Bayesian machine learning analysis of single-molecule fluorescence colocalization images
- Department of Biochemistry, Brandeis University, United States
Abstract
Multi-wavelength single-molecule fluorescence colocalization (CoSMoS) methods allow elucidation of complex biochemical reaction mechanisms. However, analysis of CoSMoS data is intrinsically challenging because of low image signal-to-noise ratios, non-specific surface binding of the fluorescent molecules, and analysis methods that require subjective inputs to achieve accurate results. Here, we use Bayesian probabilistic programming to implement Tapqir, an unsupervised machine learning method that incorporates a holistic, physics-based causal model of CoSMoS data. This method accounts for uncertainties in image analysis due to photon and camera noise, optical non-uniformities, non-specific binding, and spot detection. Rather than merely producing a binary ‘spot/no spot’ classification of unspecified reliability, Tapqir objectively assigns spot classification probabilities that allow accurate downstream analysis of molecular dynamics, thermodynamics, and kinetics. We both quantitatively validate Tapqir performance against simulated CoSMoS image data with known properties and also demonstrate that it implements fully objective, automated analysis of experiment-derived data sets with a wide range of signal, noise, and non-specific binding characteristics.
Editor's evaluation
Using a Bayesian machine learning approach, the authors of this paper have developed a tool for the analysis of single-molecule fluorescence colocalization microscopy images. The authors develop the algorithm, generate an associated software program, and then benchmark the algorithm and software using both simulated and experimental data. The results provide an important, validated tool for use by the single-molecule fluorescence microscopy community.
https://doi.org/10.7554/eLife.73860.sa0Introduction
A central concern of modern biology is understanding at the molecular level the chemical and physical mechanisms by which protein and nucleic acid macromolecules perform essential cellular functions. The operation of many such macromolecules requires that they work not as isolated molecules in solution but as components of dynamic molecular complexes that self-assemble and change structure and composition as they function. For more than two decades, scientists have successfully explored the molecular mechanisms of many such complex and dynamic systems using multi-wavelength single molecule fluorescence methods such as smFRET (single-molecule fluorescence resonance energy transfer) (Roy et al., 2008) and multi-wavelength single-molecule colocalization methods (CoSMoS, colocalization single molecule spectroscopy) (Larson et al., 2014; van Oijen, 2011; Friedman and Gelles, 2012).
CoSMoS is a technique to measure the kinetics of dynamic interactions between individual molecules. The CoSMoS method has been used for elucidating the mechanisms of complex biochemical processes in vitro. Examples include cell cycle regulation (Lu et al., 2015b), ubiquitination and proteasome-mediated protein degradation (Lu et al., 2015a), DNA replication (Geertsema et al., 2014; Ticau et al., 2015), transcription (Zhang et al., 2012; Friedman and Gelles, 2012; Friedman et al., 2013), micro-RNA regulation (Salomon et al., 2015), pre-mRNA splicing (Shcherbakova et al., 2013; Krishnan et al., 2013; Warnasooriya and Rueda, 2014), ribosome assembly (Kim et al., 2014), translation (Wang et al., 2015; Tsai et al., 2014; O’Leary et al., 2013), signal recognition particle-nascent protein interaction (Noriega et al., 2014), and cytoskeletal regulation (Smith et al., 2013; Breitsprecher et al., 2012).
Figure 1A illustrates an example CoSMoS experiment to measure the interaction kinetics of RNA polymerase II molecules with DNA. In the experiment (Rosen et al., 2020), we first measured the locations of individual DNA molecules (the ‘targets’) tethered to the surface of an observation chamber at low density. Next, a cell extract solution containing fluorescent RNA polymerase II molecules (the ‘binders’) was added to the solution over the surface and the chamber surface was imaged by total internal reflection fluorescence (TIRF) microscopy. When the binder molecules are freely diffusing in solution, they are not visible in TIRF. In contrast, when bound to a target, a single binder molecule is detected as a discrete fluorescent spot colocalized with the target position (Friedman et al., 2006; Friedman and Gelles, 2015).
Figure 1
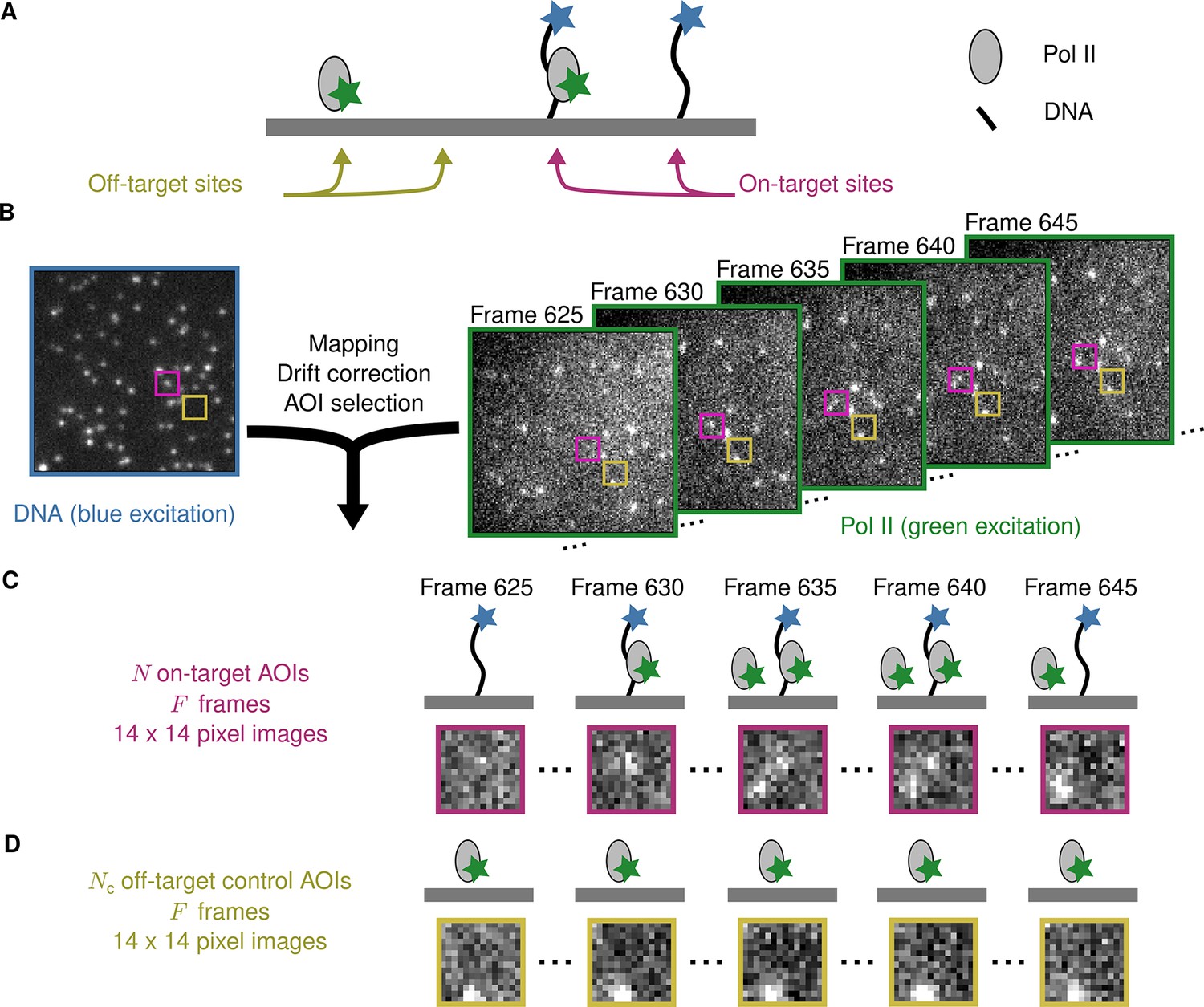
Example CoSMoS experiment.
(A) Experiment schematic. DNA target molecules labeled with a blue-excited fluorescent dye (blue star) are tethered to the microscope slide surface. RNA polymerase II (Pol II) binder molecules labeled with a green-excited dye (green star) are present in solution. (B) Data collection and preprocessing. After collecting a single image with blue excitation to identify the locations of the DNA molecules, a time sequence of Pol II images was collected with green excitation. Preprocessing of the images includes mapping of the corresponding points in target and binder channels, drift correction, and identification of two sets of areas of interest (AOIs). One set corresponds to locations of target molecules (e.g., purple square); the other corresponds to locations where no target is present (e.g., yellow square). (C) On-target data. Data are time sequences of 14 × 14 pixel AOI images centered at each target molecule. Frames show presence of on-target (e.g., frame 630) and off-target (e.g., frame 645) Pol II molecules. (D) Off-target control data. Control data consists of images collected from randomly selected sites at which no target molecule is present. Such sites can be AOIs in which no fluorescent target molecule is visible (e.g., the yellow square in the DNA channel shown in B). Alternatively, control data can be taken from a recording of a separate control sample to which no target molecules were added. Image data in B, C, and D is from Data set A in Table 1.
Effective data analysis is a major challenge in the use of the CoSMoS technique. The basic goal is to acquire information at each time point about whether a binder molecule fluorescence spot is observed at the image position of a target molecule (e.g., whether a colocalized green-dye-labeled RNA polymerase II is observed at the surface location of a blue-dye-labeled DNA spot in Figure 1B). Although CoSMoS images are conceptually simple – they consist only of diffraction-limited fluorescent spots collected in several wavelength channels – efficient analysis of the images is inherently challenging. The number of photons emitted by a single fluorophore is limited by fluorophore photobleaching. Consequently, it is desirable to work at the lowest feasible excitation power in order to maximize the duration of experimental recordings and to efficiently capture relevant reaction events. Achieving higher time resolution divides the number of emitted photons between a larger number of images, so that photon shot noise ordinarily dominates the data statistics. Furthermore, the required concentrations of binder molecules can sometimes create significant background noise (Peng et al., 2018; van Oijen, 2011), even with zero-mode waveguide instruments (Chen et al., 2014). These technical difficulties frequently result in CoSMoS images that have low signal-to-noise ratios (SNR), making discrimination of colocalized fluorescence spots from noise a significant challenge. In addition, there are usually non-specific interactions of the binder molecule with the chamber surface, and these artefacts can give rise to both false positive and false negative spot detection (Friedman and Gelles, 2015). Together, these defects in analyzing spot colocalization interfere with the interpretation of CoSMoS data to measure reaction thermodynamics and kinetics and to infer molecular mechanisms.
Most CoSMoS spot detection methods are based on integrating the binder fluorescence intensity by summing the pixel values in small regions of the image centered on the location of individual target molecules, and then using crossings of an intensity threshold to score binder molecule arrival and departure, e.g., (Friedman and Gelles, 2012; Shcherbakova et al., 2013). However, integration discards data about the spatial distribution of intensity that can (and should) be used to distinguish authentic on-target spots from artefacts caused by noise or off-target binding. More recently, improved methods (Friedman and Gelles, 2015; Smith et al., 2019) were developed that directly analyze TIRF images, using the spatial distribution of binder fluorescence intensity around the target molecule location. All these methods, whether image- or integrated intensity-based, make a binary decision about the presence or absence of a binder spot at the target location. Treating all such binary decisions as equal neglects differences in the confidence of each spot detection decision caused by variations in noise, signal intensity, and non-specific binding. Failure to account for spot confidence decreases the reliability of downstream thermodynamic and kinetic analysis.
In this paper, we describe a qualitatively different Bayesian machine learning method for analysis of CoSMoS data implemented in a computer program, Tapqir (Kazakh: clever, inventive; pronunciation: tap-keer). Tapqir analyzes two-dimensional image data, not integrated intensities. Unlike prior methods, our approach is based on an explicit, global causal model for CoSMoS image formation and uses variational Bayesian inference (Kinz-Thompson et al., 2021; Gelman et al., 2013) to determine the values of model parameters and their associated uncertainties. This model, which we call ‘cosmos’, implements time-independent analysis of single-channel (i.e., one-binder) data sets. The cosmos model is physics-informed and includes realistic shot noise in fluorescent spots and background, camera noise, the size and shape of spots, and the presence of both target-specific and nonspecific binder molecules in the images. Most importantly, instead of yielding a binary spot-/no-spot determination, the algorithm calculates the probability of a target-specific spot being present at each time point and target location. The calculated probability can then be used in subsequent analyses of the molecular thermodynamics and kinetics. Unlike alternative approaches, Tapqir and cosmos do not require subjective threshold settings so they can be used effectively and accurately by non-expert analysts. The program is implemented in the Python-based probabilistic programming language Pyro (Bingham et al., 2019), which enables efficient use of graphics processing unit (GPU)-based hardware for rapid parallel processing of data and facilitates future modifications to the model.
Results
Data analysis pipeline
The initial steps in CoSMoS data analysis involve preprocessing the data set (Figure 1B) to map the spatial relationship between target and binder images, correct for microscope drift (if any) and list the locations of target molecules. Software packages that perform these preprocessing steps are widely available (e.g., Friedman and Gelles, 2015; Smith et al., 2019).
The input into Tapqir consists of the time sequence of images (Figure 1B, right). For colocalization analysis, it is sufficient to consider the image area local to the target molecule. This analyzed area of interest (AOI) needs to be several times the diameter of a diffraction-limited spot to include both the spot and the surrounding background (Figure 1C).
In addition to AOIs centered at target molecules, it is useful to also select negative control AOIs from randomly selected sites at which no target molecule is present (Figure 1B and D). In Tapqir, such off-target control data is analyzed jointly with on-target data and serves to estimate the background level of target-nonspecific binding.
Once provided with the preprocessing data and image sequence, Tapqir computes for each frame of each AOI the probability, , that a target-specific fluorescence spot is present. The values that are output can then be used to extract information about the kinetics and thermodynamics of the target-binder interaction.
Bayesian image classification analysis
Tapqir calculates values using an objective image classification method built on a rigorous Bayesian statistical approach to the CoSMoS image analysis problem. The Bayesian approach has three components. First, we define a probabilistic model of the CoSMoS images. The probabilistic model, cosmos, is a mathematical formalism that describes the AOI images in terms of a set of parameter values. The model is probabilistic in that each parameter is specified to have a probability distribution that defines the likelihood that it can take on particular values. Model parameters describe physically realistic image features such as the characteristic fluorescence spot width. Second, we specify prior distributions for the parameters of the model. These priors embed pre-existing knowledge about the CoSMoS experiment, such as the fact that target-specific spots will be close to the target molecule locations. Third, we infer the values of the model parameters, including , using Bayes’ rule (Bishop, 2006; Kinz-Thompson et al., 2021). The cosmos model is ‘time-independent’, meaning that we ignore the time dimension of the recording – the order of the images does not affect the results.
Probabilistic image model and parameters
A single AOI image from a CoSMoS data set is a matrix of noisy pixel intensity values. In each image, multiple binder molecule fluorescence spots can be present. Figure 2A shows an example image where two spots are present; one spot is located near the target molecule at the center of the image and another is off-target.
Figure 2 with 2 supplements see all
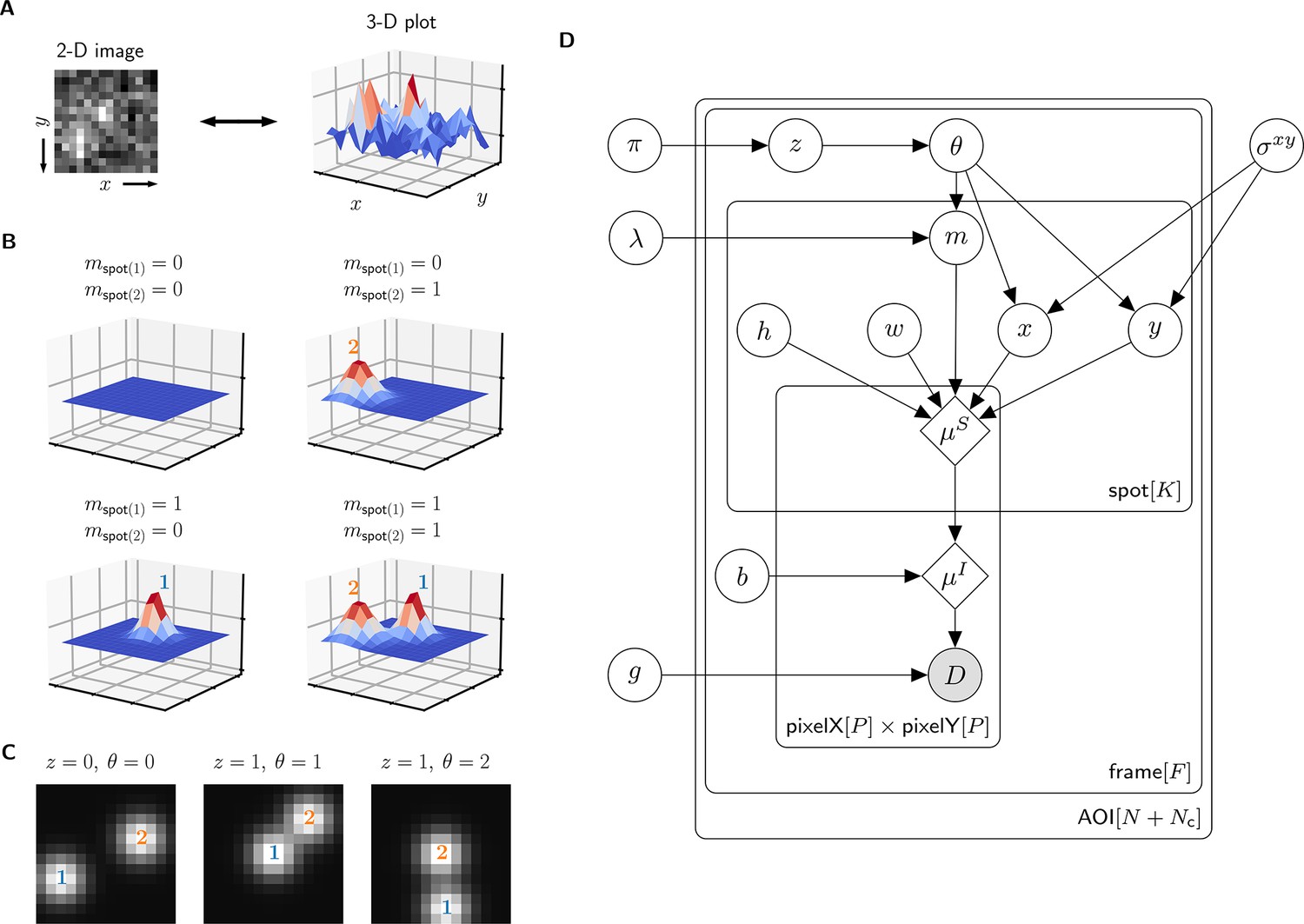
Depiction of the cosmos probabilistic image model and model parameters.
(A) Example AOI image (from Data set A in Table 1). The AOI image is a matrix of 14 × 14 pixel intensities which is shown here as both a 2-D grayscale image and as a 3-D intensity plot. The image contains two spots; one is centered at target location (image center) and the other is located off-target. (B) Examples of four idealized noise-free image representations (). Image representations consist of zero, one, or two idealized spots () superimposed on a constant background (). Each fluorescent spot is represented as a 2-D Gaussian parameterized by integrated intensity (), width (), and position (, ). The presence of spots is encoded in the binary spot existence indicator . (C) Simulated idealized images illustrating different values of the target-specific spot state parameter and index parameter . = 0 corresponds to a case when no specifically bound molecule is present ( = 0); = 1 or 2 corresponds to the cases in which specifically bound molecule is present ( = 1) and corresponds to spot 1 or 2, respectively. (D) Condensed graphical representation of the cosmos probabilistic model. Model parameters are depicted as circles and deterministic functions as diamonds. Observed image () is represented by a shaded circle. Related nodes are connected by edges, with an arrow pointing towards the dependent node (e.g., the shape of each 2-D Gaussian spot depends on spot parameters , , , , and ). Plates (rounded rectangles) contain entities that are repeated for the number of instances displayed at the bottom-right corner: number of total AOIs (), frame count (), and maximum number of spots in a single image ( = 2). Parameters outside of the plates are global quantities that apply to all frames of all AOIs. A more complete version of the graphical model specifying the relevant probability distributions is given in Figure 2—figure supplement 1.
The probabilistic model mathematically generates images as follows. We construct a noise-free AOI image as a constant average background intensity summed with fluorescence spots modeled as 2-D Gaussians , which accurately approximate the microscope point spread function (Zhang et al., 2007; Figure 2B). Each 2-D Gaussian is described by parameters integrated intensity , width , and position (, ). We define as the maximum number of spots that can be present in a single AOI image. For the data we typically encounter, = 2 is sufficient. Since the spots may be present or not in a particular image, we define the = 2 binary indicators and . Each indicator can take a value of either 0 denoting spot absence or 1 denoting spot presence.
The resulting mixture model has four possible combinations for and : (1) a no-spot image that contains only background (Figure 2B, top left), (2) a single-spot image that contains the first binder molecule spot superimposed on background (Figure 2B, bottom left), (3) a single-spot image that contains the second binder molecule spot superimposed on background (Figure 2B, top right), and (4) a two-spot image that contains both binder molecule spots superimposed on background (Figure 2B, bottom right).
Among the spots that are present in an AOI image, by assumption at most only one can be target-specific. We use a state parameter to indicate target-specific spot absence ( = 0) or presence ( = 1) in an AOI image. We also introduce an index parameter that identifies which of the spots is the target-specific spot when it is present ( = 1) (e.g., Figure 2C, middle and right have = 1 and = 2, respectively) and equals zero when it is absent ( = 0) (e.g., Figure 2C, left). Since the off-target control AOIs by definition contain only non-specific binding, = 0 and = 0 for all off-target AOIs.
Finally, to construct realistic noisy AOI images from the noise-free images , the model adds intensity-dependent noise to each pixel. For cameras that use charge-coupled device (CCD) or electron-multiplier CCD (EMCCD) sensors, each measured pixel intensity in a single-molecule fluorescence image has a noise contribution from photon counting (shot noise) and can also contain additional noise arising from electronic amplification (van Vliet et al., 1998). The result is a characteristic linear relationship between the noise variance and mean intensity with slope defining the gain . This relationship is used to compute the random pixel noise values (see Materials and methods).
The resulting probabilistic image model can be interpreted as a generative process that produces the observed image data . A graphical representation of the probabilistic relationships in the model is shown in Figure 2D. A complete description of the model is given in Materials and methods and Figure 2—figure supplement 1.
Parameter prior distributions
Specifying prior probability distributions for model parameters is essential for Bayesian analysis and allows us to incorporate pre-existing knowledge about the experimental design. For most model parameters, there is no strong prior information so we use uninformative prior distributions (see Materials and methods). However, we have strong expectations for the positions of specific and non-specific binder molecules that can be expressed as prior distributions and used effectively to discriminate between the two. Non-specific binding can occur anywhere on the surface with equal probability and thus has a uniform prior distribution across the AOI image. Target-specific binding, on the other hand, is colocalized with the target molecule and thus has a prior distribution peaked at the AOI center (Figure 2—figure supplement 2). The width of this peak, proximity parameter , depends on multiple features of the experiment such as the spot localization accuracy and the mapping accuracy between target and binder imaging channels. Prior distributions for parameters and are defined in terms of the average number of target-specific and target non-specific spots per AOI image, and , respectively. To facilitate convenient use of the algorithm, it is not necessary to pre-specify values of , , and . Instead, values of these parameters appropriate to a given data set are calculated automatically using a hierarchical Bayesian analysis (see Materials and methods; for hierarchical modeling see Chapter 5 of Gelman et al., 2013).
Bayesian inference and implementation
Tapqir calculates posterior distributions of model parameters conditioned on the observed data by using Bayes’ theorem. In particular, Tapqir approximates posterior distributions using a variational inference approach implemented in Pyro (Bingham et al., 2019). Complete details of the implementation are given in Materials and methods.
Tapqir analysis
In initial tests, we used Tapqir to analyze simulated CoSMoS image data with a comparatively high SNR of 3.76 as well as data from the experiment shown in Figure 1B–D, which has a lower SNR of 1.61. The simulated data were generated using the same cosmos model (Figure 2D) that was used for analysis. Tapqir correctly detects fluorescent spots in both simulated and experimental images (compare ‘AOI images’ and ‘Spot-detection’ rows in Figure 3). The program precisely calculates the position (, ), intensity (), and width () for each spot and also determines the background intensity () for each image without requiring a separate analysis. These parameters confirm the desired behavior of the model and could be used in further calculations. However, the most important output of the analysis is assessment of the presence of target-specific binding. For each AOI image, we calculate (Figure 3, green), the probability that any target-specific spot is present. Spots determined as likely target-specific ( > 0.5) are represented as filled circles in the spot detection row of Figure 3. For a particular spot to have high , it must have a high spot probability and be colocalized with the target molecule at the center of the AOI (Figure 3—figure supplement 1).
Figure 3 with 4 supplements see all

Tapqir analysis and inferred model parameters.
(A,B) Tapqir was applied to simulated data (lamda0.5 parameter set in Supplementary file 1) (A) and to experimental data (Data set A in Table 1) (B). (A) and (B) each show a short extract from a single target location in the data set. The first row shows AOI images for the subset of frames indicated by gray shaded stripes in the plots; image contrast and offset settings are consistent within each panel. The second row shows the locations of spots determined by Tapqir. Spot numbers 1 (blue) and 2 (orange) are assigned arbitrarily and may change from fame to frame. For clarity, only data for spots with a spot probability > 0.5 are shown. Spots predicted to be target-specific ( > 0.5 for spot ) are shown as filled circles. The topmost graphs (green) show the calculated probability that a target-specific spot is present () in each frame. Below are the calculated spot intensities (), spot widths (), and locations (, ) for spot 1 (blue) and spot 2 (orange), and the AOI background intensities (). Again, for clarity data are only shown for likely spots ( > 0.5). Error bars: 95% CI (credible interval) estimated from a sample size of 500. Some error bars are smaller than the points and thus not visible.
Tapqir robustly fits experimental data sets with different characteristics
Next, we evaluated how well the model fits data sets encompassing a range of characteristics found in typical CoSMoS experiments. We analyzed four experimental data sets with varying SNR, frequency of target-specific spots, and frequencies of non-specific spots (Table 1). We then sampled AOI images from the posterior distributions of parameters (a method known as posterior predictive checking Gelman et al., 2013). These posterior predictive simulations accurately reproduce the experimental AOI appearances, recapitulating the noise characteristics and the numbers, intensities, shapes, and locations of spots (Figure 3—figure supplement 2, images). The distributions of pixel intensities across the AOI are also closely reproduced (Figure 3—figure supplement 2, histograms) confirming that the noise model is accurate. Taken together, these results confirm that the model is rich enough to accurately capture the full range of image characteristics from CoSMoS data sets taken over different experimental conditions. Importantly, all the results on different experimental data sets were obtained using the same model (Figure 2D) and the same priors (Materials and methods). No tuning of the algorithm or prior measurement of data-set-specific properties was needed to achieve good fits for all data sets.
Table 1
Experimental data sets.
| Data set sizea | SNR | π [95% CI] | λ [95% CI] | g [95% CI] | σxy [95% CI] | Compute time |
|---|---|---|---|---|---|---|
| Data set A: Binder, SNAPf-tagged S. cerevisiae RNA polymerase II labeled with DY549; Target, transcription template DNA containing 5× Gal4 upstream activating sequences and CYC1 core promoter; Conditions, yeast nuclear extract supplemented with Gal4-VP16 activator and NTPs. From Rosen et al., 2020. | ||||||
| = 331, = 526, = 790 | 1.61 | 0.0951 [0.0936, 0.0966] | 0.2943 [0.2924, 0.2963] | 6.645 [6.643, 6.647] | 0.577 [0.573, 0.580] | 7 h 40 mb 3 h 50 mc |
| Data set B: Binder, 0.1 nM E. coli σ54 RNA polymerase labeled with Cy3; Target, 852 bp DNA containing the glnALG promoter; Conditions, physiological buffer, no NTPs. From (Fig. 1E) of Friedman et al., 2013. | ||||||
| = 102, = 127, = 4407 | 3.77 | 0.0846 [0.0835, 0.0857] | 0.1575 [0.1569, 0.1583] | 11.861 [11.856, 11.865] | 0.476 [0.474, 0.479] | 7 h 40 mb |
| Data set C: Binder, 0.4 nM E. coli σ54 RNA polymerase labeled with Cy3; Target, 3,591 bp DNA containing the glnALG promoter; Conditions, physiological buffer, no NTPs. From (Fig. 3D) of Friedman et al., 2013. | ||||||
| = 122, = 157, = 3855 | 4.23 | 0.0267 [0.0262, 0.0273] | 0.0876 [0.0869, 0.0883] | 16.777 [16.773, 16.782] | 0.404 [0.399, 0.408] | 9 h 15 mb |
| Data set D: Binder, 0.15 nM E. coli Cy3-GreB; Target, reconstituted backtracked EC-6 E. coli transcription elongation complex; Conditions, physiological buffer, no NTPs. Randomly selected subset of data set from Tetone et al., 2017. | ||||||
| = 200, = 200, = 5622 | 3.06 | 0.0038 [0.0036, 0.0039] | 0.0437 [0.0434, 0.0440] | 18.727 [18.724, 18.731] | 0.451 [0.438, 0.463] | 11 hb |
-
*N - number of on-target AOIs, Nc - number of control off-target AOIs, F - number of frames.
-
bUnattended calculation time on an AMD Ryzen Threadripper 2990WX with an Nvidia GeForce RTX 2080Ti GPU using CUDA version 11.5.
-
cUnattended calculation time on an Intel Xeon CPU with an Nvidia Tesla V100-SXM2-16GB GPU using CUDA version 11.2 in a Google Colab Pro account.
Tapqir accuracy on simulated data with known global parameter values
Next, we evaluated Tapqir’s ability to reliably infer the values of global model parameters. To accomplish this, we generated simulated data sets using a wide range of randomized parameter values and then fit the simulated data to the model (Supplementary file 2). Fit results show that global model parameters (i.e., average specific spot probability , nonspecific binding density , proximity , and gain ; see Figure 2D) are close to the simulated values (Figure 3—figure supplement 3 and Supplementary file 2). This suggests that CoSMoS data contains enough information to reliably infer global model parameters and that the model is not obviously overparameterized.
Tapqir classification accuracy
Having tested the basic function of the algorithm, we next turned to the key question of how accurately Tapqir can detect target-specific spots in data sets of increasing difficulty.
We first examined the accuracy of target-specific spot detection in simulated data sets with decreasing SNR (Supplementary file 3). By eye, spots can be readily discerned at SNR >1 but cannot be clearly seen at SNR <1 (Figure 4A). Tapqir gives similar or better performance: if an image contains a target-specific spot, Tapqir correctly assigns it a target-specific spot probability that is on average close to one as long as SNR is adequate (i.e., SNR >1) (Figure 4B). In contrast, mean sharply decreases at SNR <1, consistent with the subjective impression that no spot is recognized under those conditions. In particular, images that contain a target-specific spot are almost always assigned a high for high SNR data and almost always assigned low for low SNR data (Figure 4C, green). At marginal SNR ≈ 1, these images are assigned a broad distribution of values, accurately reflecting the uncertainty in classifying such data. Just as importantly, images with no target-specific spot are almost always assigned < 0.5, correctly reflecting the absence of the spot (Figure 4C, gray).
Figure 4 with 1 supplement see all
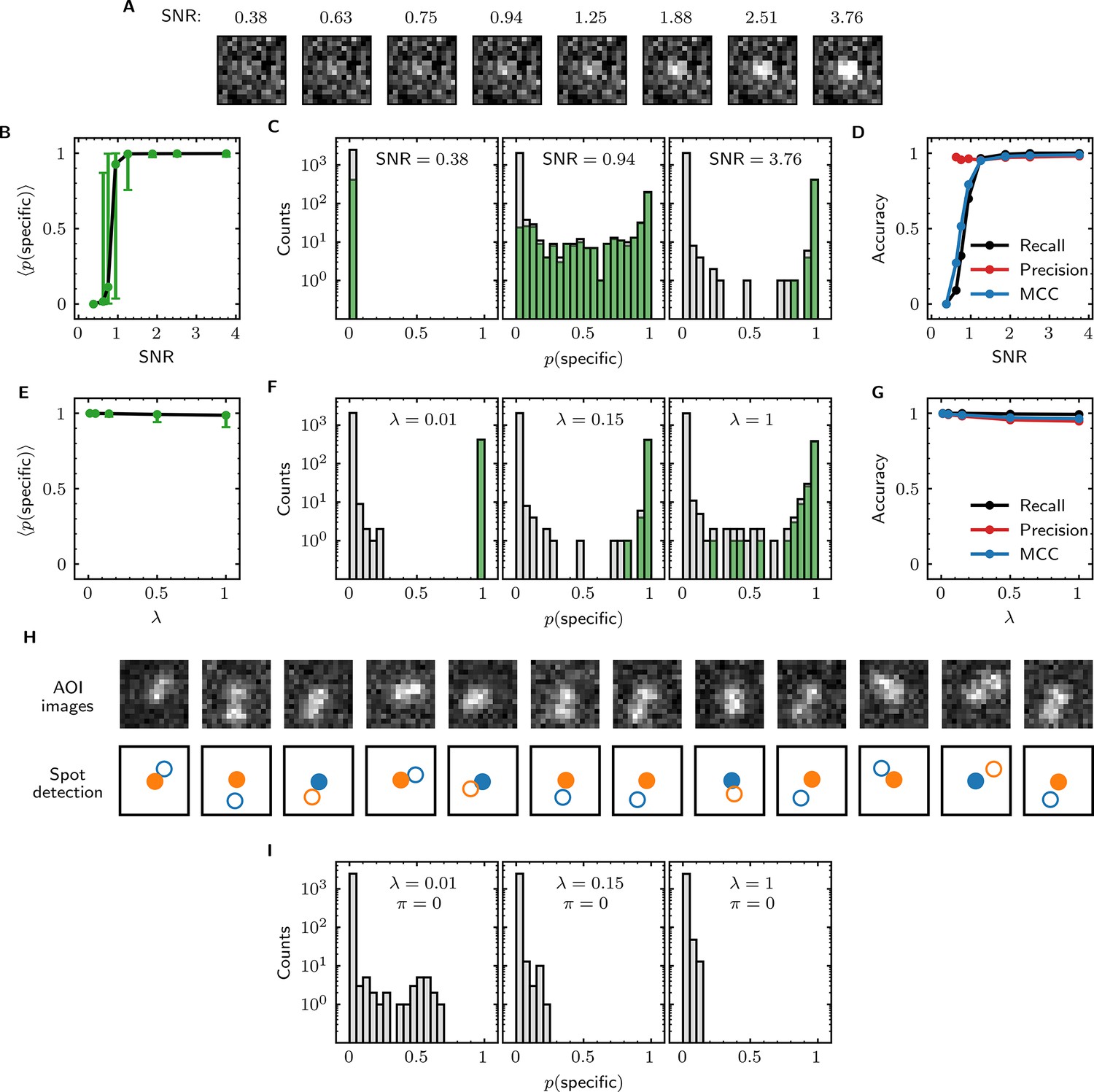
Tapqir performance on simulated data with different SNRs or different non-specific binding densities.
(A–D) Analysis of simulated data over a range of SNR. SNR was varied in the simulations by changing spot intensity while keeping other parameters constant (Supplementary file 3). (A) Example images showing the appearance of the same target-specific spot simulated with increasing SNR. (B) Mean of Tapqir-calculated target-specific spot probability (with 95% CI; see Materials and methods) for the subset of images where target-specific spots are known to be present. (C) Histograms of for selected simulations with SNR indicated. Data are shown as stacked bars for images known to have (green, 15%) or not have (gray, 85%) target-specific spots. Count is zero for bins where bars are not shown. (D) Accuracy of Tapqir image classification with respect to presence/absence of a target-specific spot. Accuracy was assessed by MCC, recall, and precision (see Results and Materials and methods sections). (E–G) Same as in (B–D) but for the data simulated over a range of non-specific binding densities at fixed SNR = 3.76 (Supplementary file 1). (H) Spot recognition in AOI images containing closely spaced target-specific and non-specific spots. Images were selected from the = 1 data set in (E–G). AOI images and spot detection are plotted as in Figure 3, with spot numbers 1 (blue) and 2 (orange) assigned arbitrarily and spots predicted to be target-specific shown as filled circles. (I) Same as in (C) but for the data simulated over a range of non-specific binding densities with no target-specific binding ( = 0) (Supplementary file 4).
Ideally, we want to correctly identify target-specific binding when it occurs but also to avoid incorrectly identifying target-specific binding when it does not occur. To quantify Tapqir’s classification accuracy, we next examined binary image classification statistics. Binary classification predictions were obtained by thresholding at 0.5. We then calculated two complementary statistics: recall and precision (Fawcett, 2006; Figure 4D; see Materials and methods). Recall is defined as the fraction of true target-specific spots that are correctly predicted. Recall is high at high SNR and decreases at lower SNR. Recall is a binary analog of the mean for the subset of images containing target-specific spots; as expected the two quantities have similar dependencies on SNR (compare Figure 4B and D, black). Precision is the fraction of predicted target-specific spots that are correctly predicted. Precision is near one at all SNR values tested (Figure 4D, red); this shows that the algorithm rarely misclassifies an image as containing a target-specific spot when none is present.
In order to quantify the effects of both correctly and incorrectly classified images in a single statistic, we used the binary classification predictions to calculate the Matthews Correlation Coefficient (MCC) (Matthews, 1975; see Materials and methods). The MCC is equivalent to the Pearson correlation coefficient between the predicted and true classifications, giving 1 for a perfect match, 0 for a random match, and –1 for complete disagreement. The MCC results (Figure 4D, blue) suggest that the overall performance of Tapqir is excellent at SNR ≥ 1: the program rarely misses target-specific spots that are in reality present and rarely falsely reports a target-specific spot when none is present.
The analyses of Figure 4B–D examined Tapqir performance on data in which the rate of target-nonspecific binding is moderate ( = 0.15 non-specific spots per AOI image on average). We next examined the effects of increasing the non-specific rate. In particular, we used simulated data (Supplementary file 1) with high SNR = 3.76 to test the classification accuracy of Tapqir at different non-specific binding densities up to = 1, a value considerably higher than typical of usable experimental data (the experimental data sets in Table 1 have ranging from 0.04 to 0.30). In analysis of these data sets, a few images with target-specific spots are misclassified as not having a specific spot ( near zero) or as being ambiguous ( near 0.5) (Figure 4F, green bars), and a few images with target-nonspecific spots are misclassified as having specific spot ( near or above 0.5) (Figure 4F, gray bars), but these misclassifications only occurred at the unrealistically high value. Even in the simulation with this highest value, Tapqir accurately identified target-specific spots (Figure 4E and F) and returned excellent binary classification statistics (Figure 4G).
A weakness of some existing image-based CoSMoS spot discrimination methods is that target-nonspecific binding adjacent to a target-specific spot can interfere with correctly identifying the latter as target-specific. The very high recall values obtained at = 1 (Figure 4G) confirm that there are few such misidentifications by Tapqir even at high non-specific binding densities. This good performance is likely facilitated by the feature of the Tapqir model that explicitly includes the possibility that both a specifically and a non-specifically bound spot may occur simultaneously in the same AOI. Consistent with this interpretation, we see effective detection of the specific and non-specific spots even in example AOIs in which the two spots are so closely spaced that they are not completely resolved (Figure 4H). In contrast, tests of existing CoSMoS image classification methods show that images with target-nonspecific spots are prone to misclassification. As discussed previously (Friedman and Gelles, 2015), methods based on thresholding of integrated AOI intensities are prone to incorrectly classify target-nonspecific spots as target-specific. Conversely, an existing ‘spot-picker’ method based on empirical binary classification of 2-D AOI images (Friedman and Gelles, 2015) is much more likely than Tapqir to fail to detect target specific spots when there is a nearby non-specific spot (Figure 4—figure supplement 1). This contributes to the superior overall performance we see for Tapqir vs. spot-picker on the = 1 data set (recall 0.993 vs 0.919; precision 0.943 vs 0.873; MCC 0.961 vs 0.874).
To further evaluate whether Tapqir is prone to misidentifying target-nonspecific spots as specific, we simulated data sets with no target-specific binding at both low and high non-specific binding densities (Supplementary file 4). Analysis of such data (Figure 4I) shows that no target-specific binding (i.e., > 0.6) was detected even under the highest non-specific binding density, demonstrating that Tapqir is robust to false-positive target-specific spot detection even under these extreme conditions.
Since target-nonspecific spots are built into the cosmos model, there is no need to choose excessively small AOIs in an attempt to exclude non-specific spots from analysis. We found that reducing AOI size (from 14 × 14 to 6 x 6 pixels) did not appreciably affect analysis accuracy on simulated data, when the width () of the spots was equal to 1.4 pixels (Table 2). In analysis of experimental data, smaller AOI sizes caused occasional changes in calculated values reflecting apparent missed detection of a few spots (Figure 3—figure supplement 4). Out of caution, we therefore used 14 × 14 pixel AOIs routinely, even though the larger AOIs somewhat reduced computation speed (Table 2 and Figure 3—figure supplement 4).
Table 2
The effect of AOI size on classification accuracy*.
-
*
Tapqir was applied to the same simulated data set (height1000 parameter set in Supplementary file 3; SNR = 1.25) using different AOI sizes.
-
†
The width () of the simulated spots (one standard deviation of the 2-D Gaussian) is equal to 1.4 pixels.
-
‡
Unattended calculation time on an AMD Ryzen Threadripper 2990WX with an Nvidia GeForce RTX 2080Ti GPU using CUDA version 11.5.
Kinetic and thermodynamic analysis of molecular interactions
The most widespread application of CoSMoS experiments is to measure rate and equilibrium constants for the binding interaction of the target and binder molecules being studied. We next tested whether these constants can be accurately determined using Tapqir-calculated posterior predictions.
We first simulated CoSMoS data sets (Supplementary file 5) that reproduced the behavior of a one-step association/dissociation reaction mechanism (Figure 5A and B, blue). Simulated data were analyzed with Tapqir yielding values for each frame (e.g., Figure 5B, green). We wanted to estimate rate constants using the full information contained in the probabilities, so we did not threshold for this analysis. Instead, from each single-AOI time record we constructed a family of binary time records (Figure 5B, black) by Monte Carlo sampling according to the time series. Each family member has well-defined target-specific binder-present and binder-absent intervals and , respectively. Each of these time records was then analyzed with a two-state hidden Markov model (HMM) (see Materials and methods), producing a distribution of inferred rate constants from which we calculated mean values and their uncertainties (Figure 5C and D). Comparison of the simulated and inferred values shows that both and rate constants are accurate within 30% at nonspecific binding densities typical of experimental data ( ≤ 0.5). At higher nonspecific binding densities, rare interruptions caused by false-positive and false-negative spot detection shorten and distributions, leading to moderate systematic overestimation of the association and dissociation rate constants.
Figure 5

Tapqir analysis of association/dissociation kinetics and thermodynamics.
(A) Chemical scheme for a one-step association/dissociation reaction at equilibrium with pseudo-first-order binding and dissociation rate constants and , respectively. (B) A simulation of the reaction in (A) and scheme for kinetic analysis of the simulated data with Tapqir. The simulation used SNR = 3.76, = 0.02 s−1, = 0.2 s−1, and a high target-nonspecific binding frequency = 1 (Supplementary file 5, data set kon0.02lamda1). Full dataset consists of 100 AOI locations and 1,000 frames each for on-target data and off-target control data. Shown is a short extract of on-target data from a single AOI location in the simulation. Plots show simulated presence/absence of the target-specific spot (blue) and Tapqir-calculated estimate of corresponding target-specific spot probability (green). Two thousand binary traces (e.g., black records) were sampled from the posterior distribution and used to infer and using a two-state hidden Markov model (HMM) (see Materials and methods). Each sample trace contains well-defined time intervals corresponding to target-specific spot presence and absence (e.g., and ). (C,D,E) Kinetic and equilibrium constants from simulations (Supplementary file 5) using a range of values and target-nonspecific spot frequencies , with constant = 0.2 s−1. (C) Values of used in simulations (blue) and mean values (and 95% CIs, black) inferred by HMM analysis from the 2000 posterior samples. Some error bars are smaller than the points and thus not visible. (D) Same as (C) but for . (E) Binding equilibrium constants used in simulation (blue) and inferred from Tapqir-calculated π as (black).
From the same simulated data, we calculated the equilibrium constant and its uncertainty. This calculation does not require a time-dependent model and can be obtained directly from the posterior distribution of the average specific-binding probability . The estimated equilibrium constants are highly accurate even at excessively high values of (Figure 5E). The high accuracy results from the fact that equilibrium constant measurements are in general much less affected than kinetic measurements by occasional false positives and false negatives in spot detection.
The forgoing analysis shows that Tapqir can accurately recover kinetic and thermodynamic constants from simulated CoSMoS data. However, experimental CoSMoS data sets can be more diverse. In addition to having different SNR and non-specific binding frequency values, they also may have non-idealities in spot shape (caused by optical aberrations) and in noise (caused by molecular diffusion in and out of the TIRF evanescent field). In order to see if Tapqir analysis is robust to these and other properties of real experimental data, we analyzed several CoSMoS data sets taken from different experimental projects. Analysis of each data set took a few hours of computation time on a GPU-equipped desktop computer or cloud computing service (Table 1). We first visualized the results as probabilistic rastergrams (Figure 6A, Figure 6—figure supplement 1A, Figure 6—figure supplement 2A, and Figure 6—figure supplement 3A), in which each horizontal line represents the time record from a single AOI. Unlike the binary spot/no-spot rastergrams in previous studies (e.g., Friedman et al., 2013; Rosen et al., 2020) we plotted the Tapqir-calculated spot probability using a color scale. This representation allows a more nuanced understanding of the data. For example, Figure 6A reveals that while the long-duration spot detection events typically are assigned a high probability (yellow), some of the shortest duration events have an intermediate (green) indicating that the assignment of these as target-specific is uncertain.
Figure 6 with 3 supplements see all
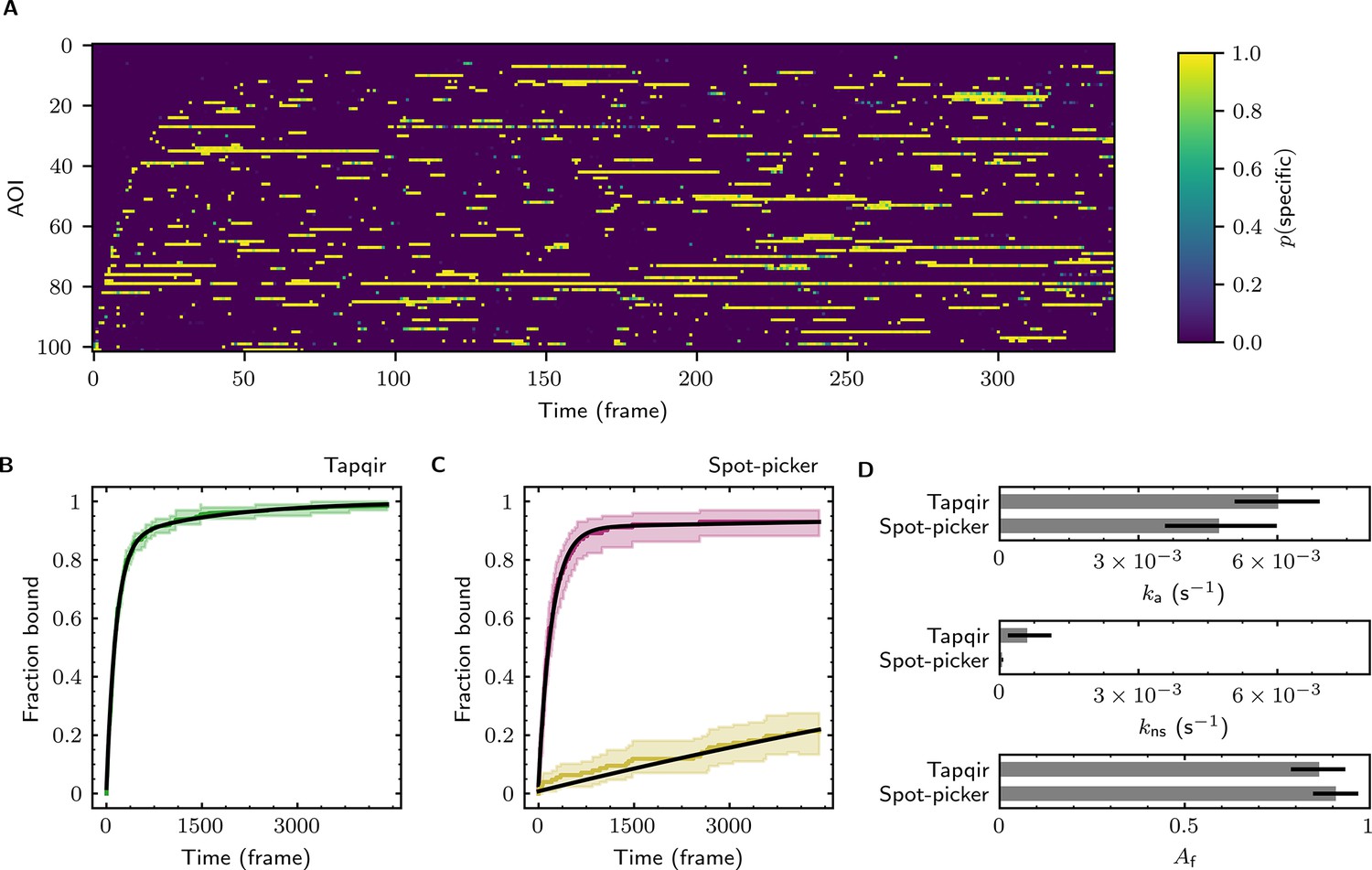
Extraction of target-binder association kinetics from example experimental data.
Data are from Data set B (SNR = 3.77, = 0.1575; see Table 1). (A) Probabilistic rastergram representation of Tapqir-calculated target-specific spot probabilities (color scale). AOIs were ordered by decreasing times-to-first-binding. For clarity, only every thirteenth frame is plotted. (B) Time-to-first-binding distribution using Tapqir. Plot shows the cumulative fraction of AOIs that exhibited one or more target-specific binding events by the indicated frame number (green) and fit curve (black). Shading indicates uncertainty. (C) Time-to-first-binding distribution using an empirical spot-picker method Friedman et al., 2013. The spot-picker method jointly fits first spots observed in off-target control AOIs (yellow) and in on-target AOIs (purple) yielding fit curves (black). (D) Values of kinetic parameters , , and (see text) derived from fits in (B) and (C). Uncertainties reported in (B, C, D) represent 95% credible intervals for Tapqir and 95% confidence intervals for spot-picker (see Materials and methods).
To demonstrate the utility of Tapqir for kinetic analysis of real experimental data, we measured binder association rate constants in previously published experimental data sets (Table 1). We employed our previous strategy (Friedman and Gelles, 2012; Friedman and Gelles, 2015) of analyzing the duration of the binder-absent intervals that preceded the first binding event. Such time-to-first binding analysis improves the accuracy of association rate constant estimates relative to those obtained by analyzing all values by minimizing the effects of target molecules occupied by photobleached binders, dye blinking and false negative dropouts that occur within a continuous binder dwell interval. To perform a time-to-first-binding analysis using Tapqir, we used the posterior sampling method (as in Figure 5B, black records) to determine the initial in each AOI record. These data were fit to a kinetic model (Friedman and Gelles, 2012; Friedman and Gelles, 2015) in which only a fraction of target molecules were binding competent and which includes both exponential target-specific association with rate constant , as well as exponential non-specific association with rate constant (Figure 6B, Figure 6—figure supplement 1B, Figure 6—figure supplement 2B, and Figure 6—figure supplement 3B). The Tapqir-derived fits showed excellent agreement with the kinetic model.
To further assess the utility of the Tapqir method, we used experimental data sets and compared the Tapqir association kinetics results with those from the previously published empirical binary ‘spot-picker’ method (Friedman and Gelles, 2015; Figure 6C, Figure 6—figure supplement 1C, Figure 6—figure supplement 2C, and Figure 6—figure supplement 3C). The values of the association rate constant obtained using these two methods are in good agreement with each other (Figure 6D, Figure 6—figure supplement 1D, Figure 6—figure supplement 2D, and Figure 6—figure supplement 3D). We emphasize that while Tapqir is fully objective, achieving these results with the spot-picker method required optimization by subjective adjustment of spot detection thresholds. We noted some differences between the two methods in the non-specific association rate constants . Differences are expected because these parameters are defined differently in the different non-specific binding models used in Tapqir and spot-picker (see Materials and methods).
Discussion
A broad range of physical processes contribute to the formation of CoSMoS images. These include camera and photon noise, target-specific and non-specific binding, and time- and position-dependent variability in fluorophore imaging and image background. Unlike prior CoSMoS analysis methods, Tapqir considers these aspects of imaging in a single, holistic model. This cosmos model explicitly includes the uncertainties due to photon noise, camera gain, and spatial variability in intensity offset. The model also includes the possibility of multiple binder molecule fluorescence spots being present in the vicinity of the target, including both target-specific binding and target-nonspecific interactions of binder molecules with the coverslip surface. This explicit modeling of target-nonspecific spots makes it possible to include off-target control data as a part of the experimental data set. Similarly, all AOIs and frames in the data set are simultaneously fit to the global model in a way that allows for realistic frame-to-frame and AOI-to-AOI variability in image formation caused by variations in laser intensity, fluctuations in background, and other non-idealities. The global analysis based on a single, unified model enables the final results (e.g., kinetic and thermodynamic parameters) to be estimated in a way that is cognizant of the known sources of uncertainty in the data.
Previous approaches to CoSMoS data analysis, including our spot-picker method (Friedman and Gelles, 2015), did not employ a holistic modeling approach and instead relied on a multi-step process that includes a separate binary classification step. These prior methods require subjective setting of classification thresholds. Because they are not fully objective, such methods cannot reliably account for uncertainties in spot classification, which compromises error estimates in the analysis pipeline downstream of spot classification. One recent approach (Smith et al., 2019; Smith et al., 2015), which like spot-picker and Tapqir analyzes 2-D images instead of integrated intensities, used a Bayesian kinetic analysis but a frequentist hypothesis test (a generalized likelihood ratio test) for spot detection. The frequentist method lacks a key advantage of Tapqir’s model-based Bayesian approach that here enables prediction of target-specific spot presence probabilities for each image, rather than a binary ‘spot/no spot’ classification. In general, previous approaches in essence assume that spot classifications are correct, and thus the uncertainties in the derived molecular properties (e.g., equilibrium constants) are systematically underestimated because the errors in spot classification, which can be large, are not accounted for. By performing a probabilistic spot classification, Tapqir enables reliable inference of molecular properties, such as thermodynamic and kinetic parameters, and allows statistically well-justified estimation of parameter uncertainties. This more inclusive error estimation likely accounts for the generally larger kinetic parameter error bars obtained from Tapqir compared to those from the existing spot-picker analysis method (Figure 6, Figure 6—figure supplement 1, Figure 6—figure supplement 2, and Figure 6—figure supplement 3). Even though existing analysis methods take advantage of subjective tuning by a human analyst, our comparisons show that Tapqir performs at least comparably to (Figure 6, Figure 6—figure supplement 1, Figure 6—figure supplement 2, and Figure 6—figure supplement 3) and under some conditions much better than (Figure 4—figure supplement 1) the existing spot-picker method.
The Tapqir cosmos model includes parameters of mechanistic interest, such as the average probability of target-specific binding, as well as ‘nuisance’ parameters that are not of primary interest but nevertheless essential for image modeling. In previous image-based methods for CoSMoS analysis (e.g., Friedman and Gelles, 2015; Smith et al., 2019), nuisance parameters were either measured in separate experiments (e.g., gain was determined from calibration data), set heuristically (e.g., a subjective choice of user-set thresholds for spot intensity and proximity in colocalization detection), or determined at a separate analysis step (e.g., rate of non-specific binding). In contrast, Tapqir directly learns parameters from the full set of experimental data, thus eliminating the need for additional experiments, subjective adjustment of tuning parameters, and post-processing steps.
Bayesian analysis has been used previously to analyze data from single-molecule microscopy experiments (e.g., Kinz-Thompson et al., 2021 and references cited therein). A key feature of Bayesian analysis is that the extent of prior knowledge of all model parameters is explicitly incorporated. Where appropriate, cosmos uses relatively uninformative priors that only weakly specify information about the value of the corresponding parameters. In these cases, cosmos mostly infers parameter values from the data. In contrast, some priors are more informative. For example, binder molecule spots near the target molecule are more likely to be target-specific rather than target-nonspecific, so we use this known feature of the experiment by encoding the likely position of target-specific binding as a data-based prior. This tactic effectively enables probabilistic classification of spots as either target-specific or target-nonspecific, which would be difficult using other inference methodologies, while still accommodating data sets with different accuracies of mapping between binder and target channels.
Tapqir is implemented in Pyro, a Python-based probabilistic programming language (PPL) (Bingham et al., 2019). Probabilistic programming is a relatively new paradigm in which probabilistic models are expressed in a high-level language that allows easy formulation, modification, and automated inference (van de Meent et al., 2018). In this work we focused on developing an image model for colocalization detection in a relatively simple binder-target single-molecule experiment. However, Tapqir can be used with more complex models. For example, the cosmos model could be naturally extended to multi-state and multi-color analysis. Furthermore, with the development of more efficient sequential hidden Markov modeling algorithms (Särkkä and García-Fernández, 2019; Obermeyer et al., 2019b) Tapqir can potentially be extended to directly incorporate kinetic processes, allowing direct inference of kinetic mechanisms and rate constants.
Tapqir is free, open-source software. Tapqir is available at https://github.com/gelles-brandeis/tapqir. The results presented here were obtained using release 1.0 of the program (https://github.com/gelles-brandeis/tapqir/releases/tag/v1.0). The Tapqir documentation, which contains tutorials on program use, is at https://tapqir.readthedocs.io/en/stable/. Source data including Figures, Figure supplements, Supplementary files, manuscript text, and the scripts and data used to generate them are available at https://github.com/ordabayevy/tapqir-overleaf.
Materials and methods
Notation
Request a detailed protocolIn the Materials and methods section, we adopt a mathematical notation for multi-dimensional arrays from the field of machine learning (Chiang et al., 2021). The notation uses named axes and incorporates implicit broadcasting of arrays when their shapes are different.
Extracting image data
Request a detailed protocolRaw input data into Tapqir consists of (1) binder channel images (), each pixels in size, for each time point (Figure 1B, right) and (2) lists of locations, corrected for microscope drift if necessary (Friedman and Gelles, 2015), of target molecules and of off-target control locations (Friedman and Gelles, 2015) within the raw images. For simplicity, we use the same notation (, ) both for target molecule locations and off-target control locations. Tapqir extracts a AOI around each target and off-target location and returns (1) the extracted data set consisting of a set of grayscale images, collected at on-target AOI sites and off-target AOI sites for a range of frames (Figure 1C and D; Figure 7), and (2) new target (and off-target) locations (, ) adjusted relative to extracted images where and both lie within the central range of the image. For the data presented in this article, we used = 14. Cartesian pixel indices (i, ) are integers but also represent the center point of a pixel on the image plane. While experimental intensity measurements are integers, we treat them as continuous values in our analysis.
Figure 7

Extraction of AOI images from raw images.
-
Figure 7—source data 1
Original text for Figure 7.
- https://cdn.elifesciences.org/articles/73860/elife-73860-fig7-data1-v2.pdf
The cosmos model
Our intent is to model CoSMoS image data by accounting for the significant physical aspects of image formation, such as photon noise and binding of target-specific and target-nonspecific molecules to the microscope slide surface. A graphical representation of the Tapqir model for CoSMoS data similar to that in Figure 2D but including probability distributions and other additional detail is shown in Figure 2—figure supplement 1. The corresponding generative model represented as pseudocode is shown in Figure 8. All variables with short descriptions and their domains are listed in Table 3. Below, we describe the model in detail starting with the observed data and the likelihood function and then proceed with model parameters and their prior distributions.
Figure 8

Pseudocode representation of cosmos model.
-
Figure 8—source data 1
Original text for Figure 8.
- https://cdn.elifesciences.org/articles/73860/elife-73860-fig8-data1-v2.pdf
Table 3
Variables used in the Tapqir model.
| Symbol | Meaning | Domain |
|---|---|---|
| Maximum number of spots per image | ||
| Number of on-target AOIs | ||
| Number of off-target control AOIs | ||
| Number of frames | ||
| Size of the AOI image in pixels | ||
| Camera gain | ||
| Proximity | ||
| Average target-specific binding probability | ||
| Target-nonspecific binding density | ||
| Mean background intensity across AOI | ||
| Standard deviation of background intensity across AOI | ||
| Background intensity | ||
| Target-specific spot presence | ||
| Target-specific spot index | ||
| Spot presence indicator | ||
| Integrated spot intensity | ||
| Spot width | ||
| Center of the spot on the -axis | ||
| Center of the spot on the -axis | ||
| 2-D Gaussian spot | ||
| Ideal image w/o offset | ||
| Offset signal | ||
| Observed image w/o offset signal | ||
| Observed image () | ||
| Target molecule position on the -axis | ||
| Target molecule position on the -axis | ||
| i | Pixel index on the -axis | |
| Pixel index on the -axis | ||
| Width of the raw microscope images in pixels | ||
| Height of the raw microscope image in pixels | ||
| Raw microscope images | ||
| Target molecule position in raw images on the -axis | ||
| Target molecule position in raw images on the -axis |
Image likelihood
Request a detailed protocolWe model the image data as the sum of a photon-independent offset introduced by the camera and the noisy photon-dependent pixel intensity values :
(1)
In our model, each pixel in the photon-dependent image has a variance which is equal to the mean intensity of that pixel multiplied by the camera gain , which is the number of camera intensity units per photon. This formulation is appropriate for cameras that use charge-coupled device (CCD) or electron-multiplier CCD (EMCCD) sensors. (The experimental CoSMoS datasets we analyzed (Table 1) were collected with EMCCD cameras.) It accounts for both photon shot noise and additional noise introduced by EMCCD camera amplification (van Vliet et al., 1998) and is expressed using a continuous Gamma distribution:
(2)
The Gamma distribution was chosen because we found it to effectively model the image noise, which includes both Poissonian (shot noise) and non-Poissonian contributions. The Gamma distribution used here is parameterized by its mean and standard deviation. The functional forms of the Gamma distribution and all other distributions we use in this work are given in Table 4.
Table 4
Probability distributions used in the model.
| Distribution | |
|---|---|
A competing camera technology based on scientific complementary metal-oxide semiconductor (sCMOS) sensors produces images that have also successfully been modeled as having a combination of Poissonian and non-Poissonian (Gaussian, in this case) noise sources. However, sCMOS images have noise characteristics that are considerably more complicated than CCD/EMCCD images, because every pixel has its own characteristic intensity offset, Gaussian noise variance, and amplification gain. Additional validation will be required to determine whether the existing cosmos model requires modification or inclusion of additional prior information (e.g., pixel-by-pixel calibration data as in Huang et al., 2013) to optimize its performance with sCMOS CoSMoS data.
Image model
Request a detailed protocolThe idealized noise-free image is represented as the sum of a background intensity and the intensities from fluorescence spots modeled as 2-D Gaussians :
(3)
For simplicity, we allow at most number of spots in each frame of each AOI. (In this article, we always use equal to 2.) The presence of a given spot in the image is encoded in the binary spot existence parameter , where = 1 when the corresponding spot is present and = 0 when it is absent.
The intensities for a 2-D Gaussian spot at each pixel coordinate (i, ) is given by:
(4)
with spot parameters total integrated intensity , width , and center (, ) relative to the target (or off-target control) location (, ).
Our primary interest is whether a target-specific spot is absent or present in a given AOI. We encode this information using a binary state parameter with 0 and 1 denoting target-specific spot absence and presence, respectively. To indicate which of the spots is target-specific, we use the index parameter which ranges from 0 to . When a target-specific spot is present ( = 1), specifies the index of the target-specific spot, while = 0 indicates that no target-specific spot is present ( = 0). For example, means that both spots are present and spot 2 is target-specific. A combination like is impossible (i.e., has zero probability) since spot 1 cannot be absent and target-specific at the same time. For off-target control data, in which no spots are target-specific by definition, and are always set to zero.
Prior distributions
Request a detailed protocolThe prior distributions for the model parameters are summarized in Figure 2—figure supplement 1 and detailed below. Unless otherwise indicated we assume largely uninformative priors (such as the Half-Normal distribution with large mean).
Background intensity follows a Gamma distribution:
(5)
where the mean and standard deviation of the background intensity describe the irregularity in the background intensity in time and across the field of view of the microscope. Priors for and are uninformative:
(6a)
(6b)
The target-specific presence parameter has a Bernoulli prior parameterized by the average target-specific binding probability for on-target AOIs and zero probability for control off-target AOIs:
(7)
The prior distribution for the index of the target-specific spot is conditional on . When no specifically bound spot is present (i.e., = 0), always equals 0. Since spot indices are arbitrarily assigned, when the target-specific spot is present (i.e., = 1) can take any value between 1 and with equal probability. We represent the prior for as a Categorical distribution of the following form:
(8)
The average target-specific binding probability has an uninformative Jeffreys prior (Gelman et al., 2013) given by a Beta distribution:
(9)
The prior distribution for the spot presence indicator is conditional on . When corresponds to spot index , i.e., , then = 1. When does not correspond to a spot index , that is, , then either spot is target-nonspecific or a spot corresponding to does not exist. Consequently, for we assign to either 0 or 1 with a probability dependent on the non-specific binding density :
(10)
The mean non-specific binding density is expected to be much less than two non-specifically bound spots per frame per AOI; therefore, we use an Exponential prior of the form
(11)
The prior distribution for the integrated spot intensity is chosen to fall off at a value much greater than typical spot intensity values
(12)
In CoSMoS experiments, the microscope/camera hardware is typically designed to set the width of fluorescence spots to a typical value in the range of 1–2 pixels (Ober et al., 2015). We use a Uniform prior confined to the range between 0.75 and 2.25 pixels:
(13)
Priors for spot position (, ) depend on whether the spot represents target-specific or non-specific binding. Non-specific binding to the microscope slide surface can occur anywhere within the image and therefore has a uniform distribution (Figure 2—figure supplement 2, red). Spot centers may fall slightly outside the AOI image yet still affect pixel intensities within the AOI. Therefore the range for (, ) is extended one pixel wider than the size of the image, which allows a spot center to fall slightly beyond the AOI boundary.
In contrast to non-specifically bound molecules, specifically bound molecules are colocalized with the target molecule with a precision that can be better than one pixel and that depends on various factors including the microscope point-spread function and magnification, accuracy of registration between binder and target image channels, and accuracy of drift correction. For target-specific binding, we use an Affine-Beta prior with zero mean position relative to the target molecule location (, ), and a ‘proximity’ parameter which is the standard deviation of the Affine-Beta distribution (Figure 2—figure supplement 2, green). We chose the Affine-Beta distribution because it models a continuous parameter defined on a bounded interval.
(14)
We give the proximity parameter a diffuse prior, an Exponential with a characteristic width of one pixel:
(15)
Tests on data simulated with increasing proximity parameter values (true) (i.e., with decreasing precision of spatial mapping between the binder and target image channels) confirm that the cosmos model accurately learns (fit) from the data (Figure 3—figure supplement 3D; Table 5). This was the case even if we substituted a less-informative prior (Uniform vs. Exponential; Table 5).
Table 5
The effect of mapping precision on classification accuracy*.
| (true) | (fit) [95% CI] | MCC | Prior |
|---|---|---|---|
| 0.2 | 0.21 [0.20, 0.22] | 0.989 | |
| 1 | 0.96 [0.90, 1.02] | 0.939 | |
| 1.5 | 1.49 [1.40, 1.59] | 0.890 | |
| 2 | 1.96 [1.84, 2.09] | 0.834 | |
| 2 | 1.97 [1.84, 2.09] | 0.834 |
-
*
Data were simulated over a range of proximity parameter values at fixed and (Supplementary file 6).
The CoSMoS technique is premised on colocalization of the binder spots with the known location of the target molecule. Consequently, for any analysis method, classification accuracy declines when the images in the target and binder channels are less accurately mapped. For the Tapqir cosmos model, low mapping precision has little effect on classification accuracy at typical non-specific binding densities ( = 0.15; see MCC values in Table 5).
Gain depends on the settings of the amplifier and electron multiplier (if present) in the camera. It has a positive value and is typically in the range between 5 and 50. We use a Half-Normal prior with a broad distribution encompassing this range:
(16)
The prior distribution for the offset signal is empirically measured from the output of camera sensor regions that are masked from incoming photons. Collected data from these pixels are transformed into a density histogram with intensity step size of 1. The resulting histogram typically has a long right hand tail of low density. For computational efficiency, we shorten this tail by binning together pixel intensity values from the upper 0.5% percentile. Since (Equation 1) and photon-dependent intensity is positive, all values have to be larger than the smallest offset intensity value. If that is not the case we add a single value to the offset empirical distribution which has a negligible effect on the distribution. Bin values and their weights are used to construct an Empirical prior:
(17)
All simulated and experimental data sets in this work were analyzed using the prior distributions and hyperparameter values given above, which are compatible with a broad range of experimental conditions (Table 1). Many of the priors are uninformative and we anticipate that these will work well with images taken on variety of microscope hardware. However, it is possible that highly atypical microscope designs (e.g., those with effective magnifications that are sub-optimal for CoSMoS) might require adjustment of some fixed hyperparameters and distributions (those in Eqs. 6a, 6b, 11, 12, 13, 15, and 16). For example, if the microscope point spread function is more than 2 pixels wide, it may be necessary to increase the range of the prior in Eq. 13. The Tapqir documentation (https://tapqir.readthedocs.io/en/stable/) gives instructions for changing the hyperparameters.
Joint distribution
Request a detailed protocolThe joint distribution of the data and all parameters is the fundamental distribution necessary to perform a Bayesian analysis. Let be the set of all model parameters. The joint distribution can be expressed in a factorized form:
(18)
The Tapqir generative model is a stochastic function that describes a properly normalized joint distribution for the data and all parameters (Figure 8). In Pyro this is called ‘the model’.
Inference
Request a detailed protocolFor a Bayesian analysis, we want to obtain the posterior distribution for parameters given the observed data . There are three discrete parameters , , and that can be marginalized out exactly so that they do not appear expilictly in either the joint posterior distribution or the likelihood function. Computationally efficient marginalization is implemented using Pyro’s enumeration strategy (Obermeyer et al., 2019a) and KeOps’ kernel operations on the GPU without memory overflows (Charlier et al., 2021). Let be the rest of the parameters. We obtain posterior distributions of using Bayes’ rule:
(19)
Note that the integral in the denominator of this expression is necessary to calculate the posterior distribution, but it is usually analytically intractable. However, variational inference provides a robust method to approximate the posterior distribution with a parameterized variational distribution (Bishop, 2006).
(20)
has the following factorization:
(21)
The variational distribution is provided as pseudocode for a generative stochastic function (Figure 9). In Pyro this is called ‘the guide’. Variational inference is sensitive to initial values of variational parameters. In Figure 9, step 1 we provide the initial values of variational parameters used in our analyses.
Figure 9

Pseudocode representation of cosmos guide.
-
Figure 9—source data 1
Original text for Figure 9.
- https://cdn.elifesciences.org/articles/73860/elife-73860-fig9-data1-v2.pdf
Calculation of spot probabilities
Request a detailed protocolVariational inference directly optimizes (see Eq. 21 and Figure 9), which approximates . To obtain the marginal posterior probabilities , we use a Monte Carlo sampling method:
(22)
In our calculations, we used = 25 as the number of Monte Carlo samples. Marginal probabilities and are calculated as:
(23a)
(23b)
The probability, , that a target-specific fluorescence spot is present in a given image by definition is:
(24)
For simplicity in the main text and figures we suppress the conditional dependency on in and and instead write them as and , respectively.
Tapqir implementation
Request a detailed protocolThe model and variational inference method outlined above are implemented as a probabilistic program in the Python-based probabilistic programming language (PPL) Pyro (Foerster et al., 2018; Bingham et al., 2019; Obermeyer et al., 2019a). We use a variational approximation because exact inference is not analytically tractable for a model as complex as cosmos. As currently implemented in Pyro, variational inference is significantly faster than Monte Carlo inference methods. In Tapqir, the objective that is being optimized is the evidence lower bound (ELBO) estimator that provides unbiased gradient estimates upon differentiation. At each iteration of inference procedure we choose a random subset of AOIs and frames (mini-batch), compute a differentiable ELBO estimate based on this mini-batch and update the variational parameters via automatic differentiation. We use PyTorch’s Adam optimizer (Kingma and Ba, 2014) with the learning rate of and keep other parameters at their default values.
Credible intervals and confidence intervals
Request a detailed protocolCredible intervals were calculated from posterior distribution samples as the highest density region (HDR), the narrowest interval with probability mass 95% using the pyro.ops.stats.hpdi Pyro function. Confidence intervals were calculated from bootstrap samples as the 95% HDR.
Data simulation
Request a detailed protocolSimulated data were produced using the generative model (Figure 8). Each simulation has a subset of parameters (, , , , , ) set to desired values while the remaining parameters (, , , ) and resulting noisy images () are sampled from distributions. The fixed parameter values and data set sizes for all simulations are provided inSupplementary file 1; Supplementary file 2; Supplementary file 3; Supplementary file 4; Supplementary file 5; Supplementary file 6.
For kinetic simulations (Figure 5, Supplementary file 5), was modeled using a discrete Markov process with the initial probability and the transition probability matrices:
(25a)
(25b)
where and are transition probabilities that numerically approximate the pseudo-first-order binding and first-order dissociation rate constants in units of , respectively, assuming 1 s/frame. We assumed that the Markov process is at equilibrium and initialized the chain with the equilibrium probabilities.
Posterior predictive sampling
Request a detailed protocolFor posterior predictive checking, sampled images () were produced using Tapqir’s generative model (Figure 8) where model parameters were sampled from the posterior distribution , which was approximated by the variational distribution :
(26)
Signal-to-noise ratio
Request a detailed protocolWe define SNR as:
(27)
where the variance of the background intensity, the variance of the offset intensity, and the mean is taken over all target-specific spots. For experimental data, is calculated as
(28)
where is
(29)
For simulated data theoretical is directly calculated as:
(30)
Classification accuracy statistics
Request a detailed protocolAs a metric of classification accuracy we use three commonly used statistics – recall, precision, and Matthews Correlation Coefficient (Matthews, 1975)
(31)
(32)
(33)
where TP is true positives, TN is true negatives, FP is false positives, and FN is false negatives.
Kinetic and thermodynamic analysis
Request a detailed protocolTo estimate simple binding/dissociation kinetic parameters (Figure 5C and D), we sample binary time records from the inferred time records for all AOIs. For a two-state hidden Markov model, the maximum-likelihood estimates of and are given by:
(34)
Repeating this procedure 2,000 times gave the distributions of and from which we compute mean and 95% credible interval.
Similarly, to estimate mean and 95% CI of (Figure 5E) we sampled π from and for each sampled value of calculated as:
(35)
To calculate time-to-first binding kinetics from the Tapqir-derived (Figure 6B, Figure 6—figure supplement 1B, Figure 6—figure supplement 2B, and Figure 6—figure supplement 3B), 2,000 binary time records were sampled from the time record for each AOI. For each sampled time record initial absent intervals were measured and analyzed using Equation 7 in Friedman and Gelles, 2015, yielding distributions of , , and . Mean value and 95% credible intervals were calculated from these distributions. Initial absent intervals from ‘spot-picker’ analysis (Figure 6C, Figure 6—figure supplement 1C, Figure 6—figure supplement 2C, and Figure 6—figure supplement 3C) were analyzed as described in Friedman and Gelles, 2015, except that on-target and off-target data were here analyzed jointly instead of being analyzed sequentially (Friedman and Gelles, 2015). Note that the values determined using the two methods are not directly comparable for several reasons, including that the non-specific binding frequencies are effectively measured over different areas. For Tapqir, the target area is approximately (which is between 0.3 and 0.8 pixels2 in the different experimental data sets) and for spot-picker the area is subjectively chosen as pixels2.
Data availability
All data generated or analyzed for this study will be available at https://github.com/ordabayevy/tapqir-overleaf. That repository also includes all figures, figure supplements, and the scripts and data used to generate them. It also contains the supplemental data files and preprint manuscript text.
-
GithubID ordabayevy/tapqir-overleaf. Simulated and experimental data used for "Bayesian machine learning analysis of single-molecule fluorescence colocalization images".
References
-
Pyro: Deep universal probabilistic programmingJournal of Machine Learning Research: JMLR 20:1–6.
-
Rocket launcher mechanism of collaborative actin assembly defined by single-molecule imagingScience (New York, N.Y.) 336:1164–1168.https://doi.org/10.1126/science.1218062
-
Kernel operations on the GPU, with autodiff, without memory overflowsJournal of Machine Learning Research: JMLR 22:1–6.
-
An introduction to ROC analysisPattern Recognition Letters 27:861–874.https://doi.org/10.1016/j.patrec.2005.10.010
-
Multi-wavelength single-molecule fluorescence analysis of transcription mechanismsMethods (San Diego, Calif.) 86:27–36.https://doi.org/10.1016/j.ymeth.2015.05.026
-
BookChapman and Hall/CRC Texts in Statistical SciencePhiladelphia: CRC Press.https://doi.org/10.1201/b16018
-
Bayesian Inference: The Comprehensive Approach to Analyzing Single-Molecule ExperimentsAnnual Review of Biophysics 50:191–208.https://doi.org/10.1146/annurev-biophys-082120-103921
-
Biased Brownian ratcheting leads to pre-mRNA remodeling and capture prior to first-step splicingNature Structural & Molecular Biology 20:1450–1457.https://doi.org/10.1038/nsmb.2704
-
Substrate degradation by the proteasome: a single-molecule kinetic analysisScience (New York, N.Y.) 348:1250834.https://doi.org/10.1126/science.1250834
-
Specificity of the anaphase-promoting complex: a single-molecule studyScience (New York, N.Y.) 348:1248737.https://doi.org/10.1126/science.1248737
-
Comparison of the predicted and observed secondary structure of T4 phage lysozymeBiochimica et Biophysica Acta 405:442–451.https://doi.org/10.1016/0005-2795(75)90109-9
-
Quantitative Aspects of Single Molecule MicroscopyIEEE Signal Processing Magazine 32:58–69.https://doi.org/10.1109/MSP.2014.2353664
-
Dynamic recognition of the mRNA cap by Saccharomyces cerevisiae eIF4EStructure (London, England 21:2197–2207.https://doi.org/10.1016/j.str.2013.09.016
-
Breaking the Concentration Barrier for Single-Molecule Fluorescence MeasurementsChemistry (Weinheim an Der Bergstrasse, Germany) 24:1002–1009.https://doi.org/10.1002/chem.201704065
-
A practical guide to single-molecule FRETNature Methods 5:507–516.https://doi.org/10.1038/nmeth.1208
-
Probability-based particle detection that enables threshold-free and robust in vivo single-molecule trackingMolecular Biology of the Cell 26:4057–4062.https://doi.org/10.1091/mbc.E15-06-0448
-
The dynamics of SecM-induced translational stallingCell Reports 7:1521–1533.https://doi.org/10.1016/j.celrep.2014.04.033
-
Single-molecule approaches to characterizing kinetics of biomolecular interactionsCurrent Opinion in Biotechnology 22:75–80.https://doi.org/10.1016/j.copbio.2010.10.002
-
BookDigital fluorescence imaging using cooled CCD array cameras invisibleIn: Celis JE, editors. Cell Biology. New York: Academic Press. pp. 109–120.
-
Single-molecule fluorescence-based studies on the dynamics, assembly and catalytic mechanism of the spliceosomeBiochemical Society Transactions 42:1211–1218.https://doi.org/10.1042/BST20140105
-
Structural basis of transcription initiationScience (New York, N.Y.) 338:1076–1080.https://doi.org/10.1126/science.1227786
Article and author information
Author details
Yerdos A Ordabayev

Douglas L Theobald
Funding
National Institute of General Medical Sciences (R01GM121384)
- Jeff Gelles
- Douglas L Theobald
National Institute of General Medical Sciences (R01GM081648)
- Jeff Gelles
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
This work was supported by grants R01GM121384 and R01GM081648 from the National Institute of General Medical Sciences, NIH. We thank Alex Okonechnikov for his work on an earlier version of this project. We thank Jane Kondev, Timothy M Lohman, and Timothy O Street for helpful comments on the manuscript.
Copyright
© 2022, Ordabayev et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,750
- views
-
- 306
- downloads
-
- 4
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Bayesian machine learning analysis of single-molecule fluorescence colocalization images
eLife 11:e73860.
https://doi.org/10.7554/eLife.73860
Further reading
-
- Biochemistry and Chemical Biology
- Microbiology and Infectious Disease
Teichoic acids (TA) are linear phospho-saccharidic polymers and important constituents of the cell envelope of Gram-positive bacteria, either bound to the peptidoglycan as wall teichoic acids (WTA) or to the membrane as lipoteichoic acids (LTA). The composition of TA varies greatly but the presence of both WTA and LTA is highly conserved, hinting at an underlying fundamental function that is distinct from their specific roles in diverse organisms. We report the observation of a periplasmic space in Streptococcus pneumoniae by cryo-electron microscopy of vitreous sections. The thickness and appearance of this region change upon deletion of genes involved in the attachment of TA, supporting their role in the maintenance of a periplasmic space in Gram-positive bacteria as a possible universal function. Consequences of these mutations were further examined by super-resolved microscopy, following metabolic labeling and fluorophore coupling by click chemistry. This novel labeling method also enabled in-gel analysis of cell fractions. With this approach, we were able to titrate the actual amount of TA per cell and to determine the ratio of WTA to LTA. In addition, we followed the change of TA length during growth phases, and discovered that a mutant devoid of LTA accumulates the membrane-bound polymerized TA precursor.
-
- Biochemistry and Chemical Biology
- Computational and Systems Biology
Protein–protein interactions are fundamental to understanding the molecular functions and regulation of proteins. Despite the availability of extensive databases, many interactions remain uncharacterized due to the labor-intensive nature of experimental validation. In this study, we utilized the AlphaFold2 program to predict interactions among proteins localized in the nuage, a germline-specific non-membrane organelle essential for piRNA biogenesis in Drosophila. We screened 20 nuage proteins for 1:1 interactions and predicted dimer structures. Among these, five represented novel interaction candidates. Three pairs, including Spn-E_Squ, were verified by co-immunoprecipitation. Disruption of the salt bridges at the Spn-E_Squ interface confirmed their functional importance, underscoring the predictive model’s accuracy. We extended our analysis to include interactions between three representative nuage components—Vas, Squ, and Tej—and approximately 430 oogenesis-related proteins. Co-immunoprecipitation verified interactions for three pairs: Mei-W68_Squ, CSN3_Squ, and Pka-C1_Tej. Furthermore, we screened the majority of Drosophila proteins (~12,000) for potential interaction with the Piwi protein, a central player in the piRNA pathway, identifying 164 pairs as potential binding partners. This in silico approach not only efficiently identifies potential interaction partners but also significantly bridges the gap by facilitating the integration of bioinformatics and experimental biology.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}