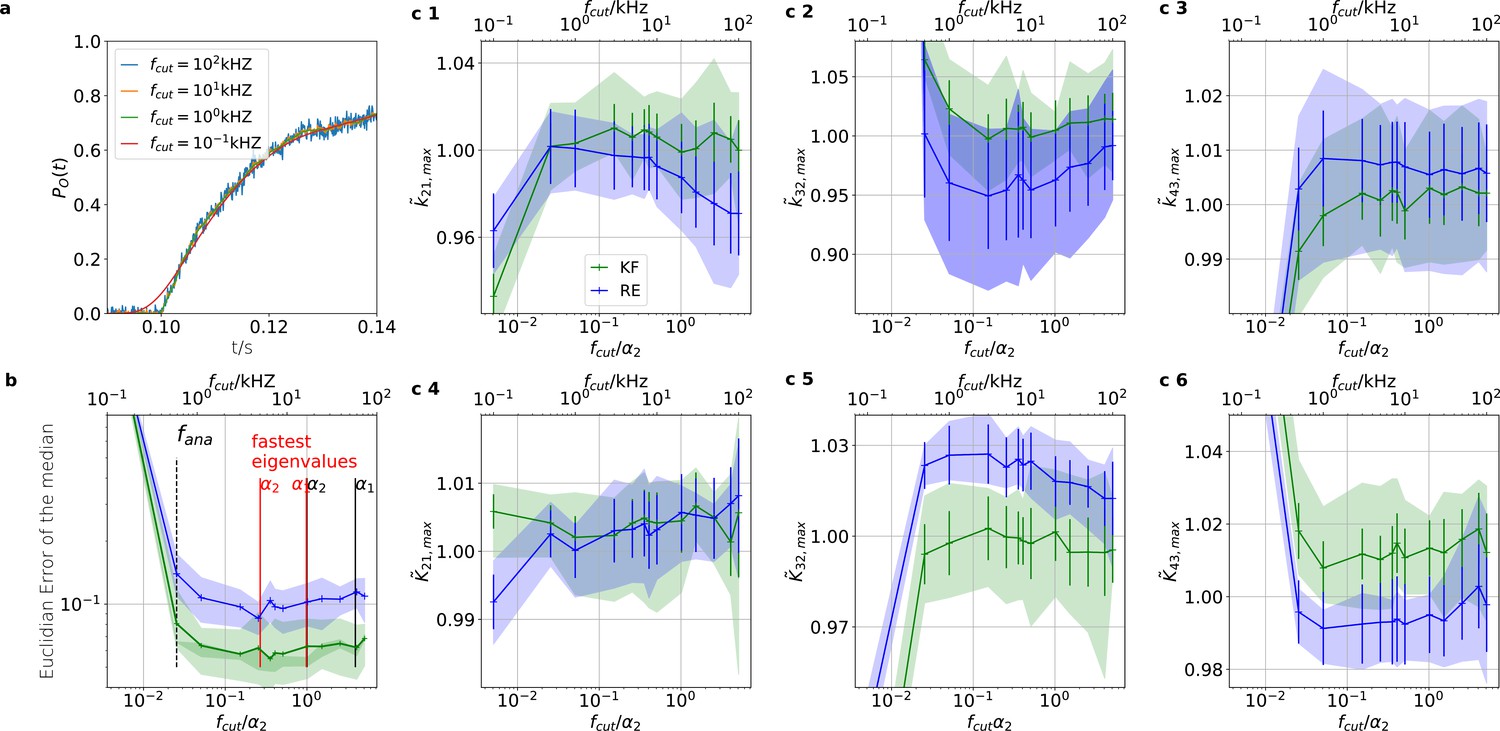
The KF is robust against moderate analog filtering of the current signal.
High (Bayesian) sampling frequencies and minimal analog filtering does minimize bias which otherwise deteriorates parameter identification. In order to mimic an analog signal before the analog-to-digital conversion we simulated seven different 100 kHz signals which were then filtered by a digital fourth-order (4 pole) Bessel filter. The activation curves were then analyzed with the Bayesian filter at 125 Hz and the deactivation curves at sampling rates between 166-500 Hz. We chose for the analog signal , , thus a stronger background noise, and we set the mean photon count per bound ligand as . For the ensemble size we choose . (a) Current time trace filtered with different fcut. Except for 100 Hz (red) the signal distortion is visually undetectable. Nevertheless, the invisible signal distortions from analog filtering are problematic for both algorithms. (b) Estimate of the distribution mean Euclidean error of the median of the posterior vs. the cut-off frequency of a 4 pole Bessel filter (upper scale is in units of kHz) or scaled to the channel time scale (lower scale, see text). The fastest two eigenvalues for the highest ligand concentration are indicated by the black vertical lines. The fastest ratios for the next smaller ligand concentration are indicated by the red vertical lines. The slowest eigenvalue ratio at the highest ligand concentration is beyond the left limit of the x-axis. The solid line is the mean median of five data sets of the respective RE posterior (blue) and KF posterior (green). The green shaded area indicates the 0.6 quantile (ranging from the 20th percentile till the 80th percentile), demonstrating the distribution of the error of the posterior median due to the randomness of the data. (c) 1–3, Accuracy (bias) and precision of the maxima of the posterior of the posterior maxima of the rates vs. the cut-off frequency of a Bessel filter. The shaded areas indicate the 0.6 quantiles (ranging from the 20th percentile till the 80th percentile) due the variability among data sets while the error bars show the standard error of the mean. The deviation of the mean from the true value is an estimate of the accuracy of the algorithm while the quantile indicates the precision. (c) 4–6, Accuracy and precision of the maxima of the posterior of the posterior maxima of the corresponding equilibria vs. the cut-off frequency of a Bessel filter.
-
Figure 11—source data 1
Representative data set of cPCF data whose current has been filtered with decreasing fcut.
In the name of each file is fcut encoded in units of 100 kHz. The time axis is identical for all time traces and saved in the file Time.txt. The folder is similar to six other provided source data folders which have in total been used in this figure.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig11-data1-v3.zip
-
Figure 11—source data 2
Representative data set of cPCF data whose current has been filtered with decreasing fcut.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig11-data2-v3.zip
-
Figure 11—source data 3
Representative data set of cPCF data whose current has been filtered with decreasing fcut.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig11-data3-v3.zip
-
Figure 11—source data 4
Representative data set of cPCF data whose current has been filtered with decreasing fcut.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig11-data4-v3.zip
-
Figure 11—source data 5
Representative data set of cPCF data whose current has been filtered with decreasing fcut.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig11-data5-v3.zip
-
Figure 11—source data 6
Representative data set of cPCF data whose current has been filtered with decreasing fcut.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig11-data6-v3.zip
Figure 12
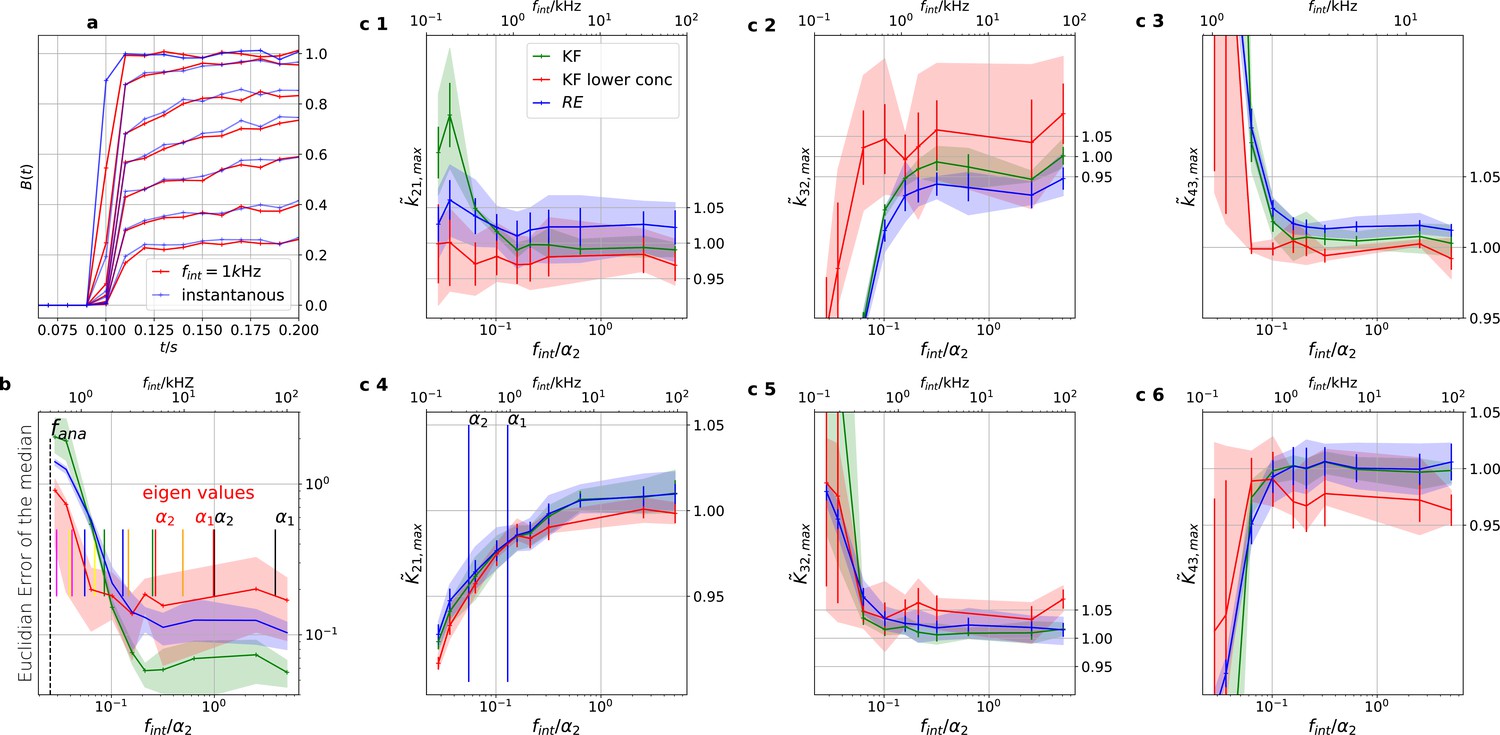
Finite integration time of fluorescence recordings acts also as a filter.
Thus the sampling should be faster than the fastest eigenvalues to avoid biased results. We simulated five different 100 kHz cPCF signals. All forms of noise were added and then the fluorescence signal was summed up using a sliding window to account for the integration time to produce one digital data point. The activation curves were then analyzed with the Bayesian filter at 125 Hz and the deactivation curves at kHz, see caption of Figure 8. We plot the 0.6-quantile (interval between the 20th and the 80th percentile) to mimic ±one standard deviation from the mean as well as the mean of the distribution of the maxima of the posterior for different data sets. (Note, this is not equivalent to the mean and quantiles of the posterior of a single data set.). The quantiles represent the randomness of the data while the error bars indicate the standard error of the mean maximum of the posterior. Blue (RE) and green (KF) indicate the two algorithms with the standard data set while red (KF) shows examples that use only the six smallest ligand concentrations for the analysis in order to limit the highest eigenvalues. a, Instantaneous probing of the ligand binding (blue) compared with a probing signal which runs at kHz. The integrated brightness of the bound ligand is photons per frame. Although the red curves seem like decent measurements of the process except for the highest two shown ligand concentrations, the mean error is roughly an order of magnitude worse than for kHz. Note, that for visualization we plot at a higher frequency than the Kalman filter analyzed the data. b, Estimate of the distribution of the (Euclidean error of the mean median of the posterior) vs. the scaled integration frequency . We use integration frequency instead of the integration time to make the plot comparable to the Bessel filter plot. The solid line is the mean median of five data sets of the respective KF posterior (green, red) and RE posterior (blue). The shaded areas indicate the 0.6-quantile which visualizes the spread of the distribution of point estimates. The two fastest time scales (eigenvalues) at the highest ligand concentration are indicated by the vertical black lines, the time scales of the next lower ligand concentrations with the red vertical lines. c 1–3, Accuracy (bias) and precision of the maxima of the posterior rates vs. the integration frequency. c 4–6, Accuracy and precision of the maxima of the posterior of the corresponding equilibria vs. the cut-off frequency of a Bessel filter.
-
Figure 12—source data 1
The data folder contains one data set of cPCF data.
The fluorescence has been integrated with decreasing fint. The number in the file name encodes the amount of data points which have been summed up to mimic the integration time. The time axis is identical for all time traces and saved in the file Time.txt. The folder is similar to six other provided source data folders which have in total been used in this figure.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig12-data1-v3.zip
-
Figure 12—source data 2
The data folder contains one data set of cPCF data.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig12-data2-v3.zip
-
Figure 12—source data 3
The data folder contains one data set of cPCF data.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig12-data3-v3.zip
-
Figure 12—source data 4
The data folder contains one data set of cPCF data.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig12-data4-v3.zip
-
Figure 12—source data 5
The data folder contains one data set of cPCF data.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig12-data5-v3.zip
-
Figure 12—source data 6
The data folder contains one data set of cPCF data.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig12-data6-v3.zip
-
Figure 12—source data 7
The data folder contains one data set of cPCF data.
- https://cdn.elifesciences.org/articles/62714/elife-62714-fig12-data7-v3.zip
Appendix 1—figure 1
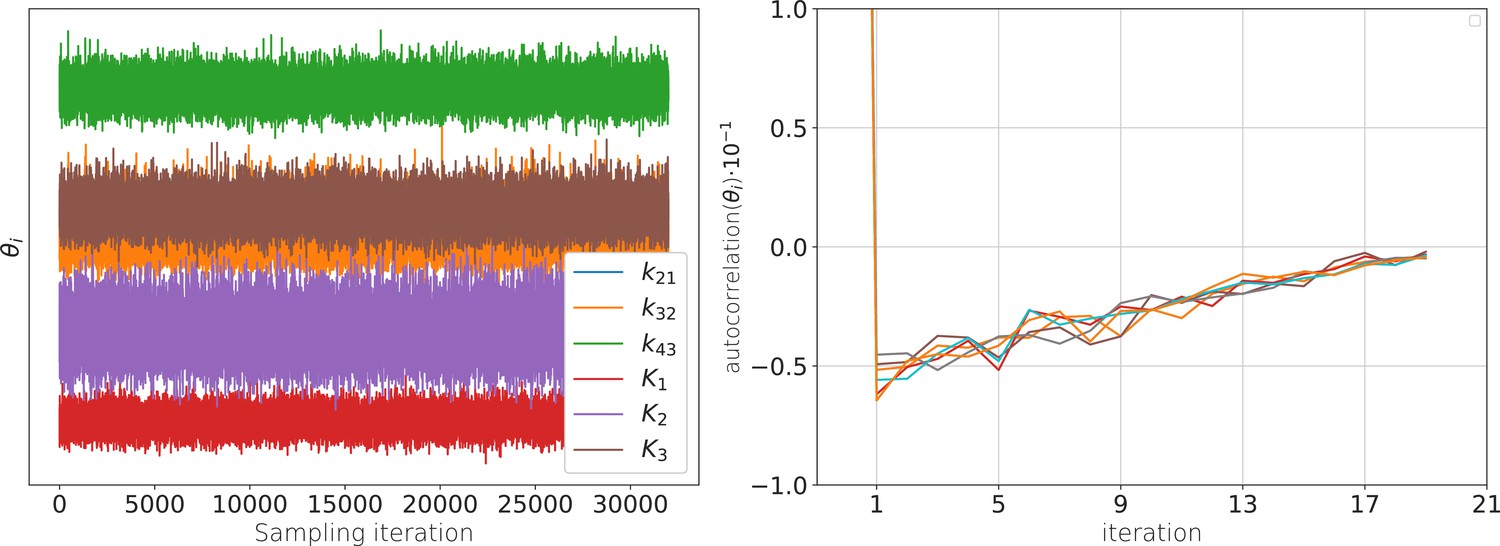
The posterior samples display autocorrelation which lowers the effective sample size.
(a) Sample traces from the 6-dimensional posterior of the rate matrix recorded after the warm-up of the sampler. (b) These traces are anti-correlated (in time) such that the effective sample size with which all quantities of relevance are estimated is smaller than the actual number of samples. Note that even at one iteration the absolute value of the auto-correlation is never larger than 0.05. The standard error of the bootstrapped mean auto-correlation is in the order of .
Appendix 1—figure 2
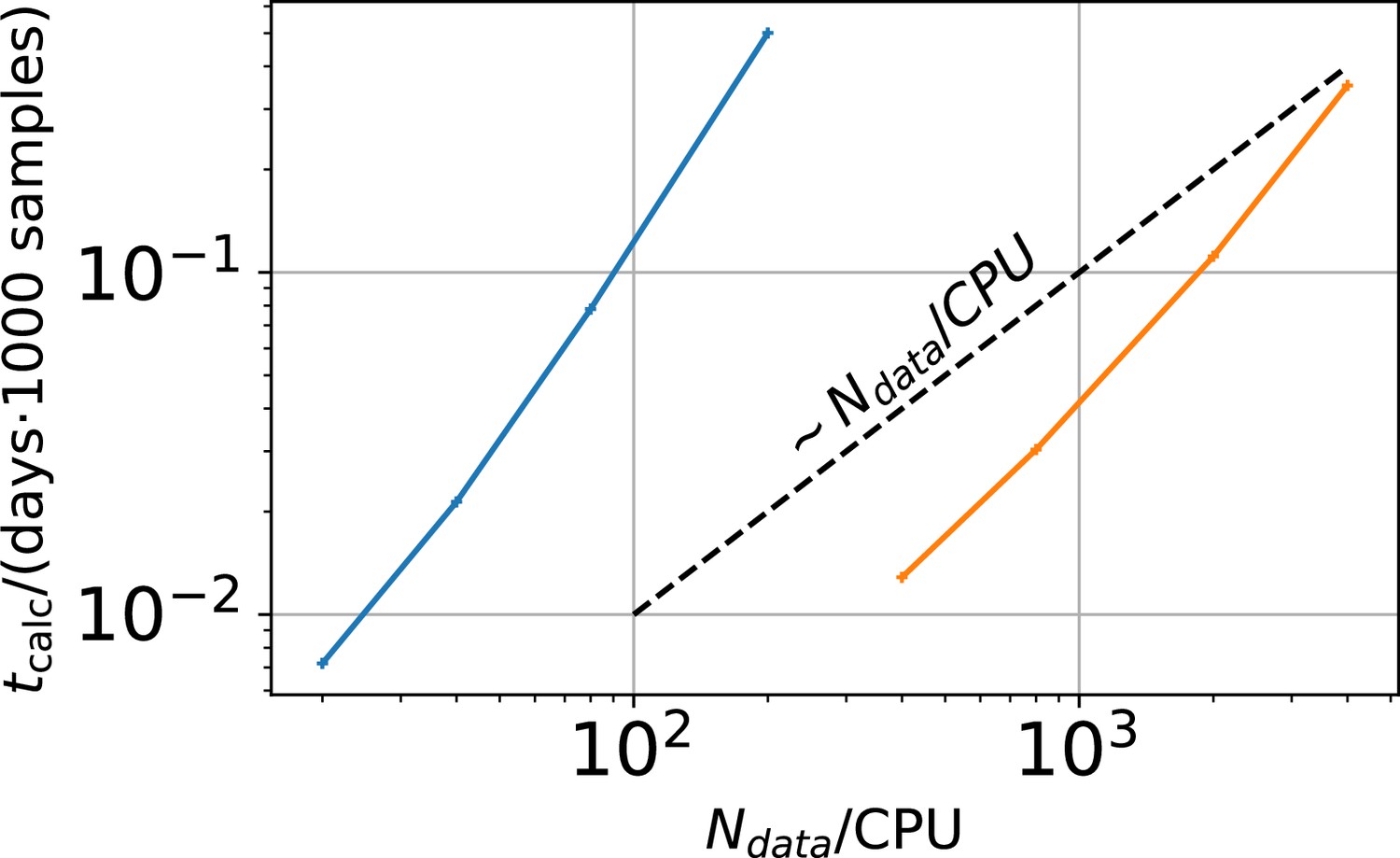
Computational time in units of 1000 samples per day vs .
The two colors represent two different implementations. The difference between the two implementations is that the derived quantities which are the predicted mean signal and the predicted signal variance for each data point in the less efficient sampling algorithm are saved. In the more efficient algorithm these derived quantities are discarded.
Appendix 1—figure 3
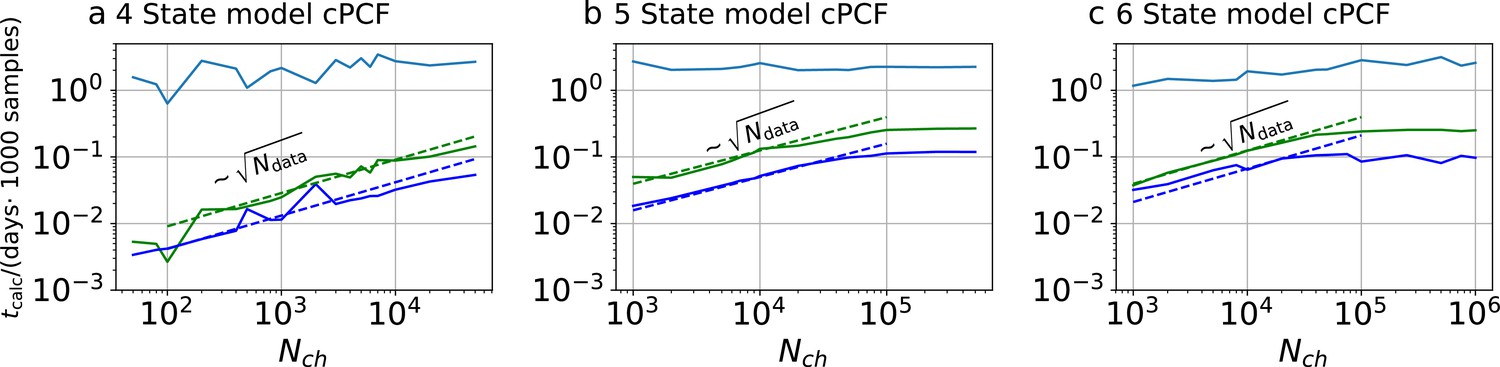
Computational time for cPCF data.
Computational time in units of 1000 samples per day vs. the amount of ion channels per trace . The green curve belongs to the results from the KF, the blue curve to the results from the RE approach. The brighter blue curve corresponds to the ratio of computational time. a, four-state model with cPCF data. The posterior of the RE approach was sampled from three independent chains. We drew 18,000 samples per chain which included a large fraction of 6000 warm-up samples per chain. The posterior of the KF was sampled from 4independent chains. We drew 26,000 samples per chain which included a large fraction of 4000 warm-up samples per chain. b Computational time of the 5-state-2-open-states model with cPCF data. The KF algorithm drew 9000 samples which included a large fraction of 6,000 warm-up samples per chain. The RE algorithm drew 10,000 samples which included a large fraction of 5,000 warm-up samples per chain. In total, we used four independent chains. c, Computational time of the 6-state-1-open-state model with cPCF data. The KF algorithm drew 10,000 samples which included a large fraction of 6000 warm-up samples per chain. The RE algorithm drew 12,000 samples which included a large fraction of 7000 warm-up samples per chain. In total, we used four independent sampling chains.
Appendix 1—figure 4
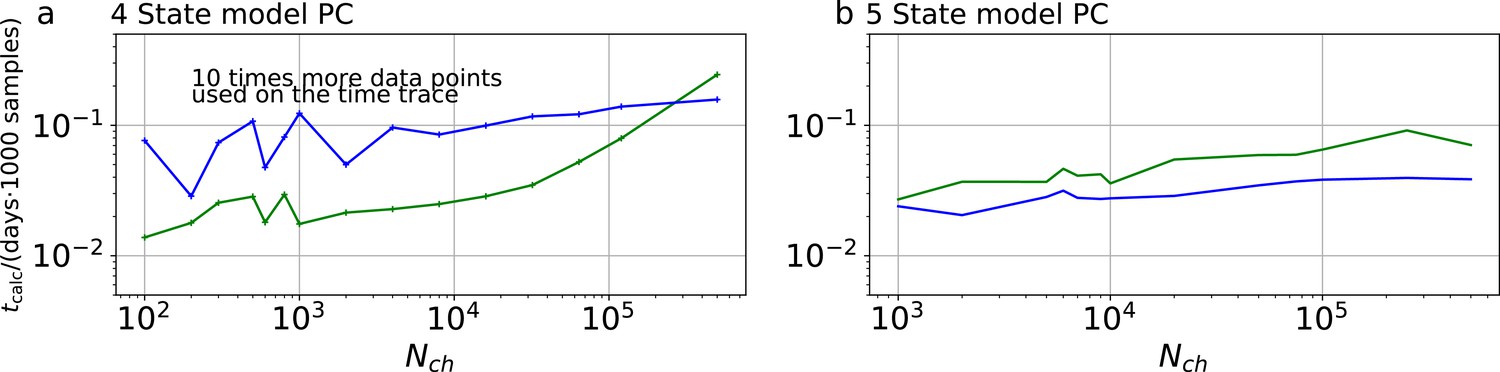
Computational time for PC data.
The computational time in units of 1,000 samples per day are plotted vs the amount of ion channels per trace . The green curve belongs to the results from the KF, the blue curve to the results from the RE approach. a, Four-state model with PC data. In contrast to the cPCF data (Appendix 1—figure 3), fana is increased by an order of magnitude. Thus, 10 times more data points per time trace and CPU are evaluated. These results were obtained by four independent chains which drew 9000 samples per chain, including a large fraction of 7000 warm-up samples per chain.b, Five-state model with PC data. Note that here fana equals the analyzing frequency of cPCF data (Appendix 1—figure 3).
Appendix 5—figure 1
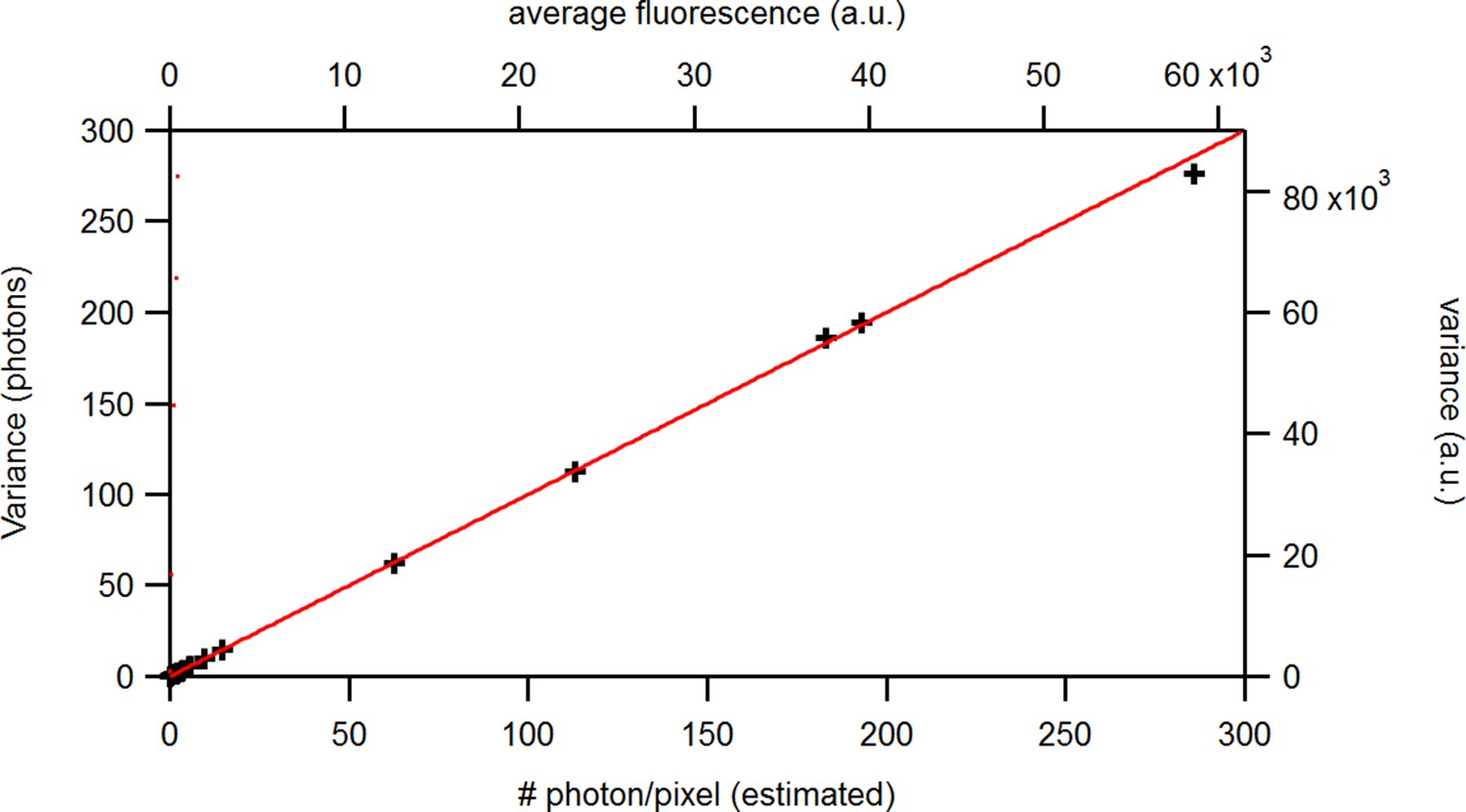
Benchmark of the signal variance vs its mean for experimental solution data recorded under cPCF conditions: The concentrations of the fluorescent ligand were 0.25, 3, and 15 and a reference dye was present. The laser intensities covered 1.6 orders of magnitude at constant detection settings. The data points were obtained from . The red and blue lines indicate the theoretical prediction for a Poisson and Gamma distribution, respectively, assuming . The linear relation allows to relate the measured a.u. (top, right axis) to photons (bottom, left axis). The inset provides the corresponding log-log plot. Important for the KF algorithm is that skewness and excess kurtosis is small.
Appendix 5—figure 2
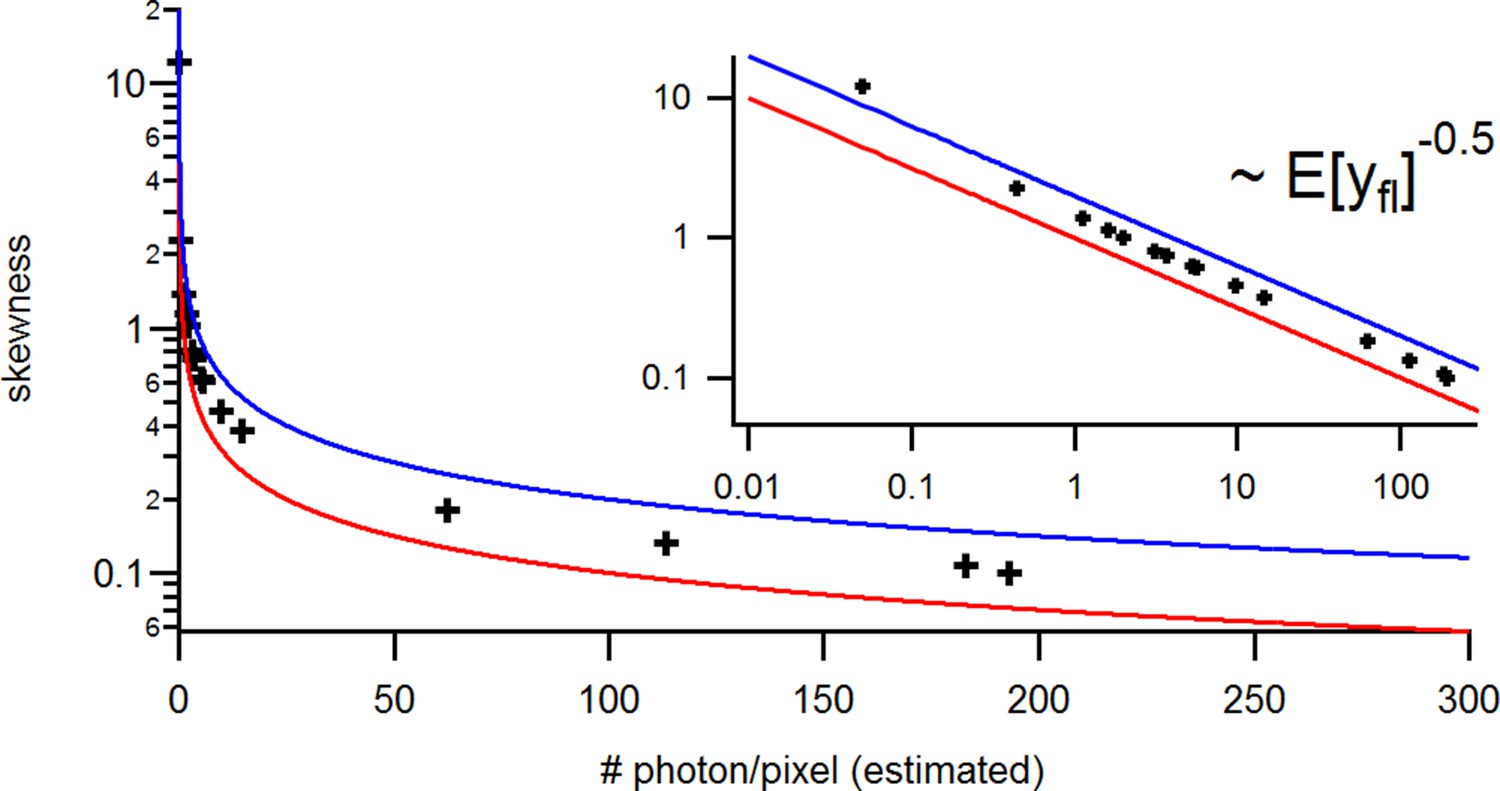
Benchmark of the signal Skewness vs its the mean for the identical experimental solution data under cPCF conditions.
The Skewness is small but the values are slightly larger than theoretically predicted. The inset provides the corresponding log-log plot. Important for the KF algorithm is that skewness and excess kurtosis is small.
Appendix 5—figure 3
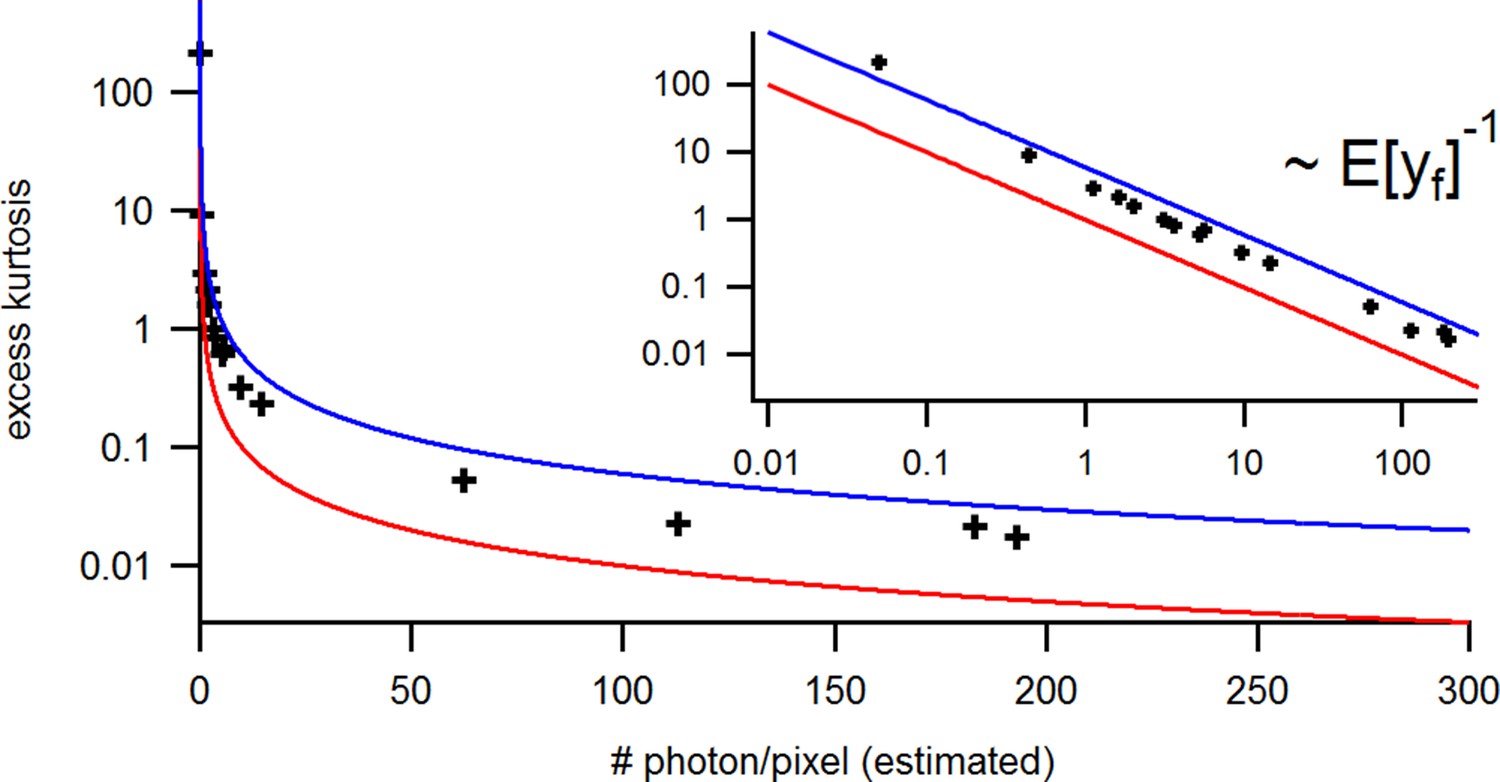
Benchmark of the signal Kurtosis vs its mean for the identical experimental solution data under cPCF conditions.
The Kurtosis is small but the values are slightly larger than theoretically predicted. The inset provides the corresponding log-log plot. Important for the KF algorithm is that skewness and excess kurtosis is small.
Appendix 5—figure 4

Simulated binding signals.
a, Comparison of binding of a labeled ligand at two concentrations. A simple two-ligand binding process was simulated with the Hill equation for the two expression levels of 1000 or 10,000 binding sites per patch and a BC50 of 1000 (BC50a) or 10,000(BC50b), respectively, given in molecules per observation unit. The observed signal is the sum of the signal from ligands free in solution and bound to the receptors. The solution signal scales linearly with the concentration, while the binding signal saturates.
Appendix 5—figure 5
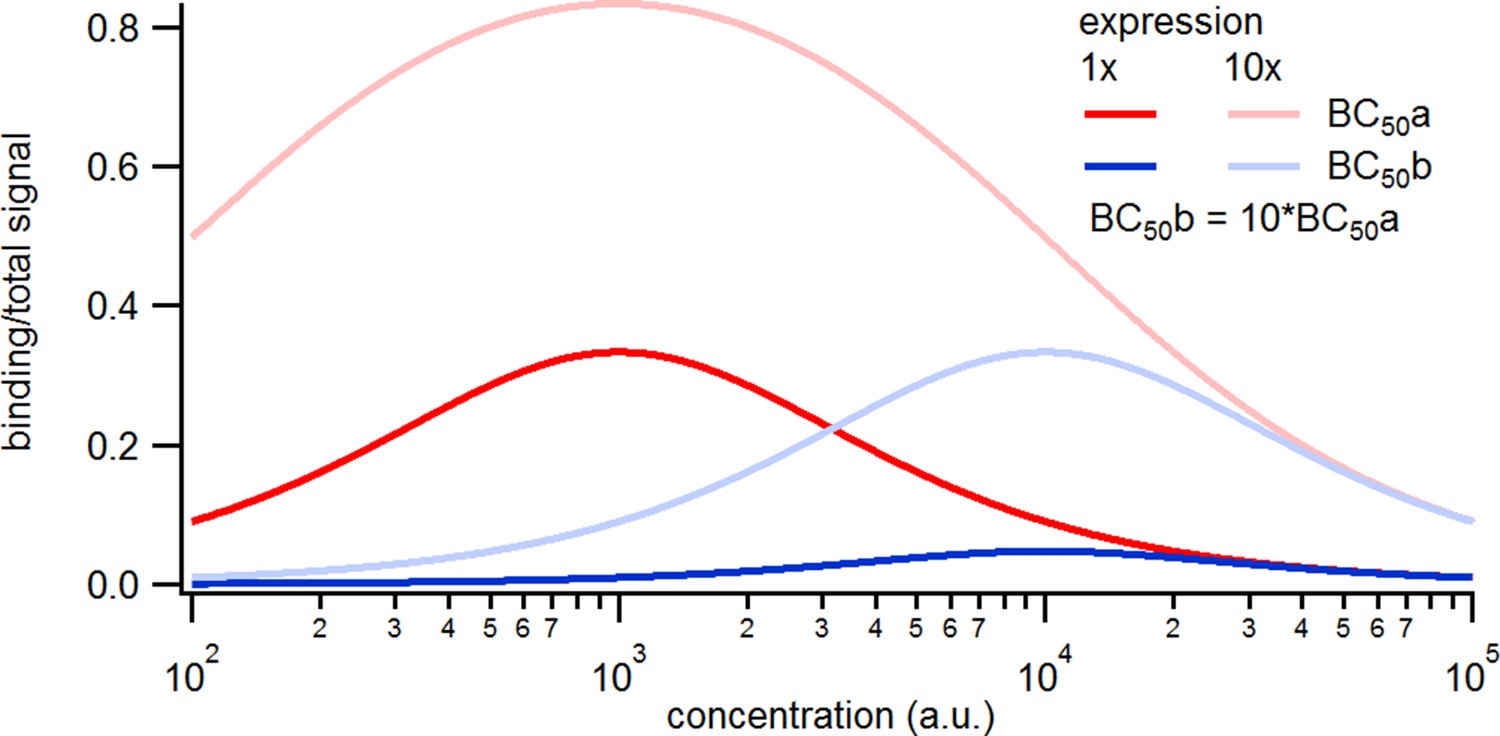
Simulated binding signals.
Relative contribution of the binding signal to the total signal. Note that the contribution of the binding signal scales linearly with the expression level and inversely with the.
Appendix 5—figure 6
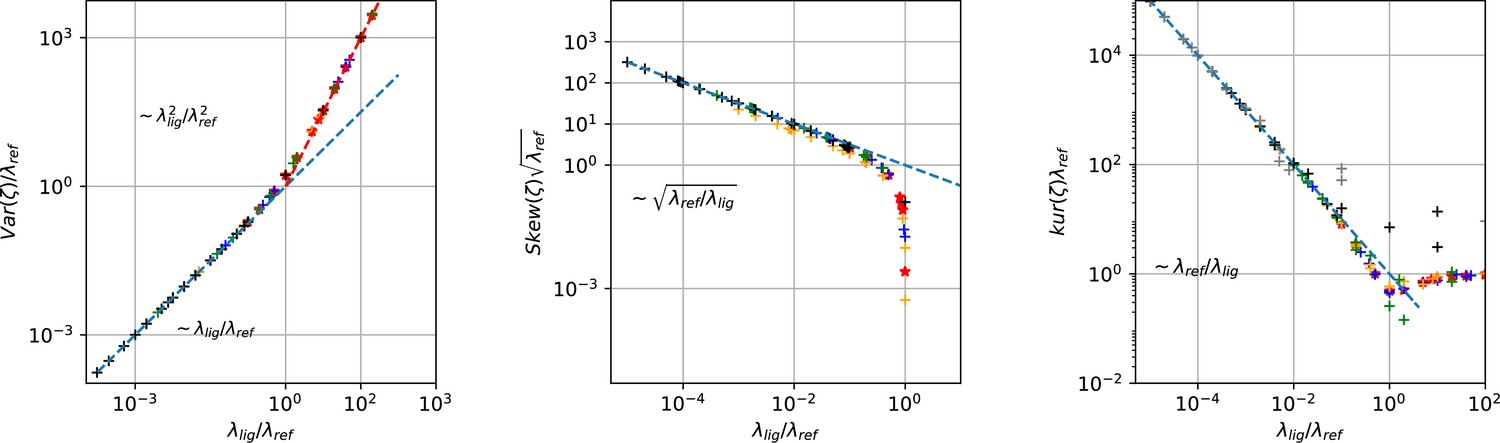
Master curves of 2nd till 4th centralized moment of photon counting noise ζ arising from the difference signal of fluorescent ligands and the dye in the bulk.
The curves are created from draws from Poisson distributions with different combinations of intensities for the reference dye and of the intensity of the confocal voxel fraction.
Appendix 7—figure 1
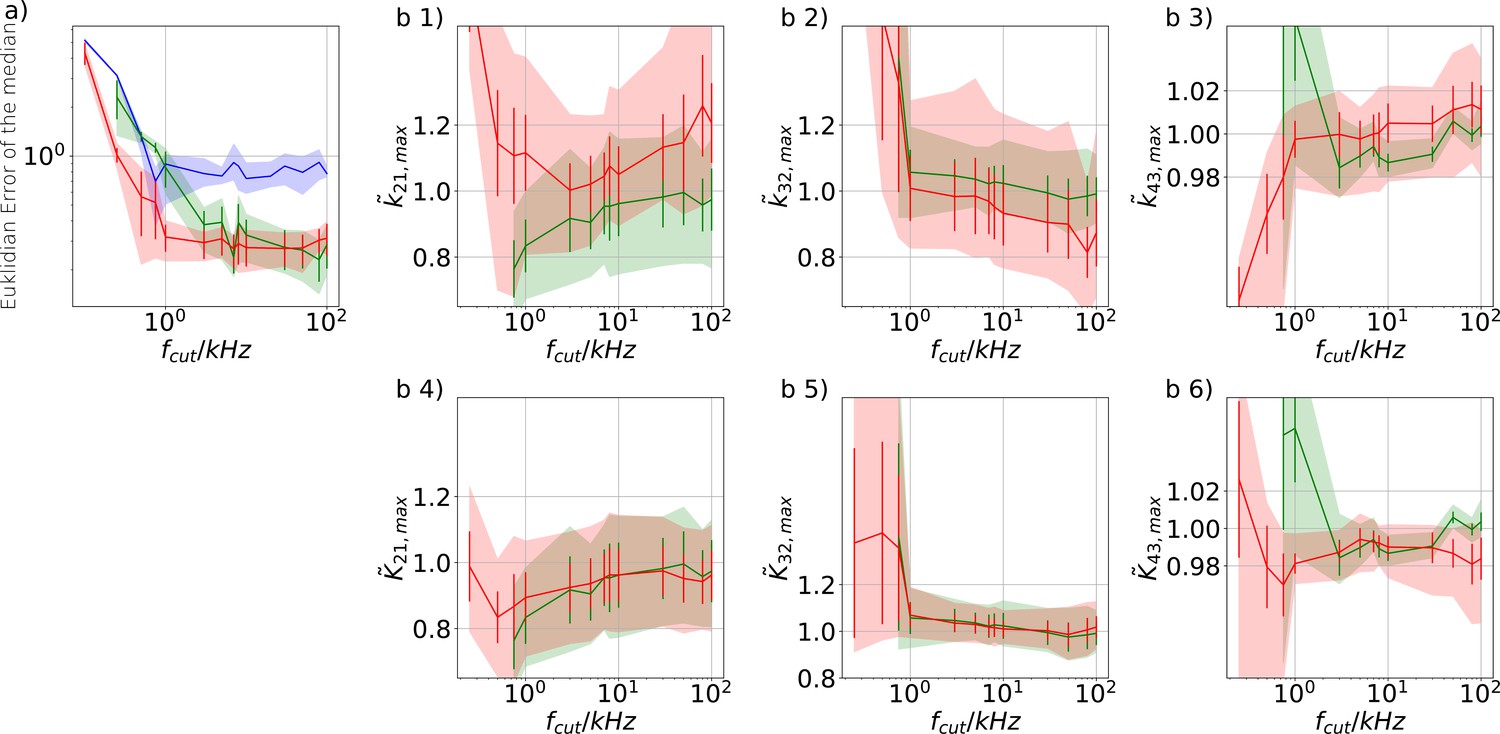
Influence of analog filtering on the accuracy and precision of the maximum of the posterior from PC data We chose for the analog signal , , thus a strong background noise.
For the ensemble size, we chose such that the likelihood dominates the uniform prior. (a) Estimate of the distribution of the accuracy (mean Euclidean error of the median of the posterior) vs. the cut-off frequency of a 4th-order Bessel filter scaled to the channel time scale. The solid line is the mean median of 5 data sets of the respective RE posterior (blue) and KF posterior (green). The green shaded area indicates the 0.6 quantile (ranging from 0.2 till 0.8) demonstrating the distribution of the error of the median of the posterior due to the randomness of data.(b 1–3) Accuracy and precision of the maxima of the posterior of the maxima of the posterior rates vs. the cut-off frequency of a Bessel filter. The shaded areas indicate the 0.6 quantiles (ranging from 0.2 till 0.8) due to the variability from data set do data set while the error bars show the standard error of the mean. (b 4–6) Accuracy and precision of the maxima of the posterior of the maxima of the posterior of the corresponding equilibria vs. the cut-off frequency of a Bessel filter.
Appendix 9—figure 1
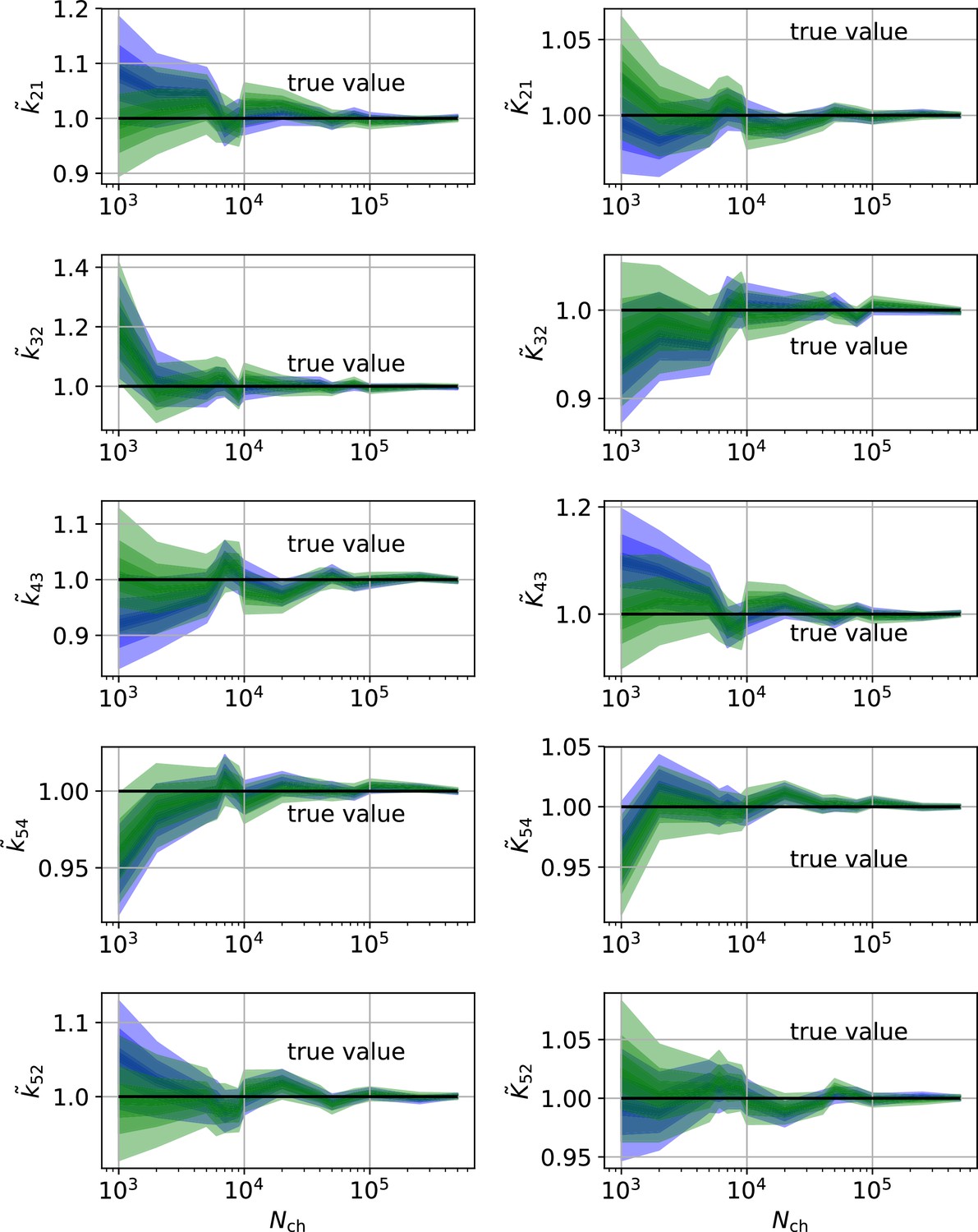
HDCIs vs for the 5-state-2-open-states model for cPCF data.
The single parameter level corresponds to the Euclidean error of Figure 7d. Compared to the main text we switched rows with columns of the panels, the first column represents now the rates and the second column the equilibrium constants. The prior that enforces microscopic-reversibility is identical to the prior mentioned in the caption of Figure 7.
Appendix 9—figure 2
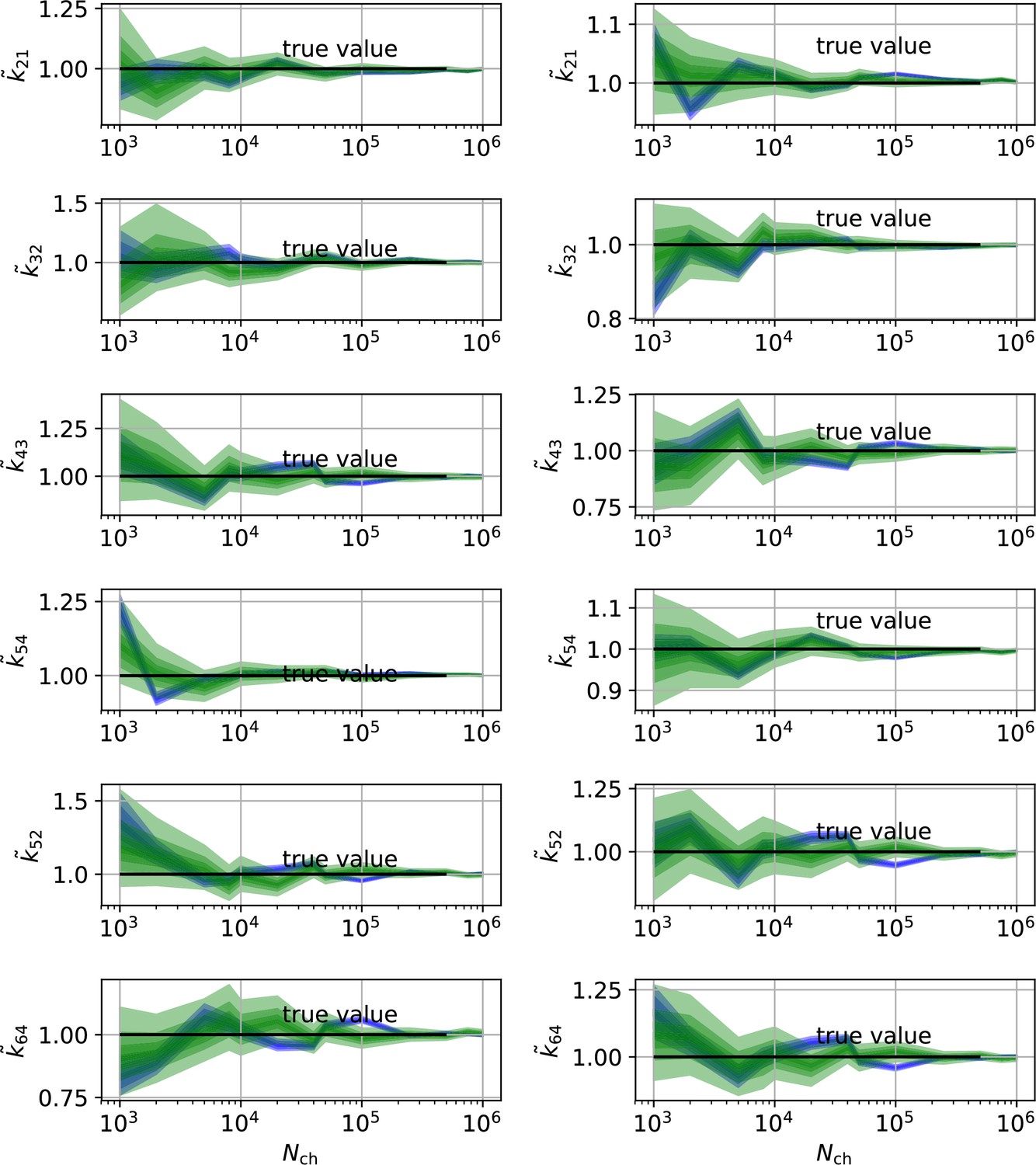
HDCIs vs for the 6-states-1-open-state model for cPCF data.
The single parameter level corresponds to the Euclidean error of Figure 7e. Compared to the main text we switched rows with columns of the panels, the first column represents now the rates and the second column the equilibrium constants. The prior that enforces microscopic-reversibility is identical to the prior mentioned in the Figure 7.
Tables
Table 1
Important symbols.
| Symbol | Meaning |
|---|---|
| Set of all unknown model parameters for which the posterior distribution is sampled | |
| Hidden ensemble occupancy vector of channel states in a specific patch at time which is a continuous Markov state vector | |
| Variance-covariance matrix of a hidden ensemble state n a specific patch at time which contains the dispersion of the ensemble and the lacking knowledge of the algorithm about the true | |
| Transition matrix of a single channel | |
| Rate matrix which is the logarithm of the transition matrix | |
| Observation matrix which projects the hidden ensemble state vector onto its mean signal. | |
| Single-molecule Markov state vector | |
| Specific transition rate from state j to state i, , | |
| Ratio of two transition rates i.e. an equilibrium constant | |
| Data point at time | |
| Number of observations in a time series | |
| Time series of data points, | |
| Time series of hidden ensemble states, | |
| Number of channels in patch number | |
| Mean electrical current through a single-channel | |
| and | Variance of the current including all noise from the patch and the recording system |
| Variance of the current noise generated by a single open-channel | |
| Mean brightness of a bound ligand | |
| Mean brightness of the fluorescence signal from bulk and bound ligands | |
| Variance of the fluorescence generated by unbound ligands after subtraction of the image obtained for the reference dye | |
| Number of single-channel states which is the dimension of in the KF algorithm | |
| Dimensions of the observational space | |
| True probability density of , i.e. the true data-generating process | |
| Likelihood function of the model parameters | |
| Posterior distribution of the model parameters | |
| Predictive distribution of the new data points | |
| Distribution of observables for a single time step | |
| Normal distribution with mean μ and variance-covariance matrix | |
| Mean value |
Table 2
Summary of signals and noise sources for the exemplary CCCO model with the closed states and the open state .
The observed space is two-dimensional with and . The fluorescence signal is assumed to be derived from the difference of two spectrally different Poisson distributed fluorescent signals. That procedure results in a scaled Skellam distribution of the noise.
| ion current | fluorescence | |||
|---|---|---|---|---|
| current signal | measurement noise | fluorescence signal | background fluorescence | |
| Signaling states | Open state | - | Ligand-bound states | - |
| Error term | Open-channel noise | Measurement noise | Photon counts | Bulk noise |
| Affected signal | Current | Current | Fluorescence | Fluorescence |
| Distribution | Normal | Normal | Poisson | Scaled Skellam |
| Contribution to | - | - | ||
| Contribution to | ||||
Appendix 1—table 1
Typical summary statistics of the posterior as printed by the “summary” method from the “fit” object in Pystan.
We deleted the 25% and 75% percentiles to decrease the size of the table and changed some of the names with respect to the used name in the algorithm to the symbol used in this article. Note that we assumed to measure 2 ligand concentrations (which includes 4 jumps) from one patch. Thus, we assumed for 10 ligand concentrations that they are coming from 5 patches which leads to a five-dimensional channels per patch vector . The bias of discussed in the main article, is also observed here.
| mean | semean | sd | 2.5% | 50% | 97.5% | neff | Rhat | |
|---|---|---|---|---|---|---|---|---|
| k21 | 507.65 | 0.06 | 11.91 | 484.74 | 507.46 | 531.62 | 41262 | 1.0 |
| k32 | 481.15 | 0.16 | 28.63 | 428.34 | 480.19 | 540.32 | 33610 | 1.0 |
| k43 | 509.95 | 0.04 | 6.99 | 496.39 | 509.91 | 523.77 | 36006 | 1.0 |
| K1 | 0.5 | 2.6e-5 | 5.2e-3 | 0.49 | 0.5 | 0.51 | 40548 | 1.0 |
| K2 | 0.51 | 6.7e-5 | 0.01 | 0.49 | 0.51 | 0.54 | 33228 | 1.0 |
| K3 | 0.49 | 4.2e-5 | 7.5e-3 | 0.47 | 0.49 | 0.5 | 31445 | 1.0 |
| Nch[1] | 1007.1 | 0.14 | 20.05 | 968.84 | 1006.8 | 1047.2 | 19838 | 1.0 |
| Nch[2] | 1006.1 | 0.14 | 20.04 | 967.83 | 1005.8 | 1046.0 | 19874 | 1.0 |
| Nch[3] | 1003.9 | 0.14 | 20.0 | 965.66 | 1003.6 | 1043.8 | 19877 | 1.0 |
| Nch[4] | 1007.0 | 0.14 | 20.09 | 968.67 | 1006.6 | 1047.1 | 19843 | 1.0 |
| Nch[5] | 1005.9 | 0.14 | 20.09 | 967.61 | 1005.6 | 1045.9 | 19874 | 1.0 |
| i | 1.0 | 7.0e-5 | 9.8e-3 | 0.98 | 1.0 | 1.02 | 19971 | 1.0 |
| 0.25 | 1.2e-5 | 2.5e-3 | 0.25 | 0.25 | 0.26 | 43142 | 1.0 | |
| 2.5e-3 | 1.2e-7 | 2.5e-5 | 2.5e-3 | 2.5e-3 | 2.5e-3 | 42707 | 1.0 | |
| 1.3e-5 | 2.3e-8 | 4.6e-6 | 1.0e-5 | 1.2e-5 | 2.5e-5 | 41306 | 1.0 | |
| λ | 9.98 | 1.1e-4 | 0.02 | 9.94 | 9.98 | 10.02 | 35109 | 1.0 |
Additional files
-
Transparent reporting form
- https://cdn.elifesciences.org/articles/62714/elife-62714-transrepform1-v3.docx
-
Source code 1
cPCF data simulation code.
- https://cdn.elifesciences.org/articles/62714/elife-62714-code1-v3.zip
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Bayesian inference of kinetic schemes for ion channels by Kalman filtering
eLife 11:e62714.
https://doi.org/10.7554/eLife.62714




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}